基于特征空间多分类对抗机制的红外可见光图像融合方法
1.本发明涉及图像增强技术领域,具体地说,本发明涉及一种基于特征空间多 分类对抗机制的红外可见光图像融合方法的技术方案。
背景技术:
2.近几十年,基于深度学习的融合方法凭借神经网络强大的特征提取和图像重 建能力,获得了远超传统方法的性能。现存的基于深度学习的图像融合方法可以 分为端到端融合方法以及非端到端融合方法。
3.端到端融合方法通常直接使用一个整体网络将输入的红外和可见光图像进 行融合。换句话说,融合的各个阶段如特征提取、特征融合以及图像重建都是隐 式的。端到端融合方法可根据所采取的架构分为基于卷积神经网络的融合方法和 基于生成式对抗网络的融合方法。这些方法的共性在于依赖融合图像与源图像绝 对分布之间的距离损失。例如,pmgi在融合图像和两个源图像间建立强度和梯 度距离损失,并通过调节损失项的权重系数来调整信息融合过程中的保留比例, 从而控制融合绝对结果分布的倾向性。u2fusion则在融合图像和两个源图像间 建立强度和结构相似度损失,并通过度量特征图的信息质量来自适应地调整损失 项系数,从而引导融合图像保留有效信息。不幸的是,这种融合图像与两个源图 像绝对分布之间的距离损失会建立一个博弈,导致最终融合图像是两个源图像原 始属性(如像素强度、梯度等)的折中,不可避免地造成有益信息被削弱。除此 以外,fusiongan网络的优化不仅依赖图像绝对分布之间的距离损失还依赖模 态概率分布之间的对抗损失。随后,它们引入双鉴别器来平衡红外与可见光信息 以进一步提升融合性能,但是网络优化仍离不开图像绝对分布之间的内容损失, 这意味有益信息的丢失问题仍然存在。
4.非端到端融合方法主要是基于自编码架构,其特征提取、特征融合以及图像 重建三个阶段都是非常明确的,由不同的网络或模块来实现。现存非端到端图像 融合方法的融合质量一直受融合策略的性能制约。具体来说,现存的基于自编码 结构的融合方法采用的融合规则都是手工制作的,且不可学习。例如,densefuse 采用addition策略和l1‑
norm策略;sedrfuse采用最大值策略。这些策略不能 根据输入图像自适应地调整,可能会造成亮度中和或过饱和、信息丢失等问题, 因此研究可学习的融合规则非常有意义。
技术实现要素:
5.针对现有的技术缺陷,本发明提出了一种基于特征空间多分类对抗机制的红 外可见光图像融合网络的技术方案。经本发明增强得到的红外图像,可以避免有 效信息被削弱和中和,能自适应地保留显著热目标和丰富纹理结构。。
6.本发明的技术方案包括以下步骤:
7.步骤1,设计一种新的自编码器网络来实现融合过程中的特征提取和图像重 建,来实现特征提取和图像重建,所述的自编码器网络包括编码器和译码器,其 中编码器将图
像映射到高维特征空间,再利用译码器将高维特征重新映射为图 像,设计损失函数对编码器和译码器进行训练;
8.步骤2,建立生成式对抗网络并对其进行训练,所述的生成式对抗网络包括 特征融合网络和和多分类鉴别器,使用训练好的编码器从红外和可见光图像中提 取特征,然后通过生成式对抗网络来融合这些特征;
9.步骤3,在整个训练结束后,将编码器、生成式对抗网络以及译码器级联组 成完整的图像融合网络,使用训练好的编码器从红外和可见光图像中提取特征, 将生成式对抗网络生成的融合特征经训练好的译码器译码得到高质量的融合图 像。
10.进一步的,步骤1中编码器的网络结构如下;
11.建立编码器e,所述的编码器e使用跳跃连接和残差连接通过9个卷积层对 原始的红外图像和可见光图像对中提取特征,所述的卷积层的卷积核尺寸均为3
×
3,激活函数均为leaky relu,分别采用空间注意力模块对第4层和第8层卷 积层加权;采用残差连接将第1层与第一个空间注意力模块进行残差连接,残差 连接的结果通过激活函数leaky relu后与第二个空间注意力模块进行残差连 接;采用跳跃连接将第2层、第3层、第6层与第7层进行跳跃连接,最终得到 红外特征fea
ir
和可见光特征fea
vis
。
12.进一步的,步骤1中译码器的网络结构如下;
13.建立译码器d,所述的译码器d使用两个结合通道注意力模块的多尺度卷 积层顺序连接,来处理编码器提取的编码特征,所述的多尺度卷积层由三个具 有不同尺寸卷积核的卷积层组成,卷积核尺寸分别为7
×
7、5
×
5和3
×
3,激活函数 均为leaky relu;在每个多尺度卷积层后连接一个通道注意力模块,在此之后, 使用三个卷积核尺寸为3
×
3的卷积层来重建红外图像和可见光图像,前两个卷积 层使用leaky relu作为激活函数,第三个卷积层使用tanh作为激活函数。
14.进一步的,建立编码器和译码器的损失函数其为在强度域和梯度域构 建重建图像与输入图像的一致性损失,其计算公式如下:
[0015][0016]
其中,是强度损失,是梯度损失,β是平衡强度损失项和梯度损失 项的参数;
[0017]
强度损失的计算公式如下:
[0018][0019]
梯度损失的计算公式如下:
[0020][0021]
其中,|
·
|是l1范数,是sobel梯度算子,其从水平和竖直两个方向来计算 图像的梯度;i
ir
和i
vis
是输入的源红外和可见光图像,和是自编码网络重建 的红外和可见光图像,其可以表示为:
[0022]
训练自编码器网络,采用adam优化器来更新参数,自编码器网络训练好后, 冻结
其参数。
[0023]
进一步的,步骤2的具体实现方式如下;
[0024]
步骤2.1,建立特征融合网络f,将训练好的编码器e提取的红外特征fea
ir
和可见光特征fea
vis
进行融合,生成融合特征fea
fused
;
[0025]
所述的特征融合网络f采用3个卷积核尺寸为3
×
3、激活函数为leaky relu 的卷积层来处理编码器e提取的红外特征fea
ir
与可见光特征fea
vis
;在此之后级 联三个并列的两层卷积层分支,分别是2个融合权重预测分支和一个偏差预测分 支,预测融合权重ω
ir
、ω
vis
以及偏差项ε;所述的融合权重预测分支包含两个卷 积层,其卷积尺寸均为3
×
3,两个卷积层分别使用leaky relu和sigmoid作为激 活函数;在偏差预测分支,也包含两个卷积层,其卷积尺寸均为3
×
3,两个卷积 层的激活函数均为leaky relu。融合特征可以被表示为:
[0026]
fea
fused
=f(fea
ir
,fea
vis
)=ω
ir
·
fea
ir
+ω
vis
·
fea
vis
+ε
[0027]
步骤2.2,建立多分类鉴别器md区分红外特征fea
ir
、可见光特征fea
vis
以及 特征融合网络f合成的融合特征fea
fused
;所述的多分类鉴别器md中,使用4个卷 积层来处理编码器提取的红外特征fea
ir
与可见光特征fea
vis
,卷积核尺寸均为 3
×
3,激活函数均为leaky relu;然后,处理后的特征被重塑为一个一维向量, 并使用一个线性层来输出一个1
×
2的预测向量,分别表示输入特征为红外特征的 概率p
ir
,以及输入特征为可见光特征的概率p
vis
;
[0028]
步骤2.3,建立特征融合网络f的损失函数和多分类鉴别器md的损失函 数特征融合网络f和多分类鉴别器md在对抗学习中迭代优化;
[0029]
步骤2.4,特征融合网络f和多分类鉴别器md连续地对抗学习,采用adam 优化器来更新参数,在训练好的编码器提取的特征空间中训练生成式对抗网络。
[0030]
进一步的,对于特征融合网络f,其目的是产生可以骗过多分类鉴别器md 的融合特征fea
fused
,即让多分类鉴别器md认为融合特征fea
fused
既是红外特征 fea
ir
又是可见光特征fea
vis
,因此,特征融合网络f的损失函数的计算公式如 下:
[0031][0032]
其中,md(
·
)表示多分类鉴别器md的函数,其输出是一个1
×
2的概率向 量.md(fea
fused
)[1]指的是该向量的第一项,表示鉴别器判定输入特征是红外特 征的概率p
ir
;md(fea
fused
)[2]指的是该向量的第二项,表示鉴别器判定输入特征 是可见光特征的概率p
vis
,a是概率标签。
[0033]
进一步的,多分类鉴别器md,希望能准确判断输入特征是红外特征、可见 光特征还是由特征融合网络f产生的融合特征,鉴别器损失函数包括三部 分,分别是判定红外特征的损失判定可见光特征的损失以及判定融 合特征的损失鉴别器损失函数的计算公式如下:
[0034]
[0035]
其中α1,α2和α3是平衡这些损失项的参数;
[0036]
当输入特征为红外特征fea
ir
,鉴别器判定的p
ir
应趋于1,p
vis
应趋于0,对应 的损失函数的计算公式如下:
[0037][0038]
其中,b1和b2是红外特征对应的概率标签;
[0039]
类似的,当输入特征为可见光特征fea
vis
,对应的损失函数的计算公式 如下:
[0040][0041]
其中,c1和c2是可见光特征对应的概率标签;
[0042]
当输入特征为融合特征fea
fused
,鉴别器输出的p
ir
和p
vis
都应趋于0,对应的 损失函数的计算公式如下:
[0043][0044]
其中,d1和d2是融合特征对应的概率标签。
[0045]
进一步的,步骤3中将编码器、生成式对抗网络以及译码器级联组成完整的 图像融合网络表示如下;
[0046]
通过训练好的编码器e提取红外图像i
ir
的红外特征fea
ir
和可见光图像i
vis
的 可见光特征fea
vis
,将红外特征fea
ir
和可见光特征fea
vis
输入训练好的特征融合 网络f,特征融合网络f生成的融合特征fea
fused
经训练好的译码器d译码生成 高质量的融合图像i
fused
,整个融合过程可以被形式化为:
[0047]
i
fused
=d(f(e(i
ir
),e(i
vis
)))
[0048]
其中,i
ir
和i
vis
分别表示红外图像和可见光图像;e(
·
)表示编码器函数,f(
·
) 表示特征融合网络函数,d(
·
)表示译码器函数。
[0049]
本发明与现有技术相比具有以下优点和有益效果:
[0050]
(1)本发明提出了一个新的红外与可见光图像融合网络,其利用多分类对 抗机制将传统融合策略扩展为可学习,具有更好的融合性能;
[0051]
(2)本发明提出的方法将现存方法中融合图像与源图像绝对分布之间的距 离损失扩展为模态概率分布之间的对抗损失,有效避免了现存融合方法中有益信 息被削弱的问题;
[0052]
(3)本发明提出的方法具有良好的泛化性,可以推广到任意红外与可见光 图像融合数据集。
附图说明
[0053]
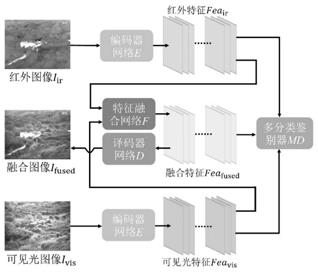
图1为本发明的整体框架;
[0054]
图2为本发明的自编码器网络结构图;
[0055]
图3为本发明的生成式对抗网络结构图;
[0056]
图4为本发明的对比实验的定性结果。
具体实施方式
[0057]
下面结合附图和实施例对本发明技术方案进一步详细说明。
[0058]
本发明所述方法选用tno数据集作为对比实验的数据,选用roadscene数 据集作为泛化性实验的数据,这两个数据集中的图像对都已被严格配准。在对比 试验和泛化性实验中,用于测试的图像对数量均为20。为了获取更多的训练数 据,将tno数据集中剩下图像进行有重叠地裁剪,共获得45910对尺寸为80
×ꢀ
80的图像块用于自编码器和生成式对抗网络的训练。
[0059]
步骤1:设计一种新的自编码器网络来实现融合过程中的特征提取和图像重 建,本发明方法的总框架如图1所示。所述的自编码器网络包括编码器和译码器。 建立编码器、译码器的损失函数,所述的编码器将图像映射到高维特征空间,再 利用译码器将高维特征重新映射为图像,其结构如图2所示;
[0060]
步骤2:建立生成式对抗网络并训练,所述的生成式对抗网络包括生成器(特 征融合网络)、和鉴别器。使用训练好的编码器从红外和可见光图像中提取特征, 通过生成式对抗网络来融合这些特征。生成式对抗网络的结构如图3所示;
[0061]
步骤3:在整个训练结束后,将编码器、生成式对抗网络以及译码器级联组 成完整的图像融合网络。使用训练好的编码器从红外和可见光图像中提取特征, 将生成式对抗网络生成的融合特征经训练好的译码器译码得到高质量的融合图 像。
[0062]
进一步的,步骤1包括如下步骤:
[0063]
步骤1.1:建立编码器e,所述的编码器e使用9个卷积层从源图像中提取 特征,其中卷积核尺寸均为3
×
3,激活函数均为leaky relu。在分别采用空间注 意力模块对第4层和第8层卷积层加权;采用残差连接将第1层与第一个空间注 意力模块进行残差连接,残差连接的结果通过激活函数leaky relu后与第二个 空间注意力模块进行残差连接;采用跳跃连接将第2层、第3层、第6层与第7 层进行跳跃连接,最终得到红外特征fea
ir
和可见光特征fea
vis
。空间注意力模块 的网络结构如图2右下角所示,为现有技术,同时编码器将密集连接和残差连接 相结合,把浅层特征不断跳跃连接到深层网络;
[0064]
步骤1.2:建立译码器模型d,所述的译码器d使用两个结合通道注意力模 块的多尺度卷积层来处理编码器e提取的中间特征。在每个多尺度卷积层,三 个具有不同尺寸卷积核的卷积层并行处理输入特征,其卷积核尺寸分别为7
×
7、 5
×
5和3
×
3,激活函数均为leaky relu。在此之后,使用三个卷积核尺寸为3
×
3的 卷积层来重建源图像,前两个卷积层使用leaky relu作为激活函数,第三个卷 积层使用tanh作为激活函数。通道注意力模块的网络结构如图2左下角所示, 为现有技术,其在通道维度上生成权重向量,以选择性增强那些对重建更有利的 特征通道;
[0065]
步骤1.3:所述的自编码器网络中的编码器和译码器需要损失函数对其进行 约束,建立损失函数其为在强度域和梯度域构建重建图像与输入图像的一 致性损失,其计算公式如下:
[0066][0067]
其中,是强度损失,是梯度损失,β是平衡强度损失项和梯度损失 项的参数,参数β被设定为10。
[0068]
强度损失的计算公式如下:
[0069][0070]
梯度损失的计算公式如下:
[0071][0072]
其中,|
·
|是l1范数,是sobel梯度算子,其从水平和竖直两个方向来计算 图像的梯度。i
ir
和i
vis
是输入的源红外和可见光图像,和是自编码网络重建 的红外和可见光图像,其可以表示为:
[0073]
步骤1.4:训练编码器和译码器,采用adam优化器来更新参数,训练好后, 冻结其参数。
[0074]
在训练过程中,批大小被设置为s1,训练一期需要m1步,一共训练m1期.在 实验中,s1被设置为48,m1被设置为100,m1是训练图像块总数量和批大小s1的比率。
[0075]
进一步的,步骤2包括如下步骤:
[0076]
步骤2.1,建立特征融合网络f,将训练好的编码器e提取的红外特征fea
ir
和可见光特征fea
vis
进行融合,生成融合特征fea
fused
;
[0077]
所述的特征融合网络f使用3个卷积核尺寸为3
×
3、激活函数为leaky relu 的卷积层来处理输入的红外特征fea
ir
与可见光特征fea
vis
;在此之后级联三个并 列的两层卷积层分支,分别是2个融合权重预测分支和一个偏差预测分支,预测 融合权重ω
ir
、ω
vis
以及偏差项ε。所述的融合权重预测分支包含两个卷积层,其 卷积尺寸均为3
×
3,两个卷积层分别使用leaky relu和sigmoid作为激活函数; 在偏差预测分支,所述的融合权重预测分支两个卷积层的激活函数均为leaky relu。融合特征可以被表示为:
[0078]
fea
fused
=f(fea
ir
,fea
vis
)=ω
ir
·
fea
ir
+ω
vis
·
fea
vis
+ε
[0079]
步骤2.2:使用一个多分类器md作为鉴别器来区分红外特征fea
ir
、可见光特 征fea
vis
以及生成器合成的融合特征fea
fused
。在鉴别器md中,先使用4个卷积层 来处理输入特征,卷积核尺寸均为3
×
3,激活函数均为leaky relu。然后,处理 后的特征被重塑为一个一维向量,并使用一个线性层来输出一个1
×
2的预测向量, 分别表示输入特征为红外特征的概率p
ir
,以及输入特征为可见光特征的概率p
vis
;
[0080]
步骤2.3:生成器f和多分类鉴别器md在对抗学习中迭代优化,需要建立 生成器f的损失函数为和鉴别器md的损失函数
[0081]
进一步的,步骤2.3包括如下步骤:
[0082]
步骤2.3.1:对于生成器f,其目的是产生可以骗过鉴别器的融合特征fea
fused
, 即让鉴别器认为融合特征fea
fused
既是红外特征fea
ir
又是可见光特征fea
vis
.因 此,生成器的损失函数的计算公式如下:
[0083][0084]
其中,md(
·
)表示多分类鉴别器的函数,其输出是一个1
×
2的概率向 量.md
(fea
fused
)[1]指的是该向量的第一项,表示鉴别器判定输入特征是红外特 征的概率p
ir
;md(fea
fused
)[2]指的是该向量的第二项,表示鉴别器判定输入特征 是可见光特征的概率p
vis
。a是概率标签,a被设定为0.5。
[0085]
步骤2.3.2:多分类鉴别器md(
·
)希望能准确判断输入特征是红外特征、可见 光特征还是由生成器f产生的融合特征。鉴别器损失函数包括三部分,分别 是判定红外特征的损失判定可见光特征的损失以及判定融合特征的 损失鉴别器损失函数的计算公式如下:
[0086][0087]
其中α1,α2和α3是平衡这些损失项的参数,参数α1,α2和α3分别被设定为0.25, 0.25和0.5。
[0088]
(1)当输入特征为红外特征fea
ir
,鉴别器判定的p
ir
应趋于1,p
vis
应趋于0。 对应的损失函数的计算公式如下:
[0089][0090]
其中,b1和b2是红外特征对应的概率标签,b1被设定为1,b2被设定为0。
[0091]
(2)类似的,当输入特征为可见光特征fea
vis
,对应的损失函数的计 算公式如下:
[0092][0093]
其中,c1和c2是可见光特征对应的概率标签,c1被设定为0,c2被设定为1。
[0094]
(3)当输入特征为融合特征fea
fused
,鉴别器输出的p
ir
和p
vis
都应趋于0。对 应的损失函数的计算公式如下:
[0095][0096]
其中,d1和d2是融合特征对应的概率标签,d1和d2都被设为0。
[0097]
步骤2.4:生成器和鉴别器连续地对抗学习,采用adam优化器来更新参数, 在训练好的编码器提取的特征空间中训练生成式对抗网络。
[0098]
在生成式对抗网络的训练过程中,批大小被设置为s2,训练一期需要m2步, 一共训练m2期.在实验中,s2被设置为48,m1被设置为20,m2是训练图像块总 数量和批大小s2的比率。
[0099]
进一步的,步骤3包括如下步骤:
[0100]
将特征融合网络f生成的融合特征经训练好的译码器d译码得到高质量的融 合图像i
fused
,整个融合过程可以被形式化为:
[0101]
i
fused
=d(f(e(i
ir
),e(i
vis
)))
[0102]
其中,i
ir
和i
vis
分别表示红外图像和可见光图像;e(
·
)表示编码器函数,f(
·
) 表
示特征融合网络函数,d(
·
)表示译码器函数。
[0103]
具体实施时,可采用软件方式实现基于特征空间多分类对抗机制的红外可见 光图像融合网络的设计方案。为了客观地衡量本发明所提方法的融合性能,从定 性和定量两方面评估各方法性能。定性评估是一种主观评估方式,其依赖于人的 视觉感受,好的融合结果应同时包含红外图像的显著对比度和可见光图像的丰富 纹理。定量评估则通过一些统计指标来客观评估融合性能,本文选用了7个在图 像融合领域被广泛使用的定量指标,如视觉信息保真度(visual informationfidelity,vif)、信息熵(entropy,en)、差异相关和(the sum of the correlationsof differences,scd)、互信息(mutual information,mi)、q
ab/f
、标准差(standarddeviation,sd)及空间频率(spatial frequency,sf)。vif测量融合图像保真度, 大的vif值表示融合图像保真度高。en测量融合图像的信息量,en值越大,融 合图像包含的信息越多。scd测量融合图像包含的信息与源图像的相关性,scd 越大意味着融合过程引入的伪信息越少。mi衡量融合图像中包含来自源图像的 信息量,mi越大意味着融合图像包含来自源图像的信息越多。q
ab/f
衡量融合过 程中边缘信息的保持情况,q
ab/f
越大,边缘被保持得越好。sd是对融合图像对 比度的反映,大的sd值表示良好的对比度。sf测量融合图像整体细节丰富度, sf越大,融合图像包含的纹理越丰富。
[0104]
定性对比:首先,5组典型的结果被挑选来定性地展示各算法的性能,如图4 所示。可以看出,本文所提方法有两方面的优势。一方面,本文方法能非常精确 地保留红外图像中的显著目标,它们的热辐射强度几乎没有损失,且边缘锐利。 另一方面,所提方法也能很好地保留可见光图像中的纹理细节。从融合结果的倾 向性可以把对比方法分为两类。第一类是融合结果倾向于可见光图像的方法,如 mdlatlrr、densefuse和u2fusion。从图4中可以看到,这一类方法的融合结果 虽然包含丰富的纹理细节,但其对比度较差,热辐射目标被削弱。例如,在第一 组结果中,mdlatlrr、densefuse和u2fusion对树木纹理保留的较好,但却削 弱了目标建筑物的亮度。类似的还有第二组中的水面、第三和第五组中的人以及 第四组中的坦克。第二类是融合结果倾向于红外图像的方法,如gtf和 fusiongan。这一类方法能较好地保留热目标,但纹理细节不够丰富,它们的结 果看起来很像是锐化的红外图像。如在图4中的第一组结果中,gtf和fusiongan 较好地保留了目标建筑物的显著性,但周边树木的纹理结构却不够丰富。类似地 还有第二组中的灌木、第三组中的路灯以及第四组中的树叶。本发明所提方法综 合了这两类方法的优势。具体来说,所提方法既能像第一类方法那样保持场景中 的纹理细节,又能像第二类方法那样准确保持热辐射目标。值得注意的是所提方 法对热目标边缘保持得比第二类方法更锐利。总的来说,本发明所提方法在定性 对比上优于这些最新方法。
[0105]
定量对比:在20张测试图像上的定量对比结果如表1所示。可以看出,本 发明所提方法在en、scd、mi、q
ab/f
、sd以及sf这6个指标上都取得最好平 均值;在vif上,本发明方法排行第二,仅次于u2fusion。这些结果说明:本 发明方法在融合过程中从源图像传输到融合图像的信息最多、引入的伪信息最 少、能最好地保持边缘。生成的融合结果包含的信息量最大、有最好的对比度、 具有最丰富的整体纹理结构。总的来说,本发明方法相较于这些对比算法在定量 上也是有优势的。
[0106]
表1对比试验的定量结果,加粗表示最好,下横线表示第二好
[0107][0108]
本发明所提出的方法融合速度很快,比对比算法快5倍以上,详见表2。
[0109]
表2各方法在两个数据集上的平均运行时间(单位:秒),加粗表示最好结果
[0110][0111]
以上所述,仅是本发明较佳实施例而已,并非对本发明的技术范围作任何限 制,故凡是依据本发明的技术实质对以上实施例所作的任何细微修改、等同变化 与修饰,均仍属于本发明技术方案的范围的。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1