一种基于异构图神经网络的用户意图识别方法及装置
本发明涉及计算机应用、计算机系统及其技术产品技术领域,尤其涉及一种基于异构图神经网络的用户意图识别方法及装置。
背景技术:
自然语言理解是人工智能的核心课题之一。通过利用计算机模拟人类间的语言交互过程,使计算机理解和运用人类的自然语言,为人类提供信息服务,如解答问题、查询资料等。传统的自然语言理解技术已应用于多个领域,包括搜索系统、问答系统、对话系统等。搜索系统根据用户输入,识别用户意图,为用户返回最相关的内容,像百度、谷歌、必应等搜索引擎,微信里的搜一搜,甚至在京东、淘宝上选购心仪的商品时都离不开搜索系统。问答系统和对话系统也逐渐出现在日常生活中,如智能客服、聊天机器人等。自然语言理解技术的快速发展,使计算机能更准确地理解用户意图,进而为用户提供方便快捷的服务。
传统的自然语言理解技术通常采用领域专家手工定制的规则模板来解析用户输入,这就导致模型无法泛化,用于汽车领域的搜索系统就无法应用于计算机领域,每个系统都需要消耗大量的时间和精力来精心构造。另一方面,由于自然语言的口语化和多样性,输入的文本通常是不规范的甚至是存在拼写或者语法错误的,这也导致基于规则模板的模型鲁棒性差,需要用户输入准确才能进行识别,为用户的使用带来诸多不便。
近年来,基于深度学习的自然语言理解技术受到学术界与工业界的广泛关注,并展现了巨大的商业潜力。与基于规则模板的方法相比,基于深度学习的方法通过数据驱动,实现了端到端的深度学习模型,减少了模型训练过程中的人工干预,使模型可以很方便的从一个领域迁移到另一领域。传统的基于深度学习的方法通常采用时序模型对对话语义建模,忽略了对话中多用户间灵活频繁的交互过程,为了解决这一问题,最近的一些方法采用图神经网络为对话建模。然而,由于自然语言的随意性和多样性,人们可以用多种多样个性化的方式来表达自己的意图,这为准确识别用户意图带来了更多的困难。
技术实现要素:
本发明目的就是为了弥补已有技术无法准确识别用户个性化表达的缺陷,提供一种基于异构图神经网络的用户意图识别方法及装置。
本发明是通过以下技术方案实现的:
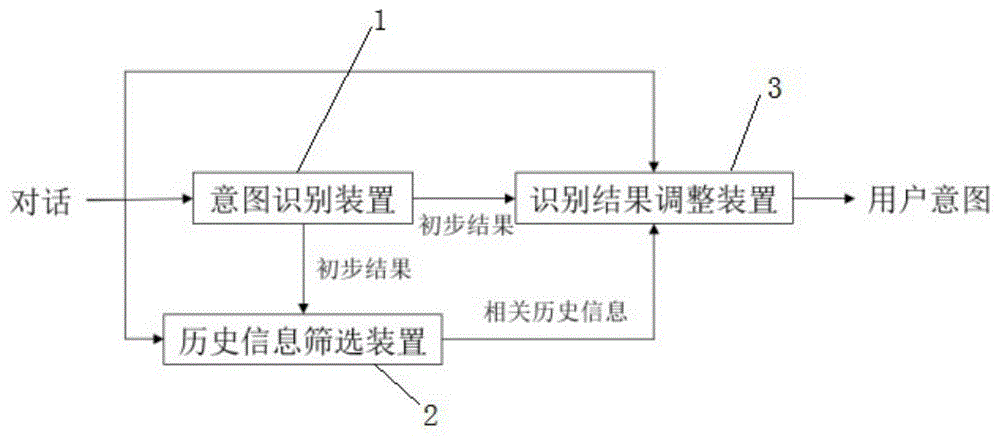
一种基于异构图神经网络的用户意图识别装置,包括有意图识别装置、历史信息筛选装置和识别结果调整装置;
所述意图识别装置根据用户的对话内容直接识别用户意图得到初步的识别结果;
所述历史信息筛选装置根据对话内容以及初步的识别结果对用户历史信息进行筛选,得到与对话内容相关的用户历史信息;
所述识别结果调整装置采用异构图神经网络对当前对话内容以及与对话内容相关的用户历史信息进行编码,进而对所述初步的识别结果进行调整,识别最终的用户意图。
所述的意图识别装置根据对话内容直接识别用户意图得到初步的识别结果,具体如下:意图识别装置将对话内容转化为对应的特征向量,并对对话内容中每句话得到一个初步的识别结果。
所述的意图识别装置将对话内容转化为对应的特征向量,并对对话内容中每句话得到一个初步的识别结果,具体如下:意图识别装置采用卷积神经网络和双向长短期记忆网络得到包含上下文语境信息的句子特征向量,使用全连接层作为分类器,对对话内容中的每句话进行分类,进而为对话内容中的每句话得到一个初步的识别结果。
所述的用户历史信息是指用户在其他对话中的历史发言。
所述的历史信息筛选装置根据对话内容以及初步的识别结果对用户历史信息进行筛选,得到与对话内容相关的用户历史信息,具体如下:
历史信息筛选装置是使用一种粗粒度历史选择模块对用户历史信息进行筛选的,首先,利用预训练词编码将文本中离散的词转换为连续的词向量表示,通过最大池化操作分别得到当前对话内容的向量表示和用户历史发言的向量表示;通过计算两者之间的余弦相似度得到用户历史发言与当前对话内容的相关性分数,同时,根据意图类别对用户历史发言进行归类,并根据相关性分数为每个类别选择前k个与当前对话内容最相关的历史发言。
利用相关性重计算方法模块来计算当前对话内容中每一句话与每个类别里k个历史发言之间的相关性分数,得到一个相似度矩阵;利用初步的识别结果和相似度矩阵,为每个类别里的k个历史发言重新计算与当前对话内容整体的相关性分数。
所述的异构图神经网络包含两种节点:句子节点和标签节点,其中,句子节点的向量表示来自于意图识别装置得到的句子特征向量表示,标签节点利用历史信息筛选装置得到的与当前对话内容最相关的k个历史发言的向量表示,根据相关性分数加权平均来得到标签节点的向量表示。
所述的异构图神经网络包含两种边:用户边和标签边,其中,用户边用来表示句子节点之间的关系,采用一种基于相似度的注意力模块对用户边的权重进行初始化;标签边用来连接标签节点和句子节点,标签边的权重表示句子节点与不同标签之间的关系,利用意图识别装置得到的初步的识别结果作为标签边权重的初始化,使用一种特定于边关系的消息传递策略对节点表示进行更新,根据异构图神经网络得到的句子节点表示,利用全连接层对每个句子节点进行分类,进而为每个句子得到调整后的意图识别结果。
在对话内容中,根据用户以及发言顺序,将用户边分为4类,即自己前、自己后、他人前、他人后。
一种基于异构图神经网络的用户意图识别方法,具体步骤如下:
s1首先根据用户的对话内容直接识别用户意图得到初步的识别结果;
s2根据对话内容以及步骤s1得到的初步的识别结果对用户历史信息进行筛选,得到与对话内容相关的用户历史信息;
s3采用异构图神经网络对当前对话内容以及步骤s2得到的与对话内容相关的用户历史信息进行编码,进而对步骤s1得到的初步的识别结果进行调整,识别最终的用户意图。
本发明的优点是:
本发明解决了传统深度学习方法无法有效识别用户个性化表达的问题,设计了一种两阶段的意图识别策略,首先根据对话上下文初步识别用户意图,再利用异构图神经网络结合用户当前对话以及在其它对话中曾经的历史发言更精准地识别用户意图。同时,本发明还设计了一种降噪机制来避免无关历史信息带来的噪声,从而进一步提高了识别用户个性化表达的准确性。
本方法的一些实施例中,利用异构图神经网络结合用户历史发言,有效对用户个性化发言进行识别,提高了意图识别的准确性,进而为系统做出准确回复提供了帮助。
附图说明
图1为本发明实施例装置框图。
图2为本发明实施例意图识别装置原理图。
图3为本发明实施例粗粒度历史选择模块原理图。
图4为本发明实施例相关性重计算模块和识别结果调整装置。
图5为本发明实施例方法流程图。
具体实施方式
一种基于异构图神经网络的用户意图识别装置,意图识别装置1根据对话内容直接识别用户意图进而得到一个初步的识别结果;历史信息筛选装置2根据对话内容以及初步结果对用户历史信息进行筛选,得到与对话内容相关的用户历史信息;识别结果调整装置3结合对话内容,初步识别结果以及相关的历史信息对识别结果进行调整进而更准确地识别用户意图。
本发明包含两阶段的意图识别过程:初步识别和识别结果调整,初步识别阶段只根据上下文来识别用户意图,无法识别用户的个性化表达,存在一定的识别缺陷,而识别结果调整阶段结合用户历史发言对用户的个性化表达有了一定的了解,基于初步识别结果进行一定的调整,进而可以更精确地识别用户意图。
本发明致力于解决对话系统中的用户意图识别问题,即给定一个用户输入以及一段对话历史,本方法自动识别出用户意图,系统根据识别出的用户意图生成对应的回复,进而使整个对话过程连贯流畅。本方法也可以应用于情绪分析系统,通过分析用户当前的情绪状态,了解用户的内在需求,对症下药,设计出更适合用户需求的产品。具体实施例如下:
如图1所示,本发明由意图识别装置1,历史信息筛选装置2和识别结果调整装置3组成。所述意图识别装置1根据用户的对话内容直接识别用户意图得到初步的识别结果;所述历史信息筛选装置2根据对话内容以及初步的识别结果对用户历史信息进行筛选,得到与对话内容相关的用户历史信息;所述识别结果调整装置3采用异构图神经网络对当前对话内容以及与对话内容相关的用户历史信息进行编码,进而对所述初步的识别结果进行调整,识别最终的用户意图。各装置的实施细节如下:
意图识别装置:
本意图识别装置1将用户对话转化为对应的特征向量,并为对话中每句话得到一个初步的意图识别结果。因为输入是一个个句子,因此意图识别装置采用一个卷积神经网络(cnn)来提取句子特征,将输入的句子转换为特征向量。为了对句子间的上下文信息进行建模,本意图识别装置采用双向循环网络结构,网络单元采用长短期记忆网络(lstm)。长短期记忆网络可以有效处理序列信息,避免深度学习过程中的梯度消失和梯度爆炸问题。利用长短期记忆网络,得到包含上下文语境信息的句子特征向量,使用全连接层(ffn)作为分类器,对对话中的每句话进行分类,进而为对话中的每句话得到一个初步的意图识别结果。
如图2所示,意图识别装置1首先通过预训练好的词编码矩阵e将对话中离散的词
ut=e(xt)
其中对话由多个句子
ut=cnn(ut)
其中dc表示cnn输出的句子向量维数。接着,将{u1,u2,...,un}输入到双向长短期记忆网络(bilstm)来得到包含上下文信息的句子表示:
其中bilstm前向单元
pt=wα[ut,ht]+bα
其中[ut,ht]表示将ut和ht进行拼接,wα和bα是需要学习的参数,
历史信息筛选装置2:
本历史信息筛选装置2根据对话内容以及初步识别结果对用户历史信息进行筛选,避免引入大量噪声信息损害系统性能。这里用户历史信息指的是用户在其他对话中的历史发言,这种历史发言包含了用户的表达习惯,有助于识别用户个性化的表达。
为了从大量用户历史信息中筛选出与当前对话相关的内容,本历史信息筛选装置首先使用了一种粗粒度历史选择模块。首先,利用预训练词编码将文本中离散的词转换为连续的词向量表示,通过最大池化操作分别得到当前对话的向量表示和用户历史发言的向量表示。通过计算两者之间的余弦相似度得到用户历史发言与当前对话的相关性分数。同时,根据意图类别对用户历史发言进行归类,并根据相关性分数为每个类别选择前k个与当前对话最相关的历史发言。
然而,上述方法是一种粗粒度的过滤过程,为了更准确的计算用户历史发言与当前对话的相关性,本历史信息筛选装置使用了一种相关性重计算方法模块4来计算对话中每一句话与每个类别里k个历史发言之间的相关性分数,得到一个相似度矩阵。利用初步识别结果和相似度矩阵,该装置为每个类别里的k个历史发言重新计算与当前对话整体的相关性分数。
本历史信息筛选装置2根据对话内容以及意图识别装置得到的初步识别结果对用户历史发言进行筛选,主要包含两个模块:粗粒度历史选择模块和相关性重计算模块4。
如图3所示,粗粒度历史选择模块首先根据参与当前对话的用户列表从数据库中选出这些用户所有的历史发言。之后,使用预训练好的词编码矩阵将当前对话和用户历史发言转换为连续向量
之后,根据意图类别对用户历史发言进行归类,并根据相关性分数为每个类别选择前k个与当前对话最相关的历史发言。
如图4所示,相关性重计算模块根据对话内容和意图识别装置得到的初步识别结果重新计算用户历史发言与当前对话的相关性分数。这里计算第j个类别中k个句子与当前对话中n个句子之间的相关性得到一个相似度矩阵
其中ws是需要学习的参数,hn是对话中第n个句子的句子表示,
其中
识别结果调整装置3:
本识别结果调整装置3根据对话内容,意图识别装置得到的初步识别结果以及历史信息筛选装置得到的历史信息和相关性分数,对识别结果进行调整,进而对用户的意图进行更准确的识别。
本识别结果调整装置3采用一种异构图神经网络,对当前对话内容以及用户历史发言进行编码,进而识别用户个性化的表达。该异构图包含两种节点:句子节点和标签节点。其中,句子节点的向量表示来自于意图识别装置得到的句子向量表示,而标签节点利用历史信息筛选装置得到的与当前对话最相关的k个历史发言的向量表示,根据相关性分数加权平均来得到标签节点的向量表示。同时,该异构图包含两种边:用户边和标签边。其中,用户边用来表示句子节点之间的关系。在对话中,每个用户会受到自己以及其它用户的影响,除此之外还受到发言先后顺序的影响,因此根据用户以及发言顺序,用户边分为4类(自己前、自己后、他人前、他人后)。同时,为了表示用户之间影响的大小,使用一种基于相似度的注意力模块来对用户边的权重进行初始化。而标签边用来连接标签节点和句子节点,标签边的权重表示句子节点与不同标签之间的关系,这里使用意图识别装置得到的初步识别结果作为标签边权重的初始化。值得注意的是,异构图神经网络在训练过程中也会对边的权重进行更新。由于该异构图包含多种边关系,这里使用一种特定于边关系的消息传递策略rgcn对节点表示进行更新。最终,根据异构图神经网络得到的句子节点表示,利用全连接层(ffn)对每个句子节点进行分类,进而为每个句子得到一种更精确的意图识别结果。
本识别结果调整装置3根据对话内容,意图识别装置得到的初步识别结果以及历史信息筛选装置得到的历史信息和相关性分数,对识别结果进行调整,进而对用户的意图进行更准确的识别。
如图4所示,本识别结果调整装置3采用一种异构图神经网络,对当前对话内容以及用户历史发言进行编码,进而识别用户个性化的表达。该异构图包含两种节点:句子节点和标签节点。句子节点的表示使用意图识别装置得到的上下文感知的句子表示{h1,h2,...,hn}进行初始化,其中n表示对话中的句子数。标签节点的表示{e1,e2,...,es}使用标签下k个句子句子表示的加权平均得到:
其中s是标签数,
其中句子节点hi接收其它句子节点{h1,...,hn}传来的信息,总权重和为1。标签边权重使用意图识别装置得到的初始识别结果pi进行初始化:
其中句子节点hi接收标签节点{e1,...,es}传来的信息,总权重和为1。由于该异构图包含多种边关系,这里使用一种特定于边关系的消息传递策略rgcn对节点表示进行更新:
其中zj表示图中节点,αi,j和αi,i是边权重,
yt=sigmoid(wα[ut,ht,gt]+bα)
其中wα来自于意图识别装置分类器学习到的参数,使用sigmoid作为激活函数并使用交叉熵作为损失函数。
如图5所示,一种基于异构图神经网络的用户意图识别方法,具体步骤如下:
s1首先根据用户的对话内容直接识别用户意图得到初步的识别结果;
s2根据对话内容以及步骤s1得到的初步的识别结果对用户历史信息进行筛选,得到与对话内容相关的用户历史信息;
s3采用异构图神经网络对当前对话内容以及步骤s2得到的与对话内容相关的用户历史信息进行编码,进而对步骤s1得到的初步的识别结果进行调整,识别最终的用户意图。
- 还没有人留言评论。精彩留言会获得点赞!