一种基于树状基学习器的混合特征数据聚类方法及系统与流程
1.本发明属于混合特征数据集聚类技术领域,具体涉及一种基于树状基学习器的混合特征数据聚类方法及系统。
背景技术:
2.针对供能站的车辆数据集,数据特征的高维度以及连续特征和离散特征的混合两个方面都对传统聚类算法提出了挑战,特别是基于欧式距离的聚类算法。在“维数灾难”的情况下,所有的样本都将会近似等距并且相邻,从而使得最近邻的问题可能会变得不具有意义。其次,许多依赖于传统距离度量的算法对不同单位的属性是很敏感的,虽然数据转换可以用来缓解这一问题,但这有可能改变数据的分布,影响到聚类结果。并且,在大数据情况下,过大的样本量会导致有些聚类算法失效,如谱聚类。
3.对于高纬度混合型数据的处理,由于其高纬度的特点以及对混合数据没有明确定义相似性的概念,当数据集包含数值特征和分类特征时,计算两个数据点的相似性问题将会变得更加困难。
4.例如申请号为cn201910308311.7的中国发明专利,其公开了一种基于som神经网络与k-均值聚类的窃电检测方法及系统,其方法包括:从用户负荷曲线中随机抽取数据作为训练样本,并对所述训练样本进行归一化处理,获取处理样本;基于som神经网络对所述处理样本进行聚类,获取所述处理样本的聚类数和初始聚类中心;将所述聚类数和所述初始聚类中心作为k-均值聚类的初始值,基于所述k-均值聚类对所述处理样本进行聚类,获取用户负荷特征曲线;计算待检测用户负荷与其用户负荷特征曲线的欧式距离,获取所述待检测用户负荷与其用户负荷特征曲线的欧式距离;当所述欧式距离大于预先设定的阈值时,则将所述用户判断为窃电嫌疑用户。该专利即通过欧式距离进行聚类,无法对高纬度混合型数据进行准确的聚类处理。
5.因此,亟需一种能针对高纬度混合型数据进行准确聚类的方案。
技术实现要素:
6.针对现有技术中存在的上述问题,本发明提出一种基于树状基学习器的混合特征数据聚类方法及系统,可针对高纬度混合型数据进行准确聚类。
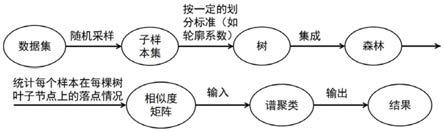
7.本发明采用以下技术方案:一种基于树状基学习器的混合特征数据聚类方法,包括步骤:
8.s1、对样本集进行随机子采样生成n个不同的子样本集;
9.s2、对每个子样本集进行树状基学习器的训练,并得到训练完成后的n颗树以及聚类簇数量k;
10.s3、基于训练完成后的n颗树,统计任意两个样本之间的相似度矩阵,并将所有相似度矩阵归一化,以得到多个归一化相似度矩阵;
11.s4、将聚类簇数量k以及多个归一化相似度矩阵作为谱聚类模型的输入,以得到样
本集最终的聚类结果。
12.优选地,步骤s1具体包括以下步骤:
13.s1.1、初始化聚类森林,设置聚类森林中树的棵树为n;
14.s1.2、设置子样本集内样本个数为ψ;
15.s1.2、对样本集采样n次,每次从样本集中随机不放回采样ψ个样本,以生成n个子样本集。
16.优选地,步骤s2中具体包括以下步骤:
17.s2.1、初始化树状基学习器,设置树的最大深度,并生成每颗树的根节点;
18.s2.2、随机挑选一子样本集,将该子样本集中的所有样本均放入一根节点;
19.s2.3、选取树中一个未访问过的节点,随机选取一种样本特征,遍历该节点中所有样本与该样本特征相关的值,作为当前节点的多个分割阈值;
20.s2.4、根据每个分割阈值,分别对当前节点中的样本进行左右树划分,并分别计算划分后每个样本的样本轮廓系数;
21.s2.5、分别根据每个分割阈值下每个样本的轮廓系数计算整棵树的整树轮廓系数;
22.s2.6、判断是否存在分割阈值,以使划分后整树轮廓系数大于划分前整树轮廓系数,若存在,则挑选使得整树轮廓系数最大的分割阈值作为划分阈值,并按划分阈值对当前节点中的所有样本进行左右树划分,并产生两个新的节点;若不存在则不进行左右树划分,也不产生新节点;
23.s2.7、重复步骤s2.3-s2.6,直至树中的所有节点均已被访问或者树的深度已达到最大深度,完成当前树的训练;
24.s2.8、重复步骤s2.2-s2.7,直至所有树均训练完成;
25.s2.9、对每棵树的节点个数求取平均值,以得到聚类簇数量k。
26.优选地,步骤s2.4中样本轮廓系数的计算公式具体为:
[0027][0028]
其中,a(i)是样本i到其节点内其他样本的平均距离,b(i)是样本i到相邻最近一节点内所有样本的平均距离。
[0029]
优选地,步骤s2.5中,整树轮廓系数通过对树中每个样本的轮廓系数取平均值得到。
[0030]
优选地,步骤s3具体包括以下步骤:
[0031]
s3.1、初始化相似度矩阵;
[0032]
s3.2、将任意两个样本分别放入步骤2训练好的每一颗树中;
[0033]
s3.3、通过判断两个样本在每一颗树中是否落入同一节点,以形成该两个样本之间的相似度矩阵;
[0034]
s3.4、重复步骤s3.2-s3.3,直至得到所有样本之间的相似度矩阵。
[0035]
s3.5、将所有相似度矩阵进行归一化,以得到所有样本之间的多个归一化相似度矩阵。
[0036]
优选地,步骤s3.5中所述归一化相似度矩阵为通过将相似度矩阵除以树的总数n
得到。
[0037]
优选地,n=50,ψ=30。
[0038]
优选地,树的最大深度为10。
[0039]
相应地,还提供了一种基于树状基学习器的混合特征数据聚类系统,包括依次相联的子样本集生成模块、树状基学习模块、相似度矩阵模块、聚类模块,聚类模块还与树状基学习模块联接;
[0040]
子样本集生成模块,用于对样本集进行随机子采样生成n个不同的子样本集;
[0041]
树状基学习模块,用于对每个子样本集进行树状基学习器的训练,并得到训练完成后的n颗树以及聚类簇数量k;
[0042]
相似度矩阵模块,用于基于训练完成后的n颗树,统计任意两个样本之间的相似度矩阵,并将所有相似度矩阵归一化,以得到多个归一化相似度矩阵;
[0043]
聚类模块,用于将聚类簇数量k以及多个归一化相似度矩阵作为谱聚类模型的输入,以得到样本集最终的聚类结果。
[0044]
本发明的有益效果是:设计了高纬度、混合特征情况下的数据聚类方法。本发明引入树状结构在不进行数据转换的情况下同时处理连续特征和离散特征,利用树的叶子节点可以视为一个簇的思想进行聚类操作;进一步运用集成思想提高聚类质量,进一步统计任意两个样本到达森林中每棵树同样的叶子节点的次数来计算相似度矩阵,定义了高纬度、混合特征数据之间的相似度,且本发明中可自动确定聚类簇数量k。本发明对于工程中特征数值复杂的数据集聚类有重要应用价值。
附图说明
[0045]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0046]
图1是本发明所述一种基于树状基学习器的混合特征数据聚类方法的流程图;
[0047]
图2是森林参数ψ的设置与聚类纯度的关系结果图;
[0048]
图3是森林参数n的设置与聚类纯度的关系结果图;
[0049]
图4是聚类结果中每一个簇内的车辆价格箱线图;
[0050]
图5是聚类结果中每一个簇内的车辆净重箱线图;
[0051]
图6是聚类结果中每一个簇内的车身长度箱线图;
[0052]
图7是本发明所述一种基于树状基学习器的混合特征数据聚类系统的结构示意图。
具体实施方式
[0053]
以下通过特定的具体实施例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实
施例中的特征可以相互组合。
[0054]
实施例一:
[0055]
本实施例通过基于供能站采集到的车辆数据来阐述具体操作步骤以及验证本发明方案的效果,车辆数据集的特征个数、类型如下表1所示:
[0056][0057]
表1车辆数据表
[0058]
参照图1,本实施例提供了一种基于树状基学习器的混合特征数据聚类方法,包括步骤:
[0059]
s1、对样本集进行随机子采样生成n个不同的子样本集;
[0060]
s2、对每个子样本集进行树状基学习器的训练,并得到训练完成后的n颗树以及聚类簇数量k;
[0061]
s3、基于训练完成后的n颗树,统计任意两个样本之间的相似度矩阵,并将所有相似度矩阵归一化,以得到多个归一化相似度矩阵;
[0062]
s4、将聚类簇数量k以及多个归一化相似度矩阵作为谱聚类模型的输入,以得到样本集最终的聚类结果。
[0063]
具体地:
[0064]
步骤s1具体包括以下步骤:
[0065]
s1.1、初始化聚类森林,设置聚类森林中树的棵树为n;
[0066]
s1.2、设置子样本集内样本个数为ψ;
[0067]
s1.2、对样本集采样n次,每次从样本集中随机不放回采样ψ个样本,以生成n个子样本集。
[0068]
在本实施例中,由于为无监督学习,参数ψ与n无法通过学习得到,需提前设置,所以我们选取了四个常用数据集对参数ψ从16遍历到128,对参数n从1遍历到100,如图2、图3所示,可发现这四个数据集最终的聚类纯度从ψ=30,n=50开始收敛,故在本实施例中ψ=30,n=50,即步骤s1.2中最终生成50个子样本集,每个子样本集中包括30个样本。
[0069]
步骤s2中具体包括以下步骤:
[0070]
s2.1、初始化树状基学习器,设置树的最大深度,本实施例中树的最大深度设置为10,并生成每颗树的根节点;
[0071]
s2.2、随机挑选一子样本集,将该子样本集中的所有样本均放入一根节点;
[0072]
s2.3、选取树中一个未访问过的节点,随机选取一种样本特征,遍历该节点中所有样本与该样本特征相关的值,作为当前节点的多个分割阈值;
[0073]
s2.4、根据每个分割阈值,分别对当前节点中的样本进行左右树划分,并分别计算划分后每个样本的样本轮廓系数;
[0074]
s2.5、分别根据每个分割阈值下每个样本的轮廓系数计算整棵树的整树轮廓系数;
[0075]
s2.6、判断是否存在分割阈值,以使划分后整树轮廓系数大于划分前整树轮廓系数,若存在,则挑选使得整树轮廓系数最大的分割阈值作为划分阈值,并按划分阈值对当前节点中的所有样本进行左右树划分,并产生两个新的节点;若不存在则不进行左右树划分,也不产生新节点;
[0076]
s2.7、重复步骤s2.3-s2.6,直至树中的所有节点均已被访问或者树的深度已达到最大深度,完成当前树的训练;
[0077]
s2.8、重复步骤s2.2-s2.7,直至所有树均训练完成;
[0078]
s2.9、对每棵树的节点个数求取平均值,以得到聚类簇数量k,本实施例中k=4。
[0079]
其中,步骤s2.4中样本轮廓系数的计算公式具体为:
[0080][0081]
其中,a(i)是样本i到其节点内其他样本的平均距离,b(i)是样本i到相邻最近一节点内所有样本的平均距离,需要说明的是当样本均位于根节点中时,类间平均距离b(i)即为0,样本轮廓系数的计算结果为-1。
[0082]
步骤s2.5中,整树轮廓系数通过对树中每个样本的轮廓系数取平均值得到。
[0083]
步骤s3具体包括以下步骤:
[0084]
s3.1、初始化相似度矩阵;
[0085]
s3.2、将任意两个样本分别放入步骤2训练好的每一颗树中;
[0086]
s3.3、通过判断两个样本在每一颗树中是否落入同一节点,以形成该两个样本之间的相似度矩阵;
[0087]
s3.4、重复步骤s3.2-s3.3,直至得到所有样本之间的相似度矩阵。
[0088]
s3.5、将所有相似度矩阵进行归一化,以得到所有样本之间的多个归一化相似度矩阵。
[0089]
其中,步骤s3.5中所述归一化相似度矩阵为通过将相似度矩阵除以树的总数n得到。
[0090]
进一步的,步骤s4中,将得到的聚类簇数量k、归一化相似度矩阵作为谱聚类模型的输入,在本实施例中k=4,即最终得到四个聚类簇。利用谱聚类学习归一化相似度矩阵中样本之间的联系,得到最终的聚类结果。在本实施例中,对每一个簇内的点以汽车价格、车辆净重、车身长度等特征为依据,绘制了箱线图如图4-6所示,通过箱线图我们可以观察到,
本方法对于车辆数据的聚类效果非常好,不论是从汽车价格、车辆净重还是车身长度这几个特征来看,簇与簇之间有明显的区分度。即本发明所提的一种基于树状基学习器的混合特征数据聚类方法达到了良好的聚类效果。
[0091]
在本发明中设计了高纬度、混合特征情况下的数据聚类方法。引入树状结构在不进行数据转换的情况下同时处理连续特征和离散特征,利用树的叶子节点可以视为一个簇的思想进行聚类操作。没有对这些数据集进行过数据归一化来统一单位,也没有对离散数据进行距离计算或者做相应的转化,仅仅只是告诉了模型哪些特征是离散特征哪些是连续特征。进一步运用集成思想提高聚类质量,进一步统计任意两个样本到达森林中每棵树同样的叶子节点的次数来计算相似度矩阵,定义了高纬度、混合特征数据之间的相似度。且对于一般的聚类算法,聚类簇的数量k的选取非常重要,而一般的聚类算法本身并不支持自动确定k的值,但本方法只需要对森林中每棵树的叶子节点个数求取平均即可得到聚类簇的数量k,实现依靠数据本身自动设置k。本发明对于工程中特征数值复杂的数据集聚类有重要应用价值。
[0092]
实施例二:
[0093]
参照图7,本实施例提供一种基于树状基学习器的混合特征数据聚类系统,包括依次相联的子样本集生成模块、树状基学习模块、相似度矩阵模块、聚类模块,聚类模块还与树状基学习模块联接;
[0094]
子样本集生成模块,用于对样本集进行随机子采样生成n个不同的子样本集;
[0095]
树状基学习模块,用于对每个子样本集进行树状基学习器的训练,并得到训练完成后的n颗树以及聚类簇数量k;
[0096]
相似度矩阵模块,用于基于训练完成后的n颗树,统计任意两个样本之间的相似度矩阵,并将所有相似度矩阵归一化,以得到多个归一化相似度矩阵;
[0097]
聚类模块,用于将聚类簇数量k以及多个归一化相似度矩阵作为谱聚类模型的输入,以得到样本集最终的聚类结果。
[0098]
需要说明的是,本实施例提供的一种基于树状基学习器的混合特征数据聚类系统,与实施例一类似,在此不多做赘述。
[0099]
以上所述的实施例仅仅是对本发明的优选实施方式进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案作出的各种变形和改进,均应落入本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1