基于点击率预估模型的广告推荐方法、系统及存储介质与流程
本发明属于广告推荐领域,具体涉及一种基于点击率预估模型的广告推荐方法、系统及存储介质。
背景技术:
点击率预估是dsp流量分配的核心依据之一,同时点击率预估的准确性对于在线广告的推荐具有非常重要的作用。近几年,点击率预估模型从传统的机器学习模型已经转变为深度学习模型,常见的点击率预估模型包括lr、fm、wide&deep、deepfm等。由于广告数据的天然特性:数据量大、维度高、数据稀疏,使得广告的点击率预估具有一定的挑战性。
数据和特征决定了机器学习的上限,而模型和算法只是无限逼近这个上限。结合业务数据特性,选择合适的算法模型,进行特征工程创新处理、网络结构设计以及embedding方法调优则是一个好模型落地的关键。现有的模型预估准确性还有待于提高。
技术实现要素:
本发明的目的在于针对上述现有技术中针对广告数据的模型预估准确性不高的问题,提供一种基于点击率预估模型的广告推荐方法、系统及存储介质,对于广告推荐能够起到很好的效果,提高点击率预估的准确性,同时有利于提高流失用户的召回率。
为了实现上述目的,本发明有如下的技术方案:
一种基于点击率预估模型的广告推荐方法,包括以下步骤:
-数据收集,对业务数据进行清洗,构造数据集;
-对数据集进行特征工程处理,生成训练样本,供模型训练使用;
-基于tensorflow框架,采用wide&deep算法进行模型训练;
-调整模型结构参数,确定最好的超参组合,进行模型优化;
-优化模型与线上模型做a/b实验,将点击率提升的模型替换旧模型;
-将特征数据实时更新至云存储器oss,使用tensorflowserving生成grpc接口,对候选的广告列表批量进行点击率预估,取点击率最高的广告,且点击率>0.5,进行推荐曝光。
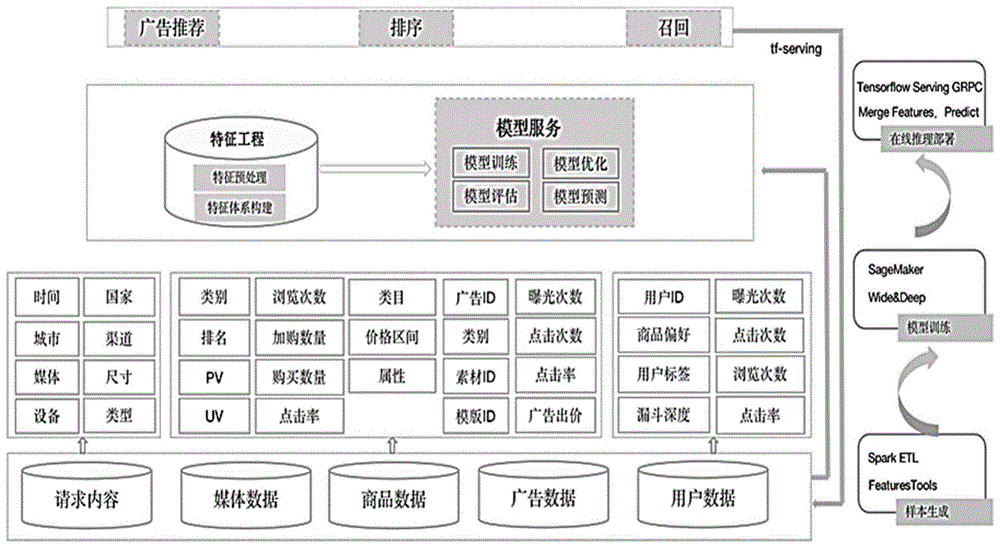
在本发明的一种实施例当中,数据收集的对象包括用户、广告、请求上下文、媒体;其中,用户特征数据包括:用户id、用户商品偏好、用户标签、用户历史漏斗深度、最近3/7/14/28天曝光次数、点击次数、浏览次数、加购次数、购买次数、点击率;广告特征数据包括:广告id、广告类别、广告素材id、广告模版id、曝光次数、点击次数、点击率;请求上下文特征数据包括:时间、国家、城市、渠道、媒体、版位尺寸、设备类型、展示类型;媒体特征数据包括:类别、排名、pv、uv、点击率。
在本发明的一种实施例当中,对数据集进行特征工程处理的具体步骤如下:
步骤1)样本采样,加入正负样本惩罚权重;
步骤2)对数据集中的数据划分为连续特征与离散特征进行归一化与缺失值处理;
步骤3)进行特征交叉组合。
在本发明的一种实施例当中,用户特征数据中的连续特征包括曝光次数、点击次数、浏览次数、点击率,广告特征数据中的连续特征包括曝光次数、点击次数、点击率,媒体特征数据中的连续特征包括排名、pv、uv、历史点击率,对以上连续特征采用对数函数进行归一化;同时对部分连续特征,包括媒体特征数据中的排名以及用户特征数据的加购次数、购买次数进行等频分桶离散化。
离散特征包括用户id、用户商品偏好、用户标签、用户历史漏斗深度、广告id、广告类别、广告素材id、广告模版id、时间、国家、城市、渠道、媒体、版位尺寸、设备类型、展示类型以及类别,对以上离散特征使用hash方式进行one-hot编码。
在本发明的一种实施例当中,所述的缺失值处理具体包括:进行特征分布统计,分析缺失的比例,针对达到80%以上缺失,则放弃掉该特征;针对离散特征采用默认值填充,针对连续特征采用均值填充。
在本发明的一种实施例当中,所述步骤3)进行特征交叉组合时,将用户特征及广告、媒体特征进行交叉,包括将用户商品偏好、用户标签、用户历史漏斗深度与广告id、广告素材id、广告类别以及类别进行交叉组合。
在本发明的一种实施例当中,采用wide&deep算法进行模型训练的具体步骤如下:在wide层输入离散特征以及交叉组合特征,deep层输入连续特征,采用历史数据集作为训练集,最近1天的数据集作为测试集;
进行模型调优,加入dropout与l2正则防止模型过拟合,引入batchnormalization加快模型的收敛;对比不同学习器,选择效果较好的adm;同时尝试不同learningrate、batchsize以及embedding参数调优,进行训练模型,最终生成savedmodel格式模型文件。
在本发明的一种实施例当中,使用tensorflowserving生成grpc接口方式的具体步骤包括:步骤1)启动docker,拉取tensorflowservindocker镜像;步骤2)生成预测接口;步骤3)线上部署,配置统一域名tfserve,生成最终打分接口服务;步骤4)线上推理,以批量方式构造请求数据,调取预测接口,最终实现能够在10ms之内返回50条广告的预测结果。
本发明还提供一种基于点击率预估模型的广告推荐系统,包括:
数据集构造模块,用于进行数据收集,对业务数据进行清洗,构造数据集;
训练样本生成模块,用于对数据集进行特征工程处理,生成训练样本;
模型训练模块,用于基于tensorflow框架,采用wide&deep算法进行模型训练;
模型优化模块,用于调整模型结构参数,确定最好的超参组合,进行模型优化;并且将优化模型与线上模型做a/b实验,将点击率提升的模型替换旧模型;
推荐模块,用于将特征数据实时的更新至云存储器oss,使用tensorflowserving生成grpc接口,对候选的广告列表批量进行点击率预估,根据点击率进行推荐曝光。
本发明还提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述的计算机程序被处理器执行时实现所述基于点击率预估模型的广告推荐方法的步骤。
相较于现有技术,本发明至少具有如下的有益效果:
本发明对于广告推荐能够起到很好的效果,将用户商品偏好,用户标签,用户历史行为漏斗深度等人工设计的抽象特征及用户偏好特征与广告特征进行交叉组合,能够使模型具有较好的记忆能力;同时采用deep模型,通过embedding方法,使用低维稠密特征输入,使得特征向量不同维度做充分的交叉,加强了模型的泛化能力,提高了模型的召回率。同时,特征工程部分,基于业务数据大量细致的挖掘分析组合特征,使得特征具有更强的灵活性,增强了模型的可解释性。实验通过离线auc和线上abtest进行评估。wide&deep模型的auc超过原有的lr模型。在abtest线上实验中,wide&deep模型比lr模型,点击率提升27%。
附图说明
为了更加清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作以简单地介绍,应当理解,以下附图仅示出了本发明部分实施例,对于本领域普通技术人员而言,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
图1本发明实施例基于点击率预估模型的广告推荐方法流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员还可以在没有做出创造性劳动的前提下获得其他实施例。
参见图1,一种基于点击率预估模型的广告推荐方法,包括以下步骤:
s1,进行数据收集,对业务数据进行清洗,构造数据集;
数据收集的对象包括用户、广告、请求上下文、媒体;其中,用户特征数据包括:用户id、用户商品偏好、用户标签、用户历史漏斗深度、最近3/7/14/28天曝光次数、点击次数、浏览次数、加购次数、购买次数、点击率;广告特征数据包括:广告id、广告类别、广告素材id、广告模版id、曝光次数、点击次数、点击率;请求上下文特征数据包括:时间、国家、城市、渠道、媒体、版位尺寸、设备类型、展示类型;媒体特征数据包括:类别、排名、pv(pageview,即页面浏览量或点击量)、uv(uniquevisitor,是指通过互联网访问、浏览这个网页的自然人,访问网站的一台电脑客户端为一个访客)、点击率。
s2,对数据集进行特征工程处理,生成训练样本,供模型训练使用;
特征工程处理的具体步骤如下:
步骤1)样本采样,加入正负样本惩罚权重。
步骤2)对数据集中的数据划分为连续特征与离散特征进行归一化与缺失值处理。
连续特征:
用户特征数据中的连续特征包括曝光次数、点击次数、浏览次数、点击率,广告特征数据中的连续特征包括曝光次数、点击次数、点击率,媒体特征数据中的连续特征包括排名、pv、uv、历史点击率,对以上连续特征采用对数函数进行归一化;同时对部分连续特征,包括媒体特征数据中的排名以及用户特征数据的加购次数、购买次数进行等频分桶离散化。
离散特征包括用户id、用户商品偏好、用户标签、用户历史漏斗深度、广告id、广告类别、广告素材id、广告模版id、时间、国家、城市、渠道、媒体、版位尺寸、设备类型、展示类型以及类别,对以上离散特征使用hash方式进行one-hot编码。
缺失值处理具体包括:进行特征分布统计,分析缺失的比例,针对达到80%以上缺失,则放弃掉该特征;针对离散特征采用默认值填充,针对连续特征采用均值填充。
步骤3)进行特征交叉组合。
手动进行特征交叉组合,将用户特征及广告、媒体特征进行交叉,包括将用户商品偏好、用户标签、用户历史漏斗深度与广告id、广告素材id、广告类别以及类别进行交叉组合。
s3,基于tensorflow框架,采用wide&deep算法进行模型训练;
具体步骤如下:
经过样本构建及特征工程最终生成的训练集,作为wide&deep的训练样本。wide层输入离散特征及交叉组合特征,包括用户id、商品偏好、标签、历史漏斗深度、广告id、广告类别、广告素材id、广告模版id、请求时间、国家、城市、渠道、媒体、版位尺寸、设备类型、展示类型、媒体类别以及用户商品偏好、用户标签、历史漏斗深度与广告id、广告素材id、广告类别、媒体类别进行交叉组合的特征。deep层输入除了离散特征外,主要是连续特征,包括用户的曝光次数、点击次数、浏览次数、点击率,广告的曝光次数、点击次数、点击率以及媒体的排名、pv、uv、历史点击率。采用历史60天的数据集作为训练集,最近1天作为测试集。模型调优,加入dropout与l2正则防止模型过拟合,引入batchnormalization加快模型的收敛。对比不同学习器,选择效果比较好的adm。同时尝试不同learningrate、batchsize及embedding参数调优。训练模型,最终生成savedmodel格式模型文件。
s4,调整模型结构参数,确定最好的超参组合,进行模型优化;
s5,优化模型与线上模型做a/b实验,将点击率提升的模型替换旧模型;
s6,将特征数据实时更新至oss(objectstorageservice,简称oss,是阿里云对外提供的海量、安全和高可靠的云存储服务),使用tensorflowserving(一个适用于机器学习模型的灵活、高性能应用系统,专为生产环境而设计,借助tensorflowserving可以轻松部署新算法和实验)生成grpc(grpc为rpc框架的一种,一个高性能、开源和通用的rpc框架,面向服务端和移动端,基于http/2设计)接口,对候选广告列表批量进行点击率预估,取点击率最高的广告,且点击率>0.5,进行广告的推荐曝光。
使用tensorflowserving生成grpc接口的具体步骤如下:
步骤1)启动docker,拉取tensorflowservingdocker镜像;步骤2)生成预测接口;步骤3)线上部署,配置统一域名tfserve,生成最终打分接口服务;步骤4)线上推理,以批量方式构造请求数据,调取预测接口,最终实现能够在10ms之内返回50条广告的预测结果。
本发明使用的wide&deep模型与lr模型的点击率对比结果如下表所示:
在abtest线上实验中,wide&deep模型比lr模型,点击率提升27%。
一种基于点击率预估模型的广告推荐系统,包括:
数据集构造模块,用于进行数据收集,对业务数据进行清洗,构造数据集;
训练样本生成模块,用于对数据集进行特征工程处理,生成训练样本;
模型训练模块,用于基于tensorflow框架,采用wide&deep算法进行模型训练;
模型优化模块,用于调整模型结构参数,确定最好的超参组合,进行模型优化;并且将优化模型与线上模型做a/b实验,将点击率提升的模型替换旧模型;
推荐模块,用于将特征数据实时的更新至云存储器oss,使用tensorflowserving生成grpc接口,对候选的广告列表批量进行点击率预估,根据点击率进行推荐曝光。
一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述的计算机程序被处理器执行时实现所述基于点击率预估模型的广告推荐方法的步骤。
所述的计算机程序可以被分割成一个或多个模块/单元,所述一个或者多个模块/单元被存储在所述存储器中,并由所述处理器执行,以完成基于点击率预估模型的广告推荐方法。
存储器可用于存储计算机程序和/或模块,所述处理器通过运行或执行存储在所述存储器内的计算机程序和/或模块,以及调用存储在存储器内的数据,实现本发明系统的各种功能。
本发明基于点击率预估模型的广告推荐方法、系统及存储介质具有以下优点:
1、点击率预估准确率高,基于对业务数据的理解,人工进行特征设计及特征组合,将显示的、直接的及关联规则等特征作为wide部分输入模型,增加了模型的记忆能力。2、召回率高,即具有一定的泛化能力。对不同id类特征进行embedding调优及网络设计作为deep部分,让模型能够抓取更多的非线性特征和组合特征的信息,表达能力得到增强。
以上所述的仅仅是本发明的较佳实施例,并不用以对本发明的技术方案进行任何限制,本领域技术人员应当理解的是,在不脱离本发明精神和原则的前提下,该技术方案还可以进行若干简单的修改和替换,这些修改和替换也均属于权利要求书所涵盖的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!