一种时序网络数据集的规则化分散及收拢方法与流程
1.本发明涉及计算机技术及互联网领域,具体涉及互联网环境下网络数据集的规则化分散及收拢方法。
背景技术:
2.随着互联网时代的不断发展,时序数据库、区块链、边缘计算等网络类型数据结构下的随时间延续的数据集体积的增长,对于数据集的读取、传输及操作所需要的资源,成为了越来越多的分布式计算系统的节点处理、存储资源的瓶颈。
3.目前对于这类分布式数据集的数据块体积增长应对可以采用减少封装时间、提高封装费用等处理方法,从而降低需要封装数据集的体积,从而降低后续数据集的传输、处理等成本,但是减少封装时间可能导致数据一致不充分的风险,而提高费用会导致项目运行成本居高的问题。
4.因此,本发明提出一种用于互联网的时序网络数据集在增长状态下的规则化分散及收拢方法,提高互联网下的时序数据在分布式网络状态下的数据存储的更加灵活性和便捷性,从而降低分布式系统的单点处理负荷。
技术实现要素:
5.针对现有技术中存在的技术问题,本发明的目的在于提供一种用于互联网的时序网络数据集在增长过程的规则化分散及收拢存储的方法,适用于所有数据集的进行分裂、收拢存储及处理等调节单点负载的应用场合,是一种应用在公共场合下的时序数据集的关联分散存储的方法。
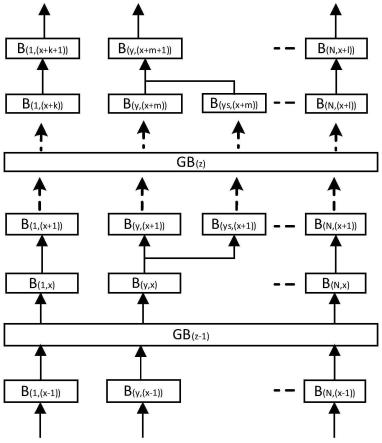
6.在一个给定的计算机网络的时序网络数据集的,时序数据集有若干并行数据块序列构成,数据序列由数据块利用特征值而次第关联的构成,数据块由如图1所示的数据结构组成,其中数据负载由如图2所示的业务数据构成。当数据序列的数据块体积超过设定容量安全阈值或业务设定需要,则数据序列就依据特征值奇偶特性或其他约定规则进行分裂成偶数列数据序列,数据序列之间的业务数据形成互补,如图5和图6所示;当分散后的数据序列的数据块低于设定容量阈值或业务设定需要,则分散后的数据合并回归为之前的数据序列,如图4。
7.本发明的时序数据集的规则化分散及收拢方法,包括如下步骤:
8.1)将用于存储分布式时序数据集的数据结构中各个数据序列b1、~、bn依据不同的业务场景或其他设定准则选择对应的封装算法规则,可以是zip格式压缩、加密算法或其他自定义算法规则,同一条数据序列by中的数据块之间依序次关联,y=1~n,其中这种关联可以是相邻数据块的数据特征之间锚定,或其他自定义关联方法。数据序列b1、~、bn最终依其自身业务特点封装成各自的数据依赖结构,如图4。其中,构成数据序列的数据块至少包括fy_sh、f_ds、ti_(y,x)、data共4部分,也可以包括h_(y,(x-1))、h_g(z-1)作为第5、6部分,如图1,其中,fy_sh是数据块的类型,f_ds是数据块所在数据序列by的标志(可以是
by,也可以是一个编码或者序数),ti_(y,x)是第y列数据序列by中第x个数据块的封装时序标识,可以是封装时刻或其他约定标识,data是指数据块中具体的业务数据负载,h_(y,(x-1))是第y列数据序列by中第x个数据块的前序数据块(即第x-1个数据块)的数字特征值,其中,h_g(z-1)是第y列数据序列by中第x个数据块的超块(即第z-1个)的数字特征值。其中,超块h_g(z)是超块序列(一类数据序列)中的数据块,超块序列的数据块至少保存了其他数据序列的数据序列标志f_ds、数据封装时序ti_(y,x),及前序超块数字特征值h_g(z-1)。“超块”的封装生成方式与普通数据块类似,同时超块接受其他数据块的数字特征值并保存,超块可以是其他普通的数据块的充当,或者也可以是专门的数据块。
9.其中,数据块类型fy_sh用来表征数据块是否分散以及分散的形式,不分散的数据序列此处置为约定值,分散类型的可以是描述参数的序列化或者描述参数的数字特征值,描述参数组织形式可以是xml、json、yml或其他自定义类型。构成数据块的数据负载data包括t_1、t_2、
…
、t_(m),其中,t_(m)(m=1~m)是具体业务数据条目,数据条目可以是k-v(即key-value)数据结构或者由具体业务场景设定数据结构,数据结构与数据块类型fy_sh相匹配。
10.2)时序数据集基于具体业务场景不断增长,达到分散触发条件(如数据负载大于容量阈值),数据序列by在此之后裂变分出数据序列bys,数据序列bys的数据结构与数据序列by相同,但是数据序列by与数据序列bys的数据块内数据负载业务数据条目为业务场景上互相合作或互相依赖的互补集,共同构成一个业务数据集合,其中,数据序列根据业务场景需求采用规则形成互补集,这类规则包括数据条目特征值的奇偶、取模、掩码及其他约定基准归类,如图5和图6,针对数据条目的特征值取模或掩码后再根据具体业务需求进行归类。其中,数据条目特征值可以是序列化或者其他方式自定义方式求得,并将数据条目特征值的获得手段置入类型fy_sh的参数结构。
11.其中,分散触发条件可以是数据负载容量阈值,或者是其他业务场景设定。其中,data_为数据序列by分裂后的数据负载,data_s为数据序列bys的数据负载。data_由t_1、t_3、
…
、t_(m-1)构成,data_s由t_2、t_4、
…
、t_(m)构成,t_(m)可以与其他数据存在着具体的业务合作关系或没有关系,data_与data_s构成互补集。其中,数据条目t_(m)的k-v结构的key可以是value的数字特征值、封装序列或者其他业务场景设置。
12.3)时序数据集基于具体业务场景不断增长,达到全局触发条件(如经过时间间隔),超块gb(z)获得各个数据序列的数据块的数字特征值h_(y,x),超块数据块包括ti_g(z)、data_g、h_(y’)(y’=1~n,ys)、h_g(z-1)部分,其中,ti_g(z)为超块序列的数据块gb(z)的封装时间序列标识,data_g为超块序列的数据块的数据负载,h_(y’)(y’=1~n,ys)为数据序列by(y’=1~n,ys)的数据块数字特征,其中数据序列bys为数据序列by分裂出来的数据序列,h_g(z-1)为超块序列的第z个数据块的前序数据块(第z-1个)。超块序列的“数据块”也即“超块”。
13.4)时序数据集基于具体业务场景不断增长,达到收拢触发条件(如分裂后的数据负载小于设定阈值,数据负载也即数据序列的数据块的封装后体积),数据序列bys向数据序列by汇集融入数据序列by,数据块类型fy_sh设定恢复未分散类型,h_(y,(x-1))中增加数据序列bys中第x个数据块的前序数据块的数字特征值h_s(y,(x-1))。其中,收拢触发条件可以是数据负载容量阈值,或者是其他业务场景设置。
14.与现有技术相比,一种针对网络分布式的时序数据集包括时序数据库、区块链等方面的数据序列的规则化分散和收拢方法,具备以下有益效果:
15.本发明通过形成互相关联互补集,可以实现快速、明确的进行新增数据集分散,从而实现数据集灵活处理;适用于公共网络环境,包括区块链、云计算、边缘计算等环境下的数据集分散、收拢环节,特别是应用于各类分布式数据增长性环境的场景领域。
16.当然,实施本发明的任一产品并不一定需要同时达到以上所述的所有优点。该装置中未涉及部分均与现有技术相同或可采用现有技术加以实现,本发明结构简单,操作方便。
附图说明
17.图1为本发明提出的数据集的数据结构i示意图。
18.图2为本发明提出的数据集的数据结构ii示意图。
19.图3为本发明提出的数据集的数据结构iii示意图。
20.图4为本发明提出的数据集的数据结构iv示意图。
21.图5为本发明提出的数据集的数据结构v示意图。
22.图6为本发明提出的数据集的数据结构vi示意图。
具体实施方式
23.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
24.具体实施案例1,应用于并行区块链,如下所示:
25.在一个区块链的计算机网络的时序网络数据集的,并行区块链有若干并行区块链子链构成,区块链由数据块利用特征值而次第锚定构成,数据块由如图1所示的数据结构组成,其中数据负载由如图2所示的业务数据构成。当区块链的数据块超过设定容量安全阈值或业务设定需要,则数据块所在区块链就进行分裂成两个区块链子链,两条区块链的业务数据形成互补,如图5和图6所示;当分裂后的区块链的数据块低于设定容量阈值或业务设定需要,则分散后的数据合并回归为之前的区块链,如图4。
26.本发明的实施案例的时序数据集的规则化分散及收拢方法,包括如下步骤:
27.1)将数据结构中各个数据序列b1、~、bn依据具体业务场景封装,同一条数据序列by中的数据块之间依序次利用哈希值锚定,y=1~n。数据序列b1、~、bn最终依其自身业务特点封装成各自的数据依赖结构,如图4所示。其中,构成数据序列的数据块包括fy_sh、f_ds、ti_(y,x)、data、h_(y,(x-1))、h_g(z-1)共6部分,如图1,其中,fy_sh是数据块的类型,f_ds是数据块所在数据序列by的标志,ti_(y,x)是数据块的封装时间,data是指数据块承载的具体业务数据负载,h_(y,(x-1))是第y列第x个数据块的前序数据块(即第x-1个)的数字特征值,h_g(z-1)是第y列第x个数据块的依赖超块(即第z-1个)的数字特征值。
28.其中,数据块类型fy_sh表征数据块采用分散以及分散形式,描述参数组织形式采用json。构成数据块的数据负载data包括t_1、t_2、
…
、t_(m),其中,t_(m)(m=1~m)是具体业务数据条目,数据条目采用k-v(即key-value)数据结构,数据结构与类型fy_sh相匹配。
29.本案例的此处fy_sh的json格式描述如下:
[0030][0031]
其中,tyofb键值表示当前区块是否处于分散,on表示处于分散状态,否则为off;k-v键值表示是否采用key-value数据结构,on表示采用。
[0032]
2)随着区块链的不断增长,承载业务的区块链的数据块的数据负载大于预先设定的2mb容量阈值,区块链系统就会触发该条区块链进行分散,数据序列by在此之后裂变分出数据序列bys,数据序列bys的数据结构与by相同。数据序列by与数据序列bys的数据块内数据负载业务数据条目形成互相依赖关系的互补集,两个数据序列的数据条目的以特征值最右位的奇、偶为基准归类,如图5和图6。
[0033]
其中,数据条目特征值可以是序列化求得,并将数据条目特征值的获得手段置入类型fy_sh的参数结构。
[0034]
本案例的序列by和bys此处的fy_sh的json格式描述如下:
[0035][0036]
其中,tyofb键值表示当前区块是否处于分散,on表示处于分散状态,否则为off;nofsh键值表示分散后序列数目,当前为2个;tyofsh键值表示分散依据,eo表示为数据条目索引值的最后右位的奇偶性;k-v键值表示是否采用key-value数据结构,on表示采用。
[0037]
其中,data_为数据序列by分裂后的数据负载,data_s为数据序列bys的数据负载。data_由t_1、t_2、
…
、t_(m-1)构成,data_s由t_2、t_4、
…
、t_(m)构成,data_与data_s构成互补集。其中,数据条目t_(m)的k-v结构的key采用value的数字特征值。
[0038]
3)随着并行区块链的不断延展,经过预先设定的10分钟时间间隔触发全局响应,超块gb(z)获得各个数据序列的数据数字特征值h_(y,x),超块数据块包括ti_g(z)、data_g、h_(y)(y=1~n,ys)、h_g(z-1)部分,其中,ti_g(z)为超块序列的数据块gb(z)的封装时间,data_g为超块序列的数据块的数据负载,h_(y)(y=1~n,ys)为数据序列by(y=1~n,ys)的数据块数字特征,其中数据序列bys为数据序列by分裂出来的数据序列,h_g(z-1)为超块序列的第z个数据块的前序数据块(第z-1个)。
[0039]
4)承载业务的分散的区块链在持续2个数据块负载低于50kb的条件下触发收拢,,数据序列bys向数据序列by汇集形成数据序列by。
[0040]
序列by和bys此处fy_sh的json格式重新描述如下:
[0041][0042]
具体实施案例2,应用于串行区块链,如下所示:
[0043]
在一个串行区块链的计算机网络的时序网络数据集的,区块链由数据块利用特征值而次第关联构成,数据块由如图1所示的数据结构组成,其中数据负载由如图2所示的业务数据构成。当区块链的数据块超过设定容量安全阈值或业务设定需要,则去跨链就进行分裂成两个区块链子链,两条区块链的业务数据形成互补,如图5和图6所示;当分裂后的区块链的数据块低于设定容量阈值或业务设定需要,则分散后的区块链合并回归为之前的数据序列,如图4。
[0044]
本发明的实施案例的时序数据集的规则化分散及收拢方法,具体包括如下步骤:
[0045]
1)将数据结构中各个数据序列b1、~、bn依据具体业务场景封装,同一条数据序列by中的数据块之间依时序次第关联,y=1~n,如图4。其中,构成数据序列的数据块包括fy_sh、f_ds、ti_(y,x)、data、h_(y,(x-1))共5部分,如图1,其中,fy_sh是数据块的类型,f_ds是数据块所在数据序列by的标志,ti_(y,x)是数据块的封装时间编号,data是数据块具体承载的业务数据负载,h_(y,(x-1))是第y列第x个数据块的前序数据块(即第x-1个)的数字特征值。
[0046]
其中,数据块类型fy_sh表征数据块采用分散以及分散形式,描述参数组织形式采用yml格式。构成数据块的数据负载data包括t_1、t_2、
…
、t_(m),其中,t_(m)(m=1~m)是具体业务数据条目,数据条目采用k-v(即key-value)数据结构,数据结构与类型fy_sh相匹配。
[0047]
本案例的此处fy_sh的yml格式描述如下:
[0048][0049]
其中,tyofb键值表示当前区块是否处于分散,on表示处于分散状态,否则为off;k-v键值表示是否采用key-value数据结构,on表示采用。
[0050]
2)区块链的数据块的数据负载大于预先设定的2mb容量阈值,区块链系统就会触发该条区块链进行分散,数据序列by在此之后裂变分出数据序列bys,数据序列bys的数据结构与by相同,但是数据序列by与数据序列bys的数据块内数据负载业务数据条目为互补集,两个数据序列的数据条目的以特征值的奇、偶为基准归类,如图5和图6所示。其中,数据条目特征值可以是序列化或者其他方式自定义方式求得,并将数据条目特征值的获得手段置入类型fy_sh的参数结构。
[0051]
本案例的序列by和bys此处的fy_sh的yml格式描述如下:
[0052][0053]
其中,tyofb键值表示当前区块是否处于分散,on表示处于分散状态,否则为off;nofsh键值表示分散后序列数目,当前为2个;tyofsh键值表示分散依据,eo表示为数据条目索引值的最后右位的奇偶性;k-v键值表示是否采用key-value数据结构,on表示采用。
[0054]
其中,分散触发条件可以是数据负载容量阈值,或者是其他业务场景设置。其中,data_为数据序列by分裂后的数据负载,data_s为数据序列bys的数据负载。data_由t_1、t_2、
…
、t_(m-1)构成,data_s由t_2、t_4、
…
、t_(m)构成,data_与data_s构成互补集。其中,数据条目t_(m)的k-v结构的key采用value的数字特征值。
[0055]
3)分散状态的区块链在持续2个数据块负载低于50kb的条件下触发收拢,,数据序列bys向数据序列by汇集形成数据序列by。其中,收拢触发条件可以是数据负载容量阈值,或者是其他业务场景设置。
[0056]
序列by和bys此处fy_sh的yml格式重新描述如下:
[0057][0058]
具体实施案例3,应用于边缘计算的时序数据处理,如下所示:
[0059]
一个边缘计算的计算机网络的时序网络数据集,时序数据集由若干并行数据块序列构成,数据序列由数据块利用zip规则封装并依时间次第锚定构成,数据块由如图1所示的数据结构组成,其中数据负载由如图2所示的业务数据构成。当数据序列的数据块超过设定容量安全阈值或业务设定需要,则数据序列就进行分裂成两个数据序列,两个数据序列的业务数据集形成互补,如图5和图6所示;当分散后的数据序列的数据块低于设定容量阈值或业务设定需要,则分散后的数据合并回归为之前的数据序列,如图4。
[0060]
本发明的实施案例的时序数据集的规则化分散及收拢方法,包括如下步骤:
[0061]
1)将数据结构中各个数据序列b1、~、bn依据具体业务场景用zip规则封装,同一条数据序列by中的数据块之间依序次利用时序锚定,y=1~n,如图4。其中,构成数据序列的数据块包括fy_sh、f_ds、ti_(y,x)、data共4部分,如图1,其中,fy_sh是数据块的类型,f_ds是数据块所在数据序列by的标志,ti_(y,x)是数据块的封装时间,data是指具体的业务数据负载。
[0062]
构成数据块的数据负载data包括t_1、t_2、
…
、t_(m),其中,t_(m)(m=1~m)是具体业务数据条目,数据条目采用k-v(即key-value)数据结构,数据结构与类型fy_sh相匹配。
[0063]
此处fy_sh的编码格式描述如下:
[0064]
fy_sh=[00 00 01 00 00 01]
[0065]
其中,依据具体业务场景设置掩码mask=[00 00 01 01 01 01],则01],则表征当下数据块不处于分散状态,并且采用key-value数据结构。
[0066]
2)随着时序数据集增长,居于边缘计算节点的业务数据负载大于预先设定的2mb容量阈值,触发该条数据序列进行分散,数据序列by在此之后裂变分出数据序列bys,数据序列bys的数据结构与by相同,但是数据序列by与数据序列bys的数据块内数据负载业务数据条目为互补集,两个数据序列的数据条目的以特征值的奇、偶为基准归类,如图5和图6。其中,数据条目特征值可以是序列化或者其他方式自定义方式求得,并将数据条目特征值的获得手段置入类型fy_sh的参数结构。
[0067]
序列by和bys此处的fy_sh的编码格式描述如下:
[0068]
fy_sh=[00 00 00 01 01 01]
[0069]
其中,依据具体业务场景设置掩码mask=[00 00 01 01 01 01],则01],则表征该处数据块处于分散状态,分散后序列数目当前为2个,数据条目索引值的最后右位的奇偶性,采用key-value数据结构。
[0070]
其中,分散触发条件可以是数据负载容量阈值,或者是其他业务场景设置。其中,data_为数据序列by分裂后的数据负载,data_s为数据序列bys的数据负载。data_由t_1、t_2、
…
、t_(m-1)构成,data_s由t_2、t_4、
…
、t_(m)构成,data_与data_s构成互补集。其中,数据条目t_(m)的k-v结构的key采用value的数字特征值。
[0071]
3)分散状态的数据序列在持续2个数据块负载低于50kb的条件下则触发收拢,数据序列bys向数据序列by汇集形成数据序列by。其中,收拢触发条件可以是数据负载容量阈值,或者是其他业务场景设置。
[0072]
序列by和bys此处fy_sh的编码格式描述如下:
[0073]
fy_sh=[00 00 00 00 00 01]
[0074]
表征当下数据块不处于分散状态,并且采用key-value数据结构。
[0075]
具体实施案例4,应用时序网络数据库,如下所示:
[0076]
在计算机网络的时序网络数据库,有若干并行数据块序列构成,数据序列由数据块利用特征值而次第锚定构成,数据块由如图1所示的数据结构组成,其中数据负载由如图2所示的业务数据构成。当数据序列的数据块超过设定容量安全阈值或业务设定需要,则数据序列就进行分裂成两个数据序列,两个数据序列的业务数据形成互补,如图5和图6所示;当分散后的数据序列的数据块低于设定容量阈值或业务设定需要,则分散后的数据合并回归为之前的数据序列,如图4。
[0077]
本发明的实施案例时序数据集规则化分散及收拢方法,包括如下步骤:
[0078]
1)将时序网络数据库的数据结构中各个数据序列b1、~、bn依据具体业务场景封装,同一条数据序列by中的数据块之间依序次利用哈希值锚定,y=1~n。数据序列b1、~、bn最终依其自身业务特点封装成各自的数据依赖结构,如图4。其中,构成数据序列的数据块包括fy_sh、f_ds、ti_(y,x)、data、h_(y,(x-1))、h_g(z-1)共6部分,如图1,其中,fy_sh是
数据块的类型,f_ds是数据块所在数据序列by的标志,ti_(y,x)是数据块的封装时间,data是数据库序列所承载具体的业务数据负载,h_(y,(x-1))是第y列第x个数据块的前序数据块(即第x-1个)的数字特征值,h_g(z-1)是第y列第x个数据块的依赖超块(即第z-1个)的数字特征值。
[0079]
其中,数据块类型fy_sh的描述参数组织形式采用json。数据块的数据负载data包括t_1、t_2、
…
、t_(m),其中,t_(m)(m=1~m)是具体业务数据条目,数据条目采用t-t(时序-交易事务)数据结构,数据结构与类型fy_sh相匹配。
[0080]
本案例的此处fy_sh的json格式描述如下:
[0081][0082]
其中,tyofb键值表示当前区块是否处于分散,on表示处于分散状态,否则为off;k-v键值表示是否采用key-value数据结构,on表示采用;t-t键值表示是否采用“时序-交易事务”数据结构,on表示采用。
[0083]
2)随着时序数据库的不断增长,承载业务的序列数据块的数据负载大于预先设定的2mb容量阈值,数据库系统就会触发该条序列进行分散,数据序列by在此之后裂变分出数据序列bys,数据序列bys的数据结构与by相同,但是数据序列by与数据序列bys的数据块内数据负载业务数据条目为互补集,两个数据序列的数据条目的以特征值的奇、偶为基准归类,如图5和图6。其中,数据条目特征值可以是序列化方式求得,并将数据条目特征值的获得手段置入类型fy_sh的参数结构。
[0084]
本案例的序列by和bys此处的fy_sh的json格式描述如下:
[0085][0086]
其中,tyofb键值表示当前区块是否处于分散,on表示处于分散状态,否则为off;nofsh键值表示分散后序列数目,当前为2个;tyofsh键值表示分散依据,eo表示为数据条目索引值的最后右位的奇偶性;k-v键值表示是否采用key-value数据结构,off表示采用;t-t键值表示是否采用“时序-交易事务”数据结构,on表示采用。
[0087]
其中,data_为数据序列by分裂后的数据负载,data_s为数据序列bys的数据负载。
data_由t_1、t_2、
…
、t_(m-1)构成,data_s由t_2、t_4、
…
、t_(m)构成,data_与data_s构成互补集。其中,数据条目t_(m)的k-v结构的key采用value的数字特征值。
[0088]
3)随着时序数据库的不断延展,经过预先设定的10分钟时间间隔触发数据库全局响应,超块gb(z)获得各个数据序列的数据数字特征值h_(y,x),超块数据块包括ti_g(z)、data_g、h_(y)(y=1~n,ys)、h_g(z-1)部分,其中,ti_g(z)为超块序列的数据块gb(z)的封装时间,data_g为超块序列的数据块的数据负载,h_(y)(y=1~n,ys)为数据序列by(y=1~n,ys)的数据块数字特征,其中数据序列bys为数据序列by分裂出来的数据序列,h_g(z-1)为超块序列的第z个数据块的前序数据块(第z-1个)。
[0089]
4)分散的数据序列在持续2个数据块负载低于50kb的条件下触发收拢,数据序列bys向数据序列by汇集形成数据序列by。其中,收拢触发条件可以是数据负载容量阈值,或者是其他业务场景设置。
[0090]
序列by和bys此处fy_sh的json格式重新描述如下:
[0091][0092]
以上所述仅为本技术的实施例而已,并不用于限制本技术。对于本领域技术人员来说,本技术可以有各种更改和变化。凡在本技术的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本技术的权利要求范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1