基于工业互联网远程恶意代码识别方法与流程
本发明涉及一种安全领域,特别是涉及一种基于工业互联网远程恶意代码识别方法。
背景技术:
当前网络空间安全的主要威胁之一是恶意代码通过系统漏洞或垃圾邮件等大规模传播,进而对信息系统所造成的破坏。随着网络攻防的博弈,恶意代码呈现出隐形化、多态化、多歧化特点,因此,对恶意代码进行分析十分必要。专利申请号2020102727302,名称为“恶意代码同源性分析方法和恶意代码同源性分析装置”,公开了:获取待分析代码;利用分类模型,对该待分析代码进行识别,得到识别结果;其中,该分类模型是利用预定的恶意代码样本的结构特征训练得到的;该结构特征由基于恶意代码样本切片过滤条件,并对恶意代码样本进行二进制代码过程间切片而得到;根据识别结果,确定该待分析代码所属的网络攻击组织或网络安全事件。通过该技术方案,使用分类模型对待分析代码进行分类识别,判断该待分析代码是否与已知网络攻击组织或事件的恶意代码样本具有同源性进而确定待分析代码是否为恶意代码,由此解决了如何提高分析恶意代码同源性的效率和准确率的问题。
技术实现要素:
本发明旨在至少解决现有技术中存在的技术问题,特别创新地提出了一种基于工业互联网远程恶意代码识别方法。
为了实现本发明的上述目的,本发明提供了一种基于工业互联网远程恶意代码识别方法,包括以下步骤:
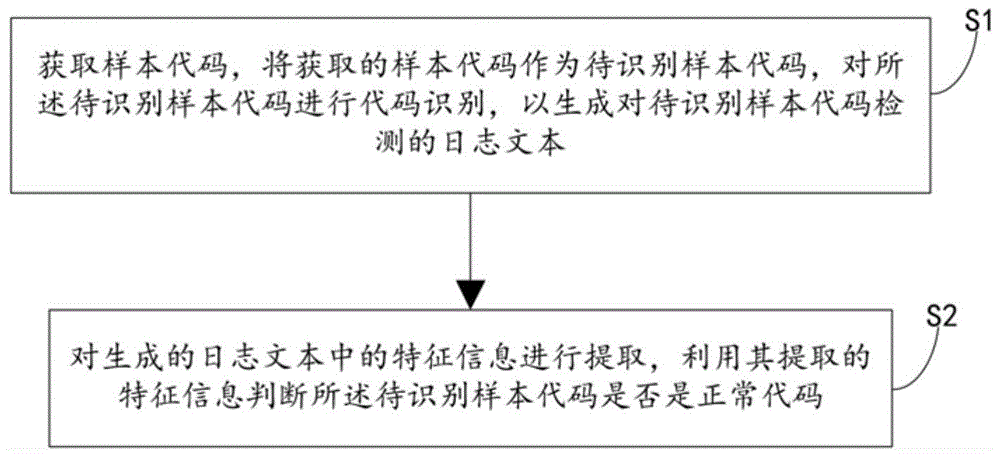
s1,获取样本代码,将获取的样本代码作为待识别样本代码,对所述待识别样本代码进行代码识别,以生成对待识别样本代码检测的日志文本本;
s2,对生成的日志文本中的特征信息进行抽取,利用其抽取的特征信息判断所述待识别样本代码是否是正常代码:
若待识别样本代码是正常代码,则不对待识别样本代码进行标识;
若待识别样本代码不是正常代码,则对待识别样本代码进行标识;将其标识的待识别样本代码存储于本地恶意代码数据库或/和云端恶意代码数据库。将其识别的恶意代码存储于数据库有利于快速分辨,提高效率。
在本发明的一种优选实施方式中,在步骤s1中,包括以下步骤:
s11,统计获取的样本代码总个数,记为m;
s12,向云端获取m个不同的序列号,分别记作第1序列号、第2序列号、第3序列号、……、第m序列号,本地端对第m序列号进行以下操作:
idm=(serialnumberm,hash[md5]),
其中,serialnumberm表示第m序列号;m为小于或者等于m的正整数;
hash[md5]表示采用md5的摘要单向算法;
idm表示第m序列号serialnumberm所对应的唯一id号;
(serialnumberm,hash[md5])表示对第m序列号serialnumberm采用md5的摘要单向算法的二元组表达;
s13,将m个唯一id号分别依次作为m个样本代码的识别代码名称。起到安全唯一性。
在本发明的一种优选实施方式中,在云端对生成的m个不同的序列号进行以下操作:
其中,
对生成的唯一id号
在本发明的一种优选实施方式中,记累计值t=0;在步骤s2中,利用其抽取的特征信息判断所述待识别样本代码是否是正常代码的方法为:
其中,kj,μ是与日志文本中抽取的特征i相似的特征j对恶意代码集合pi,j中恶意代码μ的关联度;
pi,j是恶意代码集合;
μ是恶意代码集合pi,j中的恶意代码;
η是日志文本中抽取的特征i和与日志文本中提取的特征i相似的特征j的平衡系数,取值范围(0,1];
λ是补偿系数,
qi,j是日志文本中抽取的特征i和与日志文本中提取的特征i相似的特征j所得到的恶意值;
若恶意值qi,j大于或者等于预设恶意阈值,则t=t+1;
若累计值t大于或者等于预设累计阈值,则待识别样本代码是恶意代码。
综上所述,由于采用了上述技术方案,本发明能够诊断恶意代码,增强系统安全性。
本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1是本发明流程示意框图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
本发明公开了一种基于工业互联网远程恶意代码识别方法,如图1所示,包括以下步骤:
s1,获取样本代码,将获取的样本代码作为待识别样本代码,对所述待识别样本代码进行代码识别,以生成对待识别样本代码检测的日志文本;
s2,对生成的日志文本中的特征信息进行抽取,利用其抽取的特征信息判断所述待识别样本代码是否是正常代码:
若待识别样本代码是正常代码,则不对待识别样本代码进行标识;
若待识别样本代码不是正常代码,则对待识别样本代码进行标识;将其标识的待识别样本代码存储于本地恶意代码数据库或/和云端恶意代码数据库。
在本发明的一种优选实施方式中,在步骤s1中,包括以下步骤:
s11,统计获取的样本代码总个数,记为m;
s12,向云端获取m个不同的序列号,分别记作第1序列号、第2序列号、第3序列号、……、第m序列号,本地端对第m序列号进行以下操作:
idm=(serialnumberm,hash[md5]),
其中,serialnumberm表示第m序列号;m为小于或者等于m的正整数;
hash[md5]表示采用md5的摘要单向算法;
idm表示第m序列号serialnumberm所对应的唯一id号;
(serialnumberm,hash[md5])表示对第m序列号serialnumberm采用md5的摘要单向算法的二元组表达;
s13,将m个唯一id号分别依次作为m个样本代码的识别代码名称。
在本发明的一种优选实施方式中,在云端对生成的m个不同的序列号进行以下操作:
其中,
对生成的唯一id号
若云端接收到的识别代码名称存在于云端唯一id号数据库,则云端将接收到的识别代码名称所对应的恶意代码存储于云端恶意代码数据库;
若云端接收到的识别代码名称不存在于云端唯一id号数据库,则云端将接收到的识别代码名称所对应的恶意代码存储于云端恶意代码验证数据库。其云端对存储于云端恶意代码验证数据库中的待验证代码执行以下操作:
第一步,对所述待验证代码进行代码识别,以生成对待验证代码检测的云端日志文本;
第二步,对第一步中生成的云端日志文本中的特征信息进行云端抽取,利用其云端抽取的特征信息判断所述待验证代码是否是正常代码:
若待验证代码是正常代码,则将待验证代码从云端恶意代码验证数据库中删除;
若待验证代码不是正常代码,则将待验证代码从云端恶意代码验证数据库中删除,并将待验证代码连同待验证代码对应的识别代码名称存储于云端恶意代码数据库。在第二步中,利用其云端抽取的特征信息判断所述待验证代码是否是正常代码的方法为:
其中,ki′,μ″是日志文本中云端抽取的特征i′对恶意代码集合pi′,j″中云端恶意代码μ′的关联度;
kj′,μ″是与日志文本中云端抽取的特征i′相似的特征j′对云端恶意代码集合pi′,j″中恶意代码μ′的关联度;
pi′,j″是云端恶意代码集合;
μ′是云端恶意代码集合pi′,j″中的恶意代码;
η′是日志文本中云端抽取的特征i′和与日志文本中提取的特征i′相似的特征j′的云端平衡系数,取值范围(0,1];
λ′是云端补偿系数,
qi′,j″是日志文本中云端抽取的特征i′和与日志文本中提取的特征i′相似的特征j′所得到的恶意值。起到了防止恶意代码的遗漏。
在本发明的一种优选实施方式中,记累计值t=0;在步骤s2中,利用其抽取的特征信息判断所述待识别样本代码是否是正常代码的方法为:
其中,ki,μ是日志文本中抽取的特征i对恶意代码集合pi,j中恶意代码μ的关联度;
kj,μ是与日志文本中抽取的特征i相似的特征j对恶意代码集合pi,j中恶意代码μ的关联度;
pi,j是恶意代码集合;
μ是恶意代码集合pi,j中的恶意代码;
η是日志文本中抽取的特征i和与日志文本中提取的特征i相似的特征j的平衡系数,取值范围(0,1];
λ是补偿系数,
qi,j是日志文本中抽取的特征i和与日志文本中提取的特征i相似的特征j所得到的恶意值;
若恶意值qi,j大于或者等于预设恶意阈值,则t=t+1;
若恶意值qi,j小于预设恶意阈值,则t=t+0;
s22,判断下一个特征,执行步骤s21,直至特征执行完毕后,执行步骤s23;
s23,若累计值t大于或者等于预设累计阈值,则待识别样本代码是恶意代码;
若累计值t小于预设累计阈值,则待识别样本代码是正常代码。
尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!