一种索引管理的方法与流程
1.本发明涉及海量数据管理技术领域,具体为一种索引管理的方法。
背景技术:
2.在大数据业务中,数据一般可基于elasticsearch搜索服务器的索引方式存储和检索。
3.通常情况下,数据存储的索引是根据数据入elasticsearch库时确定的,即数据索引名称通常根据入库时间确定,但用户业务场景通常更关注的是数据的发布时间,即在业务数据检索时需要检索发布时间在一个区间内的数据。
4.由于业务数据存储按照入库时间顺序排序和业务检索索引根据发布时间检索之间的不一致性,为了达到业务检索发布时间在一个区间内数据的目的,通常需要在全数据存储索引中检索,导致检索消耗变高,检索性能变慢,为了解决上述问题,我们提出一种索引管理的方法。
技术实现要素:
5.本发明的目的在于提供一种索引管理的方法,以解决上述背景技术中提出的问题。
6.为实现上述目的,本发明提供如下技术方案:一种索引管理的方法,包括索引管理器,所述索引管理器包括服务端和客户端,所述服务端包括postgres、zookeeper、yq数据处理、es入库程序,所述postgres为开源数据库、zookeeper为分布式协调服务、yq数据处理为获取索引信息并处理数据的外部服务、es入库程序为数据存入程序,所述索引管理器工作步骤如下:
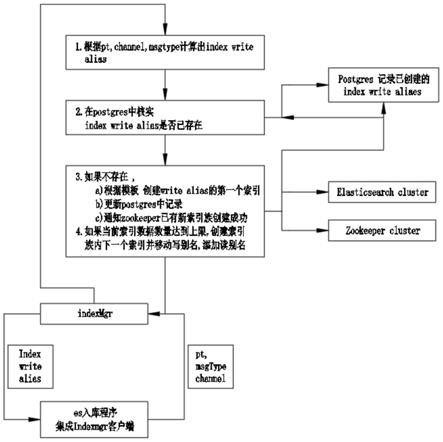
7.步骤1:数据入库过程
8.1.1.根据入库数据的pt,channel,msgtype计算出index write alias,所述pt为时间标识、channel为媒体类型标识、msgtype为信息类型标识、index write alias为索引写别名;
9.1.2.在postgres中核实index write alias是否已存在;
10.1.3.如果不存在,创建index write alias的第一个索引,更新postgres中的记录,并通知zookeeper已有新索引族创建成功;
11.1.4.如果当前索引数据数量达到上限,创建索引族内下一个索引并移动写别名,添加读别名。
12.步骤2:数据入库结果
13.经yq数据处理程序、es入库程序存储至客户端。
14.步骤3:业务检索过程
15.3.1.根据zookeeper状态通知,确定本地索引记录是否过期;
16.3.2.如果过期,从postgres中刷新本地索引数据;
17.3.3.根据pc,channel,msgtype计算出index read aliases,并剔除不存在的索引族。
18.优选的,所述索引管理器索引算法中确定索引名称过程为:
19.当t
pubtime
<=t
sparseend
时,索引族写别名和读别名为配置项namewritealias
sparse
和namereadalias
sparse
,所述t
pubtime
为稀疏数据区间变更时间、t
sparseend
为稀疏数据区间截止时间、namewritealias
sparse
为稀疏数据区间索引写别名、namereadalias
sparse
为稀疏数据区间索引读别名;
20.不满足上述条件时,当t
pubtime
∈[t0+n*t
interval
,t0+(n+1)*t
interval
],其中n∈z时,索引族写别名和读别名为t0+n*t
interval
所在日期添加上指定的prefix、suffix,所述t0为基准时间、t
interval
为索引时间跨度、prefix为正常数据区间索引名称的前缀、suffix为正常数据区间索引名称的后缀。
[0021]
优选的,所述索引管理器索引算法中滚动索引过程为:在数据量密集的情况下,单个索引名称中对应的数据流会超过n
max
,所述n
max
为单个索引最大数据量,这种情况下,会对索引名称滚动形成后续索引,其中索引读别名会添加到所有滚动的索引中,索引写别名只会指向最后一个滚动索引。
[0022]
优选的,所述索引管理器索引算法中的数据排序方式,索引族是根据数据的发布时间确定的,不同索引族内的数据是严格依据发布时间排序;索引族内不同索引之间数据是根据入库时间顺序确定的。
[0023]
优选的,所述索引管理器客户端进行业务检索时,根据检索的发布时间区域,获取该时间区域内实际存在的所有索引族的读别名,即可在显著减少待检索索引范围内的情况下获取全量符合要求的数据。
[0024]
优选的,所述客户端基于服务端提供api,所述api为应用程序编程接口,用于在数据入库时提供索引族的写别名,并在索引族不存在时创建索引族的第一个索引,或在数据检索时提供一段时间内所有存在的所有族的写别名。
[0025]
优选的,所述客户端可提供代码包,集成到业务段代码中使用,根据客户需求包装扩展适合业务需要的接口。
[0026]
与现有技术相比,本发明的有益效果是:该索引管理的方法,能够在数据入elasticsearch库时,其索引族由数据发布时间确定而不是数据入库时间确定,且业务检索时不再检索全部索引,而是根据检索的发布时间区间,确定待检索的部分索引族,能够降低业务检索中的消耗,提高检索性能,在海量数据中能够有快速且有针对性的获取目标信息的位置。
附图说明
[0027]
图1为本发明数据入库过程的流程图。
[0028]
图2为本发明数据入库结果的流程图。
[0029]
图3为本发明业务检索过程的流程图。
具体实施方式
[0030]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完
整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0031]
请参阅图1、图2、图3,本发明提供一种技术方案:一种索引管理的方法,包括索引管理器,所述索引管理器包括服务端和客户端,所述服务端包括postgres、zookeeper、yq数据处理、es入库程序,所述postgres为开源数据库、zookeeper为分布式协调服务、yq数据处理为获取索引信息并处理数据的外部服务、es入库程序为数据存入程序,所述索引管理器工作步骤如下:
[0032]
步骤1:数据入库过程
[0033]
1.1.根据入库数据的pt,channel,msgtype计算出index write alias,所述pt为时间标识、channel为媒体类型标识、msgtype为信息类型标识、index write alias为索引写别名;
[0034]
1.2.在postgres中核实index write alias是否已存在;
[0035]
1.3.如果不存在,创建index write alias的第一个索引,更新postgres中的记录,并通知zookeeper已有新索引族创建成功;
[0036]
1.4.如果当前索引数据数量达到上限,创建索引族内下一个索引并移动写别名,添加读别名。
[0037]
步骤2:数据入库结果
[0038]
经yq数据处理程序、es入库程序存储至客户端。
[0039]
步骤3:业务检索过程
[0040]
3.1.根据zookeeper状态通知,确定本地索引记录是否过期;
[0041]
3.2.如果过期,从postgres中刷新本地索引数据;
[0042]
3.3.根据pc,channel,msgtype计算出index read aliases,并剔除不存在的索引族。
[0043]
所述索引管理器索引算法中确定索引名称过程为:
[0044]
当t
pubtime
<=t
sparseend
时,索引族写别名和读别名为配置项namewritealias
sparse
和namereadalias
sparse
,所述t
pubtime
为稀疏数据区间变更时间、t
sparseend
为稀疏数据区间截止时间、namewritealias
sparse
为稀疏数据区间索引写别名、namereadalias
sparse
为稀疏数据区间索引读别名;
[0045]
不满足上述条件时,当t
pubtime
∈[t0+n*t
interval
,t0+(n+1)*t
interval
],其中n∈z时,索引族写别名和读别名为t0+n*t
interval
所在日期添加上指定的prefix、suffix,所述t0为基准时间、t
interval
为索引时间跨度、prefix为正常数据区间索引名称的前缀、suffix为正常数据区间索引名称的后缀。
[0046]
所述索引管理器索引算法中滚动索引过程为:在数据量密集的情况下,单个索引名称中对应的数据流会超过n
max
,所述n
max
为单个索引最大数据量,这种情况下,会对索引名称滚动形成后续索引,其中索引读别名会添加到所有滚动的索引中,索引写别名只会指向最后一个滚动索引。
[0047]
所述索引管理器索引算法中的数据排序方式,索引族是根据数据的发布时间确定的,不同索引族内的数据是严格依据发布时间排序;索引族内不同索引之间数据是根据入
库时间顺序确定的。
[0048]
所述索引管理器客户端进行业务检索时,根据检索的发布时间区域,获取该时间区域内实际存在的所有索引族的读别名,即可在显著减少待检索索引范围内的情况下获取全量符合要求的数据。
[0049]
所述客户端基于服务端提供api,所述api为应用程序编程接口,用于在数据入库时提供索引族的写别名,并在索引族不存在时创建索引族的第一个索引,或在数据检索时提供一段时间内所有存在的所有族的写别名。
[0050]
所述客户端可提供代码包,集成到业务段代码中使用,根据客户需求包装扩展适合业务需要的接口。
[0051]
说明项:
[0052]
elasticsearch为开源全文检索引擎,indexmgr为维护elasticsearch索引和索引数据元数据的服务,并向外提供索引检索服务,indexmgr为索引管理器的实现方式,索引管理器的核心是建立一套灵活可配置的计算机制,实现从数据的发布时间计算出数据所在索引名称(包括别名在内)的方法。
[0053]
索引族:在对数据的发布时间计算出的数据存储所在的索引名称,一个索引族至少包括一个实际存在的索引;
[0054]
索引族滚动索引:当一个索引族中的数据超过预定的最大数据量时,该索引族中的数据会滚动存储到若干个实际索引中;
[0055]
索引族读别名:一个索引族中的所有索引有统一的一个读别名,用于数据检索;
[0056]
索引族写别名:一个索引族中的最后一个索引有一个写别名,用于数据入库。
[0057]
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
[0058]
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1