一种基于多模干涉效应的片上光神经网络结构
本发明涉及人工智能技术领域,具体涉及一种基于多模干涉效应的片上光神经网络结构。
背景技术:
光子神经网络是当前人工智能领域的研究热点。光子神经网络系统既具有分布式计算架构模拟人脑的运算方式,相比于传统的电子计算机具有低功耗、容错性和深度学习能力,又将光子模拟信号处理技术的高速率、大带宽以及并行计算的特点与神经网络处理技术相融合,有望大幅提升人工智能系统的性能。全光计算的计算能力领先电子计算芯片五个数量级左右,所以光神经网络的优越性无可比拟。
过去20年里,国外研究人员提出了多种光神经网络结构。在2017年,麻省理工学院的研究团队利用了基于马赫曾德干涉仪阵列的结构实现了神经网络层与层之间的连接,并且通过热移相器来控制权重。此外,他们还利用计算机仿真了非线性单元。最终,这种基于马赫曾德干涉结构的片上光子神经网络实现了对四个元音语音信号的76.7%的识别率。除了这种结构的光神经网络外,明斯特大学的研究团队在2019年展示了一种基于波分复用技术的片上光神经网络。该方案采用了大量的片上微环来实现神经元之间的连接。其权重的调整依赖于相变材料的使用,明斯特大学的研究团队在波导中集成了相变材料,可以通过光脉冲来调整每个神经元的权重。上述两种光子神经网络芯片的尺寸在625~20000平方微米之间。此外维持热调电极的功耗在10毫瓦左右,但是如果采用相移材料来进行权重调整,则无需额外的功率来维持权重。值得一提的是,在基于波分复用技术的光子神经网络中,因为采用了相移材料,所以该方案可以在硬件上实现非线性单元,不需要使用计算机来模拟非线性单元。非线性单元的光学实现使得该光子神经网络的性能大大提升。根据其刊发的论文,该方案仅需一层神经网络结构就可以实现对四个字母的识别。
上述的片上光神经网络存在着一个弊端,所使用的器件数量巨大,例如基于mzi的光神经网络所使用的器件为56个mzi和213个相移器,基于片上微环结构的光神经网络所需的器件为121个微环,如此大型的阵列对工艺不友好,且难以保证良率以及难以进行测试,所以有必要研究一种紧凑,简洁的片上光子结构来实现神经网络,若成功实现,有望大大提升神经网络的性能和实用性。
技术实现要素:
(一)要解决的技术问题
针对上述问题,本发明提供了一种基于多模干涉效应的片上光神经网络结构,用于至少部分解决传统片上光神经网络结构器件数量巨大、对工艺不友好等技术问题。
(二)技术方案
本发明提供了一种基于多模干涉效应的片上光神经网络结构,包括:至少两层重复组成的神经网络层结构,每层神经网络层结构包括:一个片上多模干涉器,至少两个光波导,每个光波导上设有一个片上移相器;片上多模干涉器与每个光波导连接;待识别信号被调制到不同光波导中光载波上,片上移相器用于调节光载波的权重,片上多模干涉器用于实现不同光波导中光载波能量的交换,通过至少两层神经网络层结构的传播,不同的光波导输出不同的光强,实现对信号的识别。
进一步地,还包括:每个片上移相器和片上多模干涉器之间设有非线性单元。
进一步地,光波导中的光为相干光,通过单模激光器产生的连续光经由分束后产生。
进一步地,光相位的调制通过神经网络建模、训练后得到。
进一步地,对信号的识别包括以具有最高光强度的光波导的输出代表不同的判定结果。
进一步地,片上多模干涉器的长度满足自再现效应的条件。
进一步地,片上移相器的调节范围至少为2π。
进一步地,片上光神经网络结构包括三层神经网络层结构,3个片上多模干涉器、12个片上移相器。
进一步地,待识别信号被调制到不同光波导3中光载波上包括待识别信号通过不同通道上的强度调制器或者相位调制器调制到不同通道的光强度或相位上。
进一步地,强度调制器或者相位调制器为具有高速信号调制能力的调制器,包括片上器件、分离器件。
(三)有益效果
本发明实施例提供的一种基于多模干涉效应的片上光神经网络结构,利用片上多模干涉效应来连接光神经元和每个通道的移相器来调节权重,以实现对不同输入信号的判别。该技术可以以一种十分简洁的方式实现片上光神经网络,所需器件数量对比现有方案大大降低,对比现有片上光神经网络技术,其大大减少了所需的器件数量。
附图说明
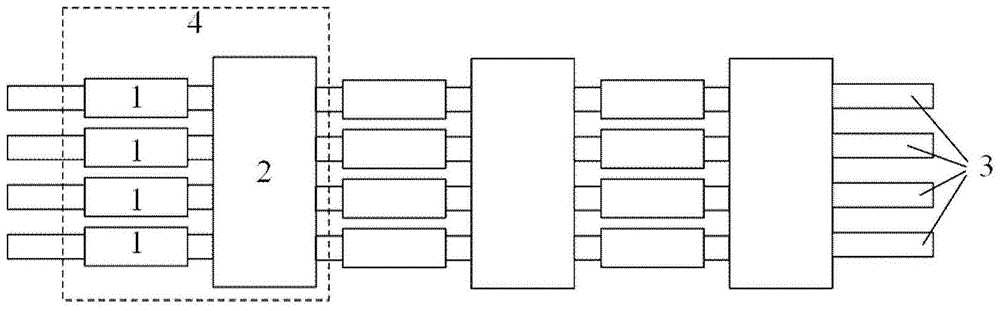
图1示意性示出了根据本发明实施例一种基于多模干涉效应的片上光神经网络的结构示意图;
图2示意性示出了根据本发明实施例中不同输入信号的光强;
图3示意性示出了根据本发明实施例中不同输入在该光神经网络技术处理之后得到的识别结果;
附图标记说明:
1-片上移相器;
2-片上多模干涉器;
3-光波导;
4-神经网络层结构。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明进一步详细说明。
本公开的实施例提供了一种基于多模干涉效应的片上光神经网络结构,请参见图1,包括:至少两层重复组成的神经网络层结构4,每层神经网络层结构4包括:一个片上多模干涉器2,至少两个光波导3,每个光波导3上设有一个片上移相器1;片上多模干涉器2与每个光波导3连接;待识别信号被调制到不同光波导3中光载波上,片上移相器1用于调节光载波的权重,片上多模干涉器2用于实现不同光波导3中光载波能量的交换,通过至少两层神经网络层结构4的传播,不同的光波导3输出不同的光强,实现对信号的识别。
对于该片上光神经网络包括片上移相器1、片上多模干涉器2、光波导3以及若干个重复的1-3组成的神经网络层结构4;这里片上移相器1用于调节权重、片上多模干涉器2用于连接光神经元、光波导3用于连接不同器件。待判别的事件或数据被转移到不同通道的光载波上,不同通道即代表着不同的光神经元,这些光神经元通过片上多模干涉器2实现能量的交换。在多模干涉器的长度满足自再现效应的条件时,多模干涉器的每一个输出都是所有多模干涉器的所有输入的线性叠加。每一层光神经网络结构4都包括一个多模干涉器2,通过每层的多模干涉器2,光神经元所携带的信息可以传导至下一层,并且实现了神经元之间的连接。神经元中权重的实现是通过每一层神经网络层结构4上不同通道上的移相器1来实现的。理论上,权重的调节可以是“复数”形式的,即可以是相位调制、强度调制或者强度调制和相位调制的结合。这里我们采用的是相位调制。通过对每一路相干光的相位的调制,结合多模干涉器的线性叠加的传播函数,可以达到控制多模干涉器的输出的效果。每一层的输出都可以通过改变移相器的相位来实现一个特殊的映射,通过层层传播,最终可以在不同的输出波导得到不同的光强。
还需说明的是,该神经网络的层数与多模干涉器2的个数相等;移相器1的个数与网络层数的比值为通道数目。通常来说层数增加可以提高识别能力和准确率。这里,多模干涉器只需要一个就可以实现多个通道光场的互相叠加,而mzi或微环阵列需要多个级联才能实现不同通道能量的交换和叠加。对比传统片上光神经网络方案,本方案中多模干涉器的使用使得该片上光神经网络方案变得十分精简,所需器件数量大大降低,降低了工艺难度和测试难度。
在上述实施例的基础上,还包括:每个片上移相器1和片上多模干涉器2之间设有非线性单元。
该方案可以通过在每个通道的移相器1后增加非线性单元以提高该片上光神经网络的性能。非线性单元是可以对光的强度实现非线性的输出,例如relu函数等。非线性单元或者函数可以实现把线性映射变成非线性映射,可以使映射的范围变大。
在上述实施例的基础上,光波导3中的光为相干光,通过单模激光器产生的连续光经由分束后产生。
输入到该光神经网络结构的不同通道的光载波需为相干光,由单模激光器产生的连续光经由分束器产生。
在上述实施例的基础上,光相位的调制通过神经网络建模、训练后得到。
每一层移相器上对各个通道的光所施加的相位偏置是由计算机上进行神经网络建模后经过训练后得到。计算机上的模型对应的是该光神经网络的物理模型,把物理模型用数学方法表示。相位偏置的计算过程是反向传播算法。
在上述实施例的基础上,对信号的识别包括以具有最高光强度的光波导3的输出代表不同的判定结果。
最终输出为判定方式可以为不同的具有最高光强度的输出通道代表不同的判定结果。本方案中,我们将不同输出波导的光强定为训练对象,而训练目标是不同输入信号在不同的输出波导具有最大光强。通过反向传播优化算法,不断的优化每一层的不同通道上的移相器对相干光所施加的相位,使最终输出不断迫近预期最终输出,得到一个输出-输出映射关系。通过这种方式,当不同的输入经过该光神经网络芯片的处理之后,在不同通道会存在最大光强,这样便实现了对不同事件或者信号的识别效果。
在上述实施例的基础上,片上多模干涉器2的长度满足自再现效应的条件。
片上多模干涉器2用于实现不同光神经元的能量的交换,多模干涉器2的长度需要特殊设计以实现泰伯自再现现象,长度l需要满足泰伯效应公式:
其中,p和n为非零正自然数,nr为mmi干涉区的基模有效折射率,we为mmi干涉区宽度,λ0为输入光中心波长。
在上述实施例的基础上,片上移相器1的调节范围至少为2π。
调节权重的方式为相位调节,移相器的调节范围至少为2π,其具体数值通过在计算机上通过python和tensorflow实现建模训练得到。
在上述实施例的基础上,片上光神经网络结构包括三层神经网络层结构4,3个片上多模干涉器2、12个片上移相器1。
这里三层神经网络结构可以验证该方案的可行性,是一种优选的方式,需要说明的是该方案可以被拓展至任意层的结构。
在上述实施例的基础上,待识别信号被调制到不同光波导3中光载波上包括待识别信号通过不同通道上的强度调制器或者相位调制器调制到不同通道的光强度或相位上。
输入数据(也就是待测数据)需要调制到相干光上。工作过程就是普通的相位调制或者强度调制,类似于ook调制或者psk调制。
在上述实施例的基础上,强度调制器或者相位调制器为具有高速信号调制能力的调制器,包括片上器件、分离器件。
对于该片上光神经网络,待判别的事件或者数据通过具有高速信号调制能力的调制器调制到不同通道的相干光的强度或者相位上。通过这样的方式,待判别的事件或数据就被转移到不同通道的光载波上。
下面以一具体实施例介绍本发明基于多模干涉效应的片上光神经网络结构。
图1所示为本发明的结构示意图。本方案的主要器件包括了片上移相器1、片上多模干涉器2、光波导3以及若干个重复的1~3组成的神经网络层结构4。
图2所示为不同的输入信号的光强。图a-d代表了四种不同的输入,这些输入作为待测数据输入到不同的波导上。
图3所示为不同输入在该光神经网络技术处理之后得到的识别结果。图a-d代表了四个不同输入在经过该光神经网络芯片之后,在四个不同的输出端分别有最大光强,通过这些具有最大光强的输出波导的不同就可以实现对输入的判别。图a-d的输出波形与图2a-d的输入波形分别一一对应。
上述的结果充分说明了该发明可以对事件或数据进行准确的识别,对比现有技术方案,其复杂度大大降低。
根据本发明的一种具体实施方式,光载波需要为相干光,波长为1550nm。
根据本发明的一种具体实施方式,调节权重的方式为相位调节,移相器的调节范围至少为2π,具体数值通过在计算机上通过python和tensorflow实现建模训练得到。
根据本发明的一种具体实施方式,待识别数据为四个4比特数据,通过强度调制方式调制到不同通道的相干光载波上;预期的输出为不同的四个输入分别在四个输出光波导具有最大光强。
根据本发明的一种具体实施方式,该光神经网络具有三层神经网络结构,也就是包含3个多模干涉器,12个移相器。
本发明的基于多模干涉效应的片上光神经网络技术,能够对输入的事件或者数据进行正确识别,对比现有片上光神经网络技术,其大大减少了所需的器件数量,预计可以为当前信息系统提供一种异常简洁,低能耗,低时延的深度学习解决方案。
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!