基于层次深度强化学习的复杂游戏AI设计方法
基于层次深度强化学习的复杂游戏ai设计方法
技术领域
1.本发明涉及强化学习和ai设计技术领域,特别是涉及一种基于层次强化学习的设计方法。
背景技术:
2.强化学习(reinforcement learning,rl)将智能体与环境交互作为整体问题,通过选择行为并最大化累计奖励的方式,不断学习并优化策略,从而产生最优行为序列。可通过在游戏场景进行强化学习,基于设定的奖励训练得到复杂环境中ai行为策略。以下介绍几种强化学习:
3.深度强化学习(deep reinforcement learning,drl)结合了深度学习(deep learning,dl)的拟合能力和强化学习的学习能力,在许多场景都取得了很好的效果,但在面对长序贯决策问题时,往往表现不佳。
4.分层强化学习(hierarchical reinforcement learning,hrl)作为强化学习的重要领研究领域,能更好解决长序贯决策问题,与现阶段复杂的游戏ai设计环境也更相匹配。分层强化学习利用分治的思想,将原始问题分解为多个子问题,通过解决子问题来实现原问题的求解。dietterich等在1991年首次提出了这一思想,即将一个马尔可夫决策过程分解为多个子任务(sub
‑
task),每个子任务都有自己的子目标(sub
‑
goal),完成了每个子任务的子目标,那么总体的任务也就完成了。florensa在基于随机神经网络的分层强化学习(stochastic neural networks for hierarchical reinforcement learning,snn4hrl)中提出利用随机神经网络来预先学习环境中有效且通用的技能,同时为每个任务训练一个单独的高级策略,调用不同技能。vezhnevets提出基于fun的分层强化学习(feudal networks for hierarchical reinforcement learning,funhrl)中,设计了工作者(worker)和管理者(manager)双层结构,工作者每n步的迁移结果作为管理者的1步迁移结果,由于管理者的时间粗粒度性质,智能体的探索能力也得到了提高。
5.层次强化学习方法在复杂游戏ai设计中有天然的优势。例如,atari平台的montezuma’s revenge由于环境设定的长序贯、奖励稀疏等特性,传统强化学习方法往往无法在该游戏中取得较好的效果。此外mujoco的迷宫游戏,蚂蚁寻物等也因为其ai场景的高复杂度,需要经过特殊的设计才能取得很好的效果。但通过层次强化学习方法,将任务进行分解为单独的子目标,并给予稳定的奖励,可以极大程度的提升学习得到的控制策略完成任务的水平。因此,层次强化学习方法是通过学习的方式进行复杂游戏ai设计的一种有潜力的解决方案。
6.虽然分层强化学习能较好地解决长序贯决策问题,但这种分层结构通常需要采用同策略训练方法,样本利用效率低,且训练难度大。由此,nachum提出了hiro,将分层强化学习与异策略训练相结合,同时采用异策略修正方法,通过最大似然估计,替换样本中的子目标。实验结果表明,hiro算法的效果优于funhrl算法和snn4hrl算法。但是,hiro算法使用随机采样的方法近似求解替换子目标,这样的做法无法对子目标空间做很好的限制,子目标
仍然有可能选到没有意义的或者说无法抵达的,使得下层学习存在问题,进而导致整的层次联动训练的不稳定和低效。
7.随着游戏产业的发展,游戏机制和行为逻辑变得越来现实与复杂,很多场景下需要设计复杂行为的ai与游戏、玩家进行交互,这类ai的设计水平极大程度上影响着游戏产品的质量以及玩家用户的游戏体验。针对这类ai的设计往往费时费力,对游戏开发工作者是巨大的挑战。本发明通过层次强化学习方法,可以将ai与环境交互的行为任务,分解为一系列子目标任务,ai在完成子目标的过程中,可以逐步完成复杂任务,并最终掌握复杂游戏场景下的ai行为策略。
8.对下层智能体目标的指定还没有一个很成熟的方法。目前的主流方法把智能体的状态作为子目标给予下层策略,这样做的话很可能发生上层智能体给予下层一个n步内无法到达的目标,或者一个没有意义的目标。这些子目标加大了下层策略的学习难度,但并没有实际的意义;原则上,这些状态都可以被替换为n步内可以到达的状态。在层次强化学习方法中,这个问题还没有得到解决,需要一个合理的方法进行改进和提升,以使层次强化学习能够在实际的游戏ai设计中有更大应用空间。
技术实现要素:
9.本发明而提出了一种基于层次深度强化学习的复杂游戏ai设计方法,旨在解决在游戏中的复杂行为ai智能设计问题。
10.本发明的一种基于层次深度强化学习的复杂游戏ai设计方法,该方法包括以下流程:
11.步骤1、将标准强化学习扩展成包括一个下层策略和一个上层策略的两层结构,从而构建成层次强化学习,进行上层策略、下层策略和预测模型初始化;
12.步骤1
‑
1、向所构建的层次强化学习方法中的上层策略输入智能体状态,上层策略在当前时刻t通过神经网络对应地输出该智能体状态下的子目标到下层策略当中,公式如下:
13.g
t
~π
hi
(s
t
)
14.其中,s
t
表示当前时刻t下的智能体状态,π
hi
(s
t
)表示上层策略,g
t
表示当前时刻t下子目标,~表示从给定的分布下采样;
15.步骤1
‑
2、下层策略基于当前智能体状态,生成子目标与环境交互的对应的执行动作,公式如下:
16.a
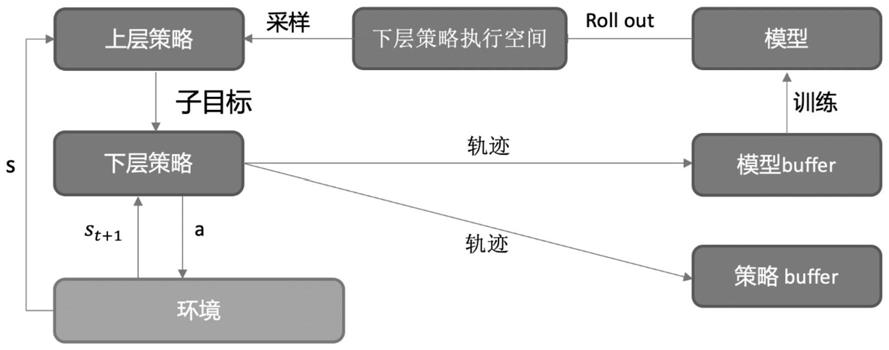
t
~π
lo
(s
t
,g
t
)
17.其中,π
lo
(s
t
,g
t
)表示当前下层策略,a
t
为下层策略在当前状态下经过网络生成的动作action,~表示从给定的分布下采样;
18.经过动作action与环境交互后,进入下一状态智能体状态s
t+1
,从而产生下层策略轨迹,将下层策略轨迹存入回放缓冲区replay buffer;
19.步骤1
‑
3、完成一组下层策略轨迹后,通过下层策略将子目标修正为下一个状态下的子目标,具体公式如下:
20.g
t
′
=h(s
t
‑1,g
t
‑1,s
t
)
21.其中,s
t
‑1表示上一时刻t
‑
1的智能体状态,g
t
‑1表示上一时刻t
‑
1的子目标;
22.然后,子目标执行动作与环境交互k
‑
1个时间步,由下层策略完成子目标;之后,返回状态s
t+k
再由上层策略执行,生成下一子目标;
23.步骤1
‑
4、按照步骤1
‑
1至1
‑
3与环境进行交互,保存交互样本,上层策略和下层策略均按照双延迟确定性策略梯度方法进行更新;
24.步骤2、通过下层策略轨迹(s
t
,g
t
,a
t
,r
t
s
t+1
)训练一个基于s
t
和a
t
预测s
t+1
的预测模型,进而拟合分布来得到世界模型p
θ
(s
′
|s,a),其含义为输入s
t
和a
t
预测出一个s
t+1
,p
θ
表示这个预测模型的分布;
25.下层策略会不断训练和执行,从而生成更多轨迹来完善预测模型,最后,得到下层策略和预测模型两者收敛到最优;
26.步骤3、迭代地进行上层策略子目标候选集采样:按照步骤2,在找好下层策略所能抵达的空间后,用该空间中的所有可选子目标作为上层策略的在根据特定状态选择子目标时的候选集,采样出下层策略所抵达的子目标,给予下层策略执行和学习;该步骤完成了对上层策略动作空间的合理约减,从而得到不断完善的策略和世界模型。
27.与现有技术相比,本发明在降低策略训练难度的前提下,使ai在复杂游戏场景下更快更稳定学习到成熟的策略,有效地提高了策略所能达到的效果。
附图说明
28.图1为本发明的基于层次深度强化学习的复杂游戏ai设计方法流程示意图;
29.图2为本发明的基于层次深度强化学习的复杂游戏ai设计方法架构实施例示意图;
30.图3为本发明的下层网络结构示意图;
31.图4为本发明的预测模型结构示意图。
具体实施方式
32.下面结合附图和实施例对本发明的技术方案进一步说明。
33.如图1所示,为本发明的基于层次深度强化学习的复杂游戏ai设计方法流程示意图。
34.本发明技术方案的主要步骤概括如下:
35.1.初始化上层策略、下层策略,初始化预测模型,之后执行以下处理:
36.a)上层策略在初始状态随机给予下层策略子目标goal;
37.b)下层策略基于状态state和子目标goal执行k个时间步,并在下层基于子目标转移公式更新子目标,产生下层策略轨迹;
38.c)保存下层策略轨迹,并使用该轨迹训练下层策略和预测模型;
39.d)世界模型进行初步roll
‑
out产生轨迹,并构建世界模型;
40.e)k步后上层策略产生轨迹并保存,同时训练上层策略;
41.2.在一定步数后,上层策略基于状态从构建好的世界模型中找到合适的子目标集合,并采样子目标给予下层策略并执行k步;
42.3.迭代上述过程,不断完善策略和世界模型。
43.如图2所示,为本发明的基于层次深度强化学习的复杂游戏ai设计方法架构实施
例示意图。本发明具体实施方式具体流程如下:
44.步骤1、构建基于层次强化学习方法的强化学习架构:基于层次深度强化学习的复杂游戏ai设计方法整体包含上层策略、下层策略,两层策略之间不存在梯度,都由双延迟确定性策略梯度方法(twin delayed deep deterministic policy gradient algorithm)进行实现,如图3所示。上层策略输入为状态,输出为子目标。下层策略输入为状态和子目标,输出为动作并与环境进行交互。
45.步骤1
‑
1、进行子目标的生成,输入信息为智能体状态,输出信息为该状态下的子目标goal,输入与输出维度都等于状态空间的维度。网络结构包含三个线性层和relu激活层。层策略每k=10时间步生成一个子目标并更新一次策略,在这k=10时间步过程中,只有下层策略进行执行,上层策略既不执行也不更新;
46.步骤1
‑
2、下层策略基于当前智能体状态和子目标执行动作与环境交互k=10步:网络输入维度为状态空间和子目标的拼接,输出为动作空间的维度。网络结构与上层策略网络结构相同。下层在每一个时间步都进行策略的执行和更新,在这10步过程中,第一步下的子目标由上层策略生成,后面需要由子目标转移公式进行子目标的调整。在下层策略执行过程中,在每次执行动作与环境交互之后,下层在执行剩余步骤之前通过子目标转移公式将子目标修正为下一个状态下的子目标,具体公式如下:
47.h(s
t
,g
t
,s
t+1
)=s
t
+g
t
‑
s
t+1
48.子目标代表一个相对位置的状态信息,根据上一步子目标和状态以及这一步的状态推导出这一步下的子目标。实质上相当于要求下层策略在10步内达到一个子目标,由子目标转移函数(subgoal transition function)来保证子目标的一致性;
49.步骤1
‑
3、上、下层策略按照步骤1
‑
1、1
‑
2与环境进行交互,保存交互样本,上下层均按照双延迟确定性策略梯度方法(twin delayed deep deterministic policy gradient algorithm)进行更新。其中actor网络优化公式为:
[0050][0051]
其中,π
φ
表示策略网络,a=π
φ
(s)即根据策略网络输出动作action,表示梯度,表示动作价值网络,表示基于给定状态和动作给出动作价值,n
‑1∑表示最后对整体的梯度求平均。
[0052]
critic网络优化公式为:
[0053][0054][0055]
其中,s
′
表示下一时刻的状态,表示下一时刻的动作,表示动作价值函数,min表示取两个动作价值的最小值,γ为奖励衰减参数,r表示reward,n
‑1∑表示对整体结果求平均。
[0056]
步骤2、世界模型的构建:拟使用基于模型的强化学习方法构建世界模型,如图4所示,通过采样下层策略轨迹(s
t
,g
t
,a
t
,r
t
s
t+1
)进行训练,即通过拟合分布来训练一个世界模型p
θ
(s
′
,r|s,a),根据state和action预测下一步状态以及奖励。训练时使用的loss为奖励
和下一步状态的实际结果与预测结果的均方误差,训练好一个世界模型后,再从轨迹覆盖到的state开始根据随机策略或者探索策略等进行roll
‑
out,使用roll
‑
out出的轨迹中state所覆盖的空间作为子目标可以抵达的状态空间。在这个过程中下层策略会不断训练和执行,从而生成更多轨迹来完善预测模型,预测模型也会更好的预测下层空间可以抵达的范围,最后两者收敛到最优;
[0057]
步骤3、进行上层策略的子目标候选集采样:按照步骤2,在找好下层策略所能抵达的空间后,用该空间中的所有可选子目标作为上层策略的在根据特定状态选择子目标时的候选集,采样出下层策略可以抵达的子目标,给予下层策略执行和学习;该步骤完成了对上层策略动作空间的合理约减。
[0058]
通过之前训练好的世界模型,获得下层策略空间中任一状态所能抵达的范围空间。通过该方法来获得的空间内的状态是在单个子目标执行周期内底层理论上能够到达的合理的选择。用该空间中的所有可选子目标作为上层策略的在根据特定状态选择子目标时的候选集,采样出下层策略可以抵达的子目标给予下层策略执行和学习。
[0059]
在执行过程中,首先训练层次强化学习方法中的下层策略,上层随机给予子目标goal。下层策略基于goal产生轨迹并进行训练。世界模型可以基于当前下层策略产生的轨迹进行训练,然后根据状态和随机动作进行初步的roll
‑
out。当上层策略开始训练时,可以由上层策略在世界模型中进行子目标的选择,再给予下层策略进行执行,并生成更多轨迹。这些轨迹一方面训练下层策略,一方面继续完善世界模型,使世界模型更好的覆盖下层策略可达的范围,直到收敛。
[0060]
在层次强化学习方法中,下层的子目标空间,相当于上层策略的动作空间。如果对子目标空间不加以限制,首先对于上层策略来说,基于相同的状态,动作空间变大意味着学习的复杂度提升,且很多动作空间并不会泛化到,导致学习过程十分缓慢不稳定;对于下层策略来说,子目标是输入的一部分,子目标空间大意味着下层策略的状态空间更大,且存在很多无意义的子目标,需要下层策略进行识别和学习,影响了下层策略的学习进度,同时扩大了高、下层策略之间的不稳定性。通过解决这个问题,可以极大程度提升层次强化学习方法的效率和最终结果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1