一种基于轻量级堆叠沙漏网络的机械臂姿态估计方法与流程
1.本发明属于机械臂姿态估计领域,具体涉及一种基于轻量级堆叠沙漏网络的机械臂姿态估计方法。
背景技术:
2.精准而灵活的机械臂在工业制造领域中有着广泛的应用,机械臂能够执行诸如物体抓取、人机交互、碰撞检测和避免等任务。近年来,基于视觉的机械臂控制受到了越来越多的关注,与使用特定传感器的传统系统相比,视觉系统具有适应复杂和新颖任务的灵活性。基于视觉的机械臂控制系统能够根据机械臂的图像对机械臂进行控制,并且可以进一步地实现机械臂的抓取。而如果我们想对机械臂进行控制,首先就要知道机械臂各个关节的位置,即机械臂的姿态,因此机械臂的姿态估计对于机械臂控制系统的实现至关重要。
3.针对机械臂的姿态估计问题,目前主流的有三种方法。第一种方法:使用3d模型创建大量虚拟的数据,在此虚拟领域中训练视觉模型,并在领域自适应后应用于真实世界的图像。此外,其设计了一种半监督方法,该方法充分利用了关键点之间的几何约束,使用迭代算法进行优化。第二种方法:从单个图像估计机械臂姿态的方法,其使用深度神经网络来处理rgb图像来检测机械臂上的关键点,并且使用域随机化完全在模拟数据上进行网络的训练。第三种方法:使用机械臂的深度图像作为输入来直接估计角关节的位置。其使用了一个随机回归森林来进行估计,该模型使用合成生成的数据进行训练。
4.尽管上述方法的精度很高,但这些方法仍存在参数量和计算量过大等不足。这些方法往往通过牺牲模型效率来换取精度优势,精度越高的方法所需要的计算开销也越大。在云上部署这些高精度方法会很困难,庞大的参数量也限制了模型在资源受限设备(比如机器臂、手机等设备)上的部署。这些高精度方法需要巨大的计算开销和内存开销,严重阻碍了资源受限情况下的使用。
技术实现要素:
5.针对现有机械臂姿态估计方法中缺乏通用的模型轻量化方法以及轻量级模型会面临的性能退化问题,本发明构建了具有两个堆的堆叠沙漏网络,使用了一种全新的神经网络基本单元ghost模块来替代堆叠沙漏网络中的标准卷积,从而搭建出轻量级的机械臂姿态估计神经网络,即ghost-shn(ghost module-based stacked hourglass network)。本发明方法在保留模型泛化性能的前提下改善机械臂姿态估计模型的推理效率,使其在实际应用场景中更加可靠实用。
6.本发明为实现上述目的所采用的技术方案是:
7.一种基于轻量级堆叠沙漏网络的机械臂姿态估计方法,包括以下步骤:
8.采集机械臂的rgb图像,并对其进行预处理;
9.对基于ghost模块的堆叠沙漏网络ghost-shn进行训练;
10.将预处理后的rgb图像输入到ghost-shn中,得到多个关键点;
11.对关键点进行三维还原,预估出机械臂的各个转轴角度,完成机械臂姿态的估计。
12.所述对rgb图像进行预处理具体为:将rgb图像裁剪为设定尺寸。
13.所述对基于ghost模块的堆叠沙漏网络ghost-shn进行训练具体为:使用ghost模块替换堆叠沙漏网络中的卷积层,并对ghost-shn进行训练。
14.所述将预处理后的rgb图像输入到ghost-shn中,得到多个关键点具体为:
15.将每一个尺寸为256*256的rgb图像输入到ghost-shn中,得到若干个尺寸为64*64的热图,每个热图对应一个关键点。
16.所述关键点为用于确定机械臂姿态的二维点。
17.所述对关键点进行三维还原,预估出机械臂的各个转轴角度具体为:
18.将机械臂构建为一个多自由度的多刚体模型,使若干个关键点的位置满足几何约束关系;
19.通过透视投影预估出若干个关键点的三维坐标,得到机械臂的各个转轴角度。
20.所述几何约束关系包括:两个关键点之间的长度。
21.所述通过透视投影预估出若干个关键点的三维坐标具体为:
[0022][0023]
其中,y是关键点的二维坐标矩阵,z是关键点的三维坐标矩阵,1是全一向量,k是相机的内参矩阵,s是缩放向量,r是旋转矩阵,t是平移向量。
[0024]
本发明具有以下有益效果及优点:
[0025]
1.模型的参数量和计算量小,克服了机械臂姿态估计模型难以在机械臂等资源受限设备上部署的问题,便于机械臂姿态估计模型的部署。
[0026]
2.提升了机械臂姿态估计模型的泛化能力,姿态估计的误差比原有模型要小,即预测的机械臂的关节角度比原有模型误差要小。
附图说明
[0027]
图1为本发明方法整体流程图;
[0028]
图2为本发明方法的网络结构图;
[0029]
图3为本发明方法的关键点检测结果图;
[0030]
图4为本发明方法与其他方法参数量的对比图;
[0031]
图5为本发明方法与其他方法计算量的对比图。
具体实施方式
[0032]
下面结合附图及实施例对本发明做进一步的详细说明。
[0033]
一种基于轻量级堆叠沙漏网络的机械臂姿态估计方法,包括以下步骤:
[0034]
s1:输入的机械臂的rgb图像;
[0035]
s2:对图像预处理;
[0036]
s3:训练ghost-shn模型;
[0037]
s4:检测关键点;
[0038]
s5:估计三维姿态;
[0039]
s6:输出关节角度。
[0040]
所述对图像预处理,具体为:将输入机械臂的图像的大小裁剪为256
×
256。
[0041]
所述训练ghost-shn模型,具体为:在堆叠沙漏网络,即shn中使用ghost模块替代普通卷积。
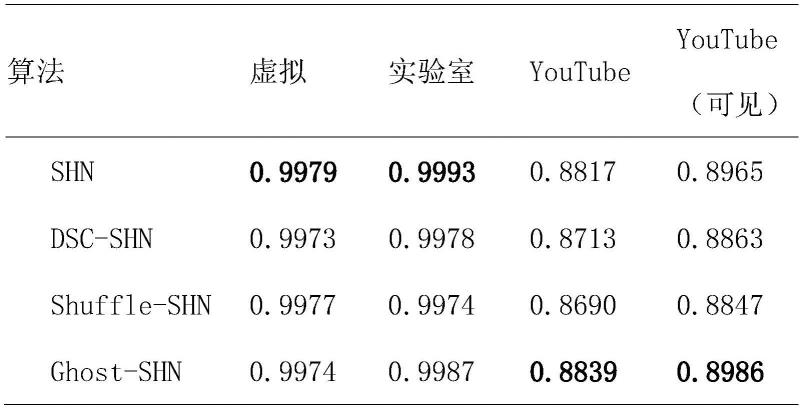
[0042]
将裁剪后的图像作为输入数据为其中,c
′
为输入数据的通道数,h
′
为输入数据的高度,w
′
为输入数据的宽度,我们可以使用一次卷积(primaryconvolution)来生成n个原始特征图,如式(1)所示。
[0043]y′
=x
′
*w
′ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)其中*是卷积运算,是卷积核,其中,d
×
d为每个线性运算的平均核大小,n≤m。是具有m个通道的输出特征图,其中,h
″
为输出特征图的高度,w
″
为输出特征图的宽度。
[0044]
ghost模块对y
′
中的每个原始特征使用线性运算来生成k个幻影特征图,具体计算过程如式(2)所示。
[0045][0046]
其中yi′
是y
′
中第i个原始特征图,g
i,j
是用于生成第j个幻影特征图y
i,j
的第j个线性运算(除了最后一个)。因此有k个幻影特征图。最后的g
i,k
是恒等映射,其用于保留原始特征图。通过线性运算,ghost模块输出了m=n
·
k个特征图y=[y
11
,y
12
,
…
,y
nk
]。因为线性运算g在每个通道上执行,所以其计算量比普通卷积少得多。
[0047]
ghost模块可以使用更少的参数来生成更多特征图,并且与普通卷积相比,在输出特征图大小不变的情况下,ghost模块中所需的参数量和计算量都有一定程度的减少。我们利用ghost模块替代普通卷积层,生成与普通卷积层相同数量的特征图,即得到了ghost-shn。
[0048]
接着,我们将预处理后的图像传送到具有两个堆的ghost-shn。在数据集上训练两层ghost-shn30个epoch。在模型训练时,本发明方法使用rmsprop优化器来优化网络,学习率为2.5
×
10-4
,损失函数为均方误差函数,每一批输入网络的样本个数为6。我们还使用了数据增强技术,对图片进行随机平移、旋转、缩放、色彩转换和翻转。
[0049]
所述检测关键点,具体为:我们将预处理后的图像传送到已经训练好的堆叠沙漏网络。网络生成了17个热图,每个热图的大小为64
×
64,对应着一个关键点。
[0050]
所述估计三维姿态,具体为:获取了二维关键点的位置后进行三维还原,将机械臂建模为一个4个自由度的多刚体模型,因此17个关键点的位置满足一定的几何约束关系(比如两个关节之间的长度)。在透视投影的假设下,每个关键点都是三维坐标的二维投影,因此我们可以写成如式(3)所示的方程:
[0051][0052]
其中y是二维坐标矩阵,z是三维坐标矩阵,1是全一向量,k是相机的内参矩阵,s是缩放向量,r是旋转矩阵,t是平移向量。
[0053]
我们通过解如式(3)所示的线性方程,就可以得到关键点的三维坐标,进一步地,我们可以根据几何约束关系来获得机械臂各转轴的角度。
[0054]
所述输出关节角度,具体为:输出四个关节的角度,也即各个转轴的角度。
[0055]
如图1所示,基于轻量级堆叠沙漏网络的机械臂姿态估计方法包括以下步骤:
[0056]
1:输入的机械臂的rgb图像;
[0057]
2:对图像进行预处理,将图片的大小裁剪为256
×
256;
[0058]
3:训练如图2所示的二维点估计神经网络ghost-shn模型;
[0059]
4:检测二维关键点;
[0060]
5:输出关键点的位置,如图3所示;
[0061]
6:估计三维姿态;
[0062]
7:输出关节角度。
[0063]
为了验证本发明方法的性能,我们在公开的机械臂姿态估计数据集上进行了实验。该公开数据集中有四个数据集。第一个数据集是虚拟数据集,该数据集里面有用虚幻引擎4生成的5000张虚拟图像。其中,4500张用于训练,其余500张用于验证。第二个数据集是实验室数据集,其中包含了720p摄像头拍摄的428张图片。第三个数据集是youtube数据集,其中的图片从youtube上抓取的。图片类型多样,图片中的机械臂甚至可能被修改,几何约束条件可能不完全成立。youtube数据集里面有275张图片,里面标注了每个2d关键点的可见性以及位置。第四个数据集是第三个数据集的子集,仅考虑youtube数据集中关键点可见的图片,我们称其为youtube(可见)数据集。
[0064]
为了验证本发明方法的有效性,我们还分别实现了基于深度可分离卷积的堆叠沙漏网络dsc-shn以及基于组卷积和通道重排的堆叠沙漏网络shuffle-shn。接着我们对本发明方法、shn、dsc-shn和shuffle-shn这四个算法的性能进行对比评估。
[0065]
为了评估2d关键点检测的效果,我们把预测关键点和真正的关键点之间的距离与阈值τ进行比较,如果在阈值τ内,就认为预测关键点是正确定位的关键点,并把正确定位的关键点的百分比(percentage ofcorrectkeypoints,pck)作为度量指标。针对本发明使用的数据集,我们令τ=0.2,即使用pck@0.2来衡量关键点检测的精度。
[0066]
表1四个数据集上的二维关键点检测正确率
[0067][0068]
本发明方法使用浮点运算量(floatingpointoperations,flops)来衡量模型的计算量。具体来说,实验中使用的是gflops,即109flops。
[0069]
如表1所示,本发明方法的泛化性能很好,其在youtube数据集和youtube(可见)数据集的准确性比shn还高。此外,如图4所示,shn的参数量是本发明的1.49倍。如图5所示,shn的计算量是本发明方法的1.42倍。虽然shuffle-shn的参数量和计算量比本发明方法更
小,但其在三个数据集上的精度都不如本发明方法高。这就是说,shuffle-shn虽然具有较低参数量与计算开销,但模型的泛化能力也同时发生了退化。而本发明方法提升了模型的泛化能力,其在准确率、参数量、计算量三者之间取得了一个较好的权衡。注意,由于我们事先将输入图像裁剪成256
×
256,所以同一个模型在四个数据集上的参数量和计算量都是一样的。
[0070]
我们还在真实图像上测试模型的3d姿态估计性能。我们仅针对实验室数据集得到定量的3d姿势估计结果,因为很难获得youtube数据集的3d标注。如表2所示,本发明方法在三个关节上的预测误差以及平均误差比shn小。
[0071]
表2实验室数据集上的三维姿态估计误差
[0072]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1