一种用于连续空间兵棋推演的多智能体决策方法
1.本发明属于智能决策领域,具体涉及一种用于连续空间兵棋推演的多智能体决策方法。
背景技术:
2.在早期的兵棋推演领域中,多采用网格化的离散数据特征对当前的局势进行判断。但随着技术的进步,越来越多的连续化状态空间的兵棋推演平台被推出。这类平台相较于之前的平面化兵棋推演平台,将整个推演环境从二维拓展到了空间三维领域,对推演单元的状态描述从离散的网格发展到连续的三维空间,推演更加真实。兵棋推演平台的发展,相应的也带来了学习训练的难度,包含状态空间爆炸,动作连续、长时奖励的影响,多智能体的合作与对抗等。在这类平台中,基于全连接(full connect,fc)网络的特征提取方式处理上述问题时,收敛较慢。同时仅使用稀疏的竞争奖励无法对智能体进行有效的训练。
技术实现要素:
3.本发明的目的是,提供一种用于连续空间兵棋推演的多智能体决策方法,该方法采用基于卷积神经网络(cnn)的特征提取方法,优于基于全连接(full connect,fc)的特征提取方法,收敛速度更快;该方法利用探索奖赏和竞争奖赏相结合的课程学习奖赏塑造q学习算法,收敛速度更快,对智能体动作的指导性更强,使得多智能体在连续空间兵棋推演中的决策效率更高,决策方案更贴合对战实际。。
4.本发明采用值分解网络的思想,分别输出每个智能体的动作。在智能体的输入端,通过通信的方式,将各个智能体的观测进行融合,同时多智能体的本地观测也作为一部分输入。在训练阶段,将包含了联合动作奖赏的竞争奖赏传给智能体,还将单个智能体的私有探索奖赏同样进行回传,保证了多智能体对基本动作的学习。
5.本发明的技术方案是:一种用于连续空间兵棋推演的多智能体决策方法,其特征在于,包括以下步骤:
6.步骤1,构建连续空间的兵棋推演场景,得到用于兵棋推演的战场环境数据,多智能体进行初始化;
7.步骤2,构建经验重访数据集,所述的经验重访数据集d
t
={e1,e2,...,e
t
}存储了多智能体在每一个时间步的经验e
t
=(s
t
,a
t
,r
t
,s
t+1
),包含当前的状态s
t
,采取的动作a
t
,当前转移获得的奖赏r
t
以及下一个时间步的状态s
t+1
;构建目标函数,所述目标函数为:
[0008][0009]
其中,q为q值,即目标函数,α为学习率,γ为奖励性衰变系数;
[0010]
步骤3,多个智能体进行本地观测;
[0011]
步骤4,基于cnn提取推演多智能体的多实体特征;
[0012]
步骤5,所述的多实体特征与多智能体的本地观测数据共同作为多智能体学习的输入,利用基于课程学习奖赏的q学习训练多智能体;
[0013]
步骤6,利用训练完成的多智能体进行对战决策;
[0014]
所述步骤5中,所述课程学习奖赏是探索奖赏和竞争奖赏相结合的课程学习奖赏方法;所述探索奖赏是指在训练的起始阶段,多智能体学习基本的动作使用的密集私有奖赏,探索奖赏随着仿真训练的推进逐渐趋向于零;所述竞争奖赏是指稀疏全局奖赏,是仿真结果的胜负奖赏。所有的智能体的训练都以最大化全局奖赏为目标。
[0015]
作为上述技术方案的进一步改进:
[0016]
更进一步的,所述步骤1中构建连续空间的兵棋推演场景,即将连续空间兵棋推演场景形式化的定义为分布式局部观测mdp过程,具体表示为如下七元组(i,s,{a
i
},{z
i
},t,r,o);其中,i表示有限的智能体的集合;s表示状态集;{a
i
}表示智能体i的动作集;{z
i
}表示智能体i的观测集;t表示所有智能体的联合状态t(s'|s,{a1,...,a
n
})转移,s'∈s,s∈s,a1,...,a
n
∈{a
i
};r表示全局动作奖赏;o表示单个智能体的观测模型,环境状态s下,单个智能体的观测状态函数为o(s,i)=o
i
。
[0017]
更进一步的,所述步骤4中基于cnn提取推演多智能体的多实体特征的方法为:用一个1
×
n的横向卷积核,对单实体的信息压缩成为一个值,通过输出多个通道,将实体信息压缩为多个值;之后通过m
×
1的纵向卷积核对多个实体的信息进行融合压缩。
[0018]
更进一步的,所述步骤5中探索奖赏和竞争奖赏相结合的课程学习奖赏方法通过线性退火因子μ来实现;在仿真时刻t,获得的探索奖赏为r
texploration
,竞争奖赏为r
tcooperation
,该仿真片段的总步长为t,t即时刻,表示该次仿真结束,获得胜负结果,则获得的奖赏值为:
[0019]
r
t
=μ
t
r
texploration
+(1
‑
μ
t
)r
tcooperation
;μ
t
:1
→
0,t:0
→
t
[0020]
线性退火因子μ
t
随着仿真时间推进不断降低,逐渐趋近于零。
[0021]
更进一步的,该发明采用值分解网络的思想,分别输出每个智能体的动作;在多智能体的输入端,通过通信的方式,将各个智能体的观测进行融合,同时各个智能体的本地观测作为一部分输入。
附图说明
[0022]
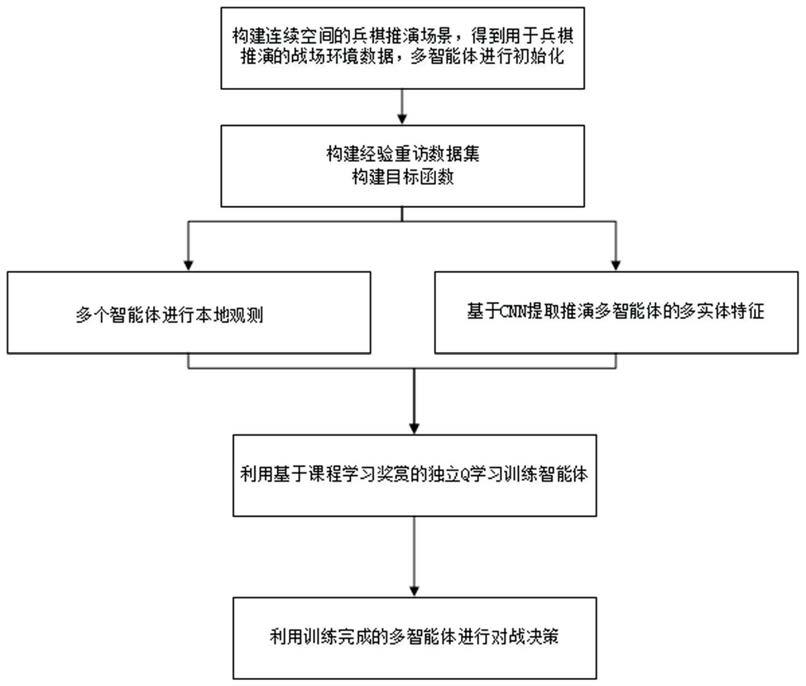
图1为本发明方法的整体流程图;
[0023]
图2为本发明中基于值分解网络的训练图;
[0024]
图3为本发明中单智能体网络架构;
[0025]
图4为实施例中基于cnn和fc的特征提取方法对内置规则1的对战结果对比;
[0026]
图5为实施例中基于cnn和fc的特征提取方法对内置规则2的对战结果对比;
[0027]
图6为实施例中基于课程学习奖赏的q学习和基于稀疏奖赏的vdn、qmix分别对内置规则1的对战结果对比;
[0028]
图7为实施例中基于课程学习奖赏的q学习和基于稀疏奖赏的vdn、qmix分别对内置规则2的对战结果对比;
[0029]
图8为实施例中基于课程学习奖赏的q学习、vdn和qmix分别对内置规则1的对战结果对比;
[0030]
图9为实施例中基于课程学习奖赏的q学习、vdn和qmix分别对内置规则2的对战结果对比。
具体实施方式
[0031]
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述,显然,所描述的实施例仅仅是本发明一部份实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0032]
随着技术的进步,越来越多的连续化状态空间的兵棋推演平台推出,这类平台相较于之前的平面化兵棋推演平台,将整个推演环境从二维拓展到了空间三维领域,对推演单元的状态描述从离散的网格发展到连续的三维空间,推演更加真实。兵棋推演平台的发展,相应的也带来了学习训练的难度,包含状态空间爆炸,动作连续、长时奖励的影响,多智能体的合作与对抗等。
[0033]
对于多智能体的合作和对抗,本发明采用值分解网络的思想,分别输出每个智能体的动作,如图2所示。在智能体的输入端,通过通信的方式,将各个智能体的观测进行融合,即为红蓝双方的状态信息。为了让不同的智能体获得不同的动作,该实施例将智能体的本地观测也作为一部分输入。在训练阶段,将包含了联合动作奖赏的竞争奖赏传给智能体,还将单个智能体的私有探索奖赏同样进行回传,保证了智能体对基本动作的学习。
[0034]
如图1所示,一种用于连续空间兵棋推演的多智能体决策方法,其特征在于,包括以下步骤:
[0035]
步骤1,构建连续空间的兵棋推演场景,得到用于兵棋推演的战场环境数据,多智能体进行初始化;
[0036]
步骤2,构建经验重访数据集,所述的经验重访数据集d
t
={e1,e2,...,e
t
}存储了多智能体在每一个时间步的经验e
t
=(s
t
,a
t
,r
t
,s
t+1
),包含当前的状态s
t
,采取的动作a
t
,当前步转移获得的奖赏r
t
以及下一个时间步的状态s
t+1
;构建目标函数,所述目标函数为:
[0037][0038]
其中,q为q值,即目标函数,α为学习率,γ为奖励性衰变系数;
[0039]
步骤3,多个智能体进行本地观测;
[0040]
步骤4,基于cnn提取推演多智能体的多实体特征;
[0041]
步骤5,所述的多实体特征与多智能体的本地观测数据共同作为多智能体学习的输入,利用基于课程学习奖赏的q学习训练多智能体;
[0042]
步骤6,利用训练完成的多智能体进行对战决策;
[0043]
其中,步骤1所述的一种用于连续空间兵棋推演的多智能体决策方法,其特征在于,所述步骤1构建连续空间的兵棋推演场景:即将连续空间兵棋推演场景形式化的定义为分布式局部观测mdp过程,具体表示为如下七元组(i,s,{a
i
},{z
i
},t,r,o);其中,i表示有限的智能体的集合;s表示状态集;{a
i
}表示智能体i的动作集;{z
i
}表示智能体i的观测集;t表示所有智能体的联合状态t(s'|s,{a
1,...,
a
n
})转移;r表示全局动作奖赏;o表示单个智能体的观测模型o,环境状态s下,单个智能体的观测状态函数为o(s,i)=o
i
。
[0044]
其中,如图3所示,所述步骤3中,该实施例采用基于卷积神经网络(cnn)的特征提取方式,采用一个1
×
n的横向卷积核,对单实体的信息压缩成为一个值,通过输出多个通道,将实体信息压缩为多个值;之后通过m
×
1的纵向卷积核对多个实体的信息进行融合压
缩,获得对全体实体状态信息的特征表示。同基于fc的特征提取方式相比,该方法在网络内部构建了通信模式,将多实体的信息在网络内进行了深度融合,其对多实体的状态表达具有更好的整体性。
[0045]
其中,在所述步骤4中,探索奖赏和竞争奖赏相结合的课程学习奖赏方法通过线性退火因子α来实现;在仿真时刻t,获得的探索奖赏为r
texploration
,竞争奖赏为r
tcooperation
,该仿真片段的总步长为t,t即时刻,表示该次仿真结束,获得胜负结果,则获得的奖赏值为:
[0046]
r
t
=α
t
r
texploration
+(1
‑
α
t
)r
tcooperation
;α
t
:1
→
0,t:0
→
t
[0047]
线性退火因子α
t
随着仿真时间推进不断降低,逐渐趋近于零。
[0048]
其中,在所述步骤5中,课程学习奖赏是探索奖赏和竞争奖赏相结合的课程学习奖赏方法;探索奖赏是指在训练的起始阶段,多智能体学习基本的动作使用的密集私有奖赏,探索奖赏随着仿真训练的推进逐渐趋向于零;竞争奖赏是指稀疏全局奖赏,是仿真结果的胜负奖赏。
[0049]
该实施例的通过如下想定来评估该发明方法。
[0050]
该实施例的想定包含第四届兵棋推演机机对抗博弈赛的主要实体,能够快速验证我们的算法性能。该想定包含红蓝双方,双方配置相同,各有一艘需要保护的船只,和一个可供飞机起飞的机场以及三架飞机。双方飞机从各自的机场起飞,去打击对方的船只,船只不具备防御能力。红蓝各方若想取得胜利,需要先打击对方的在空飞机,获得制空权才可以对船只打击。该想定包含两个内置规则。该想定下的事件得分为损失/击落一架飞机分到
‑
/+139分,击沉/被击沉船只得到+/
‑
1784分。该得分能够很好地激发飞机进行积极的进攻,避免消极防御。
[0051]
在该想定中,本方的智能体间主要是合作为主,智能体通过自身的观测学习合作行为,所有的智能体都以最大化全局奖赏为目标。红蓝双方的作战力量是对称的,因而该实施例中红蓝双方的状态设计如下:定义可能包含的最大有效实体数量为13,每个实体包含经度、纬度、高度、速度、航向、目标纬度、目标经度等七个信息,其中飞机的目标纬度和目标经度表示其飞往的目标点信息,而飞机携带导弹的目标纬度和目标经度则表示其要打击的目标信息(如果目标消失,则为0)。
[0052]
红蓝双方对对方的信息感知是利用探测获得,只有在雷达探测范围内的目标才能被观测到,而且观测具有一定的观测误差,因而获得是不完全的对手信息。同样,对手的信息最大也是13个实体,每个实体包含经度、纬度、高度、速度和航向等五个信息,其中前三个实体表示飞机,后十个为导弹信息。
[0053]
因而,对于己方和对手的信息表示都是分成了两部分进行描述,不足的位置补0。对飞机的动作设计包含了离散化的六个飞机航向、三个高度、三个武器打击距离以及三个速度变化,每一个飞机的动作空间为108个。
[0054]
基于以上想定,该实施例分别采用基于全连接(full connect,fc)网络和基于卷积神经网络cnn的特征提取算法,对两个内置规则分别进行了对抗学习,学习效果如图4,图5。图4显示了基于fc和基于cnn的特征提取对规则1的对抗结果,从实验结果中可以发现,基于cnn的特征提取方法优于基于fc的特征提取方法,收敛速度更快。图5显示了基于fc和基于cnn的特征提取对内置规则2的对抗结果。从实验结果中可以发现,基于cnn的特征提取方法其收敛速度快于基于fc特征提取方法的收敛速度。
[0055]
基于以上想定,该实施例分别采用基于课程学习奖赏方法的q学习和基于仅竞争奖赏方法的vdn、qmix分别对两个内置规则分别进行了对抗学习,学习效果如图6,图7。基于课程学习奖赏塑造的q学习同基于稀疏奖赏的同值分解网络(value decomposition net
‑
work,vdn)和qmix等算法相比,在同样的训练时间内,基于课程学习奖赏塑造的q学习已经趋向收敛,在实验环境中,能够成功攻击掉对方单位的船只;而基于稀疏奖赏的vdn和qmix等算法在相同的训练时间内,飞机仍然在原地盘旋,不能够有效的飞往交战空域进行对抗,虽然飞机没有损失,但每次都被对方飞机打掉己方船只。
[0056]
基于以上想定,该实施例分别将基于课程学习奖赏的q学习、基于课程学习奖赏的vdn和基于课程学习奖赏的qmix这三种算法对两个内置规则分别进行了对抗学习,学习效果如图8,图9。比较于课程学习奖赏塑造的q学习,采用课程学习奖赏的vdn和qmix在同样的训练时间内,训练结果依然没有超越课程学习奖赏塑造的q学习,而且在训练的早期,一直在起飞区域上空盘旋,无法有效的学习到前往交战空域的策略。
[0057]
本领域技术人员应明白,本技术的实施例可提供为方法、系统或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd
‑
rom、光学存储器等)上实施的计算机程序产品的形式。
[0058]
虽然上面已经参考各种实施例描述了本发明,但是应当理解,在不脱离本发明的范围的情况下,可以进行许多改变和修改。因此,其旨在上述详细描述被认为是例示性的而非限制性的,并且应当理解,以下权利要求(包括所有等同物)旨在限定本发明的精神和范围。以上这些实施例应理解为仅用于说明本发明而不用于限制本发明的保护范围。在阅读了本发明的记载的内容之后,技术人员可以对本发明作各种改动或修改,这些等效变化和修饰同样落入本发明权利要求所限定的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1