卷积神经网络模块的控制方法与流程
1.本发明涉及卷积神经网络领域,尤其涉及一种卷积神经网络模块的控制方法。
背景技术:
2.卷积神经网络(convolutional neural network,cnn)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。它主要包括卷积层(convolutional layer)和池化层(pooling layer)。卷积神经网络已广泛应用于图像分类、物体识别、目标追踪。
3.卷积神经网络计算可以通过如fpga(field
‑
programmable gate array,即现场可编程门阵列)、芯片等硬件为基础来实现。
4.在基于fpga硬件的神经网络计算中,张量卷积运算是使用最多的一种计算方式,主要有卷积、反卷、空洞、全连接等类型的算子,这类运算的计算核心位乘加运算,即先进行乘法运算然后将各个乘法运算结果进行累加。
5.目前,现有的张量卷积运算中,通常为先同时算出多个乘法运算的结果,然后同时对乘法运算结果进行累加,这样在累加运算中可以达到的运行速度有限,从而影响了整体的运行频率,进而使整个系统的计算能力受到限制。
技术实现要素:
6.本发明为了克服上述现有技术存在的缺陷,提供一种卷积神经网络模块的控制方法,以提高卷积计算速度,进而提高整个系统的计算能力。
7.根据本发明的一个方面,提供一种卷积神经网络模块的控制方法,所述卷积神经网络模块包括多个级联的卷积计算单元,每个卷积计算单元至少包括按顺序设置的第一乘法器、第二乘法器、第一加法器以及第二加法器,所述第一加法器连接至所述第一乘法器以及所述第二乘法器以将所述第一乘法器和第二乘法器的输出数据相加,所述第二加法器连接至所述第一加法器以及上一卷积计算单元的第二加法器,以将当前卷积计算单元的第一加法器和上一卷积计算单元的第二加法器的输出数据相加,所述控制方法包括:
8.使各所述卷积计算单元的第二乘法器相较于第一乘法器晚一个单倍频时钟节拍读取的通道数据,以使各所述卷积计算单元的第一乘法器和第二乘法器读取的相邻通道的通道数据在所述第一加法器的加法计算中对齐。
9.在本申请的一些实施例中,还包括:
10.使当前卷积计算单元的第一乘法器相较于上一卷积计算单元的第二乘法器晚一个单倍频时钟节拍读取的通道数据,以使当前卷积计算单元的第一加法器的输出数据与上一卷积计算单元的第二加法器的输出数据在当前卷积计算单元的第二加法器的加法计算中对齐。
11.在本申请的一些实施例中,所述卷积神经网络模块包括多个级联的行卷积计算单元,每个所述行卷积计算单元包括多个级联的所述卷积计算单元,所述控制方法还包括:
12.使当前行卷积计算单元的第一个卷积计算单元的第一乘法器相较于上一行卷积计算单元的最后一个卷积计算单元的第二乘法器晚一个单倍频时钟节拍读取的通道数据,以使当前行卷积计算单元的第一个卷积计算单元的第一加法器的输出数据与上一行卷积计算单元的最后一个卷积计算单元的输出数据在当前行卷积计算单元的第一个卷积计算单元的第二加法器的加法计算中对齐。
13.在本申请的一些实施例中,基于储存器的读使能的延迟以控制所述通道数据的读取的时钟节拍的延迟。
14.在本申请的一些实施例中,所述控制方法包括:
15.以单倍频时钟节拍读取通道数据,作为乘法器的一个输入,并以双倍频时钟节拍交替读取第一权重数据和第二权重数据,作为乘法器的另一个输入;
16.于所述乘法器的输出端获得所述通道数据和所述第一权重数据的第一卷积结果以及所述通道数据和所述第二权重数据的第二卷积结果。
17.在本申请的一些实施例中,所述以单倍频时钟节拍读取通道数据,作为乘法器的一个输入,并以双倍频时钟节拍交替读取第一权重数据和第二权重数据,作为乘法器的另一个输入包括:
18.提供基于单倍频时钟节拍的通道数据、第一权重数据以及第二权重数据的信号;
19.以两倍频时钟节拍采集基于单倍频时钟节拍的通道数据、第一权重数据以及第二权重数据的信号;
20.基于权重数据选择信号,合并基于两倍频时钟节拍第一权重数据以及第二权重数据的信号。
21.在本申请的一些实施例中,所述于所述乘法器的输出端获得所述通道数据和所述第一权重数据的第一卷积结果以及所述通道数据和所述第二权重数据的第二卷积结果包括:
22.于所述乘法器的输出端获得基于两倍频时钟节拍的卷积结果信号;
23.基于卷积结果选择信号,将所述卷积结果信号拆分为基于单倍频时钟节拍的所述通道数据和所述第一权重数据的第一卷积结果以及所述通道数据和所述第二权重数据的第二卷积结果。
24.在本申请的一些实施例中,基于卷积结果选择信号,将所述卷积结果信号拆分为基于单倍频时钟节拍的所述通道数据和所述第一权重数据的第一卷积结果以及所述通道数据和所述第二权重数据的第二卷积结果还包括:
25.使得基于单倍频时钟节拍的所述通道数据和所述第一权重数据的第一卷积结果以及所述通道数据和所述第二权重数据的第二卷积结果在单倍频时钟节拍上对齐。
26.在本申请的一些实施例中,所述卷积计算单元基于数字信号处理芯片实现。
27.在本申请的一些实施例中,卷积神经网络模块基于现场可编程门阵列实现。
28.相比现有技术,本发明的优势在于:
29.本发明提供的卷积神经网络模块采用卷积计算单元级联的方式对多个相乘的结果进行相加,前一个卷积计算单元的结果级联输出到后一个卷积计算单元的级联输入,通过控制每个乘法器的输入节拍来实现流水线控制以及数据计算的对齐。本发明可以最大限度的使用卷积计算单元级联,使乘法器的运行速度达到400mhz以上,提升整个系统的计算
能力。
附图说明
30.通过参照附图详细描述其示例实施方式,本发明的上述和其它特征及优点将变得更加明显。
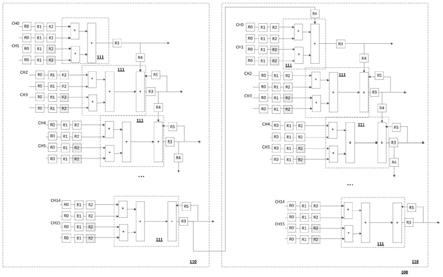
31.图1示出了根据本发明实施例的卷积神经网络模块的示意图;
32.图2示出了根据本发明实施例的卷积神经网络模块的时序意图;
33.图3示出了根据本发明实施例的双倍频时钟节拍的控制时序图。
具体实施方式
34.现在将参考附图更全面地描述示例实施方式。然而,示例实施方式能够以多种形式实施,且不应被理解为限于在此阐述的范例;相反,提供这些实施方式使得本公开将更加全面和完整,并将示例实施方式的构思全面地传达给本领域的技术人员。所描述的特征、结构或特性可以以任何合适的方式结合在一个或更多实施方式中。
35.此外,附图仅为本公开的示意性图解,并非一定是按比例绘制。图中相同的附图标记表示相同或类似的部分,因而将省略对它们的重复描述。附图中所示的一些方框图是功能实体,不一定必须与物理或逻辑上独立的实体相对应。可以采用软件形式来实现这些功能实体,或在一个或多个硬件模块或集成电路中实现这些功能实体,或在不同网络和/或处理器装置和/或微控制器装置中实现这些功能实体。
36.为了解决现有技术中的缺陷,本发明提供一种卷积神经网络模块的控制方法。下面将结合图1至3说明本发明提供的控制方法的具体实现。
37.本发明所应用的卷积神经网络模块100包括多个级联的卷积计算单元111。每个卷积计算单元111至少包括按顺序设置的第一乘法器(如图中示出的位于上方的乘法器)、第二乘法器(如图中示出的位于下方的乘法器)、第一加法器(如图中示出与乘法器相连的加法器)以及第二加法器(如图中示出与加法器相连的加法器)。图中仅仅是示意性地示出乘法器和加法器,实际的硬件布置位置并非以此为限制。其中,所述第一加法器连接至所述第一乘法器以及所述第二乘法器以将所述第一乘法器和第二乘法器的输出数据相加。所述第二加法器连接至所述第一加法器以及上一卷积计算单元111的第二加法器,以将当前卷积计算单元111的第一加法器和上一卷积计算单元111的第二加法器的输出数据相加。
38.进一步地,所述卷积神经网络模块100包括多个级联的行卷积计算单元110。每个所述行卷积计算单元110用于计算一行特征图像的多个通道的特征数据。每个所述行卷积计算单元110包括多个级联的所述卷积计算单元111。
39.在本实施例中,每个行卷积计算单元110的第一个卷积计算单元111可以仅包括一个加法器。在一些变化例中,每个行卷积计算单元110的第一个卷积计算单元111可以包括两个加法器,但第二个加法器可以处于非工作状态,不参与计算。
40.具体而言,所述卷积计算单元111基于数字信号处理芯片实现。所述卷积神经网络模块100基于现场可编程门阵列实现。
41.以上仅仅是示意性地描述本发明的控制方法所应用的卷积神经网络模型100的具体结构,但本发明并非以此为限制,行卷积计算单元110的数量、卷积计算单元111的数量,
以及级联的连接方式可以按需设置,本发明并非以此为限制。
42.具体而言,本发明的控制方法包括:使各所述卷积计算单元111的第二乘法器相较于第一乘法器晚一个单倍频时钟节拍读取的通道数据,以使各所述卷积计算单元111的第一乘法器和第二乘法器读取的相邻通道的通道数据在所述第一加法器的加法计算中对齐。具体而言,一个单倍频时钟节拍为乘法器、加法器执行一次运算所需的时间。
43.如图1所示,乘法器输入处的r0、r1、r2为读取通道数据的单倍频时钟节拍,为了使同一的卷积计算单元111的第一乘法器从第一通道(ch0)读取的通道数据和第二乘法器从第二通道(ch1)读取的通道数据对齐,由此,使得第二乘法器比第一乘法器晚一个单倍频时钟节拍读取的通道数据(在图中示意为第二乘法器的输入端的r2不读取数据)。
44.具体而言,本发明的控制方法还包括:使当前卷积计算单元111的第一乘法器相较于上一卷积计算单元111的第二乘法器晚一个单倍频时钟节拍读取的通道数据,以使当前卷积计算单元111的第一加法器的输出数据与上一卷积计算单元111的第二加法器的输出数据在当前卷积计算单元111的第二加法器的加法计算中对齐。
45.为了能够直观地表示相邻卷积计算单元111的读取通道数据的时钟节拍延迟,图1以卷积计算单元111右移的方式示出。如图1所示,左侧的行卷积计算单元110的第二个卷积计算单元111相对于第一个卷积计算单元111右移一个单倍频时钟节拍,由此,第二个卷积计算单元111的第一乘法器相对于第一个卷积计算单元111的第二乘法器晚一个单倍频时钟节拍来读取读取的通道数据,从而使得第一个卷积计算单元111的第一通道和第二通道的通道数据经经过乘加计算后的输出数据正好与第二个卷积计算单元111的第三通道和第四通道的对应的通道数据经过乘加计算后的输出数据在同一时刻进入第二个卷积计算单元111的第二加法器,以执行加法计算。以此类推,从而实现乘加计算数据对齐和流水线控制。
46.具体而言,本发明的控制方法还包括:使当前行卷积计算单元110的第一个卷积计算单元111的第一乘法器相较于上一行卷积计算单元110的最后一个卷积计算单元111的第二乘法器晚一个单倍频时钟节拍读取的通道数据,以使当前行卷积计算单元110的第一个卷积计算单元111的第一加法器的输出数据与上一行卷积计算单元110的最后一个卷积计算单元111的输出数据在当前行卷积计算单元110的第一个卷积计算单元111的第二加法器的加法计算中对齐。其实现方式与相邻卷积计算单元111的通道数据的读取延迟类似,在此不予赘述。
47.进一步地,上述实施例各行的各通道数据的单倍频时钟节拍的时钟信号可以参见图2所示。具体而言,本申请可以基于储存器的读使能的延迟以控制所述通道数据的读取的时钟节拍的延迟。储存器例如可以是随机存取存储器(random access memory,ram),本发明并非以此为限制。
48.在本申请的又一些实施例中,所述控制方法还可以包括:以单倍频时钟节拍读取通道数据,作为乘法器的一个输入,并以双倍频时钟节拍交替读取第一权重数据和第二权重数据,作为乘法器的另一个输入;于所述乘法器的输出端获得所述通道数据和所述第一权重数据的第一卷积结果以及所述通道数据和所述第二权重数据的第二卷积结果。具体控制的实现可以参见图3。
49.如图3所示,图3示出了根据本发明实施例的双倍频时钟节拍的控制时序图。
50.图3中,clk为单倍频时钟节拍的时钟信号,clk2x为双倍频时钟节拍的时钟信号。data_valid为数据有效信号,仅在data_valid高电平时,读取的通道数据(特征数据才有效)。feature_data为单倍频时钟节拍的时钟信号下的通道数据(特征数据);weights_a为单倍频时钟节拍的时钟信号下的第一权重数据;weights_b为单倍频时钟节拍的时钟信号下的第二权重数据。由于单倍频时钟节拍的时钟信号与双倍频时钟节拍的时钟信号跨时钟域,因此,首先需要将data_valid、feature_data、weights_a、weights_b转换为双倍频时钟节拍的时钟信号下的数据。由此,通过在双倍频时钟节拍的时钟信号下采集data_valid、feature_data、weights_a、weights_b,从而分别获得data_valid_2x、feature_data_2x、weights_a_2x、weights_b_2x。然后基于一权重选择信号weights_a_b_sel,以在高低电平分别交替选择weights_a_2x和weights_b_2x从而合并weights_a_2x和weights_b_2x,获得weights_a_b_2x。同时,还使得feature_data_2x与weights_a_b_2x对齐,以获得feature_data_2x_dl信号。通过将feature_data_2x_dl和weights_a_b_2x分别按双倍频时钟节拍的时钟信号输入到乘法器的两个输入端,以获得乘法器输出的卷积结果result_a_b_2x。此时,为了将result_a_b_2x转换到单倍频时钟节拍的时钟信号下,且将两个卷积结果分离,因此,通过一基于卷积结果选择信号result_a_b_sel以在高低电平分别交替选择result_a_b_2x中的两个卷积结果,以将result_a_b_2x拆分获得result_a_2x和result_b_2x。同时,为了使得卷积结果对齐,需要将result_a_2x进行延迟,从而获得result_a_2x_dl。最后,以单倍频时钟节拍的时钟信号采集result_a_2x_dl和result_b_2x,从而获得单倍频时钟节拍的时钟信号下的第一卷积结果result_a和第二卷积结果result_b。
51.由此实现,卷积计算的倍频处理,进一步提高卷积计算速度和计算效率。
52.以上仅仅是示意性的描述本发明提供的多个实施方式,本发明并非以此为限制。
53.相比现有技术,本发明的优势在于:
54.本发明提供的卷积神经网络模块采用卷积计算单元级联的方式对多个相乘的结果进行相加,前一个卷积计算单元的结果级联输出到后一个卷积计算单元的级联输入,通过控制每个乘法器的输入节拍来实现流水线控制以及数据计算的对齐。本发明可以最大限度的使用卷积计算单元级联,使乘法器的运行速度达到400mhz以上,提升整个系统的计算能力。
55.本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本公开的其它实施方案。本申请旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由所附的权利要求指出。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1