一种基于图注意力网络的社交媒体谣言检测方法和系统
本发明属于人工智能中的深度学习和自然语言处理技术领域,更具体地,涉及一种基于图注意力网络(graphattentionnetwork,简称gat)的社交媒体谣言检测方法和系统。
背景技术:
如今,越来越多的人在社交平台上分享自己的意见、经验和观点;以twitter为例,其每天发送的新推文超过5亿条,即每秒近5787条。
然而,如今的许多社交平台已经逐渐成为滋生虚假消息和散布谣言的理想场所。因此,如何快速、准确的识别社交平台上的谣言是当务之急。目前的谣言检测方法主要分为基于机器学习和基于深度学习两类。
针对基于机器学习的谣言检测方法而言,其集中于谣言的浅层特征,其中有三个特征效果突出,一是文本特征,如用户的评论和回复等;二是用户特征,如用户的关注数,用户的粉丝数,用户的星座,生日,兴趣等;三是传播特征,如传播的时间序列,转发的帖子数等。利用这些特征训练机器学习算法,如支持向量机、决策树、随机森林等来实现谣言检测。然而,基于机器学习的这些谣言检测方法主要依赖于特征工程,提取特征的效率较低,从而导致检测过程非常费时费力。
针对基于深度学习的谣言检测方法而言,虽然通过卷积神经网络、循环神经网络、长短期记忆网络等深度学习模型,能自动化的从谣言事件中提取特征,从而解决了现有基于机器学习的谣言检测方法提取特征效率低的问题。但是,现有基于深度学习的谣言检测方法仍然存在一些不可忽略的缺陷:第一、卷积神经网络设计的初衷是用于捕获结构化数据的特征,比如图像数据等,循环神经网络,长短期记忆网络等模型主要是用于处理固定长度的数据,而在谣言事件级别检测中,每个谣言事件的帖子数不是固定的,因此该基于深度学习的谣言检测方法不能高效地提取谣言传播结构特征和聚合邻接节点特征,进而导致谣言检测准确率偏低;第二、在谣言事件中,原贴子往往包含着更多有利于谣言检测的特征,随着谣言的传播,越远离原贴子的节点包含的利于谣言检测的特征越少,这也会导致谣言检测准确率偏低;第三,基于深度学习的谣言检测方法大部分都是基于传统的词向量模型(例如one-hot、word2vec、tf-idf等)来表示文本,该词向量模型表示文本的能力有限,不能根据语境动态调整词语对词向量表示,进而会导致谣言检测准确率偏低。
技术实现要素:
针对现有技术的以上缺陷或改进需求,本发明提供了一种基于图注意力网络的社交媒体谣言检测方法和系统。其目的在于,解决现有基于深度学习的谣言检测方法由于不能高效的提取谣言传播结构特征和聚合邻接节点特征,导致影响谣言检测准确度的技术问题;以及由于远离原贴子的节点包含的有利于谣言检测的特征较少,导致影响谣言检测准确度的技术问题;以及由于使用传统词向量对文本进行编码并不能根据语境动态调整词向量,导致影响谣言检测准确度的技术问题。
为实现上述目的,按照本发明的一个方面,提供了一种基于图注意力网络的社交媒体谣言检测方法,包括如下步骤:
(1)获取待检测的谣言事件,对待检测的谣言事件对应的文本进行预处理,以得到预处理后的文本,并使用bert-large-cased预训练词向量模型将预处理后的文本转换成文本向量矩阵。
(2)根据步骤(1)得到的待检测的谣言事件对应的用户之间的转发、评论或回复关系构建用户关系结构图表示为g=(v,e),并根据该用户关系结构图构建邻接矩阵,其中v表示节点集合,每个节点表示待检测的谣言事件对应的一个用户,e表示边的集合,每条边表示两个用户之间的转发、评论或回复关系。
(3)将步骤(1)得到的文本向量矩阵、以及步骤(2)得到的邻接矩阵,输入预先训练好的谣言检测模型中,以得到最终的谣言检测结果。
优选地,步骤(1)首先是使用正则表达式对待检测的谣言事件对应的文本进行清洗(即删除一些特殊符号以及网页链接等),然后使用bert-large-cased预训练词向量模型将清洗后的每条文本转换成1024维向量,所有文本对应的1024维向量构成文本向量矩阵。
步骤(3)中,根据用户关系结构图构建邻接矩阵具体为:对谣言事件对应的节点进行编号1到n,然后对于其中任意两个节点i和j而言,如果对应的用户之间有转发、评论或回复关系,则邻接矩阵中第i行第j列的元素aij=1,否则为0,这样就可以得到维度为n·n的邻接矩阵a,其中n为谣言事件对应的节点总数,即谣言事件对应的用户总数,其中i和j均∈[1,n]。
优选地,谣言检测模型包含依次连接的第一图注意力网络、第二图注意力网络、原帖子增强网络,以及全连接网络;
第一图注意力网络包括n个单头图注意力网络,其中n的取值为大于1的自然数;
对于单头图注意力网络而言,其具体结构为:
第一层是特征变换层,输入n·d的文本向量矩阵,利用一个d·h的矩阵,输出一个n·h特征矩阵,其中h为隐含层向量长度,d为编码后的文本向量长度;
第二层是注意力计算层,其输入为第一层得到的n·h矩阵和n·n用户行为关系的邻接矩阵,输出为n·n的注意力权值矩阵。
第三层是邻接顶点特征聚合层,其将第一层n·h矩阵和第二层得到n·n的注意力权值矩阵进行矩阵乘法,以得到n·h的特征矩阵。
优选地,对于第一图注意力网络而言,其通过将n个单头图注意力网络输出的n·h的特征矩阵进行拼接,就能得到一个n·(n*h)的特征矩阵;
第二图注意力网络是一个单头图注意力网络,其输入为第一图注意力网络输出的n·(n*h)的特征矩阵,输出为n·h的特征矩阵。
优选地,原帖子增强网络的具体结构为:
第一层是拼接层,其输入为经过第二图注意力网络输出的特征矩阵,该层使用n·h的原帖子特征矩阵进行拼接,输出为经过增强后的特征矩阵,维度为n·2h;
第二层是池化层,其输入为增强后的特征矩阵,输出为经过池化后的特征向量,维度为1·2h;
全连接网络具体结构为:
第一层是特征变换层,其输入为经过原帖子增强网络池化后的特征向量,该层使用2h·h维的权重矩阵,输出维度为h的特征向量。
第二层是特征降维层,其输入为第一层输出的特征向量,该层使用h·h/2维的权重矩阵,输出为降维后的特征向量,维度为h/2。
第三层是谣言检测结果层,其输入为第二层降维后的特征向量,该层使用h/2·2维权重矩阵,输出为谣言检测结果。
优选地,谣言检测模型是通过以下步骤训练得到的:
(3-1)获取谣言数据,按照8:2的比例将谣言数据划分为训练集和测试集,对训练集中每个谣言数据对应的文本进行预处理,以得到预处理后的文本,使用bert-large-cased预训练词向量模型将预处理后的文本转换成文本向量矩阵x,根据训练集中每个谣言数据对应的用户之间的转发、评论或回复关系构建用户关系结构图,并根据该用户关系结构图构建邻接矩阵a。
(3-2)将步骤(3-1)得到的文本向量矩阵x和邻接矩阵a输入到第一图注意力网络中,以得到n·(n*h)的特征向量矩阵t;
(3-3)将步骤(3-1)得到的文本向量矩阵x和邻接矩阵a输入第一图注意力网络中第一个单头图注意力网络的特征变换层,以得到维度为n·h的特征矩阵h;
(3-4)将步骤(3-3)得到的特征矩阵h输入第一图注意力网络中第一个单头图注意力网络的注意力计算层,以得到每个谣言事件对应的节点之间的注意力系数;
(3-5)对步骤(3-4)得到的每个谣言事件对应的节点之间的注意力系数eij进行归一化处理,以得到归一化后的注意力系数αij;
(3-6)将步骤(3-3)得到的特征矩阵h和步骤(3-5)归一化后的注意力系数αij输入第一图注意力网络中第一个单头图注意力网络的邻接顶点特征聚合层,以得到n·h的特征矩阵;
(3-7)针对第一图注意力网络中剩余的n-1个单头图注意力网络中的每一个而言,重复上述步骤(3-3)至(3-6),从而得到n-1个维度为n·h的特征矩阵,将这n-1个维度为n·h的特征矩阵与步骤(3-6)得到的特征矩阵进行拼接,从而得到n·(n*h)的特征矩阵;
(3-8)对步骤(3-2)得到的特征向量矩阵t进行drop_out处理,以得到n·(n*h)的特征向量矩阵t`,其中随机失活的比例为0.5。
(3-9)将步骤(3-8)得到的特征向量矩阵t`和步骤(3-1)得到的邻接矩阵a输入到第二图注意力网络中,以得到每个谣言数据的高阶表示所对应的向量矩阵w,其维度为n·h。
(3-10)将步骤(3-9)得到的向量矩阵w中的第一行向量w0复制n份,并沿着y轴的方向对复制的n份向量进行拼接,以得到大小为n·h的向量矩阵w0;
(3-11)将步骤(3-9)得到的向量矩阵w和步骤(3-10)得到向量矩阵w0进行拼接,以获得特征向量矩阵w`,其维度为n·(2*h);
(3-12)将步骤(3-11)得到的特征向量矩阵w`输入全连接网络进行分类,以获得是否为谣言的概率向量p,其中概率向量p的长度为2;
(3-13)对步骤(3-12)得到的概率向量p先进行softmax运算以得到归一化后的概率向量p`,之后对归一化后的概率向量p`进行对数运算,以得到最后的分类标签向量y,其长度为2;
(3-14)根据步骤(3-13)得到的分类标签向量y计算损失函数,并利用该损失函数对谣言检测模型进行迭代训练,直到该谣言检测模型收敛为止,从而得到初步训练好的谣言检测模型。
(3-15)使用步骤(3-1)得到的测试集对步骤(3-14)初步训练好的谣言检测模型进行验证,直到得到的分类精度达到最优为止,从而得到训练好的谣言检测模型。
优选地,步骤(3-3)的计算公式为·:
h=wh×x
其中wh表示第一图注意力网络的初始权值参数矩阵,×表示矩阵乘法;步骤(3-4)的计算公式为:
eij=a([hi||hj]),j∈ai
其中hi表示步骤(3-3)得到的特征矩阵h中的第i行向量,ai为邻接矩阵a中的第i行向量,j∈ai表示为邻接矩阵a中的第i行向量值为1的节点,[hi||hj]表示对hi和hj进行拼接,a(.)表示把拼接后的特征通过前馈神经网络映射到实数,这样就得到任意两个节点之间的注意系数eij,其中如果aij为0,则eij也为0,表示节点i和节点j没有转发、评论或回复关系。
优选地,步骤(3-5)的计算公式为:
其中leakyrelu(x)为激活函数,其中a为固定常数,a∈[0,1],公式表示如下:
exp(x)为指数函数,公式表示如下:
exp(x)=ex
步骤(3-6)具体为:
首先根据以下公式获得节点特征:
h'i=σ(∑j∈aiαijhj)
其中σ(x)为elu激活函数,其公式表示如下:
k为固定常数,k∈[0,1];
然后通过将得到的h'i按行进行拼接,就能得到维度为n·h的特征矩阵。
优选地,步骤(3-13)中的softmax运算的公式为:
对数运算的公式表示如下:
yi=loge(p'i)
步骤(3-14)使用的损失函数loss为:
loss=-(y0+y1)/2
其中y0和y1分别表示分类标签向量y中的第一个和第二个元素。
按照本发明的另一方面,提供了一种基于图注意力网络的社交媒体谣言检测系统,包括:
第一模块,用于获取待检测的谣言事件,对待检测的谣言事件对应的文本进行预处理,以得到预处理后的文本,并使用bert-large-cased预训练词向量模型将预处理后的文本转换成文本向量矩阵。
第二模块,用于根据第一模块得到的待检测的谣言事件对应的用户之间的转发、评论或回复关系构建用户关系结构图表示为g=(v,e),并根据该用户关系结构图构建邻接矩阵,其中v表示节点集合,每个节点表示待检测的谣言事件对应的一个用户,e表示边的集合,每条边表示两个用户之间的转发、评论或回复关系。
第三模块,用于将第一模块得到的文本向量矩阵、以及第二模块得到的邻接矩阵,输入预先训练好的谣言检测模型中,以得到最终的谣言检测结果。
总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
1、由于本发明采用了步骤(3-3)到步骤(3-7),其通过采用第一图注意力网络,动态的给邻接节点赋予相应的权值,能更好的表示每个节点的信息,聚合邻接节点特征,通过采用第二图注意力网络,能更好的提取谣言传播结构高阶特征。因此能够解决现有基于深度学习的谣言检测方法不能高效的提取谣言传播结构特征和聚合邻接节点特征,进而影响谣言检测分类准确度的技术问题;
2、由于本发明采用了步骤(3-10)和步骤(3-11),其通过将原贴子的特征信息聚合到每个节点上,能更好的利用原贴子信息,因此能够解决现有基于深度学习的谣言检测方法由于远离原贴子的节点包含的有利于谣言检测的特征较少,进而影响谣言检测分类准确率的技术问题;
3、由于本发明采用了步骤(3-1),其使用了bert-large-cased预训练词向量模型对谣言文本进行编码,因此能够解决现有基于深度学习的谣言检测方法由于使用传统词向量对文本进行编码不能根据语境动态调整词向量,进而影响谣言检测分类准率的技术问题;
4、本发明的方法具有普适性,能够适用于各种情况下的谣言检测任务。
附图说明
图1是本发明基于图注意力网络的社交媒体谣言检测方法的整体框架示意图;
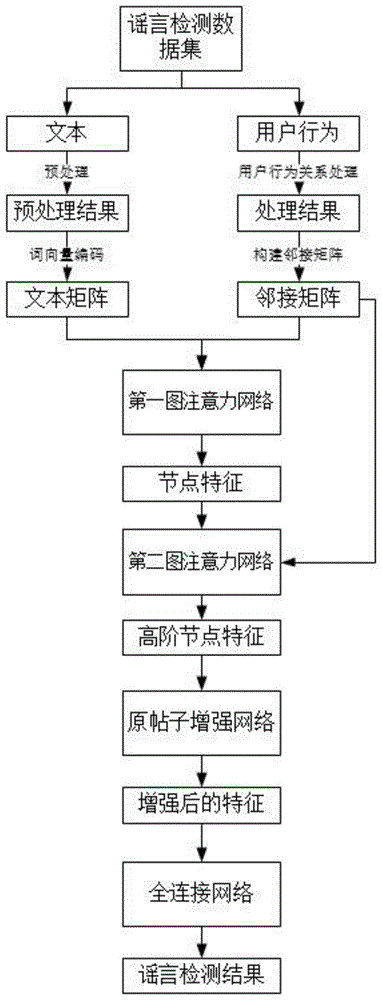
图2是本发明基于图注意力网络的社交媒体谣言检测方法的流程图;
图3是本发明中使用的谣言检测模型的网络结构图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
本发明的基本思路在于,从三个方面提升谣言检测的效果,一方面利用第一图注意力网络动态的给谣言传播节点赋予权值,更好的聚合邻接顶点的信息,同时利用第二图注意力网络能捕获到谣言传播结构的高阶特征;另一方面,利用原帖子增强网络,聚合特征,更好的利用了原帖子的信息。最后,用bert-large-cased预训练词向量模型对谣言事件文本进行编码,解决了一词多义的问题;
在本发明的实验中,通过在谣言检测的数据集上测试,本发明发现在多个数据集上的谣言检测效果均有提升,以数据集pheme2017为例,准确率约提升7%,查全率约提升9%,召回率约提升15.7%,f1值约提升12.6%。其原因在于利用bert-large-cased预训练词向量模型对谣言事件文本进行编码,解决了一词多义的问题。利用第一图注意力网络动态的给邻接节点赋予相应的权值,能更好的表示每个节点的信息,聚合邻接节点特征。第二图注意力网络,能更好的提取谣言传播结构高阶特征。最后,利用原帖子增强网络的方法,聚合特征,更好的利用了原帖子的信息,三个方面提高谣言检测的结果。
如图1和图2所示,本发明提供了一种基于图注意力网络的社交媒体谣言检测方法方法,包括如下步骤:
(1)获取待检测的谣言事件,对待检测的谣言事件对应的文本进行预处理,以得到预处理后的文本,并使用bert-large-cased预训练词向量模型将预处理后的文本转换成文本向量矩阵。
具体而言,本步骤首先是使用正则表达式对待检测的谣言事件对应的文本进行清洗(即删除一些特殊符号(例如#,@等)以及网页链接等),然后使用bert-large-cased预训练词向量模型将清洗后的每条文本转换成1024维向量,所有文本对应的1024维向量构成文本向量矩阵。
(2)根据步骤(1)得到的待检测的谣言事件对应的用户之间的转发、评论或回复关系构建用户关系结构图表示为g=(v,e),并根据该用户关系结构图构建邻接矩阵,其中v表示节点集合,每个节点表示待检测的谣言事件对应的一个用户,e表示边的集合,每条边表示两个用户之间的转发、评论或回复关系。
本步骤中,根据用户关系结构图构建邻接矩阵具体为:对谣言事件对应的节点进行编号(1到n,其中n为谣言事件对应的节点总数,即谣言事件对应的用户总数),然后对于其中任意两个节点i和j而言(其中i和j均∈[1,n]),如果对应的用户之间有转发、评论或回复关系,则邻接矩阵中第i行第j列的元素aij=1,否则为0,这样就可以得到维度为n·n的邻接矩阵a。
(3)将步骤(1)得到的文本向量矩阵、以及步骤(2)得到的邻接矩阵,输入预先训练好的谣言检测模型中,以得到最终的谣言检测结果。
如图3所示,本发明的谣言检测模型包含依次连接的第一图注意力网络、第二图注意力网络、原帖子增强网络,以及全连接网络四个部分。
第一图注意力网络包括n个单头图注意力网络,其中n的取值为大于1的自然数,优选为5;
对于单头图注意力网络而言,其具体结构为:
第一层是特征变换层,输入n·d的文本向量矩阵,利用一个d·h的矩阵,输出一个n·h特征矩阵,其中h为隐含层向量长度(其大小为64),d为编码后的文本向量长度(其等于1024);
本层通过两个矩阵相乘可以提取编码后的文本向量特征,同时降低文本向量长度提高运行速度。
第二层是注意力计算层,其输入为第一层得到的n·h矩阵和n·n用户行为关系的邻接矩阵,输出为n·n的注意力权值矩阵。
第三层是邻接顶点特征聚合层,其将第一层n·h矩阵和第二层得到n·n的注意力权值矩阵进行矩阵乘法,以得到n·h的特征矩阵。
对于第一图注意力网络而言,由于每个单头图注意力网络都会得到1个n·h的特征矩阵,最终通过将n个单头图注意力网络输出的n·h的特征矩阵进行拼接,就能得到一个n·(n*h)的特征矩阵。
第二图注意力网络是一个单头图注意力网络,其输入为第一图注意力网络输出的n·(n*h)的特征矩阵,输出为n·h的特征矩阵。
原帖子增强网络的具体结构为:
第一层是拼接层,其输入为经过第二图注意力网络输出的特征矩阵,该层使用n·h的原帖子特征矩阵进行拼接,输出为经过增强后的特征矩阵,维度为n·2h;
第二层是池化层,其输入为增强后的特征矩阵,输出为经过池化后的特征向量,维度为1·2h。
全连接网络具体结构为:
第一层是特征变换层,其输入为经过原帖子增强网络池化后的特征向量,该层使用2h·h维的权重矩阵,输出维度为h的特征向量。
第二层是特征降维层,其输入为第一层输出的特征向量,该层使用h·h/2维的权重矩阵,输出为降维后的特征向量,维度为h/2。
第三层是谣言检测结果层,其输入为第二层降维后的特征向量,该层使用h/2·2维权重矩阵,输出为谣言检测结果。
具体而言,本发明的谣言检测模型是通过以下步骤训练得到的:
(3-1)获取谣言数据,按照8:2的比例将谣言数据划分为训练集和测试集,对训练集中每个谣言数据对应的文本进行预处理,以得到预处理后的文本,使用bert-large-cased预训练词向量模型将预处理后的文本转换成文本向量矩阵x,根据训练集中每个谣言数据对应的用户之间的转发、评论或回复关系构建用户关系结构图,并根据该用户关系结构图构建邻接矩阵a。
本步骤中对文本进行预处理并生成文本向量矩阵的过程和上述步骤(1)完全相同,构建邻接矩阵的过程和上述步骤(2)完全相同,在此不再赘述;
本步骤数据的划分步骤如下:首先将所有谣言数据随机打乱,之后将所有谣言数据均匀的划分成5份,从5份数据中取任意1份作为测试集,其余4份作为训练集。
本步骤(3-1)的优点在于,使用bert-large-cased预训练词向量模型对谣言事件文本进行编码,解决了一词多义的问题。
(3-2)将步骤(3-1)得到的文本向量矩阵x和邻接矩阵a输入到第一图注意力网络中,以得到n·(n*h)的特征向量矩阵t;
(3-3)将步骤(3-1)得到的文本向量矩阵x和邻接矩阵a输入第一图注意力网络中第一个单头图注意力网络的特征变换层,以得到维度为n·h的特征矩阵h;
具体而言,本步骤的计算公式为·:
h=wh×x
其中wh表示第一图注意力网络的初始权值参数矩阵,×表示矩阵乘法。
(3-4)将步骤(3-3)得到的特征矩阵h输入第一图注意力网络中第一个单头图注意力网络的注意力计算层,以得到每个谣言事件对应的节点之间的注意力系数;
具体而言,本步骤的计算公式为:
eij=a([hi||hj]),j∈ai
其中hi表示步骤(3-3)得到的特征矩阵h中的第i行向量,ai为邻接矩阵a中的第i行向量,j∈ai表示为邻接矩阵a中的第i行向量值为1的节点,[hi||hj]表示对hi和hj进行拼接,a(.)表示把拼接后的特征通过前馈神经网络映射到实数,这样就得到任意两个节点之间的注意系数eij,其中如果aij为0,则eij也为0,表示节点i和节点j没有转发、评论或回复关系。
(3-5)对步骤(3-4)得到的每个谣言事件对应的节点之间的注意力系数eij进行归一化处理,以得到归一化后的注意力系数αij;
具体而言,本步骤的计算公式为:
其中leakyrelu(x)为激活函数,其中a为固定常数,a∈[0,1],公式表示如下:
exp(x)为指数函数,公式表示如下:
exp(x)=ex
通过上述公式就能得到归一化后注意力系数αij。
(3-6)将步骤(3-3)得到的特征矩阵h和步骤(3-5)归一化后的注意力系数αij输入第一图注意力网络中第一个单头图注意力网络的邻接顶点特征聚合层,以得到n·h的特征矩阵;
具体而言,本步骤首先根据以下公式获得节点特征:
h'i=σ(∑j∈aiαijhj)
其中σ(x)为elu激活函数,其公式表示如下:
k为固定常数,k∈[0,1],一般取值为1。
然后通过将得到的h'i按行进行拼接,就能得到维度为n·h的特征矩阵。
(3-7)针对第一图注意力网络中剩余的n-1个单头图注意力网络中的每一个而言,重复上述步骤(3-3)至(3-6),从而得到n-1个维度为n·h的特征矩阵,将这n-1个维度为n·h的特征矩阵与步骤(3-6)得到的特征矩阵进行拼接,从而得到n·(n*h)的特征矩阵;
上述步骤(3-1)到(3-7)的优点在于,利用图注意力网络动态的给邻接节点赋予相应的权值,能更好的表示每个节点的信息,聚合邻接节点特征。
(3-8)对步骤(3-2)得到的特征向量矩阵t进行drop_out处理,以得到n·(n*h)的特征向量矩阵t`,其中随机失活的比例为0.5。
上述步骤(3-8)的有优点在于,能防止模型过拟合,提高模型的泛化能力。
(3-9)将步骤(3-8)得到的特征向量矩阵t`和步骤(3-1)得到的邻接矩阵a输入到第二图注意力网络中,以得到每个谣言数据的高阶表示所对应的向量矩阵w,其维度为n·h。
上述步骤(3-9)的有优点在于,能更好的提取谣言传播结构高阶特征。
(3-10)将步骤(3-9)得到的向量矩阵w中的第一行向量w0复制n份,并沿着y轴的方向对复制的n份向量进行拼接,以得到大小为n·h的向量矩阵w0;
(3-11)将步骤(3-9)得到的向量矩阵w和步骤(3-10)得到向量矩阵w0进行拼接,以获得特征向量矩阵w`,其维度为n·(2*h);
上述步骤(3-10)到(3-11)的优点在于,利用原帖子增强网络的方法,聚合特征,能更好的利用了原帖子的信息。
(3-12)将步骤(3-11)得到的特征向量矩阵w`输入全连接网络进行分类,以获得是否为谣言的概率向量p,其中概率向量p的长度为2;
(3-13)对步骤(3-12)得到的概率向量p先进行softmax运算以得到归一化后的概率向量p`,之后对归一化后的概率向量p`进行对数运算,以得到最后的分类标签向量y,其长度为2;
具体而言,本步骤softmax运算的公式为:
对数运算的公式表示如下:
yi=loge(p'i)
(3-14)根据步骤(3-13)得到的分类标签向量y计算损失函数,并利用该损失函数对谣言检测模型进行迭代训练,直到该谣言检测模型收敛为止,从而得到初步训练好的谣言检测模型。
本步骤使用的损失函数loss为:
loss=-(y0+y1)/2
其中y0和y1分别表示分类标签向量y中的第一个和第二个元素。
(3-15)使用步骤(3-1)得到的测试集对步骤(3-14)初步训练好的谣言检测模型进行验证,直到得到的分类精度达到最优为止,从而得到训练好的谣言检测模型。
实验结果
本发明的实验环境:在ubuntu18.04操作系统下,cpu为intel(r)core(tm)i9-7900x,gpu为2块nvidia1080ti12gb,内存为64gbddr4,采用pytorch编程实现本发明的算法。具体设置如下:batchsize大小为256,初始学习率为1e-3,正则化权重1e-4。
为了说明本发明方法的有效性以及对于分类效果的提升,在多个数据集上进行了测试,以pheme2017数据集为例,该数据集的统计信息如下表1,将本发明得到的测试结果与当前常用的方法进行对比,评估结果如下表2:
表1
表2
根据上表2记载的在pheme2017数据集下的实验结果,可以看到本发明中提出的基于图注意力网络的社交媒体谣言检测方法,在准确率、查准率、召回率、f1值的四个指标上都优于现有的方法。
本发明提出的基于图注意力网络的社交媒体谣言检测方法,一方面利用第一图注意力网络动态的给邻接节点赋予相应的权值,能更好的表示每个节点的信息,聚合邻接节点特征。第二图注意力网络,能更好的提取谣言传播结构高阶特征。另一方面利用原帖子增强网络的方法,聚合特征,更好的利用了原帖子的信息。最后用bert-large-cased预训练词向量模型对谣言事件文本进行编码,解决了一词多义的问题。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!