一种基于疾病领域知识图谱的问答匹配系统
1.本发明涉及自然语言处理领域,具体涉及一种基于疾病领域知识图谱的问答匹配系统。
背景技术:
2.问答系统是自然语言处理领域中常见的一种应用,作为信息检索系统的一种常见的表现形式,其可以通过对用户输入的问题进行分析,借助深度学习等算法从众多信息中迅速获取准确有效的信息返回用户,回答用户的问题,满足用户对快速获取准确信息的需求。
3.知识图谱以接近人类认知思维的形式对数据进行组织和理解,为互联网上海量、异构、动态的大数据管理和使用提供了一种优秀的解决方案。知识图谱综合了众多方面的技术和方法,有知识表示、知识抽取(命名实体识别、关系抽取等)、知识融合、知识存储、知识推理、图计算、可视化、语义搜索、知识问答、知识众包等。知识图谱一般遵循rdf三元组数据结构,即(s,p,o)形式,对应主实体subject、关系predicate、尾实体object。知识图谱包含数千万级或者亿级规模实体,以及数十亿或百亿事实(即属性值和与其他实体的关系),这些实体被组织在成千上万由语义体现的客观世界概念结构中。图1展示了冠心病领域知识图谱的一部分,箭头表示关系,箭头从主实体指向尾实体。圆圈表示实体或属性,实体是对客观个体的抽象,如身体部位、疾病、症状。而属性值是用来描述实体的,分为文本型和数值型,如“不能治愈”、“80%”。
4.基于医疗知识图谱的问答系统,可以帮助用户在海量医疗数据中筛选出问题的精准答案并返回给用户,同时借助结构化的知识图谱,可为答案提供一定的解释性。
5.现有技术中存在的缺陷是:
6.1、基于通用领域的词向量表示模型缺乏领域知识,导致原因是bert是在通用语料上进行预训练,而疾病领域专业术语较多,实体较复杂,如“风湿性二尖瓣狭窄”本身是一个完整的实体,同时也嵌套了疾病实体“二尖瓣狭窄”,但由于风湿性二尖瓣狭窄在常见的通用训练语料上出现较少,导致对应的语义向量学习较差,仅识别出二尖瓣狭窄。
7.2、基于流水线的实体链接和实体识别过程存在累积错误,导致原因是流水线是指实体链接和实体识别是串行的过程,实体链接是基于实体识别的结果进行判断,导致错误传递。当实体识别模块输出错误的实体提及,会导致实体无法链接到知识图谱中真正的实体词。
技术实现要素:
8.为了克服现有技术存在的两种缺陷,本发明提供一种基于疾病领域知识图谱的问答匹配系统。
9.本发明采用如下技术方案:
10.一种基于疾病领域知识图谱的问答匹配系统,包括:
11.预处理模块,用于针对用户输入的问题进行预处理,记预处理模块输出q;
12.命名实体识别模块,用于确定实体提及的起始位置和结束位置,预测输出q中各个字符作为句子实体提及开始位置和结束位置的概率,根据起始位置和结束位置的概率确定实体提及的起始位置和结束位置,该命名实体识别模块使用bert
domain
进行微调;
13.实体链接模块,用于将实体提及链接到疾病知识图谱中的实体词,并通过该实体词检索在疾病知识图谱中对应的所有关系;
14.关系匹配模块,用于将实体词对应的关系与预处理模块的输出q进行匹配,判断是否与用户问题一致,一致则输出,且使用bert
domain
进行微调。
15.进一步,所述预处理包括对用户输入的文字问题使用正则化去除空格及标点符号,并且将字母统一为小写。
16.进一步,预测输出q中各个字符作为句子实体提及开始位置和结束位置的概率,确定实体提及,具体为:
17.通过疾病领域预训练后的bert
domain
模型对预处理模块的输出q进行编码输出特征向量,该特征向量经过两个softmax分类层预测每个字符作为实体提及开始位置和结束位置的概率,实体开始位置和结束位置对应的字符串即为实体提及。
18.进一步,获取疾病疾领域的bert
domain
模型的预训练过程为:
19.首先将临床诊疗文献以及电子病历中疾病名称存为词典文件;
20.然后将临床诊疗文献以及电子病历中的文本内容按找标点符号切分为句子;
21.对切分后的句子使用最大词典匹配法查找句子是否包含了词典文件中的疾病词,若包含该疾病词,则将该疾病词进行遮蔽,即将该疾病词替换为mask;对于不包含疾病词的句子,则随机遮蔽某个字符,由此构造疾病领域的mlm任务数据集;
22.最后通过mlm任务数据集对bert模型进行预训练,mlm任务的目标是通过句子的上下文信息预测被替换为mask的词,从而使得模型学习到句子的双向信息,通过mlm任务获得bert
domain
模型以及字符向量e
char
。
23.进一步,所述命名实体识别模块中使用bert
domain
进行微调,微调是在bert
domain
的基础上添加面向下游任务的网络参数,并微调整个网络的参数,命名实体识别模块是在bert
domain
的基础上分别拼接两个softmax分类层,分别用于预测输出q中各个字符作为实体提及起始位置和结束位置的概率。另外,在微调阶段将bert
domain
原始输入中的段编码替换为分词编码。微调阶段中bert
domain
的网络参数使用预训练阶段保存的模型参数进行初始化。
24.进一步,命名实体识别模块实体提及起始位置和结束位置的概率采用如下公式计算:
[0025][0026]
其中,l是q的字符个数,表示q中第k个字符c
k
的特征编码,是bert
domain
输出,h
k
是softmax分类层的网络参数。
[0027]
进一步,所述分词编码具体为:通过分词工具对输出q进行切分,根据分词结果为每个字符打上一个标签,标签集合为{b,m,e,s},其中b代表这个字符是词汇的开始字符,m代表这个字符是词汇的中间字符,e代表这个字符是词汇的结束字符,而s代表单字词,对应分词编码分别为e
b
、e
m
、e
s
、e
e
。
[0028]
进一步,所述实体链接模块通过检索的方式实现,具体分为两阶段,离线阶段和在线查找阶段:
[0029]
离线阶段:将疾病知识图谱中的实体词以及实体别名按字切分,统计tf
‑
idf;
[0030]
对统计后的实体词建立字索引,记录出现过包含某个字的所有实体词以及该字在实体词中出现的位置信息;
[0031]
在线查找阶段:用户输入的问题经过预处理得到q,通过命名实体识别模块得到实体提及,对实体提及按字切分,查找对应的字索引。按照tf
‑
idf累加,按照分数从大到小排序,选取得分最高的前2个实体词作为候选实体;
[0032]
计算各个候选实体与实体提及的dice距离d1和候选实体与q的dice距离d2的加权和,若该加权和大于阈值则保留候选实体,否则去除候选实体。
[0033]
进一步,dice距离为:
[0034][0035]
x、y、s依次表示实体词、实体提及、用户输入,α、β是参数,a∩b表示a与b的公共字符,|*|表示字符长度。
[0036]
进一步,两个softmax分类层的网络参数不同。
[0037]
本发明的有益效果:
[0038]
(1)本发明采用更丰富更专业的领域疾病字符表示。以往的预训练模型是使用通用的语料预训练,疾病领域中存在专业术语多,实体嵌套等问题,因此通过疾病领域的临床诊疗文献和电子病历预训练,可以获得疾病领域的字符向量表示和领域预训练模型bert;
[0039]
(2)本发明实体边界识别更精准,利用知识图谱中的实体辅助分词,按照分词结果增加了分词编码,通过分词结果辅助实体边界识别;
[0040]
(3)本发明缓解实体识别和实体链接之间的耦合。实体链接使用基于检索的实体链接方法,针对实体识别的结果直接影响实体链接的结果,在计算dice距离时,增加实体词与句子的dice距离的计算,避免由于实体边界识别错误导致的dice距离较小。
附图说明
[0041]
图1是现有技术中冠心病领域知识图谱的局部示意图,图中示出主实体、关系、属性及尾实体的示意图;
[0042]
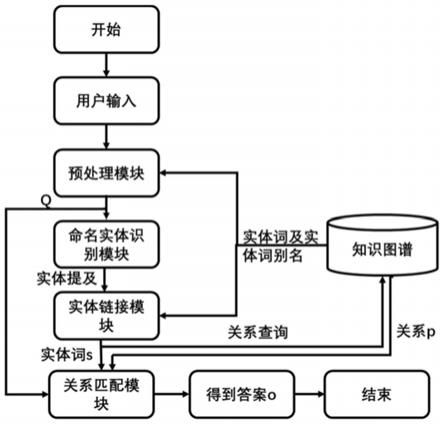
图2是本发明的工作流程图;
[0043]
图3是本发明的命名实体识别模块的示意图。
具体实施方式
[0044]
下面结合实施例及附图,对本发明作进一步地详细说明,但本发明的实施方式不
限于此。
[0045]
实施例
[0046]
如图1
‑
图3所示,一种基于疾病领域知识图谱的问答匹配系统,基于已构建的疾病知识图谱,对用户提出的问题进行分析,并提供相关的答案,包括
[0047]
预处理模块,用于针对用户输入的问题使用正则化去除空格、标点符号等,并且大小写统一为小写,然后记预处理模块输出为q;
[0048]
命名实体识别模块,用于确定实体提及的起始位置和结束位置,经过两个softmax分类层预测输出q中各个字符作为句子实体提及开始位置和结束位置的概率,根据起始位置和结束位置的概率确定对应的字符串,即为实体提及。该命名实体识别模块使用bert
domain
进行微调。
[0049]
概率计算公式为:
[0050][0051]
其中,l是预处理模块的输出q的字符个数,表示第k个字符c
k
的特征编码,是bert
domain
的输出,h
k
是分类层的网络参数,实体开始和结束位置预测时使用的网络层仅分类层网络参数是独立的,即h
k
不同,而bert
domain
相同。
[0052]
是通过领域预训练的bert
domain
获得。原始的bert输入为:字符编码、位置编码以及段编码,命名实体模块使用bert
domain
微调。bert
domain
的输入分为3部分:字符编码、位置编码以及分词编码。其中字符编码是bert
domain
预训练得到的字符表示e
char
,位置编码是各个字符的位置表示,用于bert模型的时序判断,与原始bert的位置编码表示相同。原始的段编码则去掉,替换为分词编码,因为命名实体识别任务是单个句子的任务,不涉及多个句子,所以不需要段编码表示每个字符属于哪个句子。
[0053]
分词编码具体为:通过分词工具对输出q进行分词,根据分词结果为每个字符打上一个标签,标签集合为{b,m,e,s},其中b代表这个字符是词汇的开始字符,m代表这个字符是词汇的中间字符,e代表这个字符是词汇的结束字符,而s代表单字词。按照分词结果,分词结果为b,对应的分词边界编码为e
b
,其它类似,e
b
、e
m
、e
s
、e
e
均是网络参数。通过引入分词编码,为实体边界的识别提供一定的先验知识。如用户输入“风湿性二尖瓣狭窄怎么治”,分词后“狭窄”是相连的词,将分词的结果作为命名实体识别模块的特征,可减少出现实体提及中仅包含“狭”,却不包含“窄”这类实体边界识别错误的情况。
[0054]
实体链接模块是用于将实体识别模块输出的实体提及链接到知识图谱中的实体词s,该模块使用基于检索的实体链接方法实现。具体实施方法为:将知识图谱中的所有实体词以及实体别名(以下实体词指实体词以及实体别名)按字切分,统计tf
‑
idf(term frequency
–
inverse document frequency)。tf是词频(term frequency),表示某个词在一篇文章中出现的频率。idf是逆文本频率指数(inverse document frequency),表示文章总数与某个词在文章出现的次数的比值,一般将该比值取对数。tf
‑
idf的主要思想是:如果某
个词或短语在一篇文章中出现的频率tf高,并在其它文章中很少出现,则认为此词或者短语具有很好的类别区分能力。对于实体链接模块,tf表示实体词中某个字在实体词中的频率,idf为所有实体词数量除以包含该字的实体词个数。统计后对实体词进行倒排索引,记录出现过包含某个字的所有实体词及该字在实体词中出现的位置信息。当输入实体提及,按字切分,按字获取实体词的索引,得到包含该字的各个实体词以及tf
‑
idf,实体词按照命中的字,对tf
‑
idf累加,按照分数从大到小排序,选取得分最高的前2个实体词作为候选实体词。
[0055]
根据以下距离公式判断top2候选实体词是否符合。x、y、s依次表示候选实体词、实体提及、预处理模块的输出q,α、β是参数,a∩b表示a与b的公共字符,|*|表示字符长度。
[0056]
下述公式(2)是候选实体词与实体提及的dice距离d1和候选实体词与句子的dice距离d2的加权和,若该加权和大于阈值则保留该候选实体词,否则去除该候选实体词。
[0057]
计算时不仅关注实体提及与实体词的dice距离d1,还关注实体与句子的dice距离d2,在一定程度上减少由于实体提及边界漏识别导致d1较小,导致实体提及无法链接到正确的实体词。如输入“风湿性二尖瓣狭窄怎么治”,实体提及仅包含了“二尖瓣狭窄”,召回的top1实体是“二尖瓣狭窄”,top2实体是“风湿性二尖瓣狭窄”。计算d1,top1实体比top2实体得分高,而计算d2,top1实体比top2实体得分少,通过d1和d2的加权和,可以减少由于实体边界识别错误导致实体链接时错误链接到“二尖瓣狭窄”的情况。
[0058][0059]
实体链接模块中先根据字索引计算tf
‑
idf,得到两个候选实体词,根据候选实体词计算两个dice距离的加权和,若符合阈值,就将对应的候选实体词称为实体词,实体词的数量可能为0,1,2个。
[0060]
关系匹配模块是用于判断关系p是否与用户输入的意图匹配,若匹配,则知识图谱中(s,p,o)中o即为待输出的答案。关系匹配模块的具体实施方法为:根据实体链接得到的实体词,进行知识图谱的关系检索。实体词与关系进行拼接,作为句子1,用户输入作为句子2,多个关系对应有多个句子1,与bert预训练中的nsp任务一致。使用[cls]的字符表示作为句子的特征向量,进行softmax分类,判断句子1(实体词与关系拼接的句子)与句子2(用户输入经过预处理的句子q)是否在语义上相近。在关系匹配时使用实体词与关系拼接后的句子与q进行匹配,而不是仅使用关系与去除实体提及后的非实体提及部分进行匹配。这是因为考虑到实体链接中是基于字匹配的,需要综合考虑实体和关系两部分是否与用户输入的实体和意图相匹配。而仅使用去除实体提及后的非实体提及部分进行匹配,可能会因为实体提及边界识别错误,导致非实体提及部分的语义发生影响,导致与关系的匹配度不高。选取分数最高的且概率大于阈值的关系记为p,将(s,p,o)中对应的o作为用户输入的答案。
[0061]
本发明使用bert模型有两个阶段:
[0062]
阶段1:预训练阶段。通过屏蔽语言模型(masked language model,mlm)任务预训练,因为原始的bert训练语料是通用领域的,而没有针对疾病领域的,因此对部分疾病词的字符表示效果较差。所以通过设计疾病领域的mlm任务,得到疾病领域的bert
domain
。该mlm任务的输入的编码向量与通用领域的bert预训练中的一致,输入的编码向量为字符向量、段编码、位置向量三者的和。字符向量、段编码、位置向量均是可学习的参数,预训练结束后将
输入中的字符向量e
char
和模型参数保存为文件。预训练阶段bert
domain
的输入为字符向量、段编码、位置向量三者之和。输出称为字符特征向量。
[0063]
阶段2:微调阶段。微调阶段是在bert
domain
的基础上添加面向下游任务的网络参数,并微调整个网络的参数。微调阶段bert
domain
的参数使用阶段1的模型参数初始化,学习率较小,一般为10^
‑
5,而面向下游任务的网络参数则是随机初始化。根据下游任务设计新的损失函数,对模型参数进行微调,因为学习率比较小,所以下游任务模型参数调整也比较小,离模型的输出层越远的网络层参数调整越小。
[0064]
对于本问答系统,下游任务包括两个任务:实体识别和关系匹配。
[0065]
实体识别:针对该任务,将bert
domain
输入中的段编码更改为分词编码。在bert
domain
的基础上分别拼接两个softmax分类层,分别用于预测q中各个字符作为实体提及起始位置和结束位置的概率。bert
domain
的网络参数采用预训练阶段保存的模型参数文件进行初始化。
[0066]
关系匹配:针对该任务,bert
domain
的输入不变,为字符向量、段编码、位置向量三者的和。在bert
domain
的基础上拼接一个softmax分类层,预测输出q与【实体词+关系】是否一致。bert
domain
的网络参数采用预训练阶段保存的模型参数文件进行初始化。
[0067]
本发明与现有技术不同之处在于:
[0068]
(1)命名实体识别模块和关系匹配模块使用疾病领域预训练的bert模型以及疾病领域的字符向量表示。通过mlm任务进行预训练,预训练的语料来自疾病领域的临床诊疗文献和电子病历;
[0069]
(2)命名实体识别模块是单个句子任务,因此不需要段编码。同时,利用知识图谱中的实体辅助分词,按照分词结果获得分词编码。将原始的bert模型输入中的段编码替换分词编码,通过分词结果辅助实体边界识别。
[0070]
(3)实体链接模块使用基于检索的实体链接方法实现。针对实体识别的结果直接影响实体链接的结果,在计算dice距离时,增加实体词与句子的dice距离的计算,减少由于实体边界漏识别导致的dice距离小于阈值。
[0071]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受所述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1