基于人工智能的CBCT图像增强方法、装置和存储介质与流程
基于人工智能的cbct图像增强方法、装置和存储介质
技术领域
1.本发明涉及图像处理技术领域,尤其涉及一种基于人工智能的cbct图像增强方法、装置和存储介质。
背景技术:
2.为满足物理师和技师在放疗患者临床摆位验证方面的需求,可采用锥形束电子计算机断层扫描(cone beam computed tomography,cbct)技术获取治疗室内患者的三维容积影像,然后与计划ct影像进行三维配准确定患者摆位偏差,至此医护人员可根据该摆位偏差修正患者的摆位。
3.与诊断用ct相比,cbct球管的电流和曝光时间相对较小,机架旋转一圈探测器的采样次数更少,且cbct探测器与ct探测器相比,受散射影响更大,灵敏度低。因此cbct图像比ct图像噪声大、对比度低,这将影响医生摆位的精度,为了解决此问题,需要对cbct图像进行增强。
4.现有技术中,通常采用如下方法对cbct图像进行增强:
5.1、在图像空间域使用各种卷积算子进行图像降噪和边缘增强,例如高斯算子、canny算子、拉普拉斯算子等;
6.2、在频域进行高通滤波,去除图像中的低频信息,降低图像的噪声;
7.3、对图像的灰度直方图进行处理,增加图像的对比度。
8.但是现有技术的鲁棒性不强,对于不同的图像的效果不能完全保持一致,而且去除噪声的过程中不可避免的会损失部分图像信息,导致图像边缘变模糊,在图像对比度增强后,可能会改变图像ct值。
技术实现要素:
9.为了解决上述技术问题,本发明公开了一种基于人工智能的cbct图像增强方法、装置和存储介质,通过本发明方法增强的cbct图像噪声更小、对比度高、ct值更准确,可以有效提高临床医生摆位精度和摆位速度,而且之前受限于cbct较差的ct值准确性,自适应计划无法顺利实施,通过本方法处理后的cbct图像,更有利于自适应计划的制作,进一步提高放疗效果。
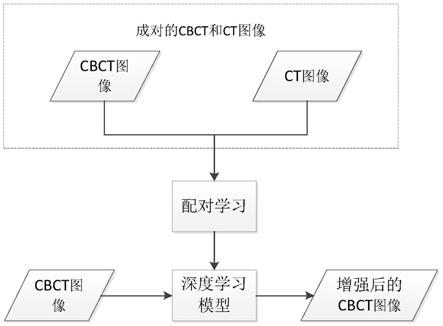
10.具体地,本发明提供了一种基于人工智能的cbct图像增强方法,其包括如下步骤:s1:准备成对的cbct与ct训练图像数据;s2:使用准备好的成对cbct与ct训练图像数据训练学习网络,以得到将cbct图像转换成ct图像的网络模型;s3:将cbct图像输入网络模型,以得到增强后的cbct图像。
11.在进一步的技术方案中,步骤s1包括:s11:使用配准框架对cbct图像与ct图像进行配准;s12:对配对好的cbct图像与ct图像进行像素归一化以及灰度值归一化处理。
12.在进一步的技术方案中,步骤s11包括:s111:对cbct图像与ct图像进行刚性配准,以矫正全局大尺度偏移;s112:在进行刚性配准后,对cbct图像与ct图像进一步进行弹性配
准,以保证两组图像中体内组织一一对应。
13.在进一步的技术方案中,在步骤s2中,基于pix2pix
‑
gans模型来进行深度学习,pix2pix
‑
gans模型包括生成器和判别器,生成器基于输入的cbct图像生成伪ct图像,判别器用于区分cbct图像与伪ct图像。
14.在进一步的技术方案中,所述生成器采用u
‑
net结构,所述判别器使用patchgan结构。
15.在进一步的技术方案中,所述u
‑
net结构采用将输入图像先降采样到低维度,再升采样到原始分辨率的结构,且加入skip
‑
connection,对应的feature maps和decode之后的同样大小的feature maps按通道拼一起,用来保留不同分辨率下像素级的细节信息。
16.在进一步的技术方案中,所述patchgan结构使用gan用于构建高频信息,通过对图像的每个大小为n x n的patch进行真假判别,并将一张图片所有patch的结果取平均作为最终的判别器输出。
17.在进一步的技术方案中,在步骤s12中,将像素大小统一为1mm,将灰度值限制在(
‑
1024,2048),若像素灰度值小于
‑
1024则置为
‑
1024,若像素灰度值大于2048则置为2048,然后将灰度值归一化到(
‑
1,1)。
18.本发明还提供了一种基于人工智能的cbct图像增强装置,其包括:cbct与ct训练图像数据准备模块,用于准备成对的cbct与ct训练图像数据;网络模型训练模块,用于使用准备好的成对cbct与ct训练图像数据训练学习网络,以得到将cbct图像转换成ct图像的网络模型;增强cbct图像输出模块,用于将cbct图像输入网络模型,以得到增强后的cbct图像。
19.本发明另外提供了一种计算机存储介质,其存储有计算机程序,所述计算机程序在被运行时执行如上所述的方法。
20.本发明中的算法可以在完全保持原有边缘的情况下,去除图像中的噪声,且去噪效果比现有技术更好。
附图说明
21.图1是本发明的cbct图像增强方法流程示意图;
22.图2是本发明的图像配准的流程示意图;
23.图3a是配准前的cbct与ct图像;
24.图3b是对cbct与ct图像进行刚性配准后的结果;
25.图3c是对cbct与ct图像进行弹性配准后的结果;
26.图4是本发明的pix2pix
‑
gans网络结构的示意图;
27.图5是本发明的生成器u
‑
net网络结构的示意图。
具体实施方式
28.下面结合具体实施例对本发明的技术方案作进一步的描述,但本发明并不限于这些实施例。
29.在本发明中,设计了一个深度学习模型,使用该模型可以将cbct图像转换成ct图像,经过转换后,cbct图像质量与ct接近,图像中的噪声和伪影明显消失,图像对比度也得
到增强。
30.如图1所示,本发明的基于人工智能的cbct图像增强方法可以包括如下步骤:
31.1、准备cbct与ct的成对数据,ct图像通过ct模拟定位机获得,cbct的获取时间与ct接近,为了保证cbct与ct图像空间信息一致,先使用刚性配准将ct与cbct整体轮廓匹配上,再使用弹性配准保证两组图像中体内组织一一对应。
32.2、将配对好的cbct和ct图像做像素大小归一化、灰度值归一化。
33.3、使用准备好的cbct与ct图像训练深度学习网络,得到将cbct转换成ct图像的网络模型;
34.4、后续再次重建cbct时,将重建好的cbct图像输入网络模型,即可得到增强后的图像。
35.由于病人的cbct和ct数据是在不同的时刻采集的,因此存在一定的偏移和变形,因此在训练模型前,需要使用配准框架对cbct和ct图像进行配准,保证cbct和ct图像空间信息一致,弹性配准框架主要包括刚性配准和弹性配准两大部分,其中刚性配准主要用于校正全局大尺度偏移,弹性配准主要用于恢复局部诸如软组织等形变。整体配准流程图如图2所示。
36.具体配准效果如图3a
‑
图3b所示,其中,图3a为配准前cbct与ct图像,图像中人体部分有明显的错位,图3b为刚性配准后结果,cbct和ct的主体轮廓的偏移得到校正,但皮肤边缘处以及人体内组织还有一定的形变,图3c为弹性配准后的结果,人体局部的形变已经消失,配准后的cbct和ct图像像素一一对应,这样才可以用于后续模型的训练。
37.另外,为了训练模型,可以准备200组cbct和ct的对应数据,像素大小统一为1mm,图像层厚同样为1mm,cbct和ct的灰度值限制在(
‑
1024,2048),像素灰度值小于
‑
1024则置为
‑
1024,像素灰度值大于2048,则置为2048,然后将灰度值归一化到(
‑
1,1)。
38.本发明设计的深度学习模型是基于pix2pix
‑
gans模型,模型由一个生成器g和一个判别器d组成,将cbct图片需要输入生成器中,生成器生成伪ct图像(fake ct)。判别器的输入是cbct和fake ct图像,判别器需要区分出cbct和fake ct。
39.如图4所示,pix2pix
‑
gans使用生成器来解决图像低频成分(纹理信息),用gan(生成式对抗网络)来解决高频成分(图像边缘信息)。生成器使用传统的l1 loss或mse loss来让生成的图片跟训练的图片尽量相似,用gan来构建高频部分的细节。
40.如图5所示,使用u
‑
net网络结构作为生成器,u
‑
net采用将输入图像先降采样到低维度,再升采样到原始分辨率的(encoder
‑
decoder)结构,且加入skip
‑
connection,对应的feature maps和decode之后的同样大小的feature maps按通道拼(concatenate)一起,用来保留不同分辨率下像素级的细节信息。u
‑
net对提升细节的效果非常明显。
41.另一方面,使用patchgan作为判别器,来判别是否是生成的图片。patchgan的思想是,使用gan用于构建高频信息,不需要将整张图片输入到判别器中,让判别器对图像的每个大小为n x n的patch做真假判别就可以了。因为不同的patch之间可以认为是相互独立的。pix2pix对一张图片切割成不同的n x n大小的patch,判别器对每一个patch做真假判别,将一张图片所有patch的结果取平均作为最终的判别器输出。
42.patchgan使用的是一个nxn输入的全卷积小网络,最后一层每个像素过sigmoid输出为真的概率,然后用bceloss计算得到最终loss。这样做的好处是因为输入的维度大大降
低,所以参数量少,运算速度也比直接输入一张快,并且可以计算任意大小的图。
43.在本发明的实施方式中,提供了一种基于人工智能的cbct图像增强方法,其包括如下步骤:s1:准备成对的cbct与ct训练图像数据;s2:使用准备好的成对cbct与ct训练图像数据训练学习网络,以得到将cbct图像转换成ct图像的网络模型;s3:将cbct图像输入网络模型,以得到增强后的cbct图像。
44.在进一步的技术方案中,步骤s1包括:s11:使用配准框架对cbct图像与ct图像进行配准;s12:对配对好的cbct图像与ct图像进行像素归一化以及灰度值归一化处理。
45.在进一步的技术方案中,步骤s11包括:s111:对cbct图像与ct图像进行刚性配准,以矫正全局大尺度偏移;s112:在进行刚性配准后,对cbct图像与ct图像进一步进行弹性配准,以保证两组图像中体内组织一一对应。
46.在进一步的技术方案中,在步骤s2中,基于pix2pix
‑
gans模型来进行深度学习,pix2pix
‑
gans模型包括生成器和判别器,生成器基于输入的cbct图像生成伪ct图像,判别器用于区分cbct图像与伪ct图像。
47.在进一步的技术方案中,所述生成器采用u
‑
net结构,所述判别器使用patchgan结构。
48.在进一步的技术方案中,所述u
‑
net结构采用将输入图像先降采样到低维度,再升采样到原始分辨率的结构,且加入skip
‑
connection,对应的feature maps和decode之后的同样大小的feature maps按通道拼一起,用来保留不同分辨率下像素级的细节信息。
49.在进一步的技术方案中,所述patchgan结构使用gan用于构建高频信息,通过对图像的每个大小为n x n的patch进行真假判别,并将一张图片所有patch的结果取平均作为最终的判别器输出。
50.在进一步的技术方案中,在步骤s12中,将像素大小统一为1mm,将灰度值限制在(
‑
1024,2048),若像素灰度值小于
‑
1024则置为
‑
1024,若像素灰度值大于2048则置为2048,然后将灰度值归一化到(
‑
1,1)。
51.本发明中的方法不会丢失图像中原有的信息,既去除了图像中的噪声和伪影,还保留了图像的边缘信息,增强了图像的对比度,而且,在cbct到ct图像训练模型的过程中,模型保留了ct图像中的部分空间信息,使用该模型增强cbct图像时,可以将ct中的先验知识保留在cbct图像中。
52.在本发明的另一实施方式中,还提供了一种基于人工智能的cbct图像增强装置,其包括:cbct与ct训练图像数据准备模块,用于准备成对的cbct与ct训练图像数据;网络模型训练模块,用于使用准备好的成对cbct与ct训练图像数据训练学习网络,以得到将cbct图像转换成ct图像的网络模型;增强cbct图像输出模块,用于将cbct图像输入网络模型,以得到增强后的cbct图像。
53.在本发明的其他实施方式中,还提供了一种计算机存储介质,其存储有计算机程序,所述计算机程序在被运行时执行如上所述的方法。
54.以上所述的仅是本发明的优选实施方式,应当指出,对于本领域的普通技术人员来说,在不脱离本发明创造构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1