一种图形化前端工程化框架构建方法与流程
本发明涉及前端工程化技术领域,具体来说,涉及一种图形化前端工程化框架构建方法。
背景技术:
随着互联网技术的发展,web业务日益复杂化和多元化,前端开发也已经由webpage(网页模式)的模式转变为webapp(客户端)的模式,对于现在的前端日益复杂的工程,如何提高多人协作效率,保证项目的可维护性,提高开发的质量成为了首要的问题。
现有的前端工程化解决方案,是通过webpack(包管理工具),git(代码管理工具),gulp(自动构建工具),jekins(自动打包工具),等各类工具意义实现,这样的实现方式有一下几种缺点,(1)、每次新建一个项目都要重新集成这些软件,后期维护成本高,并且随着时间的推移,不同的开发人员使用的版本不一致也会带来很大的隐患;(2)、不能够灵活开发,开发产品仍然需要依托这些软件实现一整套开发环境,开发场地受限,不能够及时的进行产品迭代;(3)、各个软件的兼容性也是头疼考虑的一部分,解决这些问题会影响到开发的整体效率。
专利号cn104978194b公开了一种网页前端开发方法及装置,该专利包括:建立项目开发目录,对项目开发目录中的静态资源进行实时编译,对编译结果进行优化处理并输出至开发页面,将优化结果上传至测试服务器,将通过测试的优化结果发布至内容分发网络服务器;从而可在本地使用同一个开发工具贯穿完整的web前端开发流程,可用该工具中的命令将每个流程步骤单独处理,且达到了将原本相互分离的各开发过程整合到一起的目的,省去开发过程中在不同工具之间进行切换的繁琐步骤,简单便捷。该专利对开发步骤进行精简优化,提高效率,但仍然无法解决开发场地、软件兼容等相关问题,来帮助开发者选择线上或本地随时进行开发或维护。
针对相关技术中的问题,目前尚未提出有效的解决方案。
技术实现要素:
针对相关技术中的问题,本发明提出一种图形化前端工程化框架构建方法,以克服现有相关技术所存在的上述技术问题。
为此,本发明采用的具体技术方案如下:
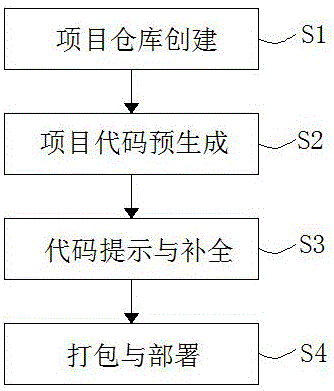
一种图形化前端工程化框架构建方法,该方法包括以下步骤:
s1、项目仓库创建;
s2、项目代码预生成;
s3、代码提示与补全;
s4、打包与部署。
进一步的,所述项目仓库创建包括本地创建与在线创建中的其中一种。
可选的,所述本地创建包括以下步骤:
s11、选择前端框架类型,创建前端脚手架;
s12、在弹出选项框内输入代码设置本地项目配置,并将其存储在默认的代码存储库中;
s13、缓冲区间对代码进行校验,若代码有冲突错误,则返回消息给工作区间,若代码没有冲突错误,则同步本地代码区间内容。
可选的,所述在线创建包括以下步骤:
s11′、选择前端框架类型,创建前端脚手架;
s12′、在弹出选项框内输入代码设置本地项目配置,并将其存储在默认的代码存储库中;
s13′、利用远程缓冲区间拷贝当前远程仓库代码;
s14′、缓冲区间通过对比分析算法对代码进行校验,算法公式如下:
其中,xi代表本地代码仓库序列,yj代表远程代码仓库序列,c[i,j]代表序列xi和yj的最长公共子序列的长度,xi=<x1,x,…,xi>,yj=<y1,y2,…,yj>;
s15′、若计算得到c中有重复内容则判断为冲突项,对冲突进行解决,重复步骤s14′直至c为0时判断验证通过并同步至远程代码仓库。
进一步的,所述代码储存库包括工作区间,缓冲区间及本地代码区间。
进一步的,所述项目代码预生成包括以下步骤:
s21、使用psd文件解析库解析图层信息;
s22、对解析得到的散列函数(hash)内容进行遍历,将整个文档遍历成多叉树,并通过节点实例化对应的对象;
s23、将遍历得到的节点数据转换为一一对应的层叠样式表(css)和超文本标记语言(html),将代码生成项目模块并判断是否使用。
进一步的,所述代码提示与补全包括以下步骤:
s31、对输入内容进行监听获取输入内容;
s32、使用决策树算法对输入内容进行判断匹配,给出对应代码提示;
s33、利用以下公式计算,并按照概率大小依次排列提示和补全的代码;
其中,s是s个数据样本的集合,m表示类标号属性具有的不同值数量,ci=(i=1,m),si是类c中的样本数,i(s1,s2,s3)代表一个给定的样本分类所需的期望信息,pi=si/s是任意样本输入ci的概率。
进一步的,所述决策树的建立包括:
s321、通过训练样本集,建立目标变量关于各输入变量的分类预测模型;
s322、全面实现输入变量和目标变量不同取值下的数据分组;
s323、对新数据对象进行分类和预测。
进一步的,所述打包与部署包括以下步骤:
s41、通过微软脚本环境拉取代码;
s42、将拉好的包通过自定义命令进行打包并上传。
进一步的,所述上传方式包括用户自己部署拉取打包后的部署包与通过微软脚本环境上传替换文件进行部署。
本发明的有益效果为:
1、项目环境无需重复集成,只需要部署一次就可以正常使用,从而减少后期维护成本,大大减少开发的步骤,提高效率。
2、代码开发量减少,提供组件机制,减少代码重复开发,从而降低开发难度,减少开发周期,避免出现代码冗余。
3、可以部署在公网或私网环境下的服务器作为代码开发服务,线上编程随时随地修改代码增加开发效率,从而避免开发场地的限制,同时提高代码更新与维护的效率。
4、统一集成开发工具版本统一,减少不必要的兼容性错误,从而扩展开发环境的适应场景,提高灵活性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是根据本发明实施例的一种图形化前端工程化框架构建方法的主流程图;
图2是根据本发明实施例的一种图形化前端工程化框架构建方法的原理图。
具体实施方式
为进一步说明各实施例,本发明提供有附图,这些附图为本发明揭露内容的一部分,其主要用以说明实施例,并可配合说明书的相关描述来解释实施例的运作原理,配合参考这些内容,本领域普通技术人员应能理解其他可能的实施方式以及本发明的优点,图中的组件并未按比例绘制,而类似的组件符号通常用来表示类似的组件。
根据本发明的实施例,提供了一种图形化前端工程化框架构建方法。
现结合附图和具体实施方式对本发明进一步说明,如图1-2所示,根据本发明实施例的图形化前端工程化框架构建方法,该方法包括以下步骤:
s1、项目仓库创建;
s2、项目代码预生成;
s3、代码提示与补全;
s4、打包与部署。
在一个实施例中,所述项目仓库创建包括本地创建与在线创建中的其中一种。
在一个实施例中,所述本地创建包括以下步骤:
s11、选择前端框架类型,创建前端脚手架;
s12、在弹出选项框内输入代码设置本地项目配置,并将其存储在默认的代码存储库中;
s13、缓冲区间对代码进行校验,若代码有冲突错误,则返回消息给工作区间,若代码没有冲突错误,则同步本地代码区间内容。
在一个实施例中,所述在线创建包括以下步骤:
s11′、选择前端框架类型,创建前端脚手架;
s12′、在弹出选项框内输入代码设置本地项目配置,并将其存储在默认的代码存储库中;
s13′、利用远程缓冲区间拷贝当前远程仓库代码;
s14′、缓冲区间通过对比分析算法对代码进行校验,算法公式如下:
其中,xi代表本地代码仓库序列,yj代表远程代码仓库序列,c[i,j]代表序列xi和yj的最长公共子序列的长度,xi=<x1,x,…,xi>,yj=<y1,y2,…,yj>;
s15′、若计算得到c中有重复内容则判断为冲突项,对冲突进行解决,重复步骤s14′直至c为0时判断验证通过并同步至远程代码仓库。
其中,线上创建方式即在本地创建的基础上增加远程代码仓库,和远程缓冲区间,线上创建一般涉及到多人协调问题。假设本地代码仓库和远程代码仓库的分别对应x和y,设序列x=<x1,x2,…,xm>和y=<y1,y2,…,yn>的一个最长公共子序列z=<z1,z2,…,zk>,则:
1.若xm=yn,则zk=xm=yn且zk-1是xm-1和yn-1的最长公共子序列;
2.若xm≠yn且zk≠xm,则z是xm-1和y的最长公共子序列;
3.若xm≠yn且zk≠yn,则z是x和yn-1的最长公共子序列。
其中xm-1=<x1,x2,…,xm-1>,yn-1=<y1,y2,…,yn-1>,zk-1=<z1,z2,…,zk-1>。
由最长公共子序列问题的最优子结构性质可知,要找出x=<x1,x2,…,xm>和y=<y1,y2,…,yn>的最长公共子序列,可按以下方式递归地进行:当xm=yn时,找出xm-1和yn-1的最长公共子序列,然后在其尾部加上xm(=yn)即可得x和y的一个最长公共子序列。当xm≠yn时,必须解两个子问题,即找出xm-1和y的一个最长公共子序列及x和yn-1的一个最长公共子序列。这两个公共子序列中较长者即为x和y的一个最长公共子序列。
由此递归结构容易看到最长公共子序列问题具有子问题重叠性质。例如,在计算x和y的最长公共子序列时,可能要计算出x和yn-1及xm-1和y的最长公共子序列。而这两个子问题都包含一个公共子问题,即计算xm-1和yn-1的最长公共子序列。
与矩阵连乘积最优计算次序问题类似,来建立子问题的最优值的递归关系。用c[i,j]记录序列xi和yj的最长公共子序列的长度。其中xi=<x1,x2,…,xi>,yj=<y1,y2,…,yj>。当i=0或j=0时,空序列是xi和yj的最长公共子序列,故c[i,j]=0,即可得出步骤s14′中的公式。
在一个实施例中,所述代码储存库包括工作区间,缓冲区间及本地代码区间,其中,工作区间及本地创建的项目区间该区间用在开发,缓冲区间用于代码更改完毕后进行代码校验的区间。
在一个实施例中,所述项目代码预生成包括以下步骤:
s21、使用psd文件解析库解析图层信息;
其中,解析完成得到散列函数如下:
{:children=>[{:type=>:group,
:visible=>true,
:opacity=>1.0,
...
}]
:document=>{:width=>300,
:height=>600
...
}
s22、对解析得到的散列函数(hash)内容进行遍历,将整个文档遍历成多叉树,并通过节点实例化对应的对象;
其中,通过深度优先方式遍历该模板的如下:
publicstaticvoiddepthfirst(treenoderoot){
deque<treenode>nodedeque=newlinkedlist<>();
treenodenode=root;
nodedeque.push(node);
while(!nodedeque.isempty()){
node=nodedeque.pop();
system.out.print(node.getname());
for(treenodetreenode:node.getchildren()){
nodedeque.push(treenode);
}
}
}
s23、将遍历得到的节点数据转换为一一对应的层叠样式表(css)和超文本标记语言(html),将代码生成项目模块并判断是否使用。
在一个实施例中,所述代码提示与补全包括以下步骤:
s31、对输入内容进行监听获取输入内容;
s32、使用决策树算法对输入内容进行判断匹配,给出对应代码提示;
s33、利用以下公式计算,并按照概率大小依次排列提示和补全的代码;
其中,s是s个数据样本的集合,m表示类标号属性具有的不同值数量,ci=(i=1,m),si是类c中的样本数,i(s1,s2,s3)代表一个给定的样本分类所需的期望信息,pi=si/s是任意样本输入ci的概率。
在一个实施例中,所述决策树的建立包括:
s321、通过训练样本集,建立目标变量关于各输入变量的分类预测模型;
s322、全面实现输入变量和目标变量不同取值下的数据分组;
s323、对新数据对象进行分类和预测。
其中,当利用所建决策树对一个新数据对象进行分析时,决策树能够依据该数据输入变量的取值,推断出相应目标变量的分类或取值。决策树技术中有各种各样的算法,这些算法都存在各自的优势和不足。目前,从事机器学习的专家学者们仍在潜心对现有算法的改进,或研究更有效的新算法。总结起来,决策树算法主要围绕两大核心问题展开:第一,决策树的生长问题,即利用训练样本集,完成决策树的建立过程。第二,决策树的剪枝问题,即利用检验样本集,对形成的决策树进行优化处理。
在一个实施例中,所述打包与部署包括以下步骤:
s41、通过微软脚本环境拉取代码;
其中,拉取代码如下:
#!/bin/bash
ftp-n<<!
openxxx,xxx,xxx,xxx打开地址可以是线上服务地址也可以是本地服务地址
user账号密码
binary
cd/home/data
lcd/home/databackup
prompt
mget*
close
bye
!
s42、将拉好的包通过自定义命令进行打包并上传。
在一个实施例中,所述上传方式包括用户自己部署拉取打包后的部署包与通过微软脚本环境上传替换文件进行部署。
综上所述,借助于本发明的上述技术方案,项目环境无需重复集成,只需要部署一次就可以正常使用,从而减少后期维护成本,大大减少开发的步骤,提高效率。代码开发量减少,提供组件机制,减少代码重复开发,从而降低开发难度,减少开发周期,避免出现代码冗余。可以部署在公网或私网环境下的服务器作为代码开发服务,线上编程随时随地修改代码增加开发效率,从而避免开发场地的限制,同时提高代码更新与维护的效率。统一集成开发工具版本统一,减少不必要的兼容性错误,从而扩展开发环境的适应场景,提高灵活性。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!