基于地物光谱库的内蒙古草原植物物种分类
1.本发明是关于一种基于地物光谱库的内蒙古草原植物物种分类方法,属于光谱分类技术领域。
背景技术:
2.草地是陆地生态系统的重要组成部分,具有调节气候、涵养水源、防风固沙、生物多样性保育、初级生产力和碳固持等极其重要的生态服务功能,同时也为包括维管植物、鸟类、大型哺乳动物和土壤微生物在内的生物多样性提供了栖息地。我国是世界草地资源大国,拥有草地总面积近4亿公顷,占国土总面积的41.7%。据不完全统计,全国草地植物共计254科、4000多属、9700多种。其中,有毒植物52科、138属、316种。然而,受长期过度放牧、开垦、气候变化、环境污染以及生物入侵等因素的影响,我国草地生物多样性明显降低,进而引起草地生态系统功能和功能下降。因此,加强对草地生物多样性的监测与评估,对草地生物多样性保护政策的制定和草地生态系统适应性管理至关重要。草地物种的识别与分类是草地生态系统生物多样性监测的基础,因此如何对草地物种进行准确分类是开展草地生态系统保护和恢复的重要一步。
3.传统的草地生物多样性监测以地面调查和定点台站监测为主,多立足于物种水平的局地尺度机理研究,区域空间代表性和时间连续性差,且耗时耗力,对热、高、寒等人力难以到达的区域难以获得实地调查数据。卫星遥感具有探测范围广、获取数据周期性短、动态性强等优势,有助于迅速地揭示大面积生物多样性丢失状况,而且是以连续的、无边界的、可重复的方式展现,非常适用于不同时间与空间尺度的生物多样性监测。在近些年,遥感技术被越来越多地用于植物物种识别领域。高光谱数据包含几十个或几百个连续的波段,这些波段中有很多与植物功能特征相关的光谱特征,较适合用于植物物种的识别与分类。
4.在高光谱数据的分类中,机器学习是较为常用的方法,但是高光谱数据的高维性和多重共线性可能会降低该类方法分类模型的精度,因此如何降低数据冗余是需要解决的一个关键问题。huan yu等指出特征提取是降低数据冗余的一个有效方法,而数据的降维和植被指数提取是在特征提取中常用的两种策略。除高维特征冗余外,物种种间的光谱数量不平衡是导致分类结果不准确的另一个原因。在实际野外光谱采集中,稀有物种所得的光谱数量很少,甚至与常见物种所得光谱数量差距在两个数量级以上,由于机器学习算法的偏向性会导致稀有物种有极大的概率被识别为常见物种,从而降低了物种分类的精度。
技术实现要素:
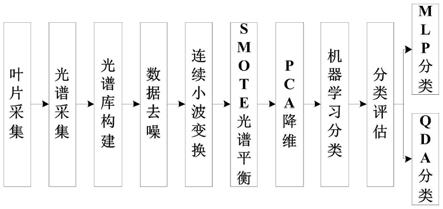
5.为了解决上述技术问题,本发明提供一种基于地物光谱库的内蒙古草原植物物种分类,由以下具体技术手段所达成:一种基于地物光谱库的内蒙古草原植物物种分类方法,包括以下步骤:
6.s1:草原植物物种光谱库的构建,包括野外叶片样本的采集和室内叶片光谱测量;
7.s2:地物光谱库预处理,包括数据去噪,连续小波变换光谱特征增强,smote算法光
谱平衡和pca光谱降维四个步骤;
8.s3:mlp算法对预处理后的地物光谱库进行分类。
9.进一步的,所述草原植物物种光谱库的构建,包含叶片采集和光谱测量,构建出一个大型的包含120个物种总计29212条光谱数据的光谱库,叶片样本采集:在内蒙古锡林郭勒盟根据环境梯度选取采样地点,然后采集不同草地物种放于冷藏箱冷藏,以用于室内光谱测量。室内叶片光谱测量:基于asd地物光谱仪对冷藏箱的叶片按照操作规范进行光谱测量,并保证测量精度和光谱数据多样性。
10.进一步的,所述地物光谱库预处理,包括数据去噪,连续小波变换光谱特征增强,smote算法光谱平衡和pca光谱降维,地物光谱库预处理,包括数据去噪,连续小波变换光谱特征增强,smote算法光谱平衡和pca光谱降维四个步骤。数据去噪包括删减边缘光谱减小系统误差和使用savitzky
‑
golay滤波过滤噪声。连续小波变换用于去噪和特征增强。
11.进一步的,所述smote算法,以光谱数量最多的物种为参照,将其他物种的光谱数量均扩展最多物种的数量,针对常见种和稀有种种间光谱数据数量不平衡的问题,本发明使用smote算法进行数据平衡。以光谱数量最多的物种为参照,将其他物种的光谱数量均扩展最多物种的数量。pca光谱降维是一种较为常见的数据降维方法,可有效降低数据冗余提高运算速度。需要设定两个参数:n_components和svd_solver。
12.进一步的,所述mlp算法包含预处理后的地物光谱库分类,首先将pca处理后的光谱数据按照一定的比例分为训练集和验证集,然后使用常见的机器学习算法对训练集进行分类,经过评估,最后得出mlp方法精度最高,若兼顾精度与速度,则二次判别分析(quadratic discriminant analysis,qda)最适用。
13.与现有技术相比,本发明具有如下有益效果:
14.1、本发明选取不同环境梯度的草原物种,构建了一个涵盖120个物种,29212条光谱的内蒙古草原植物物种光谱库;
15.2、本发明基于地物光谱库,提供了一种有效的草原多物种光谱分类方法;
16.3、本发明中使用smote算法解决种间光谱数量不平衡问题,使用pca算法解决光谱数据冗余的问题,在本实施例中,经过数据预处理,mlp的分类精度高达97.17%,表明本发明具有高可靠性;
17.4、本发明使用多种方法对地物光谱库进行预处理,然后使用qda方法对光谱进行分类,速度大幅提升且精度依旧保持在高位,表明本发明具有较强的实用性。
附图说明
18.图1是本发明基于地物光谱库的内蒙古草原植物物种分类方法的流程图。
具体实施方式
19.以下结合附图对本发明做进一步描述:
20.本发明公开了一种基于地物光谱库的内蒙古草原植物物种分类方法,包括以下步骤:
21.s1:草原植物物种光谱库的构建;
22.s2:地物光谱库预处理;
23.s3:mlp算法对预处理后的地物光谱库进行分类。
24.步骤s1,草原植物物种光谱库的构建,包括野外叶片样本的采集和室内叶片光谱测量。叶片样本采集:在内蒙古自治区锡林郭勒盟,于2020年6月至2020年8月,选取了18个环境梯度差异明显的采样地点,草地类型涵盖草甸草原和典型草原(包括灌丛化草原),采集到包括草本和灌木共120种(具体见表格1)植物的新鲜叶片,同时为保证后续光谱采集准确,将叶片放在冷藏箱内,然后在实验室当天测量完毕所有叶片光谱。室内叶片光谱测量:使用asd地物光谱仪对叶片进行光谱测量。具体操作步骤如下:
①
开机预热15分钟;
②
rs3软件操作:镜头对准白板点击“opt”优化;
③
rs3软件操作:获取白板参考光谱:“wr”对白板,出现reflectance=1的直线;
④
rs3软件操作:镜头对准待测植物叶片:“空格”保存数据;
⑤
光谱数据整合统计:将所测植物光谱进行分类整理,经过统计得到120个物种共计29212条光谱的光谱库,镜头对准待测植物叶片。为确保光谱数据多样性,选取同种植物的上、中、下位置的叶子以及单个叶片的不同位置进行光谱测量,且不允许重复测量。为确保测量精度,每隔4分钟,校正标准白板一次。
25.步骤s2,地物光谱库预处理,包括数据去噪,连续小波变换光谱特征增强,smote算法光谱平衡和pca光谱降维四个步骤。数据去噪包括删减边缘光谱减小系统误差和使用savitzky
‑
golay滤波过滤噪声。连续小波变换是一种有效的数据降噪方法,它还可以增强高光谱数据的光谱特征细节,在本实施例中,其母函数选用高斯二阶导数,尺度参数设置为16。
26.去噪后进行smote算法平衡数据:
27.针对常见种和稀有种种间光谱数据数量不平衡的问题,本发明使用smote算法进行数据平衡。smote算法的基本思想是对少数类样本进行分析,然后使用k近邻分类算法进行模拟生成新合成样本,最后将原始样本和合成样本合并作为新的该少数类样本。在本实施例中,以光谱数量最多的物种狼毒(其数量为444条)为参照,将其他119个物种的光谱数量均扩展为444条。
28.数据平衡后进行pca光谱降维:
29.pca,即主成分分析法,是一种较为常见的数据降维方法,可有效降低数据冗余提高运算速度,同时其也可根据一定的规则提取出重要的特征供后续处理。因此,为提高后续算法运行效率,在本实施例中使用pca进行光谱数据的降维,具体参数设定有两个:n_components和svd_solver。n_components用于设置pca降维后的特征维度数目,可根据需要进行调整,本实施例设定n_components=100。svd_solver为设定奇异值分解(singular value decomposition,svd)的方法,有4个值可供选择:{
‘
auto’,
‘
full’,
‘
arpack’,
‘
randomized’},本实施例选择svd_solver=
‘
auto’。
30.步骤s3,使用mlp算法对预处理后的地物光谱库进行分类。包括:s3.1使用stratifiedshufflesplit函数按照7:3的比例将经过pca处理后的光谱数据分为训练集和验证集,同时该函数能保证在每一类别的数据中占比也为7:3;s3.2为评估算法性能选出最优的分类方法,选取了常见的6种机器学习算法进行综合比较分析(具体方法见表格2);s3.3对分类结果进行评估,得出精度在95%以上的算法中,精度最高的分类算法为mlp,效率最高的算法为qda。s3.4,仅考虑精度,使用mlp进行光谱数据的物种分类,若兼顾精度与速度,则使用qda。
31.步骤s3.3中,评估方法选用了5种,具体为
①
accuracy
②
recall
③
precison
④
f1
‑
score
⑤
kappa系数。经过比较(参考表格1),得出mlpclassifier函数代表的mlp分类精度最高,accuracy高达97.17%,所用时间为192.8s,quadraticdiscriminantanalysis代表的qda精度稍低为96.35%,但是所用时间大幅下降,为2.4s。
32.步骤s3.4中,在仅考虑精度的情况下,使用mlp进行光谱数据的物种分类。mlp又称人工神经网络,由输入层、隐藏层和输出层三部分组成,其隐藏层可以包含多层。mlp对噪声具有较强的鲁棒性和容错能力,且能充分逼近复杂的非线性关系,因此在数据分类中可以取得较好的结果。在本实施例中使用的mlpclassifier(参数分别为solver='sgd',activation='relu',max_iter=2000,alpha=1e
‑
5,hidden_layer_sizes=(256,128);在考虑精度的同时兼顾速度,使用qda对光谱数据进行植物物种的分类。二次判别分析(qda),与线性判别分析(linear discriminant analysis,lda)密切相关。二者的区别在于,qda的每个类别都有对应的协方差矩阵。当决策边界为非线性时,qda通常会表现更好。另一方面,当训练集较大时,qda表现较好。在本实施例中,经过类别平衡光谱数量高达53280条,因此分类结果较好。
[0033][0034]
表1
[0035]
方法/评价指标%)accuracyprecisionrecallf1
‑
scorekappat/slineardiscriminantanalysis()80.63%86.51%80.63%82.23%80.47%0.283quadraticdiscriminantanalysis()96.35%96.89%96.35%96.47%96.32%2.456kneighborsclassifier()90.82%91.43%90.82%90.40%90.74%133.0randomforestclassifier()84.02%85.01%84.02%83.86%83.89%9.585mlpclassifier()97.17%97.19%97.17%97.16%97.14%192.8linearsvc()95.88%95.92%95.88%95.82%95.85%42.30
[0036]
表2
[0037]
利用本发明所述技术方案,或本领域的技术人员在本发明技术方案的启发下,设计出类似的技术方案,而达到上述技术效果的,均是落入本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1