一种使用网络爬虫技术获取安全设备数据信息的方法与流程
【技术领域】
本发明属于计算机软件技术领域,尤其涉及一种使用网络爬虫技术获取安全设备数据信息的方法。
背景技术:
网络爬虫作为在网络中很常见的用于爬取网络信息的工具,但是某些网站对网络爬虫做了限制,需要进行身份认证才能信息采集,如果使用网络爬虫直接对此类网站进行采集,得到的通常是用户信息认证失败后跳转到的用户登录页面,而不是实际想要采集的页面内容,当我们想要绕过身份登录认证来爬取我们所需要的数据时,现有通过提供无需登录验证的接口,但是这需要二次开发对接系统,是很难实现的。
技术实现要素:
本发明提出了一种使用网络爬虫技术获取安全设备数据信息的方法,目的在于解决现有使用网络爬虫需要进行身份认证才能进行信息采集的问题。
本发明由以下技术方案实现的:
一种使用网络爬虫技术获取安全设备数据信息的方法,包括如下步骤:
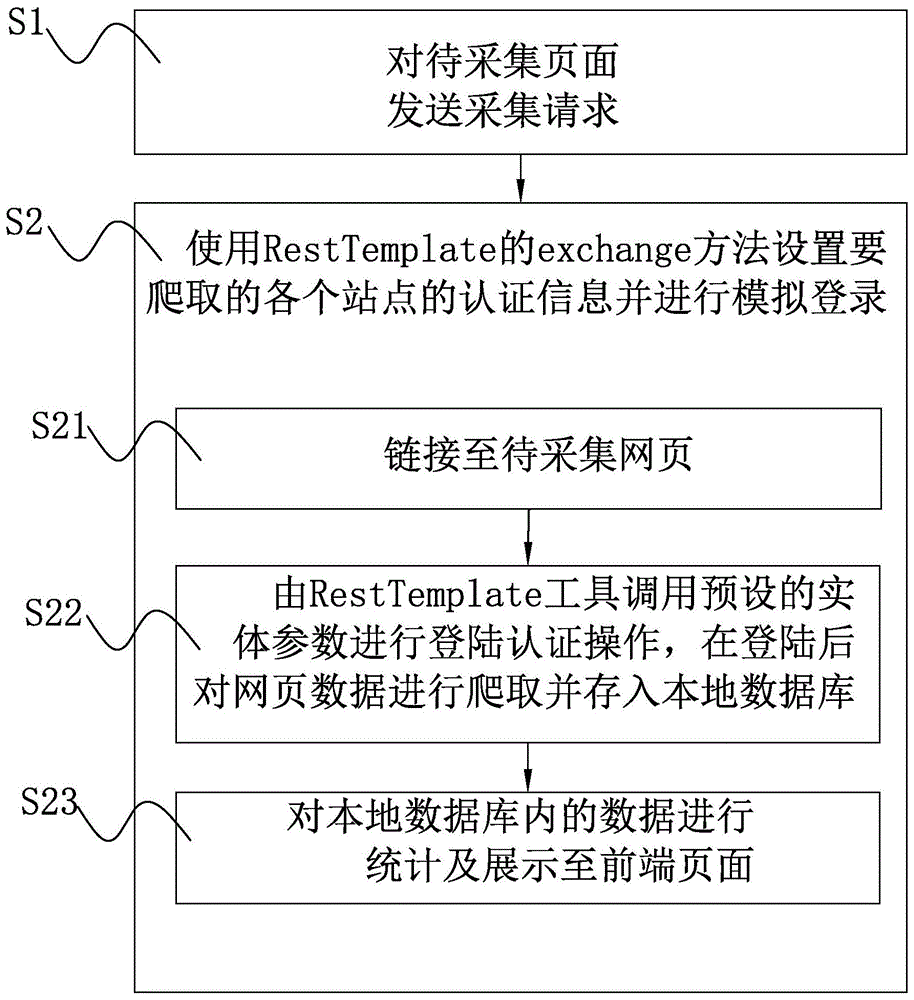
步骤s1,对待采集页面发送采集请求;
步骤s2,使用resttemplate工具中的exchange方法设置待采集网页的登陆相关的实体参数,然后通过resttemplate工具链接网页并进行模拟登陆,其中包括以下操作:
步骤s21,链接至待采集网页;
步骤s22,由resttemplate工具调用预设的实体参数进行登陆认证操作,在登陆后对网页数据进行爬取并存入本地数据库;
步骤s23,对本地数据库内的数据进行统计及展示至前端页面。
如上所述的一种使用网络爬虫技术获取安全设备数据信息的方法,在步骤s22中,完成模拟登陆后将实体参数写入于浏览器的cookie中,并将cookie记录至httpheaders变量。
如上所述的一种使用网络爬虫技术获取安全设备数据信息的方法,通过resttemplate工具模拟登陆绕过认证限制,再通过爬虫技术对链接的页面进行信息爬取,对网页数据进行清洗以获取到需要的原始数据。
如上所述的一种使用网络爬虫技术获取安全设备数据信息的方法,在步骤s22中执行下以步骤:
网络爬虫调用浏览器访问网页api,将要访问的网站登录地址传给浏览器;
浏览器加载网站登录网页,网络爬虫调用浏览器的获取网页api,并获得网页的html内容;
网络爬虫分析获得的html内容查找登录相关的实体参数,调用浏览器的提交表单api,将验证信息提交给网站验证;
提交的验证信息认证成功后,网络爬虫调用浏览器获得cookie接口,通过cookie接口取得该站点的cookie信息并保存。
如上所述的一种使用网络爬虫技术获取安全设备数据信息的方法,在步骤s22中,发送http请求访问站点,并在http请求中设置取得的cookie信息,在cookie失效前免登陆访问站点,爬取站点网页数据。
如上所述的一种使用网络爬虫技术获取安全设备数据信息的方法,所述登录相关的实体参数包括用户名和密码。
与现有技术相比,本发明有如下优点:
本发明提供了一种使用网络爬虫技术获取安全设备数据信息的方法,首先对待采集页面发送采集请求,再使用resttemplate工具中的exchange方法设置待采集网页的登陆相关的实体参数,然后通过resttemplate工具链接网页并进行模拟登陆,链接至待采集网页,由resttemplate工具调用预设的实体参数进行登陆认证操作,在登陆后对网页数据进行爬取并存入本地数据库,最后对本地数据库内的数据进行统计及展示至前端页面,通过这种方式绕过身份认证限制,通过爬虫技术,无需进行身份登录认证即可爬取我们想要的数据信息,避免了人工参与的弊端,且无需通过二次开发得到登录验证的接口,减少开发工作量,降低成本。
【附图说明】
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍。
图1为本发明的方法流程示意图。
【具体实施方式】
为了使本发明所解决的技术问题、技术方案及有益效果更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
当本发明实施例提及“第一”、“第二”等序数词时,除非根据上下文其确实表达顺序之意,应当理解为仅仅是起区分之用。
在本发明的描述中,需要说明的是,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
具体实施例,如图1所示的一种使用网络爬虫技术获取安全设备数据信息的方法,包括如下步骤:
步骤s1,对待采集页面发送采集请求;
步骤s2,使用resttemplate工具中的exchange方法设置待采集网页的登陆相关的实体参数,然后通过resttemplate工具链接网页并进行模拟登陆,其中包括以下操作:
步骤s21,链接至待采集网页;
步骤s22,由resttemplate工具调用预设的实体参数进行登陆认证操作,在登陆后对网页数据进行爬取并存入本地数据库;
步骤s23,对本地数据库内的数据进行统计及展示至前端页面。在spring应用程序中访问第三方rest服务与使用springresttemplate类有关。resttemplate类的设计原则与许多其他spring相关的模板类,例如jdbctemplate、jmstemplate相同,为执行复杂任务提供了一种具有默认行为的简化方法。resttemplate默认依赖jdk提供http连接的能力,例如httpurlconnection,如果有需要的话也可以通过setrequestfactory方法替换为例如apachehttpcomponents、netty或okhttp等其它httplibrary。resttemplate是spring提供的用于访问rest服务的客户端,resttemplate提供了多种便捷访问远程http服务的方法,相比传统的apache的httpclient客户端更加简单便捷,采用resttemplate能够大大提高客户端的编写效率。通过spring框架提供的resttemplate,可用于在应用中调用rest服务,它简化了与http服务的通信方式,统一了restful的标准,封装了http链接,我们只需要传入url及返回值类型即可。
具体地,在步骤s22中,完成模拟登陆后将实体参数写入于浏览器的cookie中,并将cookie记录至httpheaders变量;
更具体地,通过resttemplate工具模拟登陆绕过认证限制,再通过爬虫技术对链接的页面进行信息爬取,对网页数据进行清洗以获取到需要的原始数据;
进一步地,在步骤s22中执行下以步骤:
网络爬虫调用浏览器访问网页api,将要访问的网站登录地址传给浏览器;
浏览器加载网站登录网页,网络爬虫调用浏览器的获取网页api,并获得网页的html内容;
网络爬虫分析获得的html内容查找登录相关的实体参数,调用浏览器的提交表单api,将验证信息提交给网站验证;
提交的验证信息认证成功后,网络爬虫调用浏览器获得cookie接口,通过cookie接口取得该站点的cookie信息并保存。
更进一步地,在步骤s22中,发送http请求访问站点,并在http请求中设置取得的cookie信息,在cookie失效前免登陆访问站点,爬取站点网页数据。
具体地,所述登录相关的实体参数包括用户名、密码、秘钥、身份证等。
本发明一种使用网络爬虫技术获取安全设备数据信息的方法,首先对待采集页面发送采集请求,再使用resttemplate工具中的exchange方法设置待采集网页的登陆相关的实体参数,然后通过resttemplate工具链接网页并进行模拟登陆,链接至待采集网页,由resttemplate工具调用预设的实体参数进行登陆认证操作,在登陆后对网页数据进行爬取并存入本地数据库,最后对本地数据库内的数据进行统计及展示至前端页面,通过这种方式绕过身份认证限制,通过爬虫技术,无需进行身份登录认证即可爬取我们想要的数据信息,避免了人工参与的弊端,且无需通过二次开发得到登录验证的接口,减少开发工作量,降低成本。
如上所述是结合具体内容提供的一种实施方式,并不认定本发明的具体实施只局限于这些说明,同时由于行业命名不一样,本发明不限于以上命名,不限于英文命名。凡与本发明的方法、结构等近似、雷同,或是对于本发明构思前提下做出若干技术推演或替换,都应当视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!