一种基于水文相似性和人工神经网络的新安江模型参数率定方法
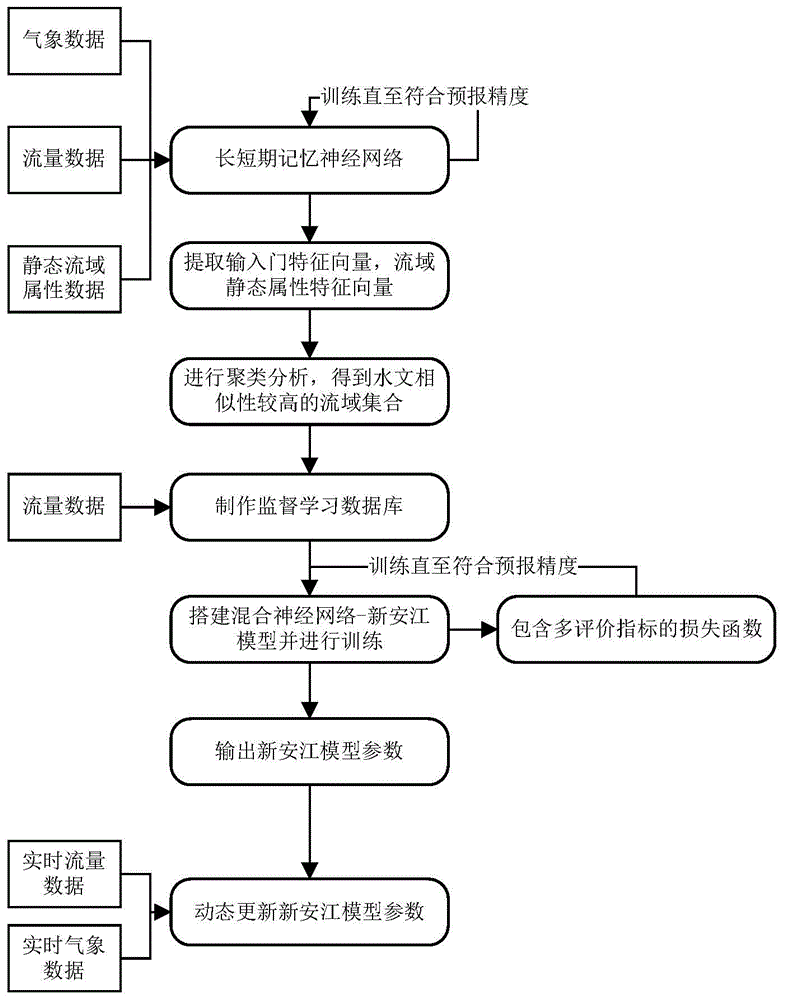
本发明属于数据挖掘与传统物理模型相结合的水文预报
技术领域:
,具体涉及一种基于水文相似性和人工神经网络的新安江模型参数率定方法。
背景技术:
:随着信息技术的发展,使水利信息化程度得到不断提高,大量的智能化水文观测站点被建立。海量的水文历史数据与实时观测数据被存储进水文数据库。系统中的水文数据也呈现爆炸性地增长,虽然给水文信息的研究带来了便利,但同时如何挖掘出这些水文数据背后的信息,也成为水利信息化中面临的最突出问题。趋势对流域未来的水位流量进行有效预测,有助于预防洪涝灾害。新安江模型是概念性水文模型,本文采用将径流划分为地表径流、壤中流以及地下径流的三水源新安江模型。采用蓄满产流假定进行产流计算,将流域内各点不同土壤含水容量概化成蓄水容量曲线。蒸散发采用三层蒸发模式计算,将土壤层划分为上层、下层和深层。三水源新安江模型将净雨划分成地面径流、壤中流以及地下径流,其中地面径流采用单位线进行汇流计算,壤中流和地下径流经过线性水库的调蓄分别作为壤中流出流和地下水出流。周瑜佳等人于2018年5月在《中国农村水利水电》第五期114-118页提出的基于复合形遗传算法的新安江模型参数优化率定将遗传算法与复合形法相结合,构建了一种复合形遗传算法,并采用分层率定思想对新安江模型参数进行优化率定,取得了良好效果,但仍有运行时间相对较长,精度不高的问题。刘欣蔚等人于2018年在《南水北调与水利科技》第十六期69-74页提出的粒子群优化算法(pso)是一种基于群体智能的进化算法,其采用实数求解,不要求目标函数可微,并且模型的参数较少,原理简单,易于实现,可用于解决大规模、非线性、不可微和多峰值的复杂优化问题。但pso算法在应用中和其它全局优化算法同样可能会陷入局部最优,导致收敛精度不高,后期收敛速度较慢。且上述两种参数率定方法没有考虑到流域的水文相似性,物理可解释性较低。技术实现要素:本发明的目的在于克服现有技术的缺陷,提供一种基于水文相似性和人工神经网络的新安江模型参数率定方法,该方法在流域水文建模的基础上,分析流域特征与新安江模型参数之间的关系,接受实时更新的雨量信息作为模型输入,最小化损失函数以更新混合神经网络-新安江模型的参数,最终得到适合该流域的新安江模型。为了解决上述技术问题,本发明采用以下技术方案。本发明的一种基于水文相似性和人工神经网络的新安江模型参数率定方法,包括:步骤一、水文相似性分析:得到流域的各个特征向量并构建监督学习数据库;步骤二、建立参数映射:使用监督学习数据库对混合神经网络-新安江模型即初始人工神经网络进行训练,并最小化损失函数更新新安江模型参数;步骤三、洪水预报与新安江模型参数率定:将流域的特征向量输入到训练完成的混合神经网络-新安江模型即训练后的人工神经网络中,利用训练后的人工神经网络输出新安江模型参数;接受实时更新的雨量信息作为练后的人工神经网络输入,再次训练练后的人工神经网络以减少预报误差,最终实现高精度的洪水预报效果,获得新安江模型参数率定结果;所述的步骤一的过程包括:步骤1.1搭建能识别静态流域特征的长短期记忆网络模型,将流域的气象数据、流量数据和静态流域属性数据作为输入,未来第k时刻流域出口断面流量为长短期记忆网络模型的输出,即长短期记忆网络预报的未来第k小时流量,训练该模型直至符合预报精度;步骤1.2提取长短期记忆网络模型中输入门的权重向量αi作为流域特征向量,流域特征向量代表输入门的激活程度,一定程度上可反映流域的水文特性;并使用k均值聚类算法对该流域特征向量进行聚类分析,从而得到水文相似性较高的流域集合;步骤1.3将流域特征向量作为监督学习数据库的特征,以t时间段内的流域流量数据作为改动长短期记忆网络模型的输入门,使其能识别静态流域特征,即i=σ(wixs+bi)式中,i是输入门,但其状态不随时间改变,xs是静态输入即静态流域特征,包括:平均海拔、植被覆盖率、流域面积。进一步地,所述的步骤1中监督学习数据库的格式为:其中,αi代表第i个流域的特征向量,βi代表第i个流域的t时间段内的流量数据,即βi={q1,q2,……,qt}。进一步地,步骤2中所述的人工神经网络包括一层输入层、两层隐藏层、一层输出层、激活函数为可适应新安江模型参数范围的sigmoid函数;其中,输入层的数据是长短期记忆网络输入门的权重向量αi,且αi∈r256;输出层的数据是包含新安江模型五个高敏感参数的向量γ={x1,x2,……,x5},此五个参数分别为蒸散发折算系数k、表层土自由蓄水库容量sm、地面径流消退系数cs、壤中流消退系数ci和自由水蓄水库地下水日出流系数ki。进一步地,所述的人工神经网络的激活函数由新安江模型参数的取值范围决定,其公式为:其中,xi代表输出的第i个新安江模型参数,maxxi和minxi分别对应第i个参数的最大值和最小值,该激活函数可以将人工神经网络的输出值控制在新安江模型参数的取值范围内。进一步地,步骤2中所述的损失函数是由洪峰峰值误差、洪水流量曲线拟合程度和均方根误差的加权组合,包含多项可评价水文预报精度的相关指标,其公式为:l(γ,β)=λ1·re+λ2·dc+λ3·rmse其中,λ1、λ2和λ3为三个超参数,是控制损失函数中每个项的权重,并且可以在训练过程中进行调整;三个超参数可以设置为同一数值,或者根据决策者的预报侧重点手动调整其权重值大小;re是洪峰相对误差,洪峰预报的准确性是衡量一个模型的重要指标,该数值越接近于0,洪峰预报精度越高;dc为确定性系数,经过改动后使其越接近0,预报准确率越高,其公式为:其中,具体公式为qsimi=f(γ,β)代表输入相关数据后第i时刻的新安江模型的模拟值,qobsi代表实际观测值,代表实际观测值的平均值;rmse为均方根误差,即预测值与真实值之间的偏差的程度,该值越接近0越表明结果与真实值相差越小。进一步地,所述步骤3的具体过程包括:3.1首先通过聚类判断这两个流域是否具有较强的水文相似性;3.2将要进行参数率定的流域的特征向量输入到训练后的人工神经网络中,捕捉该流域的特征与新安江模型参数之间的关系;3.3经过先验知识调参后的新安江模型仍然有一定的预报误差,需要引入该流域的实时气象和流量数据再次对该训练后的人工神经网络进行训练,最终得到适合该流域的新安江模型参数。与现有技术相比,本发明包括以下优点和有益效果:1.与现有参数率定算法相比,本发明参数率定速度快、精度高、物理可解释性和参数可迁移性强。2.本发明可利用实时数据对新安江模型参数进行实时更新,有利于保障在流域地貌特征改变后仍可保持较高的预报精度。附图说明图1为本发明的一种实施例的方法流程图。图2为本发明的一种实施例的可识别流域静态属性数据的长短期记忆神经网络的结构图。图3为本发明的一种实施例的特征向量提取模型训练过程图。图4为本发明的一种实施例的输入门特征向量的激活程度图。图5为本发明的一种实施例的人工神经网络结构图。具体实施方式下面结合附图对本发明做进一步详细说明。图1为本发明的一种实施例的方法流程图。如图1所示,本实施例方法包括以下步骤:步骤一、水文相似性分析:得到流域的各个特征向量并构建监督学习数据库;步骤二、建立参数映射:使用监督学习数据库对混合神经网络-新安江模型即初始的人工神经网络进行训练,并最小化损失函数更新新安江模型参数;步骤三、洪水预报与新安江模型参数率定:将流域的特征向量输入到训练完成的混合神经网络-新安江模型中,利用该训练后的人工神经网络输出新安江模型参数;接受实时更新的雨量信息作为混合模型输入,再次训练混合模型以减少预报误差,最终实现高精度的洪水预报效果,获得新安江模型参数率定结果。所述步骤一的具体过程包括:步骤1.1搭建能识别静态流域特征的长短期记忆神经网络,将流域的气象数据、流量数据和静态流域属性数据作为输入,未来第k时刻流域出口断面流量为长短期记忆网络的输出,即长短期记忆网络预报的未来第k小时流量,训练长短期记忆网络模型直至该模型符合预报精度。步骤1.1.1数据预处理。对流域的气象数据、流量数据和静态流域属性数据的缺值进行插值补全,将数据划分为训练集和测试集,并将时间步设置为365天,时间步长即为降水-径流模拟中的前期天数,以更好地体现长短期记忆网络所拥有的长短期记忆机制。同时为了加速模型参数的优化、加速收敛需要对序列数据进行归一化处理,其转换公式为:其中xi、x′i分别代表第i个时间点的值与归一化值,xmin、xmin为所有时间点中数值的最小值与最大值。步骤1.1.2搭建经过结构改造后能识别静态流域特征的长短期记忆网络,该长短期记忆网络主要在输入门进行修改,使其在最初时刻只能输入流域的静态特征数据,其内部结构如图2所示:i=σ(wixs+bi)f[t]=σ(wfxd[t]+ufh[t-1]+bf)g[t]=tanh(wgxd[t]+ugh[t-1]+vg)o[t]=σ(woxd[t]+uoh[t-1]+bo)c[t]=f[t]⊙c[t-1]+i⊙g[t]h[t]=o[t]⊙tanh(c[t])式中,i是输入门,但其状态不随时间改变。xs是静态输入(例如静态流域特征),xd是时间步长为t动态输入(例如流域气象信息),f[t]是遗忘门,g[t]、h[t]是激活函数,o[t]是输出门,c[t]是细胞状态,σ和tanh分别为sigmoid和双曲正切激活函数。lstm网络中的权值w和偏置值b为决策变量,包括wi、wf、wg、wo、bi、bf、bg、bo;步骤1.1.3输入测试集的数据对训练好的模型进行径流量预测,对输出结果进行反归一化,并使用nse指标对其合理性进行验证,直至模型符合预报精度要求,如图3所示。其中是模型训练后的预测值,为预测值的反归一化值。使用nse(纳什效率)来度量误差:式中,qo指观测值,qm指模拟值,qt表示第t时刻的某个值,表示观测值的总平均;步骤1.2.提取长短期记忆网络模型中输入门的权重向量αi作为流域特征向量,流域特征向量代表输入门的激活程度,一定程度上可反映流域的水文特性;并使用k均值聚类算法对该流域特征向量进行聚类分析,从而得到水文相似性较高的流域集合;步骤1.2.1.提取长短期记忆网络中输入门的权重向量wi作为流域特征向量,如图4所示,汇总所有流域输入门的权重向量作为样本点,即其中n为流域的数量。步骤1.2.2,输入是样本集d={x1,x2,...xm},聚类的簇树k,最大迭代次数n。1)从数据库d中随机选择k个样本作为初始的k个质心向量:[μ1,μ2,...,μk}2)对于n=1,2,...,na)将簇划分c初始化为b)对于i=1,2...m,计算样本xi和各个质心向量μj(j=1,2,...k)的距离:将xi标记最小的为dij所对应的类别λi。此时更新c)对于j=1,2,...,k,对cj中所有的样本点重新计算新的质心e)如果所有的k个质心向量都没有发生变化,则转到以下步骤3)。3)输出簇划分c={c1,c2,...ck}将输入样本映射到高维特征空间中,并对其进行聚类。长短期记忆网络通过直接对流域属性和降雨径流的时间序列数据进行训练,故其输入门的激活程度能直接反映流域之间的水文相似性。通过对流域特征向量进行聚类分析,得到具有较强水文相似性流域的集合。步骤1.3,将流域特征向量作为监督学习数据库的特征,t时间段内的流域流量数据作为数据库的标签,建立监督学习数据库。其监督学习数据库的格式如下所示:其中,αi代表第i个流域的特征向量,βi代表第i个流域的t时间段内的流量数据,即βi={q1,q2,……,qt}。以下,表1为新安江模型日径流模型非敏感性参数的取值,表2为新安江模型日径流模型敏性参数的取值范围及分布形式。表1的参数不需要率定。表2是人工神经网络需要率定的参数。表1新安江模型日径流模型非敏感性参数的取值表2新安江模型日径流模型敏性参数的取值范围及分布形式参数含义最小值最大值k蒸散发折算系数02sm表层土自由蓄水库容量0200cs地面径流消退系数01ci壤中流消退系数01ki自由水蓄水库地下水日出流系数00.6wm流域平均蓄水容量50300所述步骤二的具体过程包括:步骤2.1,使用监督学习数据库对混合神经网络-新安江模型即人工神经网络进行训练,并通过最小化损失函数更新新安江模型参数,该损失函数由洪峰峰值误差、洪水流量曲线拟合程度和确定性系数加权组合。搭建一个包含一层输入层、两层隐藏层以及一层输出层的人工神经网络,其中激活函数为可适应新安江模型参数范围的sigmoid函数,损失函数由洪峰峰值误差、洪水流量曲线拟合程度和均方根误差加权组合。其中,输入层的数据是步骤2中提取的长短期记忆网络输入门的权重向量αi,且αi∈r256。输出层的数据是由新安江模型五个高敏感参数组成的向量γ={x1,x2,……,x5},这五个参数分别为蒸散发折算系数(k)、表层土自由蓄水库容量(sm)、地面径流消退系数(cs)、壤中流消退系数(ci)和自由水蓄水库地下水日出流系数(ki)。其混合模型人工神经网络的激活函数由新安江模型参数的取值范围决定,具体公式如下:其中,xi代表输出的第i个新安江模型参数,maxxi和minxi分别对应第i个参数的最大值和最小值,该激活函数可以将神经网络的输出值控制在新安江模型参数的取值范围内。所述损失函数由洪峰峰值误差、洪水流量曲线拟合程度和确定性系数的加权组合,具体公式如下:l(γ,β)=λ1·re+λ2·dc+λ3·rmse其中,λ1、λ2和λ3三个超参数是控制损失函数中每个项的权重,并且可以在训练过程中进行调整。三个超参数可以设置为同一数值,或者根据决策者的预报侧重点手动调整权重值大小。re是洪峰相对误差,洪峰预报的准确性是衡量一个模型的重要指标,该数值越接近于0,洪峰预报精度越高,具体公式如下:其中,ym,p和y0,p分别是模拟和观察到的峰值径流量。dc为确定性系数,经过改动后使其越接近0,预报准确率越高,具体公式如下:其中,具体公式为qsimi=f(γ,β)代表输入相关数据后第i时刻的新安江模型的模拟值,qobsi代表实际观测值,代表实际观测值的平均值。rmse为均方根误差,即预测值与真实值之间的偏差的程度,该值越接近0越表明结果与真实值相差越小。其中:表示第i个样本河水流量观测值,表示第i个样本河水流量预报值,表示河水流量预报平均值,nsamples表示测试样本数量,n表示测试集第n个样本,分别表示第1个和第n个样本的河水流量观测值,分别表示第1个和第n个样本的河水流量预报值。所述步骤三的具体过程包括:步骤3,模型投入使用后,接受实时更新的雨量信息作为模型输入,训练模型以更新混合神经网络-新安江模型的参数,得到适合该流域的新安江模型参数。步骤3.1,在水文相似性较强的流域进行新安江模型参数率定的具体实施步骤如下:(1)首先通过聚类判断这两个流域是否具有较强的水文相似性。(2)将要进行参数率定的流域的特征向量输入到已经训练好的混合模型中,捕捉该流域的特征与新安江模型参数之间的关系。(3)经过先验知识调参后的新安江模型仍然有一定的预报误差,需要引入该流域的实时气象和流量数据再次对该混合模型进行训练,最终得到适合该流域的新安江模型参数。总之,本发明的一种基于水文相似性和人工神经网络的新安江模型参数率定方法,首先进行水文相似性分析,得到各个流域的特征向量并构建监督学习数据库。然后获取参数映射,使用监督学习数据库对混合神经网络-新安江模型进行训练,该混合神经网络-新安江模型以流域的特征向量作为输入,通过最小化损失函数更新新安江模型参数,损失函数包含洪峰峰值误差、洪水流量曲线拟合程度和均方根误差。最后进行洪水预报与新安江模型参数率定:将流域的特征向量和实时更新的雨量信息作为模型输入,再次训练混合模型以减少预报误差,最终实现高精度的洪水预报效果。本发明提供的新安江模型参数率定方法,具有精度高、物理可解释性和参数可迁移性强的特点。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1