一种快速支持AB分流的系统接入方法与流程
一种快速支持ab分流的系统接入方法
技术领域
1.本发明属于计算机应用技术领域,具体涉及一种快速支持ab分流的系统接入方法。
背景技术:
2.ab分流实验是为app界面或流程制作两个或多个版本,在同一时间维度,分别让组成成分相似的访客群组随机的访问这些版本,收集各群组的用户体验数据和业务数据,最后分析、评估出最好版本,正式采用,ab分流实验沿用至今,在企业的业务发展上发挥着重要的作用。
3.现在企业的每个业务系统上都开发有一套独有的ab分流实验平台,不同的业务系统之间不可复用,因此需要重复开发,开发成本高,而且ab分流实验平台的配置信息读写耦合,无谓的增加服务器的压力。
技术实现要素:
4.为解决上述背景技术中提出的问题。本发明提供了一种快速支持ab分流的系统接入方法,具有一次开发,多端适配,实验数据自动采集,配置信息读写分离,减少服务器压力的特点。
5.为实现上述目的,本发明提供如下技术方案:一种快速支持ab分流的系统接入方法,包括以下步骤:
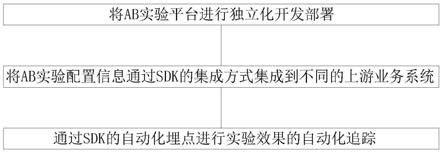
6.s1:将ab实验平台进行独立化开发部署;
7.s2:将ab实验配置信息通过sdk的集成方式集成到不同的上游业务系统;
8.s3:通过sdk的自动化埋点进行实验效果的自动化追踪。
9.本发明中进一步的,所述步骤s2中,ab实验配置信息包括流量入口、ab实验版本信息和实验分流信息。
10.本发明中进一步的,所述步骤s2中,通过sdk的集成方式将ab实验配置信息集成到不同上游业务系统的具体步骤为:
11.s21:向初始化后的sdk引入中jar包;
12.s22:将sdk的jar包引入不同的上层java业务系统;
13.s23:引入的jar包里有打印日志的功能,当有流量进入的时候,该日志模块打印日志到业务系统服务器中。
14.本发明中进一步的,所述步骤s21中,初始化后的sdk在应用启动时就一个new abclient,new abclient的使用方式和应用中容器的bean的生命周期保持一致,在需要的地方进行注入即可。
15.本发明中进一步的,所述步骤s23中,日志打印的存储路径为日志目录下的/ab/ab
‑
track.log中,且日志打印的存储格式为yyyy
‑
mm
‑
dd hh:mm:ss#appld@应用id#entranceld场景id#expversionld@实验版本id#traceld@traceld#divisionld@分流id(手
机号/uid)。
16.本发明中进一步的,所述步骤s3中,实验效果的具体自动化追踪步骤为:
17.s31:业务系统服务器中的flume日志采集系统自动采集打印的日志,并上报至业务系统服务器中的kafka日志收集系统;
18.s32:业务系统服务器中的kafka日志收集系统对采集的打印日志进行收集,并上报至业务系统服务器中的hadoop/spark数据处理系统;
19.s33:业务系统服务器中的hadoop/spark数据处理系统对收集的打印日志进行实时/离线数据处理,并上报至业务系统服务器中的clickhouse/hbase数据存储系统;
20.s34:业务系统服务器中的clickhouse/hbase数据存储系统对数据处理后的打印日志进行存储;
21.s35:工作人员通过监控平台的indicator数据指标系统查看clickhouse/hbase数据存储系统内存储的实验效果数据,实现实验效果的自动化追踪。
22.与现有技术相比,本发明的有益效果是:
23.1、本发明将ab实验平台进行独立化开发部署,并通过sdk的集成方式将ab实验配置信息集成到不同的上游业务系统,一次开发,多端适配,解决现有不同业务系统需要重复开发ab实验平台的问题,开发成本低。
24.2、本发明通过sdk的集成方式将ab实验配置信息集成到不同的上游业务系统,sdk的集成方式是通过jar包的引入方式实现的,引入的jar包里有打印日志的功能,当有流量进入的时候,该日志模块就会打印日志到业务系统的服务器中,而业务系统的服务器中有flume的日志采集工具,这样整个日志埋点信息就能够进行自动采集上报,实现实验效果的自动化追踪,配置信息读写分离,能够减少服务器的压力。
附图说明
25.图1为本发明快速支持ab分流的系统接入方法的流程图;
26.图2为本发明读写分离的整体流程图;
27.图3为本发明上游业务系统接入的流程图。
具体实施方式
28.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
29.请参阅图1
‑
3,本发明提供以下技术方案:一种快速支持ab分流的系统接入方法,包括以下步骤:
30.s1:将ab实验平台进行独立化开发部署;
31.s2:将ab实验配置信息通过sdk的集成方式集成到不同的上游业务系统;
32.s3:通过sdk的自动化埋点进行实验效果的自动化追踪。
33.具体的,步骤s2中,ab实验配置信息包括流量入口、ab实验版本信息和实验分流信息。
34.具体的,步骤s2中,通过sdk的集成方式将ab实验配置信息集成到不同上游业务系统的具体步骤为:
35.s21:向初始化后的sdk引入中jar包;
36.s22:将sdk的jar包引入不同的上层java业务系统;
37.s23:引入的jar包里有打印日志的功能,当有流量进入的时候,该日志模块打印日志到业务系统服务器中。
38.具体的,步骤s21中,初始化后的sdk在应用启动时就一个new abclient,new abclient的使用方式和应用中容器的bean的生命周期保持一致,在需要的地方进行注入即可。
39.具体的,步骤s23中,日志打印的存储路径为日志目录下的/ab/ab
‑
track.log中,且日志打印的存储格式为yyyy
‑
mm
‑
dd hh:mm:ss#appld@应用id#entranceld场景id#expversionld@实验版本id#traceld@traceld#divisionld@分流id(手机号/uid)。
40.具体的,步骤s3中,实验效果的具体自动化追踪步骤为:
41.s31:业务系统服务器中的flume日志采集系统自动采集打印的日志,并上报至业务系统服务器中的kafka日志收集系统;
42.s32:业务系统服务器中的kafka日志收集系统对采集的打印日志进行收集,并上报至业务系统服务器中的hadoop/spark数据处理系统;
43.s33:业务系统服务器中的hadoop/spark数据处理系统对收集的打印日志进行实时/离线数据处理,并上报至业务系统服务器中的clickhouse/hbase数据存储系统;
44.s34:业务系统服务器中的clickhouse/hbase数据存储系统对数据处理后的打印日志进行存储;
45.s35:工作人员通过监控平台的indicator数据指标系统查看clickhouse/hbase数据存储系统内存储的实验效果数据,实现实验效果的自动化追踪。
46.尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1