一种基于图像结构信息的OCR数据合成方法
本发明涉及光学字符识别领域的相关问题,具体涉及一种基于图像结构信息的ocr数据合成方法。
背景技术:
ocr领域主要有两种方法:基于传统算法的ocr方法与基于深度学习的ocr方法。基于深度学习ocr方法无论是准确率还是鲁棒性都大大优于基于传统算法的ocr方法。但前者的准确率非常依赖于大批量的训练样本,而仅仅通过人工标注数据来获得训练样本是不够的,因为ocr需要的数据至少是百万级别的,完全靠人为标注是不现实的。
另外ocr对训练样本的丰富性要求很高,而目前的一般ocr数据合成方法都是在背景图像上直接嵌入文字,不能充分利用背景图像的三维空间信息以及结构信息,导致合成出来的图像不逼真。
技术实现要素:
本发明克服了现有技术的不足之处,提供一种基于图像结构信息的的ocr数据合成方法,以期能充分利用背景图像的结构信息来合成海量逼真的文本图像数据,从而提升文本检测与识别模型的准确率与鲁棒性。
本发明为达到上述发明目的,采用如下技术方案:
本发明一种基于图像结构信息的ocr数据合成方法的特点在于,包括以下步骤:
步骤1:收集自然场景图像,用于建立图像背景库;
步骤2:构建图像结构信息预测网络sn,包括:编码模块encoder,快速特征融合模块fm,结构预测模块decoder;
所述编码模块encoder,包含:4n个卷积层,n个最大池化层;
所述快速特征融合模块fm,包含4个卷积层,4个上采样层;
所述结构预测模块decoder,包含3a个卷积层;
步骤3:将图像背景库中的每一张背景图片均输入图像结构信息预测网络sn中进行预测,得到对应的结构信息;
步骤3.1:将一张背景图片x送入编码模块encoder中,每经过n层卷积后再经过一个最大池化层的下采样处理,从而经过4n个卷积层以及n个最大池化层处理后,得到四组特征图f1、f2、f3、f4,尺寸分别为
步骤3.2:将四组特征图f1、f2、f3、f4送入快速特征融合模块fm中,从而利用式(1)-(5)进行快速的特征融合,得到多种尺度的融合特征ffuse:
ffuse=conv(f1up)(1)
式(1)中:conv表示卷积层操作,f1up表示第二组特征图f2与第一组特征图f1的融合特征,并有:
f1up=up(f2up)+conv(f1)(2)
式(2)中:up表示上采样层操作;f2up表示第三组特征图f3与第二组特征图f2的融合特征,并有:
f2up=up(f3up)+conv(f2)(3)
式(3)中:f3up表示第三组特征图f3与第四组特征图f4的融合特征,并有:
f3up=f4up+conv(f3)(4)
式(4)中:f4up表示对第四组特征图f4进行上采样之后的特征,并有:
f4up=up(f4)(5)
步骤3.3:将融合特征ffuse送入结构预测模块decoder中,从而利用式(6)-式(8)进行解码,分别得到语义分割图segx、深度估计图depthx、边缘检测图edagex并作为结构信息:
segx=conva1(ffuse)(6)
depthx=conva2(ffuse)(7)
edagex=conva3(ffuse)(8)
式(6)-式(8)中:conva1、conva2、conva3表示分别表示三个a次卷积操作;
步骤4:在背景图片x中找到一个嵌入文字的区域;
根据语义分割图segx中每一类别对应的区域,使用泛洪填充算法对边缘检测图edagex进行处理,得到边缘内的连续区域;将每一类别对应的区域与连续区域进行合并处理,从而得到嵌入文字的区域;
步骤5:估计三维空间信息:
首先根据深度估计图depthx计算背景图片x上每一个像素点的三维坐标;然后根据背景图片x上的每一个连续区域的所有像素点的三维坐标,计算对应的三维平面的信息;最后计算一个水平面分别映射到的每一个连续区域所对应的三维平面的单应性矩阵;
步骤6:建立前景背景颜色库:
通过聚类算法对背景图片x中的每个像素的颜色进行聚类,得到两个聚类中心,分别代表前景颜色与文字颜色;
对外部的文本识别数据集中的每张文本图片进行聚类,得到前景背景颜色库;
步骤7:将文字嵌入到背景图像x:
对一个嵌入文字的区域对应的背景颜色进行统计,并从前景背景颜色库中选择与统计出的背景颜色对应的前景文字的颜色;
随机选择一个字体与文本串,用于绘制前景文字图片,并根据嵌入文字区域的单应性矩阵对所述前景文字图片进行透视变换,再将透视后的前景文字图片与背景图片x进行泊松融合,得到最终的合成的文本图片。
与现有技术相比,本发明的有益效果在于:
1、本发明通过在背景图像上嵌入文字,可以快速合成海量逼真的数据,这些数据可以代替人工标注的数据来训练ocr网络,大大减少了人工标注的人力物力,并且可以增加ocr网络的准确率与鲁棒性。
2、本发明充分利用了背景图像的结构信息来找到合适的位置来嵌入文字,因此嵌入的文字能与背景图像较为和谐的融合在一起,从而大大提高了合成图像的真实性。
3、本发明提出的数据合成方法可以保证每一类文字的频率较为均衡,解决了真实数据类别不均衡的问题,也因此可以提高网络对那些出现频率较低的文字的识别率。
附图说明
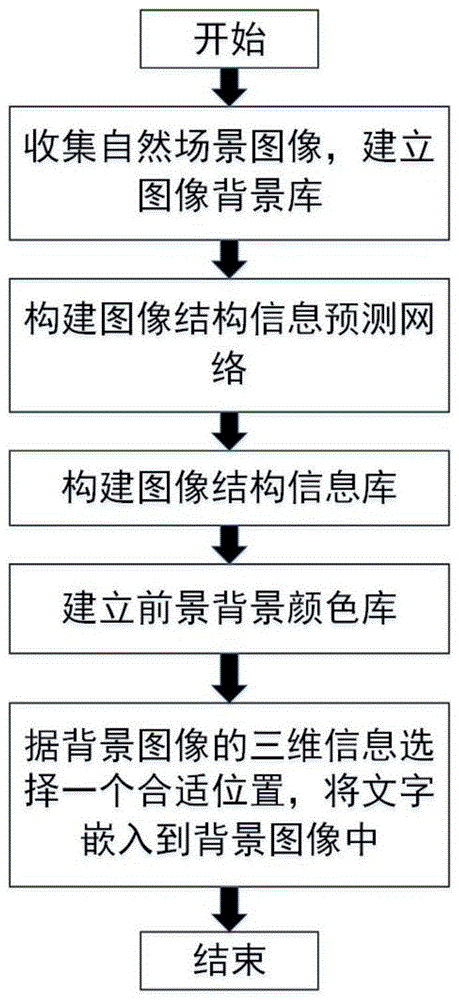
图1是本发明基于图像结构信息的ocr数据合成方法的使用流程图;
图2是本发明基于图像结构信息的ocr数据合成方法的网络结构图。
具体实施方式
本实施例中,如图1所示,一种基于图像结构信息的的ocr数据合成方法,包括以下步骤:
步骤1:收集自然场景图像,用于建立图像背景库;
步骤2:构建图像结构信息预测网络sn,包括:编码模块encoder,快速特征融合模块fm,结构预测模块decoder;
编码模块encoder,包含:4n个卷积层,n个最大池化层;
快速特征融合模块fm,包含4个卷积层,4个上采样层;
结构预测模块decoder,包含3a个卷积层;
步骤3:如图2所示;将图像背景库中的每一张背景图片均输入图像结构信息预测网络sn中进行预测,得到对应的结构信息;
步骤3.1:将一张背景图片x送入编码模块encoder中,每经过n层卷积后再经过一个最大池化层的下采样处理,从而经过4n个卷积层以及n个最大池化层处理后,得到四组特征图f1、f2、f3、f4,尺寸分别为
步骤3.2:将四组特征图f1、f2、f3、f4送入快速特征融合模块fm中,从而利用式(1)-(5)进行快速的特征融合,得到多种尺度的融合特征ffuse:
ffuse=conv(f1up)(1)
式(1)中:conv表示卷积层操作,f1up表示第二组特征图f2与第一组特征图f1的融合特征,并有:
f1up=up(f2up)+conv(f1)(2)
式(2)中:up表示上采样层操作;f2up表示第三组特征图f3与第二组特征图f2的融合特征,并有:
f2up=up(f3up)+conv(f2)(3)
式(3)中:f3up表示第三组特征图f3与第四组特征图f4的融合特征,并有:
f3up=f4up+conv(f3)(4)
式(4)中:f4up表示对第四组特征图f4进行上采样之后的特征,并有:
f4up=up(f4)(5)
步骤3.3:将融合特征ffuse送入结构预测模块decoder中,从而利用式(6)-式(8)进行解码,分别得到语义分割图segx、深度估计图depthx、边缘检测图edagex并作为结构信息:
segx=conva1(ffuse)(6)
depthx=conva2(ffuse)(7)
edagex=conva3(ffuse)(8)
式(6)-式(8)中:conva1、conva2、conva3表示分别表示三个a次卷积操作;
步骤4:在背景图片x中找到一个嵌入文字的区域;
根据语义分割图segx中每一类别对应的区域,使用泛洪填充算法对边缘检测图edagex进行处理,得到边缘内的连续区域;将每一类别对应的区域与连续区域进行合并处理,从而得到嵌入文字的区域;
步骤5:估计三维空间信息:
首先根据深度估计图depthx将背景图片x上的每一个像素赋予一个三维坐标,即将每一个像素对应的深度信息作为z方向的坐标,每一个像素的二维平面位置作为x与y方向的坐标,如此就可得到对应的三维空间坐标计算背景图片x上每一个像素点的三维坐标;然后根据背景图片x上的每一个连续区域的所有像素点的三维坐标,利用最小二乘法计算对应的三维平面的信息;最后计算一个水平面分别映射到的每一个连续区域所对应的三维平面的单应性矩阵;
步骤6:建立前景背景颜色库:
因为文本识别数据集中只存在文字与背景,即可以近似认为图片只存在两种主导颜色,一种是背景的颜色,一种是文字的颜色。因此可以通过聚类算法对背景图片x中的每个像素的颜色进行聚类,得到两个聚类中心,分别代表前景颜色与文字颜色;
对外部的文本识别数据集中的每张文本图片进行聚类,得到前景背景颜色库;
步骤7:将文字嵌入到背景图像x:
首先遍历之前统计得到的每一个嵌入文字区域,并计算对应的最小外接矩形,判断最小外接矩形的宽度与高度是否大于32,如果大于32则表示此区域可以用来嵌入文本,反之则忽略此区域。然后对一个嵌入文字的区域对应的背景颜色进行统计,并从前景背景颜色库中选择与统计出的背景颜色对应的前景文字的颜色;
随机选择一个字体与文本串,用于绘制前景文字图片。为了保证前景文字图片的几何形状与背景相吻合,根据嵌入文字区域的单应性矩阵对前景文字图片进行透视变换,再将透视后的前景文字图片与背景图片x进行泊松融合,得到最终的合成的文本图片。
- 还没有人留言评论。精彩留言会获得点赞!