一种视听双模态的360度全方位说话人定位方法
本发明涉及说话人定位的技术领域,具体涉及一种视听双模态的360度全方位说话人定位方法。
背景技术:
随着互联网、移动智能终端和智能机器人的快速发展,人与机器之间的交互也越来越频繁,以人为中心、自然、高效是发展新一代人机交互方式的主要目标。而在实际的人机交互系统中,目标定位功能是交互系统中的第一个需要解决的重要问题。获取了目标用户位置后,机器可以进行后续的定向语音识别、情感识别以及为用户提供定向服务等操作,且交互系统可以在期望方向上拾取更准确的目标信息,从而提供精准的服务和反馈。
现有的目标说话人定位方法往往依赖于计算机视觉或是基于计算机听觉的方法,这些单模态的定位方法容易受到噪声、光线等环境因素的影响,系统的可靠性较低。
一些方法把图像和声源进行融合,但这些方法往往受限于定位设备的有限的定位方位角,无法对其他位置的说话人进行定位。
已公开的改进方案注重利用麦克风或者其他传感器进行辅助定位,之后利用转动平台等带动摄像头进行视觉空间定位。但这些方法存在一定的定位延时,如果目标说话人移位则定位效率、定位精度都存在不确定性。
已公开的全景深度图像拼接生成方法往往需要大量的时间完成,对说话人定位的时效性存在不利影响。
在基于计算机视觉的人脸图像定位中,当人脸位于图像中心区域附近时定位效果好,而远离中心区域时,定位精度会明显降低,甚至出现定位错误。
在基于线性麦克风阵列的说话人定位中,当说话人的方位与线性麦克风阵列的中垂线接近时,定位效果好;而当说话人远离线性麦克风的中垂线时,定位精度会明显降低,甚至出现定位错误。
技术实现要素:
有鉴于此,本发明提供了一种视听双模态的360度全方位说话人定位方法,包括以下步骤:
s1、依据说话人语音信号到达环形麦克风阵列所在圆直径的麦克风上的时间差,获取声源信息降维;利用降维后的声源信息对目标说话人进行声源粗定位;
s2、图像拼接决策与视觉空间定位:基于所述声源粗定位的结果判断说话人是否位于说话人所在方位最近两枚摄像头的摄像画面交接区域,并决策开启的所述环形摄像头组中摄像头的方位、数量以及是否进行图像拼接;之后基于所述图像拼接处理后的摄像画面进行视觉空间定位;
s3、多模态融合定位:基于所述声源粗定位和视觉空间定位中对说话人的定位结果,进行视听模态的决策级融合,计算出视听模态融合定位结果。
实施本发明的技术方案带来的有益效果是:本发明可以在360全方位的环境下准确高效的定位到目标说话人。
附图说明
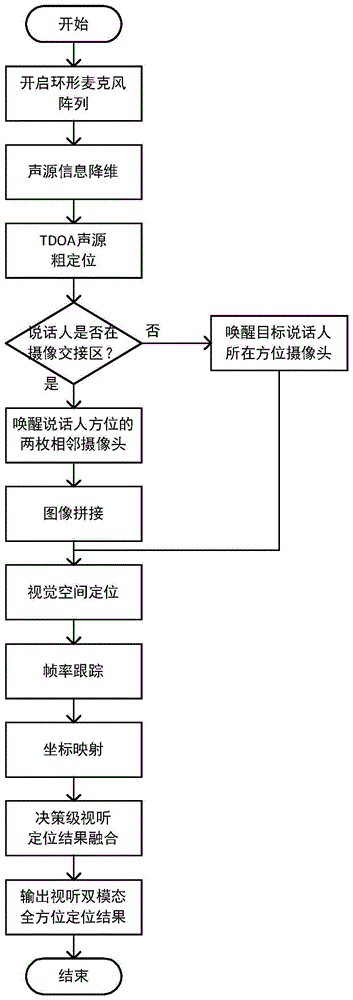
图1为本发明所述视听双模态的360度全方位说话人定位方法的流程图;
图2为语音信号过环形麦克风阵列所在圆直径的麦克风的示意图;
图3为摄像画面的交接区域示意图。
具体实施方式
本发明是为了解决现有基于现有的单模态说话人定位方法可靠性低,以及现有的多模态说话人定位方法受限于有限的定位方位角、需要依赖转动平台才能完成定位的问题,提出了一种视听双模态的360度全方位说话人定位方法。
请参考图1,一种视听双模态的360度全方位说话人定位方法,包括以下步骤:
s1:依据说话人语音信号到达环形麦克风阵列中麦克风a和麦克风b的时间差,其中,a和b是环形麦克风阵列所在圆的直径上的麦克风,且目标说话人与圆心的连线和直径ab形成的夹角,相较与其他位于直径的麦克风形成的夹角更接近于直角;请参考图2,以进行声源信息降维;利用降维后的声源信息对目标说话人进行声源粗定位;
所述的声源粗定位采用的环形麦克风阵列含有偶数个数的麦克风,选取环形麦克风阵列中合适的两枚麦克风,进行时延估计和位置估计已完成声源定位,可以通过到达时间差(timedifferenceofarrival,tdoa)声源定位的方法对目标说话人进行粗定位;
其中,所述的麦克选取部分的主要目的减少定位麦克风以简化声源定位步骤,将环形麦克风的说话人定位问题降维至线性麦克风阵列的说话人定位问题,声源信息降维方法的主要内容如下:
s111:标记所述的环形麦克风阵列中的所有麦克风并分组,过环形麦克风阵列同一直径上的两枚麦克风记为同一组,设环形麦克风阵列中的麦克风总数为m,设各个麦克风分组的编号为1,2,…,
s112:用环形麦克风阵列接收说话人的声音信号,计算每组麦克风中的两枚麦克风接收到说话人声音信号的时间差,设时间差最大的麦克风组为λ,则选取编号为
以所述麦克选择方法选取的两枚麦克风作为线性麦克风阵列,在进行说话人声源定位时,因为说话人的方位相对于该组线性麦克风阵列的中垂线最近,所以利用这两个麦克风进行声源定位的定位精度相对较高。
所述tdoa声源定位方法中时延估计部分的主要内容如下:
s121:假设步骤s112中所选取的两枚麦克风mi和mj接收的音频信号分别表示为:xi(t)=ais(t-τi)+ni(t),xj(t)=ajs(t-τj)+nj(t),设两个麦克风接收的信号xi(t)和xj(t)的相关函数为:
s122:假设声源信号与噪声相互独立,且两路噪声ni(t)和nj(t)互不相关,信号s(t)是平稳随机信号,则可将相关函数化为:
s123:当τ=τi-τj时,
上式中s(t)表示声源信号,τi和τj分别表示声源信号到两个麦克风mi和mj的传播时间,ai和aj分别表示两路声音信号传播过程中的衰减因子,ni(t)和nj(t)分别表示两路信号引入的噪声。
所述的tdoa声源定位方法中所述位置估计的主要内容如下:
s131:将声波简化为平面波,忽略声波的振幅差,则可以近似地认为传声器阵列单元接收到的地面信号之间只有一个简单的延迟差,在环形麦克风阵列内一个麦克风接收到的信号作为参考信号,则另一个麦克风接收到的信号的延迟计算为:
s132:将将s131的计算结果代入s123中时延估计的计算公式,则可计算声源相对于麦克风阵列的方位角:
式中,d是两个麦克风之间的距离(即环形麦克风阵列所在圆直径),c是声波在空气中的传播速度。
s2:依据生源粗定位得到的目标说话人方位,以及环形摄像头组中摄像头的规格、拍摄角、摆放,判断目标说话人是否位于其所在方位最近两枚摄像头的摄像画面交接区域,如图3所示,当说话人位于摄像画面交接区域时,唤醒说话人所在方位的两个相邻摄像头,并对这两个摄像头的摄像画面进行图像拼接;否则直接唤醒说话人所在方位摄像头,不进行图像拼接。
所采用的环形摄像头组为由三个以上(n个)摄像头组成,设每个所述摄像头的拍摄范围角度为q,要求q×n>360°。
所述的视觉空间定位中,采用人脸检测算法、进行人脸检测并定位,并将定位结果转换到世界坐标系。具体视觉空间定位方法如下:
s221:选取人脸检测算法,调用人脸检测分类器,捕捉目标人脸并用矩形框画出;
s222:记录当前画面帧人脸矩形框四个角的位置坐标(x1,y1),(x1,y2),(x2,y1),(x2,y2),坐标系中心为当前摄像画面中心点;
s223:计算人脸中心位置
s224:计算人脸方位角:
s225:计算人脸俯仰角:
s226:将人脸图像定位结果转换到世界坐标系(俯仰角不变);设环形规则分布的360度全景摄像头组共有n个摄像头,以顺时针方向从1到n-1给摄像头编号,方向1号摄像头拍摄中心为世界坐标系中心,则由在第k个摄像机拍摄到的人脸由图像坐标转换世界坐标时,有
其中,km指图像拼接时取得的编号较小的摄像头编号。
s3:基于所述声源粗定位和视觉空间定位中对说话人的定位结果,进行视听模态的决策级融合,计算出视听模态融合定位结果;
所述的多模态融合定位主要包含帧率跟踪、坐标映射以及决策级视听模态定位结果融合。其详细内容如下:
s31:使用帧率跟踪等方法,将图像和声音信号两者数据在时间上保持同步传输和处理,保证视觉空间定位结果与声源定位结果在时间上的一致性;
s32:完成全方位坐标映射,由于在s226中已经把视角空间定位结果转换到世界坐标系,当前仅需将声源定位结果转换到世界坐标系即可完成坐标映射,将声源定位转换到世界坐标的结果转换到如下:
θsound=θt+θω
式中,θω为所选取麦克风组的近世界坐标系麦克风修正到世界坐标系原点的角度补偿值;
s33:所述的决策级视听模态定位结果融合主要通过依据环境噪声、环境亮度等条件的条件独立,计算出所述声源定位结果、视频定位得到的方位角的融合权重γimage、γsound,从而得到目标说话人融合定位的方位角,并取视觉空间定位的得到的目标说话人俯仰角为最终融合的俯仰角,其中,γsound+γimage=1,且0≤γsound≤1,0≤γimage≤1。
具体内容如下:
s331:由人脸矩阵框四角坐标计算人脸大小在整幅图像的占比,即人脸大小评价系数:
s332:由双眼坐标(xel,yel),(xer,yer)计算人脸角度评价系数
s333:由图像平均亮度bave计算图像明亮度系数
s334:计算视觉空间定位的融合权重:γimage=ω1γ1+ω2γ2+ω3γ3,并计算出声源定位结果的融合权重γsound=1-γimage,其中ωi为权重补偿值,且ω1+ω2+ω3=1;
s335:计算融合后的目标说话人方位角:θ=γsoundθsound+γimageθimage;而目标说话人的俯仰角为视觉空间定位得到的俯仰角
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!