一种增值税发票识别系统及方法与流程
本发明涉及票据识别领域,具体涉及一种增值税发票识别系统及方法。
背景技术:
增值税发票作为企业间交易的凭证,是核实业务往来以及报税的重要依据,此外,增值税发票对于企业的财务管理也极为重要。
随着信息化进程的不断推进,当前增值税发票存在纸质发票和电子发票两种,其中,纸质发票(或打印出来的电子发票)一般通过拍照、扫描等方式电子化后以图像文件的形式进行存储,即形成图片形式增值税发票进行存储,而电子发票则一般以pdf文件格式存储,即形成pdf形式增值税发票进行存储。
在实际的工作中,企业财务需要录入的发票,一般都是图片形式增值税发票和pdf形式增值税发票两种类型混合的。现有的增值税发票识别系统,很少具有对pdf形式增值税发票识别的功能,即便是有,也与图片形式增值税发票识别的功能分离,且与发票图像识别数据格式不统一,需要用户自主选择,并处理不同的数据格式,无法实现自动化区分识别
同时,现有的对于图片形式增值税发票的识别一般以ocr(opticalcharacterrecognition,光学字符识别)技术为基础,主要过程包括预处理、文字检测、文字识别和后处理,但其存在以下缺陷:
(1)预处理一般为基于传统图像处理方法,但是对真实条件下复杂多变的拍照场景,如光照、旋转、模糊、扭曲、发票区域占整个图片区域小、发票区域与背景相似等情况,其处理效果差,且对高分辨率的图片处理速度慢。
(2)文字检测一般为传统图像处理或基于深度学习的文字行检测方法,但只能检测水平或有轻微倾斜的文字行,无法处理大角度旋转甚至垂直的文字行。
(3)文字识别一般为传统图像处理或基于深度学习的识别方法,但由于中文汉字具有以形辨字、字符数量多的特殊性,导致经常出现错识别为形似字的情况,且对模糊文字识别精度低、识别速度慢。
(4)后处理一般为基于预设规则或模板的匹配方法,此类方法无法处理文字检测或文字识别出现的漏识别、错识别等情况,且对于图片上出现字段被部分遮挡、字段打印不规整、字段错行等情形,亦无法成功匹配。因此现有的图片形式增值税发票识别方法,易出现结果输出字段不全情况,输出结果只包含诸如发票代码、发票号码等较为容易匹配的字段。
由上可知,现有的增值税发票识别方法对于扫描或高质量的增值税发票图片有较好的效果,但对真实场景复杂多变的拍照环境和纸质发票打印出来的各种不规整情形,识别效果较差,无法实现对于图片形式增值税发票和pdf形式增值税发票两种形式发票的有效识别。
技术实现要素:
针对现有技术中存在的缺陷,本发明的目的在于提供一种增值税发票识别系统及方法,无需进行增值税发票文件类型的指定,便可实现增值税发票的自动识别。
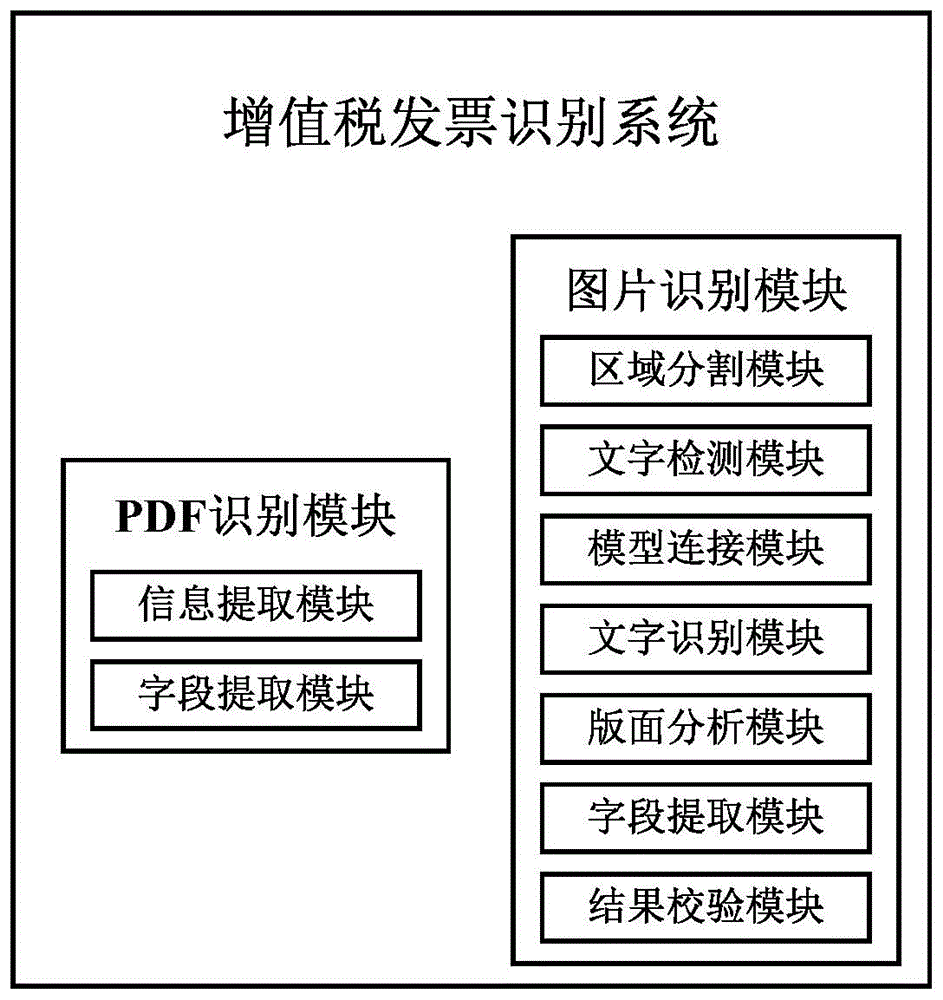
为达到以上目的,本发明提供的一种增值税发票识别系统,包括:
pdf识别模块,其用于对pdf形式增值税发票进行识别,以及当对pdf形式增值税发票识别失败时,基于pdf格式和图片格式间的转化,将pdf形式增值税发票转化为图片形式增值税发票;
图片识别模块,其用于对于图片形式增值税发票以及pdf识别模块转化得到的图片形式增值税发票进行识别。
在上述技术方案的基础上,
所述pdf识别模块包括信息提取模块和字段提取模块;
所述信息提取模块用于解析pdf形式增值税发票的pdf文件数据,得到pdf文件数据中每个字符的文字内容和位置坐标;
所述字段提取模块用于基于预设规则,将信息提取模块得到的每个字符的文字内容和位置坐标,组合为key-value形式的字段,并得到每个字段对应文字内容的位置坐标。
在上述技术方案的基础上,所述预设规则为基于增值税电子发票的版式规则,得到的各个字符的空间位置关系和各个字符的文字内容的正则关系。
在上述技术方案的基础上,
所述图片识别模块包括区域分割模块、文字检测模块、模型连接模块、文字识别模块、版面分析模块、字段提取模块和结果校验模块;
所述区域分割模块用于将图片形式增值税发票所在图片中的发票区域进行分割,得到增值税发票图片;
所述文字检测模块用于检测增值税发票图片上文字行所在的位置,得到文字行的边界框坐标,所述文字行为多个,且每个文字行对应一边界框坐标;
所述模型连接模块用于将文字检测模块检测得到的文字行的边界框坐标所在区域转化为图片,得到文字行图片;
所述文字识别模块用于对文字行图片上的文字内容进行识别;
所述版面分析模块用于基于文字行的边界框坐标、文字行间的相对位置和识别得到的文字行的文字内容,得到每个文字行所属的字段类别;
所述字段提取模块用于基于文字行所属的字段类别,将文字行的文字内容组合成key-value形式的字段,并得到每个字段对应文字内容的位置坐标,输出识别结果;
所述结果校验模块用于对识别结果进行校验。
在上述技术方案的基础上,所述区域分割模块将图片形式增值税发票所在图片中的发票区域进行分割,得到增值税发票图片,具体过程为:
基于fastscnn,得到图片形式增值税发票所在图片的方向,以及图片形式增值税发票所在图片中的发票区域掩膜;
对得到的发票区域掩膜进行轮廓检测,并基于透视变换技术将图片形式增值税发票所在图片中的发票区域进行裁剪;
根据得到的图片形式增值税发票所在图片的方向,对裁剪得到的发票区域进行对应旋转,得到方向为正,且发票区域占满整张图片的增值税发票图片。
在上述技术方案的基础上,所述模型连接模块将文字检测模块检测得到的文字行的边界框坐标所在区域转化为图片,得到文字行图片,具体过程为:
基于透视变换技术,并根据文字行的边界框坐标,对增值税发票图片中的文字行进行裁剪,得到文字行图片,且每张文字行图片仅包括一行文字,且文字行图片的方向为正。
在上述技术方案的基础上,
所述文字识别模块对文字行图片上的文字内容进行识别,具体的,文字识别模块基于crnn+ctc模型对文字行图片上的文字内容进行识别;
所述crnn+ctc模型在对文字行图片进行识别时,将宽高比相近的文字行图片合并成一个批次,输入crnn+ctc模型以进行文字内容识别;
所述crnn+ctc模型有提取图像特征的卷积神经网络backbone、提取语义特征的循环神经网络languagemodel和计算损失的ctcloss串联组成;
所述卷积神经网络backbone和循环神经网络languagemodel之间设有可插拔的超分辨率模块,所述超分辨率模块用于在卷积神经网络backbone的输出之后添加一个与循环神经网络languagemodel平行的分支,利用上采样结构将输入恢复到与输入相同的尺寸;
所述crnn+ctc模型还用于根据语料统计字符出现的频率,并采用huffman树的形式对字符进行编码。
在上述技术方案的基础上,
所述版面分析模块基于文字行的边界框坐标、文字行间的相对位置和识别得到的文字行的文字内容,得到每个文字行所属的字段类别,具体的,基于文字行的边界框坐标、文字行间的相对位置和识别得到的文字行的文字内容,并结合带注意力机制的sequencetosequence模型,得到每个文字行所属的字段类别;
所述sequencetosequence模型的输入为按空间位置顺序排列的特征序列,输出为与特征序列长度相同的序列;
所述特征序列的长度与文字行的数量相同;
所述特征序列的顺序排列为依据文字行边界框坐标,按从上到下,从左到右的排列顺序;
所述特征序列每个位置的特征表现为一个向量。
在上述技术方案的基础上,所述结果校验模块对识别结果进行校验,具体的,结果校验模块基于增值税发票各个字段应满足的固定规则对识别结果进行校验。
本发明提供的一种增值税发票识别方法,包括以下步骤:
获取待识别增值税发票,并基于待识别增值税发票的类型:
当待识别增值税发票的类型为pdf形式增值税发票时,通过pdf识别模块对pdf形式增值税发票进行识别,并当识别失败时,基于pdf格式和图片格式间的转化,将pdf形式增值税发票转化为图片形式增值税发票后,通过图片识别模块进行识别;
当待识别增值税发票的类型为图片形式增值税发票时,直接使用图片识别模块进行识别。
与现有技术相比,本发明的优点在于:能够自动处理不同文件类型的增值税发票,支持pdf形式增值税发票和图片形式增值税发票的识别,无需进行增值税发票文件类型的指定,便可实现自动识别,且还支持输出统一数据格式的识别结果。
附图说明
为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例中一种增值税发票识别系统的结构示意图。
具体实施方式
本发明实施例提供的一种增值税发票识别系统,能够自动处理不同文件类型的增值税发票,支持pdf形式增值税发票和图片形式增值税发票的识别,无需进行增值税发票文件类型的指定,便可实现自动识别,且还支持输出统一数据格式的识别结果。本发明实施例相应地还提供了一种增值税发票识别方法。
为使本申请实施例的目的、技术方案和优点更加清楚,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本申请的一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本申请保护的范围。
参见图1所示,本发明实施例提供的一种增值税发票识别系统,包括pdf识别模块和图片识别模块。pdf识别模块用于对pdf形式增值税发票进行识别,以及当对pdf形式增值税发票识别失败时,基于pdf格式和图片格式间的转化,将pdf形式增值税发票转化为图片形式增值税发票;图片识别模块用于对于图片形式增值税发票以及pdf识别模块转化得到的图片形式增值税发票进行识别。
本发明实施例中,pdf形式增值税发票为可解析的pdf文件格式的增值税电子发票。可解析pdf文件格式,是指包含未加密的文字内容、位置等数据的文件,在用pdf阅读器中打开后出现的文字是由这些数据渲染而成的矢量文字,其表现为文字内容可由鼠标框选,且文字清晰度不会随着放大而降低。与之相对的不可解析的pdf文件,是指文件中包含的是图片数据,表现为文字内容不可由鼠标框选。图片形式增值税发票的文件格式为图片。
本发明实施例中,pdf识别模块包括信息提取模块和字段提取模块;信息提取模块用于解析pdf形式增值税发票的pdf文件数据,得到pdf文件数据中每个字符的文字内容和位置坐标;字段提取模块用于基于预设规则,将信息提取模块得到的每个字符的文字内容和位置坐标,组合为key-value(键值对)形式的字段,并得到每个字段对应文字内容的位置坐标。预设规则为基于增值税电子发票的版式规则,得到的各个字符的空间位置关系和各个字符的文字内容的正则关系。即根据增值税电子发票的版式规则,得到每个字段处的文字内容,以及该文字内容的位置坐标,例如,对于发票名称字段,得到发票名称字段的文字内容,以及该文字内容的位置坐标。
本发明实施例中,图片识别模块包括区域分割模块、文字检测模块、模型连接模块、文字识别模块、版面分析模块、字段提取模块和结果校验模块。区域分割模块用于将图片形式增值税发票所在图片中的发票区域进行分割,得到增值税发票图片。区域分割模块将图片形式增值税发票所在图片中的发票区域进行分割,得到增值税发票图片,具体过程为:
a:基于fastscnn,得到图片形式增值税发票所在图片的方向,以及图片形式增值税发票所在图片中的发票区域掩膜;
b:对得到的发票区域掩膜进行轮廓检测,并基于透视变换技术将图片形式增值税发票所在图片中的发票区域进行裁剪;
c:根据得到的图片形式增值税发票所在图片的方向,对裁剪得到的发票区域进行对应旋转,得到方向为正,且发票区域占满整张图片的增值税发票图片。
将图片形式增值税发票所在图片中的发票区域进行分割,为一个语义分割任务,该任务使用fastscnn进行。fastscnn是一个用于语义分割任务的深度卷积神经网络模型,其输入为归一化后的三通道图片张量,输出与输入长宽相同的二元掩膜,每个位置的值代表该位置的对应像素是否为增值税发票区域的一部分。fastscnn拥有速度快,计算开销低,且有不错精度的特点。
为了适应不同方向的增值税发票图片,对fastscnn的网络结构进行改进,在其globalfeatureextractor模块的下采样之后,添加了一个分类的输出分支,来判定输入图片的方向。在得到fastscnn输出的发票区域掩膜和图片方向后,先对发票区域掩膜做轮廓检测,然后用透视变换将发票区域从原图中剪裁出来,最后根据fastscnn输出的图片方向,对切割出来的图片做相应的旋转,得到正的、发票区域占满整张图片的增值税发票图片。区域分割模块的输入为原始增值税发票图片,输出为正方向,且发票区域占满整张图片的增值税发票图片。
本发明实施例中,文字检测模块用于检测增值税发票图片上文字行所在的位置,得到文字行的边界框坐标,文字行为多个,且每个文字行对应一边界框坐标。
检测增值税发票图片上文字行所在的位置,得到文字行的边界框坐标,具体为使用db(differentiablebinarization,可微分二值化)模型进行。db模型是一种基于分割方法的深度卷积神经网络模型,专用于场景文字检测任务,得益于分割方法像素级别的预测结果,基于分割的场景文字检测方法可以描述不同形状的文字。大多数基于分割的方法需要复杂的后处理,把像素级别的预测结果分类为已检测的文字实例,导致推理的时间成本相当高,一般方法的pipeline使用固定的阈值对于分割后的热力图进行二值化处理,而db的pipeline会将二值化操作嵌入到分割网络中进行组合优化,生成与热力图对应的阈值图,通过二者的结合生成最终的二值化操作。
db模型的优势在于精度高、速度快、可检测任意方向的文字。基于这种特性,在训练的时候将样本图片做随机的旋转,来让模型不仅能检测到水平的文字行,也可以检测到大角度倾斜甚至是垂直的文字行,从而可以很好的处理增值税发票打印时出现的倾斜情况,并且能检测到发票联次字段所在的垂直文字行,不会漏掉这一字段。文字检测模块的输入为区域分割模块的输出,即方向为正,且发票区域占满整张图片的增值税发票图片,输出为输入图片上所有文字行的边界框,每个边界框是一个四边形,由四点共八个坐标表示。
本发明实施例中,模型连接模块用于将文字检测模块检测得到的文字行的边界框坐标所在区域转化为图片,得到文字行图片。模型连接模块将文字检测模块检测得到的文字行的边界框坐标所在区域转化为图片,得到文字行图片,具体过程为:
基于透视变换技术,并根据文字行的边界框坐标,对增值税发票图片中的文字行进行裁剪,得到文字行图片,且每张文字行图片仅包括一行文字,且文字行图片的方向为正。即用透视变换,将文字行从图片中剪裁出来,变为一个个单独的文字行图片,每个文字行图片仅包含一行文字,并根据宽高比,将垂直的文字行小图片,旋转至水平。模型连接模块的输入为区域分割模块和文字检测模块的输出,即方向为正,且发票区域占满整张图片的增值税发票图片,以及所有文字行的边界框;输出为与文字行数量相同的、每张仅包含单独文字行的图片。
本发明实施例中,文字识别模块用于对文字行图片上的文字内容进行识别。文字识别模块对文字行图片上的文字内容进行识别,具体的,文字识别模块基于crnn+ctc模型对文字行图片上的文字内容进行识别;crnn+ctc模型在对文字行图片进行识别时,将宽高比相近的文字行图片合并成一个批次,输入crnn+ctc模型以进行文字内容识别;crnn+ctc模型有提取图像特征的卷积神经网络backbone、提取语义特征的循环神经网络languagemodel和计算损失的ctcloss串联组成;卷积神经网络backbone和循环神经网络languagemodel之间设有可插拔的超分辨率模块,所述超分辨率模块用于在卷积神经网络backbone的输出之后添加一个与循环神经网络languagemodel平行的分支,利用上采样结构将输入恢复到与输入相同的尺寸;crnn+ctc模型还用于根据语料统计字符出现的频率,并采用huffman树的形式对字符进行编码。
crnn+ctc模型一种常用的基于深度神经网络的识别模型,其结构由提取图像特征的卷积神经网络backbone、提取语义特征的循环神经网络languagemodel、和计算损失的ctcloss串联组成,并支持不固定宽度的输入图片,输出则为文本内容和文字行识别置信度。针对增值税发票图片的文字识别,对crnn+ctc模型进行了以下两点改进:
一是针对打印或拍照造成模糊的文字,在卷积神经网络和循环神经网络之间,加入可插拔的超分辨率模块。超分辨率模块只在训练中生效。在训练时,输入为经过模糊处理的低分辨率文字行图片。超分辨率模块在backbone的输出后,添加一个与languagemodel平行的分支,利用反卷积等上采样结构将输入恢复到与输入相同的尺寸,与输入图片模糊前的高分辨率图片做像素级的l1loss,来约束backbone,使其更好的处理模糊的低分辨率输入。而在推理预测时,是不需要该超分辨模块的,因此不会增加额外的计算量。
二是针对中文字符数量多,形近字容易混淆的特点,根据语料统计字符出现的频率,将字符用huffman树的形式编码。这样的层次结构能大幅降低模型参数,减少计算量;并且会为常见字符提供更高的先验概率,以此来降低形近字混淆的错误率。
此外,为了充分利用gpu(graphicsprocessingunit,图形处理器)计算能力,在推理预测阶段,会将所有的文字行图片按宽高比排序,将宽高比相近的文字行小图片合并成一个批次,作为模型的输入。这样的方式不仅利用了并行计算方式速度快的优点,且尽可能的降低了额外增加的计算量。文字识别模块的输入为模型连接模块的输出,即文字行图片;输出为每个文字行的文本内容。
本发明实施例中,版面分析模块用于基于文字行的边界框坐标、文字行间的相对位置和识别得到的文字行的文字内容,得到每个文字行所属的字段类别。版面分析模块基于文字行的边界框坐标、文字行间的相对位置和识别得到的文字行的文字内容,得到每个文字行所属的字段类别,具体的,基于文字行的边界框坐标、文字行间的相对位置和识别得到的文字行的文字内容,并结合带注意力机制的sequencetosequence模型(序列到序列模型),得到每个文字行所属的字段类别;sequencetosequence模型的输入为按空间位置顺序排列的特征序列,输出为与特征序列长度相同的序列;特征序列的长度与文字行的数量相同;特征序列的顺序排列为依据文字行边界框坐标,按从上到下,从左到右的排列顺序;特征序列每个位置的特征表现为一个向量。
具体的,特征序列每个位置的特征表现为一个339维的向量,其组成包括边界框四点坐标(8维)、文字内容每个字符做word2vec后平均(300维)和文字内容依据预设的正则表达式规则判断等人工设计的特征(31维)。其中word2vec是预先由语料数据训练的字符级别的词向量模型,它将每个字符转化为300维的向量表示。
输出的字段类别序列同样与文字行的数量相同。序列的每个位置表示该文字行所属的字段类别,共33类,包括表示文字行不属于任何字段的其它类、增值税发票基本信息24类和增值税发票物品明细信息8类。使用带注意力机制的sequencetosequence模型优势在于分利用了文字行间的关联关系,能更准确的判断文字行的类别。版面分析模块的相对于一般增值税发票识别的后处理,优势在于能准确的判断因打印倾斜、多行错行、部分遮盖等各种复杂情况下文字行所属的字段类别,鲁棒性高,泛化能力强。版面分析模块的输入为文字检测模块和文字识别模块的输出,即文字行的边界框坐标和文本内容;输出为文字行所属的字段类别。
本发明实施例中,字段提取模块用于基于文字行所属的字段类别,将文字行的文字内容组合成key-value形式的字段,并得到每个字段对应文字内容的位置坐标,输出识别结果。主要是依据预设的正则表达式等人工设计的规则,将属于同字段类别的(可能有)多个文字行按空间位置关系组合起来,并将字段的key与value区分开来。这里的空间位置关系判断的依据是文字行边界框的坐标。字段提取模块的输入为文字检测模块、文字识别模块、版面分析模块的输出,即每个文字行的边界框坐标、文本内容和所属的字段类别;输出为结构化的key-value形式的的增值税发票字段,以及字段相关文字所在的位置坐标。
本发明实施例中,结果校验模块用于对识别结果进行校验。结果校验模块对识别结果进行校验,具体的,结果校验模块基于增值税发票各个字段应满足的固定规则对识别结果进行校验。
因为识别不可能做到100%完全正确,故通过结果校验模块,依据文字识别的置信度和增值税发票各个字段的应满足的固定规则(如“发票代码”、“发票号码”一定存在且为固定位数的数字、“纳税人识别号”最后一位应满足相应的校验规则等),给出每个字段识别结果的置信度,帮助快速判断哪些字段的识别结果是可信的,而哪些识别错误概率较大,从而极大地提高了人工复核的效率。结果校验模块不会修改识别结果,只给出每个字段识别的置信度,以提醒重点关注置信度低的字段。结果校验模块的输入为字段提取模块的输出,即识别得到的结构化的增值税发票字段信息;输出为每个字段识别的置信度。
本发明实施例的增值税发票识别系统,作为云端服务,系统由docker构建的基于flask/gunicorn的微服务框架部署。系统主体与区域分割、文字检测、文字识别模块的深度学习模型部署相分离,在主体内部的对应模块由rpc方式调用模型计算。主体与深度学习模型分离部署,可以做到多主体、单模型,能够大大节约计算资源,在相同的计算资源下提高并发量。作为sdk(softwaredevelopmentkit,软件开发工具包),本发明的增值税发票识别系统由c++实现识别流程,输入待识别的增值税发票图片或pdf文件,输出统一格式的结构化识别结果,可支持本地私有化部署或端侧部署。
本发明实施例的增值税发票识别系统,能够自动处理不同文件类型的增值税发票,支持pdf形式增值税发票和图片形式增值税发票的识别,无需进行增值税发票文件类型的指定,便可实现自动识别,且还支持输出统一数据格式的识别结果。
同时,本发明实施例的增值税发票识别系统还支持全字段识别,可以识别增值税发票的全部32个字段,包括24个发票信息字段和8个项目明细字段;24个发票信息字段包括发票名称、发票代码、发票号码、开票日期、校验码、机器编号、密码区、购买方名称、购买方识别号、购买方地址电话、购买方开户行及账号、合计金额、合计税额、价税合计大写、价税合计小写、联次、销售方名称、销售方识别号、销售方地址电话、销售方开户行及账号、收款人、复核、开票人和备注,8个项目明细字段包括名称、规格型号、单位、数量、单价、金额、税率、税额。
且识别精度高,适用复杂多变的真实自然场景下的增值税发票图片识别,可以在(包括但不限于)发票区域占图片区域较小、背景复杂、任意旋转角度、打印或拍摄模糊、打印多行错行、字段部分遮盖等情况下保证高识别准确率;且识别速度快、利用gpu计算、并行加速、模型结构优化等方法,相对于一般的增值税发票识别,极大地提高识别速度;且能够辅助人工核验,返回字段置信度,帮助快速定位识别出错可能性大的字段,极大地提高人工复核的效率。
本发明实施例的增值税发票识别系统,主要创新点在于:(1)加入区域分割模块,使用深度学习方法提取发票区域;(2)文字检测模块可检测任意角度的文字,包括垂直的文字行;(3)文字识别模块模型训练时使用可插拔超分辨模块增强对模糊文字的识别,huffman树字符编码降低计算量且增强对形近字的区分;(4)版面分析模块使用自然语言处理机器翻译的思想方法,用模型预测文字行所属的字段类别,有很高的分类精度和强鲁棒性;(5)加入结果校验模块,提升人工核验效率;(6)系统主体与深度学习模型分离部署,节约计算资源,增强并发能力。
本发明实施例提供的一种增值税发票识别方法,基于上述所述的增值税发票识别系统实现,其特征在于:
获取待识别增值税发票,并基于待识别增值税发票的类型:
当待识别增值税发票的类型为pdf形式增值税发票时,通过pdf识别模块对pdf形式增值税发票进行识别,并当识别失败时,基于pdf格式和图片格式间的转化,将pdf形式增值税发票转化为图片形式增值税发票后,通过图片识别模块进行识别;
当待识别增值税发票的类型为图片形式增值税发票时,直接使用图片识别模块进行识别。
以上所述仅是本申请的具体实施方式,使本领域技术人员能够理解或实现本申请。对这些实施例的多种修改对本领域的技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本申请的精神或范围的情况下,在其它实施例中实现。因此,本申请将不会被限制于本文所示的这些实施例,而是要符合与本文所申请的原理和新颖特点相一致的最宽的范围。
本发明是参照根据本发明实施例的方法、设备(系统)和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
- 还没有人留言评论。精彩留言会获得点赞!