一种基于组合编码的协同排序推荐方法
本发明属于离散推荐领域,尤其涉及一种基于组合编码的协同排序推荐方法。
背景技术:
近年来,推荐系统在互联网多个领域中得到广泛运用,比如电子商务、社交媒体、新闻流平台等,在这些场景中,推荐系统主要的作用,是根据用户和物品已有的信息,挖掘出用户潜在的感兴趣的物品,推荐给用户,从而提升用户的体验以及平台的流量和广告收入等。
为了提升算法在大规模推荐场景下的推荐效率,近年来很多研究工作在这方面做了大量努力。其中一个研究方向是使用哈希方法。区别于传统的使用实数潜在特征向量来表示用户和物品,哈希方法使用二进制向量来表示用户和物品,这样一来,用户和物品的特征向量的内积操作,就可以在海明空间中,通过快速的位运算的方式来实现。然而,与实值向量相比,二进制向量由于其每一位表达能力有限,其精度自然就会比较低,这就阻碍了它对用户和物品之间的复杂关系的建模。
为了充分利用实值向量在精度上的优势和二进制向量在效率上的优势,基于组合编码的协同过滤方法(cccf)被提出。尽管与现有的推荐方法相比,cccf方法在推荐精度和效率之间有更好的平衡,但是它有两个局限性。首先,该方法的目标函数是平方差逐点损失函数,这与推荐系统的最终目标(即准确推荐用户最喜欢的top-k物品的排序目标)不一致。第二,由于离散约束,该方法采用离散坐标下降的方式进行优化,这种按位更新哈希码的方法会导致方法收敛速度慢,并且容易陷入局部最小值。
技术实现要素:
本发明的目的在于针对现有技术的局限和不足,提供一种基于组合编码的协同排序推荐方法。本发明解决了传统二进制码表达能力不足以及已有的基于组合编码的方法的优化目标与推荐目标不一致的问题,旨在提高推荐的效率和准确度。
本发明的目的是通过以下技术方案来实现的:一种基于组合编码的协同排序推荐方法,包括训练阶段和在线推荐阶段。
在训练阶段,根据由m个用户和n个物品构成的评分矩阵m∈rm×n,来得到用户和物品的组合编码,组合编码包括g个r维的二进制向量,以及一个g维的实数权重向量。第u个用户的组合编码表示为:
其中,bu(k)∈{±1}r为用户u的第k个二进制向量,ηu为用户u实数权重向量,k=1~g,r是实值特征向量的维度。
第i个物品的组合编码表示为:
其中,
用a={(u,i)|mui>0}来表示m中每一个评分对应的用户和物品构成的集合对,u=1~m,i=1~n,mui表示用户u对物品i的评分。用三元组(u,i,j)来代表用户u所评分过的所有物品对i和j使用ω={(u,i,j)|(u,i),(u,j)∈a}来表示所有的三元组,j=1~n。定义yu,i,j来表示用户对这两个物品偏好程度的相对关系,具体定义如下:
用b=[b1,...,bm]∈{±1}m×r以及d=[d1,...,dn]∈{±1}n×r来分别表示r维的用户和物品的二进制向量。优化的目标函数如下:
b(k)∈{±1}m×r,d(k)∈{±1}n×r,k=1,...,g.
其中,
在线推荐阶段:根据训练得到的用户和物品的组合编码,对于每一个访问的用户,计算该用户与所有物品的得分,用户u对物品i的得分计算公式如下:
再将所有得分从高到低进行排序,选择top-k个物品作为推荐结果返回给用户,完成在线推荐。
进一步地,训练阶段具体包括以下步骤:
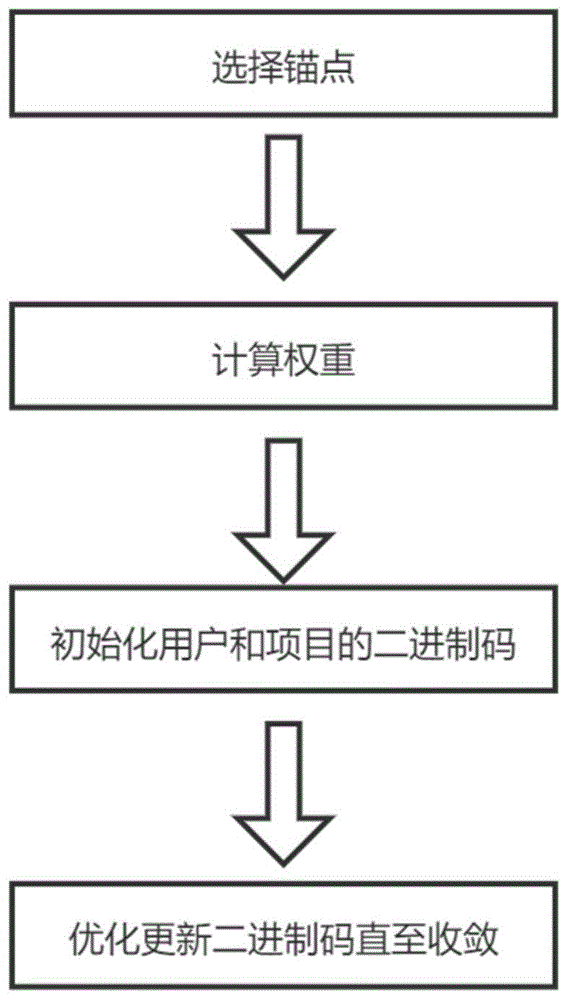
(1)选择锚点。使用协同过滤算法,得到用户和物品的初始实值特征向量,再使用k-means算法,选取g个锚点(u′1,i′1),...,(u′g,i′g)来对应g个局部模型。
(2)计算权重。对于每一个用户和物品,根据其与锚点的距离来计算权重,第k个局部模型的用户权重
其中,u0是用户u对应的初始化实值特征向量,u′k是第k个锚点所对应的用户的实值特征向量,
(3)优化目标函数,以整体闭合解的方式来依次循环更新每个局部模型的二进制向量,直至所有二进制向量都收敛,构建组合编码。
进一步地,步骤(1)具体为:对m使用协同过滤算法,得到用户的初始实值特征向量u0和物品的初始实值特征向量i0;再使用k-means聚类算法,选取g个锚点(u′1,i′1),...,(u′g,i′g)来对应g个局部模型;其中,u′k∈rr是第k个局部模型对应的用户的实值特征向量,i′k∈rr是第k个局部模型所对应的物品的实值特征向量。
进一步地,步骤(3)具体包括以下子步骤:
(3.1)初始化g个局部模型中用户和物品的二进制向量;
(3.2)基于二进制向量的初始值,通过优化目标函数,以整体闭合解的方式依次更新每个局部模型的用户和物品的二进制向量;重复循环更新所有的局部模型,直至所有二进制向量都收敛,得到最终的用户和物品的二进制向量。
(3.3)构建用户和物品的组合编码。
进一步地,步骤(3.1)中,初始化g个局部模型中用户和物品的二进制向量,可以采用以下两种方式:
(3.3.1)随机初始化二进制向量的初始值。
(3.3.2)先将实值特征向量代替二进制向量代入步骤(3.2)构建的目标函数中,优化目标函数得到新的实值特征向量,将新的实值特征向量的符号位作为二进制向量的初始值。
本发明的有益效果是:本发明既利用了组合编码带来的优势,同时又使用了排序损失作为目标函数,相比于使用平方差逐点损失的协同过滤算法,进一步提升了在排序指标上的性能表现。另外,在二进制向量的优化更新方法上,由于传统的bit-by-bit的更新形式收敛速度慢,并且容易陷入局部最优解,本发明采用了block-wise的整体更新方法,具有较快的收敛速度,并且可以获得更优解。
附图说明
图1是本发明的训练流程图;
图2是本发明的在线推荐流程图;
图3是权重计算方式示意图;
图4是用户和物品的二进制向量的更新方法示意图;
图5是本发明方法(cccr)与传统的推荐方法(cccf、primal-cr++、drmf、dcf、pph)在ndcg指标上的比较结果示意图。
具体实施方式
下面结合附图详细描述本发明,本发明的目的和效果将变得更加明显。
本发明一种基于组合编码的协同排序推荐方法,包括训练阶段和在线推荐阶段。
训练流程如图1所示,具体步骤如下:
(1)如图3所示,选择锚点。
(1.1)m个用户和n个物品构成评分矩阵m∈rm×n,用a={(u,i)|mui>0}来表示m中每一个评分对应的用户和物品构成的集合对;其中,u=1~m,i=1~n,mui表示用户u对物品i的评分;
(1.2)对m使用协同过滤算法,得到用户的初始实值特征向量u0和物品的初始实值特征向量i0;再使用k-means聚类算法,选取g个锚点(u′1,i′1),...,(u′g,i′g)来对应g个局部模型;其中,u′k∈rr是第k个局部模型对应的用户的实值特征向量,i′k∈rr是第k个局部模型所对应的物品的实值特征向量,k=1~g,r是实值特征向量的维度。
(2)计算权重。如图3所示,对于每一个用户和物品,根据用户和物品的实值特征向量与锚点的距离来计算权重。
第k个局部模型的用户权重
其中,ii是指示函数,超参数h用来控制权重的稀疏度,distance(us,ut)为计算距离的函数:
其中,<us,ut>表示点积,||表示向量的模。
(3)如图4所示,通过优化目标函数,更新每个局部模型的用户和物品的二进制向量,得到组合编码。
(3.1)用三元组(u,i,j)来代表用户u所评分过的所有物品对i和j,使用ω={(u,i,j)|(u,i),(u,j)∈a}来表示所有的三元组,定义yu,i,j来表示用户对这两个物品偏好程度的相对关系,评分与偏好程度成正比,具体定义如下:
其中,j=1~n。
(3.2)构建目标函数如下:
b(k)=[b1(k),...,bm(k)]∈{±1}m×r,d(k)=[d1(k),...,dn(k)]∈{±1}n×r,k=1,...,g
其中,
(3.3)初始化g个局部模型中用户和物品的二进制向量,可以采用以下两种方式:
(3.3.1)随机初始化二进制向量的初始值。
(3.3.2)先将实值特征向量代替二进制向量代入步骤(3.2)构建的目标函数中,优化目标函数得到新的实值特征向量,将新的实值特征向量的符号位作为二进制向量的初始值。
(3.4)基于二进制向量的初始值,通过优化目标函数,以整体闭合解的方式依次更新每个局部模型的用户和物品的二进制向量;重复循环更新所有的局部模型,直至所有二进制向量都收敛,得到最终的用户和物品的二进制向量。
(3.5)构建用户和物品的组合编码,组合编码包括g个r维的二进制向量,以及一个g维的实数权重向量。
第u个用户的组合编码表示为:
其中,ηu为用户u实数权重向量。
第i个物品的组合编码表示为:
其中,ξi为物品i实数权重向量。
在线推荐阶段时,如图2所示,根据训练得到的用户和物品的组合编码,对于每一个访问的用户,计算该用户与所有物品的得分估计;将所有得分估计从高到低进行排序,选择top-k个物品作为推荐结果返回给用户,完成在线推荐。用户u对物品i的得分估计计算公式如下:
本发明实施例以movielens1m、yelp、netflix作为数据集。将本发明方法称为cccr,其重复检测结果与cccf、primal-cr++、drmf、dcf、pph等方法在ndcg指标上的对比结果如图5所示,与primal-cr++、drmf在检索时间上的对比结果如表1所示,结果表明,本发明方法不光在检索时间上要大大少于已有的实值的算法,在推荐精确度上也要优于已有的基于哈希的和实值的推荐算法。因此,本发明在离散推荐系统中,同时保持了较高的推荐效率以及准确度。
表1:本发明与传统方法在检索时间上的比较结果
- 还没有人留言评论。精彩留言会获得点赞!