一种计算机辅助的数据人工标注与自动清洗系统的制作方法
本发明涉及机器学习与人工智能技术领域,具体为一种计算机辅助的数据人工标注与自动清洗系统。
背景技术:
随着大数据时代的到来,机器学习与人工智能被应用于越来越多的领域。在有监督学习中,首先要解决的就是高质量训练数据的获取问题,有了已标注的数据才能进行接下来的模型训练与预测。在某些业务领域,为了获取训练数据,不得不采用人工标注的方法,对训练数据进行打标。
在人工标注数据时,如果标注的数据量很大,标注时需要参考的维度又多的话,由于人的记忆能力有限,且对多维度数据的分析与判别较弱,很可能会对类似的数据,前后标注的结果却大相径庭,产生数据不一致,降低了数据标注的质量,影响后期模型训练的效果。受标注人对业务领域的了解程度、对全局数据分布的把控以及标注时情绪的影响等,人工标注的结果可能会存在一定程度的噪声数据,这些数据不但无益于模型训练与预测精度,甚至可能会导致错误的模型训练结果,因此有必要对其进行清洗。
针对上述机器学习里训练数据标注过程中的问题,目前尚无有效的方法来解决,因此人工标注的数据的准确性难以改善与提升,从而影响了最终训练出的模型的有效性。
技术实现要素:
为了克服现有技术方案的不足,本发明提供一种计算机辅助的数据人工标注与自动清洗系统,能有效的解决背景技术提出的问题。
本发明解决其技术问题所采用的技术方案是:
一种计算机辅助的数据人工标注与自动清洗系统,在人工标注过程中引入计算机来辅助,并在数据清洗时借助计算机和算法进行噪声数据自动发现与清除,包括以下步骤:
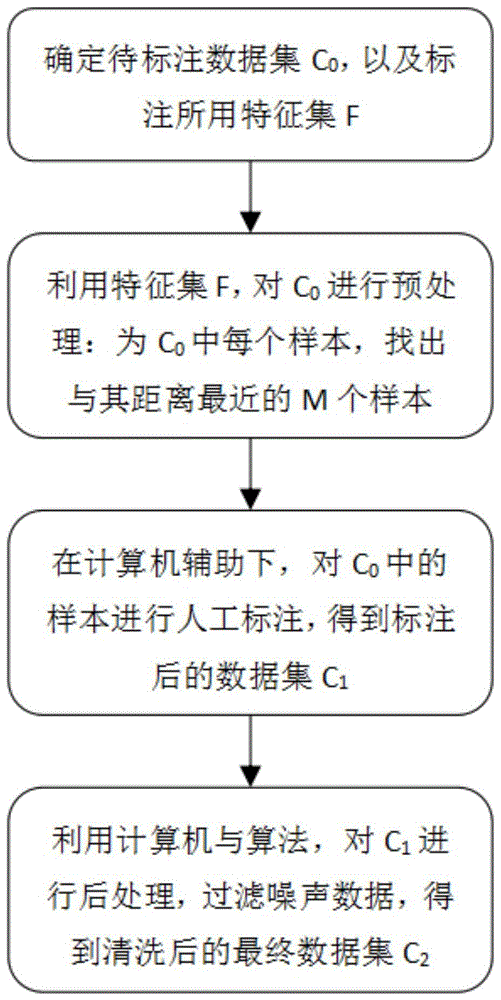
步骤s1:确定待标注数据集合c0,以及标注数据所使用的特征集合f;
步骤s2:利用特征集合f对数据集c0进行预处理,为c0中的每个样本s找出与其距离最近的m个样本;
步骤s3:在计算机的辅助下,对数据集c0中的每个样本进行人工标注,得到标注后的数据集c1;
步骤s4:利用计算机对c1进行处理,过滤噪声数据,得到清洗后的最终数据集c2。
进一步地,在步骤s1中,在确定待标注的数据集c0之后,接着根据业务领域特点,确定人工标注时需要参考的所有特征集合f={f0,f1,f2,…,fn},以及每个样本在各个特征上的取值,这些特征值将作为后续人工标注的依据,用于为每个样本进行准确标注。
进一步地,在步骤s2中,根据业务领域与数据特点,选择一种距离度量算法,为每个样本计算出距其最近的m个样本标记为pre-refs。
进一步地,在步骤s3中,对待标注数据集c0,取出待标注的样本及其特征值向量,结合标结果pre-refs对样本预标注为x,系统将计算与标注结果x最接近的n个已标注的样本,将其作为用户标注的进一步参考,以便用户确定最终标注的结果。
进一步地,在步骤s4中,根据标注任务是打标签还是打分数,并结合业务领域与数据特点,选择一种相应的分类或回归算法用来作为接下来数据清洗之用,将数据集c1平均分成k份,对c1进行k折交叉验证,并根据验证结果,清洗掉其中的噪声数据。
进一步地,距离度量算法包括有欧式距离、余弦距离等。
进一步地,m的取值不小于3。
进一步地,如果待标注数据集c0为空,则执行结束。
进一步地,样本预标注x具体包括有打标签和打分数两种状态。
进一步地,将数据集c1平均分成k份,对c1进行k折交叉验证,依次取出其中一份数据作为测试集,剩余的k-1份作为训练集,用k-1份数据来训练选定的算法,得到训练结果的模型,对剩余的k-1份数据,依次将其作为测试集重复操作。
与现有技术相比,本发明的有益效果是:
本发明在计算机的辅助下,克服了数据量大、标注需参考维度多的缺点,使得前后标注数据一致性;利用计算机辅助标注,能够提高人工标注的效率;对人工标注结果进行自动化的数据清洗,有效去除噪声数据,提升了数据标注的精度,有利于改善和提高数据的准备性。
附图说明
图1是本发明的总体处理流程图;
图2是本发明在计算机辅助下的人工标注数据流程图;
图3是本发明利用计算机与算法自动清洗数据的流程图;
图4是本发明数据清洗过程中用户标注与模型预测结果的差值t的计算示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1-4所示,本发明提供了一种计算机辅助的数据人工标注与自动清洗系统,实际是应用于机器学习中训练数据人工标注的优化系统,本系统主要由两部分组成,分别是计算机辅助下的人工数据标注,以及利用计算机与算法自动清洗标注结果中的噪声数据,通过引入这两个部分,可以增强标注数据之间的一致性,清除人工错误产生的噪声数据,提高标注的准确性,保证数据质量,并且有助于提高标注的效率,包括以下步骤:
步骤s1:确定待标注数据集合c0,以及标注数据所使用的特征集合f;
步骤s2:利用特征集合f对数据集c0进行预处理,为c0中的每个样本s找出与其距离最近的m个样本;
步骤s3:在计算机的辅助下,对数据集c0中的每个样本进行人工标注,得到标注后的数据集c1;
步骤s4:利用计算机对c1进行处理,过滤噪声数据,得到清洗后的最终数据集c2。
其中,在步骤s1中,在确定待标注的数据集c0之后,接着根据业务领域特点,确定人工标注时需要参考的所有特征集合f={f0,f1,f2,…,fn},以及每个样本在各个特征上的取值,这些特征值将作为后续人工标注的依据,用于为每个样本进行准确标注。
在步骤s2中,根据业务领域与数据特点,选择一种距离度量算法,为每个样本计算出距其最近的m个样本标记为pre-refs,其中,距离度量算法包括有欧式距离、余弦距离等。
在步骤s3中,对待标注数据集c0,取出待标注的样本及其特征值向量,结合标结果pre-refs对样本预标注为x,系统将计算与标注结果x最接近的n个已标注的样本,将其作为用户标注的进一步参考,以便用户确定最终标注的结果。
进一步说明的是,对待标注数据集c0,重复执行如下流程:
(1)如果待标注数据集c0为空,则执行结束;否则取出下一个待标注的样本s,及其特征值向量f;
(2)系统从已标注的数据集c1中,找出与s距离最近的m个(如果存在)样本及其标注结果(记为pre-refs),展示给用户,作为用户标注的参考;
(3)用户根据s的特征值向量f,结合参考的已标注样本pre-refs,对样本s预标注为x;
(4)如果标注任务是给s打标签(即x是一个标签),则系统从已标注数据集c1中随机取出n(如n=3)个标注为x的样本及其标签(记为post-refs),作为与s的比较,给用户参考;如果标注任务是给s打分数(即x是一个分数),则系统从已标注数据集c1中取出n个标注分数与x最接近的样本及其分数(记为post-refs),作为与s的比较,给用户参考;
(5)用户综合pre-refs和post-refs的参考,确定样本s最终的标注结果(如果将s的标注由x改为y,则系统重复执行前一步骤,取出新的post-refs用作参考);
(6)将样本s从数据集c0中剔除,并将它与标注结果添加到已标注数据集c1中,跳到(1)。
最终,将得到经过用户标注的数据集c1。
在步骤s4中,根据标注任务是打标签还是打分数,并结合业务领域与数据特点,选择一种相应的分类或回归算法用来作为接下来数据清洗之用,如果是分类算法,需要选择一种可得到用作分类的分值的算法,将数据集c1平均分成k份,对c1进行k折交叉验证,并根据验证结果,清洗掉其中的噪声数据。
进一步说明的是,将数据集c1平均分成k份,对c1进行k折交叉验证,并根据验证结果,清洗掉其中的噪声数据,具体步骤如下:
(1)依次取出其中一份数据作为测试集,剩余的k-1份作为训练集。
(2)用k-1份数据(所用特征仍为f)来训练选定的算法algo,得到训练结果的模型。
(3)利用训练出来的模型,对测试集中的每个样本s进行预测,得到预测结果(包括标签c、分值score、类别分割阈值thr。如果是多分类,分割阈值可能是多个),或回归结果(回归值reg)。
(4)对于分类:找出模型预测结果与人工标注结果不一致的样本,计算其分值score到用户标注的标签c’的边界的最小差值t;对于回归:计算每个样本s的模型预测值reg与用户标注值reg’之差t。
(5)结合具体业务情况设定阈值t,对于t>t的样本,标记为当前轮的噪声数据,这些数据组成当前轮的噪声数据集合。
(6)对剩余的k-1份数据,依次将其作为测试集,重复步骤1~5,得到k份噪声数据集合。将这些集合中的数据从标注结果中剔除,得到最终的数据集c2。
具体实施例:
本发明的计算机辅助的数据人工标注与自动清洗系统总体处理流程如附图1所示,下面结合附图和实施例对本发明做进一步说明:
第一步:确定待标注数据集合c0,以及标注数据所使用的特征集合f。
确定数据集c0之后,根据业务领域特点,确定人工标注时需要参考的所有特征f={f0,f1,f2,…,fn},并计算出样本在各个特征上的取值。这些特征值构成一个向量,将作为后续人工标注、模型训练的输入。
第二步:利用特征集合f,对数据集c0进行预处理:为c0中的每个样本,找出与其距离最近的m个样本。
首先根据业务领域与数据特点,选择一种合适的距离度量算法,不妨选择欧式距离作为度量两个样本之间距离的标准。设两个样本的分别为w=[w0,w1,w2,…,wn]和v=[v0,v1,v2,…,vn](其中w0,w1,w2,…,wn分别是样本w在特征f0,f1,f2,…,fn上的取值。向量v的含义相同),则w和v的欧式距离为
确定距离度量标准后,为每个样本计算出距其最近的m个样本。m取值不用太大,一般几个即可,不妨取m=3。在计算距离最近的m个样本时,可以引入一些剪枝技巧,加快计算速度。比如一旦发现当前两个样本的在某个维度上的差值绝对值大于已找到候选较小距离时,则一定不会是更小的距离,可立即停止当前的计算。
第三步:在计算机的辅助下,对数据集c0中的每个样本进行人工标注,得到标注后的数据集c1。计算机辅助下的人工标注数据流程如附图2所示,对待标注数据集c0,重复执行如下流程:
(1)如果待标注数据集c0为空,则执行结束;否则取出下一个待标注的样本s,及其特征值向量f。
(2)系统从已标注的数据集c1中,找出与s距离最近的m=3个(如果存在)样本及其标注结果(记为pre-refs),展示给用户,作为用户标注的参考。
(3)用户根据s的特征值向量f,结合参考的已标注样本pre-refs,对样本s预标注为x。
(4)如果标注任务是给s打标签(即x是一个标签),则系统从已标注数据集c1中随机取出n个标注为x的样本及其标签(记为post-refs),作为与s的比较,给用户参考;如果标注任务是给s打分数(即x是一个分数),则系统从已标注数据集c1中取出n个标注分数与x最接近的样本及其分数(记为post-refs),作为与s的比较,给用户参考。这里的n也不用太大,一般几个即可,不妨取n=3。
(5)用户综合pre-refs和post-refs的参考,确定样本s最终的标注结果(如果将s的标注由x改为y,则系统重复执行前一步骤,取出新的post-refs用作参考)。
(6)将样本s从数据集c0中剔除,并将它与标注结果添加到已标注数据集c1中。跳到(1)。
经过这些步骤后,我们将得到用户标注的数据集c1。
第四步:利用计算机与算法对c1进行后处理,过滤噪声数据,得到清洗后的最终数据集c2。自动清洗数据的流程如附图3所示。
根据标注任务是打标签还是打分数,并结合业务领域与数据特点,选择一种相应的分类或回归算法(记为algo),用来作为接下来数据清洗之用。注意,如果是分类算法,需要选择一种可得到用作分类的分值的算法。例如,分类算法可以选择随机森林,回归算法可以选择逻辑回归。
根据数据量的大小,将数据集c1平均分成合适的k份,对c1进行k折交叉验证,并根据验证结果,清洗掉其中的噪声数据。具体步骤如下:
(1)依次取出其中一份数据作为测试集,剩余的k-1份作为训练集。
(2)用k-1份数据(所用特征仍为f)来训练选定的算法algo,得到训练结果的模型。
(3)利用训练出来的模型,对测试集中的每个样本s进行预测,得到预测结果(包括标签c、分值score、类别分割阈值thr。注:如果是多分类,分割阈值可能是多个),或回归结果(回归值reg)。
(4)对于分类:找出模型预测结果与人工标注结果不一致的样本,计算预测分值score到用户标注的标签c’的边界的最小差值t;对于回归:计算每个样本s的模型预测值reg与用户标注值reg’之差t。
对于分类问题,在计算预测分值score到用户标注的标签c’的边界的最小差值t时需要注意:如果是多分类,则一个类别最多可能有两个边界,此时t取score到用户标注类别的较近边界的距离。计算示意可参考附图4。
(5)结合具体业务情况设定阈值t,对于t>t的样本,标记为当前轮的噪声数据,这些数据组成当前轮的噪声数据集合。
(6)对剩余的k-1份数据,依次将其作为测试集,重复上述5个步骤,得到k份噪声数据集合。将这些集合中的数据从标注结果中剔除,得到最终的数据集c2。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
- 还没有人留言评论。精彩留言会获得点赞!