基于深度学习的文本内容安全检测方法
1.本发明涉及文本目标检测技术领域,具体涉及一种基于深度学习的文本内容安全检测方法。
背景技术:
2.近年来随着互联网行业的高速发展,智能手机用户呈爆炸性增长,网络平台已经成为人们获取和交流信息的重要平台。互联网不仅拓宽了信息传播的广度和深度,也为大众提供了一个自由发表言论的平台。微博、微信等社交工具的出现,极大的促进了人们之间的交流。实时消息会通过这些平台传播给广大网友。人们通过社交平台将自己的观点公开到互联网上,无数的观点会形成一种舆论倾向,从而会引发一些网络暴力、侵犯隐私等极端行为。如何引导网络舆论、制止网络暴力行为、净化网络环境,是当今网络发展面临的一个重大问题。由此可见,文本内容的安全性至关重要,尤其是各式各样app中文本内容的安全性更加重要。
3.目前存在的检测文本内容的方法是关键字检测,例如微博,当一篇微博里的内容涉及一些敏感词汇时,这篇博文的内容将不会被别人看到,严重情况下此账号将会被冻结。主流的文本检测使用的是长短记忆网络lstm结构,此结构也是一种rnn,实现简单,具有长期记忆功能,主要采用门的机制,能一定程度上解决梯度消失和爆炸的问题。这种方法虽然能精确地查找出违规的内容,但是这种检测方法过于单一,如果这些敏感词汇用同音字替换或者缩写代替,这种方法将不能检测出。随着深度学习的发展,目前也出现了一些基于深度学习的文本检测,例如lstm+ctc等方法,虽然对lstm算法有所改进,但仍有改进的空间。
技术实现要素:
4.本发明的目的是为了克服背景技术中的不足之处,基于深度学习的文本内容安全检测方法,融合注意力机制,构建一个检测文本安全的方法,尤其适用于社交app。该方法将注意力机制进行改进,将attention模型跟长短记忆网络lstm结构相结合,使神经网络专注于特征子集的能力并且对输入的特征没有任何的限制。在计算能力有限的情况下,注意力机制是解决信息超载问题的主要手段的一种资源分配方式,将资源分配给更重要的任务,同时也能并行处理问题。与传统的lstm算法相比,能在减少网络参数的情况下大大提升准确率等性能。
5.本发明是通过以下技术方案实现的:一种基于深度学习的文本内容安全检测方法,该方法基于改进的lstm结构,包括以下过程:
6.s1、采用爬虫方式从各社交app上获取独立的数据集作为训练数据,原始数据均转换为文本格式的词汇;
7.s2、对原始数据进行预处理,并采用将词汇重构为数字向量的word2vec算法简化计算与存储,该算法采用自然语言处理的模型—continuous bag-of-words,根据目标单词的上下文预测该目标单词含义,以实现文本检测,从而获得标词汇在给定句子中出现的概
率,此概率为
8.p(w
twt-c
:w
t+c
)
9.对于给定的一句话w1、w2…wt
,该模型的目标函数就是最大化上式的对数似然函数:
[0010][0011]
其中,l为似然函数、t为句子中向量的索引值、t为句子长度、c为上下文大小、w
t-c
为句子中第一个向量、w
t+c
为句子中末尾向量;
[0012]wt
为要预测的目标单词条件概率由如下表达式计算:
[0013][0014][0015]
其中,n为任意一个句子的索引值、n为句子的个数、为一篇文章中句子的平均长度、j为句子的索引值;
[0016]
s3、将处理后的数据利用随机森林算法减少冗余信息,之后再利用注意力attention算法进行处理;
[0017]
s4、将s3中处理后的数据通过改进的lstm模型进行训练并保存最终权重,所述lstm模型中引入了改进版注意力机制,所述改进版注意力机制在传统注意力机制的全连接层之前添加了残差结构,以便于优化并提高准确率;
[0018]
s5、将s4中处理后的数据并行传入到两个lstm单元中进行训练,第一个lstm单元对文本内容进行分类,如果属于第一类就不进行任何处理,如果属于第二类就给发送此文本的用户发送警告信息。另一个单元是检测文本中的敏感词汇,如果检测到了敏感词汇,则删除此文本的同时给发送此文本的用户发送警告信息。
[0019]
优选地,在所述s1中,通过调用已有词库对采集不充足样本进行补充;在所述s2中,对原始数据集进行正负样本的标定,将褒义或中性的词标为正样本,贬义的词标为负样本。
[0020]
优选地,所述s3中,所述attention算法的改进结构具体为:
[0021]
a、将数据进行融合处理,转化张量tensor的维度;
[0022]
b、将a中数据进行重塑reshape处理,改变张量tensor的形状;
[0023]
c、将b中数据传入残差结构的两层3*3的卷积层,数据通过卷积操作之后再与未处理的数据进行相加;
[0024]
d、将c中数据再次进行两次特征融合处理;
[0025]
e、将d中数据进行展平flatten操作之后送入全连接层进行预测。
[0026]
优选地,所述残差结构的内部设有残差块,残差块使用跳跃连接以减少神经网络中梯度消失的问题。
[0027]
优选地,通过word2vec算法将所有的词表示成低维稠密向量,从而能在词向量空间定性衡量词与词之间的相似性,并利用word2vec的词袋模型弱化词汇排序的重要性。
[0028]
优选地,在所述attention算法结构中加入残差结构,增加学习结果对网络权重波动的敏感度,所述安全检测方法通过改变模型参数,能构建不同的社交app文本内容检测器。
[0029]
与现有技术相比,本发明具有以下有益效果:
[0030]
(1)本发明应用于社交app内容检测时,结合了当下主流两种文本检测方法,将文本内容检测和关键词检测相结合,基于二者的优点,能更好地检测出一些不良的隐讳内容,也增强了方法的鲁棒性;
[0031]
(2)在对样本进行标注时,采用随机森林算法,大大提升了样本筛选的效率;
[0032]
(3)本发明在注意力机制网络中加入了残差结构,在降低过拟合的风险同时能使网络更加专注于文本特征提取;上述方法相结合,使得模型的精度有较高地提升,为社交app提供了一种更加精准的文本检测方法。
附图说明
[0033]
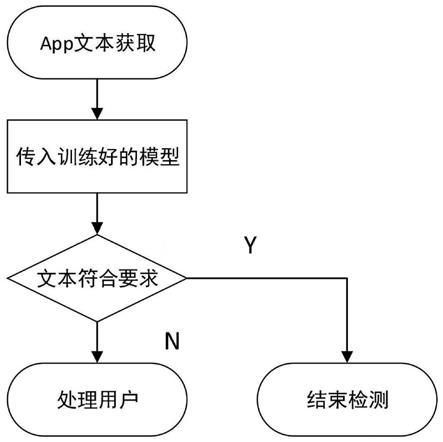
图1是本发明的使用流程图;
[0034]
图2是本发明核心算法流程图;
[0035]
图3是本发明数据获取及处理流程图;
[0036]
图4是本发明随机森林算法流程图;
[0037]
图5是本发明lstm算法流程图;
[0038]
图6是lstm内部结构图;
[0039]
图7是本发明改进的注意力机制流程图。
具体实施方式
[0040]
下面将结合本发明实施例中图,对本发明实施例中的技术方案进行清楚、完整地描述。通常在此处图中描述和展示出的本发明实施例的组件能以各种不同的配置来布置和设计。因此,以下对在图中提供的本发明实施例的详细描述并非旨在限制本发明要求保护的范围,而是仅仅表示本发明的选定实施例。基于本发明的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的其他所有实施例,都属于本发明保护的范围。
[0041]
一种针对社交app的基于深度学习的文本内容安全检测方法,如图1~图7所示,主要包括算法部分。算法部分主要指的是对数据的采集和处理以及按要求训练的部分。训练好的模型用来检测社交app文本内容。本发明采用获取独立的数据集,这样能训练出更加精准有效的模型。数据集能采用爬虫的方式从各大社交app上获取,获取成功后还需将数据集贴上正负样本的标签用于训练。由于数据集是文本格式,不同于图像可用数字表示,因此要将文本转化成数字格式。这里采用word2vec算法来进行转化。
[0042]
word2vec算法用以将词汇重构为数字向量。该模型为浅而双层的神经网络,用来训练以重新构建语言学之词文本。网络以词来表现,并需要猜测相邻词位置的输入词,在word2vec中词袋模型假设下,词的顺序是不重要的。训练完成之后,word2vec可用来映射每一个词到一个向量,可用来表示词对词之间的关系,该向量为神经网络之隐藏层。
[0043]
数据集通过word2vec处理之后,为了减少冗余信息,本发明优化了随机森林算法,这样能更好的优化随机森林算法。随机森林算法是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
[0044]
接着,经过处理的处理后的数据需要通过以长短记忆网络lstm为核心的模型进行训练。在此模型中,本发明对注意力attention机制有所修改,能使模型更有效的保存重要的信息。经过注意力机制处理后,数据将并行地传入到两个lstm单元中进行训练,其中一个单元是对文本内容进行分类,如果属于第一类就不进行任何处理,如果属于第二类就给发送此文本的用户发送警告信息。另一个单元是检测文本中的敏感词汇,如果检测到了敏感词汇,则删除此文本并给发送此文本的用户发送警告信息。
[0045]
图1所示是本发明的使用流程图。该图清晰地展示了本发明的使用流程。先利用爬虫技术获取社交app的文本内容,之后将这些内容送入到训练好的模型进行检测,如果检测出违规内容,则将对应的给予警告等处理。
[0046]
图2所示是发明核心算法流程图。结合图1,其核心内容如下:
[0047]
s1、获取训练数据,采用爬虫方式从各社交app上获取独立的数据集作为训练数据,原始数据为词汇,如果所采集的样本不充足,可用现有的词库进行补充;
[0048]
s2、对原始数据进行处理,并采用word2vec算法将词汇转换成数字向量,方便计算机存储和计算;
[0049]
s3、将处理后的数据利用随机森林算法减少冗余信息,之后再利用attention算法进行处理;
[0050]
图3是本发明数据获取及处理流程图,首先要利用爬虫技术获取信息,接下来传入word2vec模型进行转化,转化完成之后输入到随机森林进行下一步处理;
[0051]
s4、将s3中处理后的数据通过改进的lstm模型进行训练并保存最终权重,lstm模型中引入了改进版注意力机制,改进版注意力机制在传统注意力机制的全连接层之前添加了残差结构,以便于优化并提高准确率;
[0052]
s5、将s4中处理后的数据并行传入到两个lstm单元中进行训练,第一个lstm单元对文本内容进行分类,如果属于第一类就不进行任何处理,如果属于第二类就给发送此文本的用户发送警告信息。本实施例中文本中正值代表褒义或中性的词,负值代表贬义的词,因此本实施例中的第一类和第二类文本内容以相应的文本总值来进行分类。另一个单元是检测文本中的敏感词汇,如果检测到了敏感词汇,则删除此文本的同时给发送此文本的用户发送警告信息。
[0053]
本发明应用于社交app内容检测时,结合了当下主流两种文本检测方法,将文本内容检测和关键词检测相结合,基于二者的优点,能更好地检测出一些不良的隐讳内容,也增强了方法的鲁棒性;本发明还在注意力机制网络中加入了残差结构,在降低过拟合的风险同时能使网络更加专注于文本特征提取;上述方法相结合,使得模型的精度有较高地提升。
[0054]
word2vec是google在2013年提出的自然语言处理模型,它的特点是将所有的词表示成低维稠密向量,从而能在词向量空间定性衡量词与词之间的相似性。相似的词在向量空间上的夹角会越小。本发明采用的模型为continuous bag-of-words。cbow根据目标单词的上下文预测该目标单词含义,以实现文本检测的目的,给定目标单词的上下文预测该目标单词是什么,能用条件概率来建模这个问题,我们的模型是求一个单词在给定句子中出
现的概率,此概率为:
[0055]
p(w
t
|w
t-c
:w
t+c
)
ꢀꢀ⑴
[0056]
对于给定的一句话w1,w2…wt
,该模型的目标函数就是最大化上式的对数似然函数:
[0057][0058]
其中,l为似然函数、t为句子中向量的索引值、t为句子长度、c为上下文大小、w
t-c
为句子中第一个向量、w
t+c
为句子中末尾向量;
[0059]wt
为要预测的目标单词条件概率由softmax给出:
[0060][0061][0062]
其中,n为任意一个句子的索引值、n为句子的个数、为一篇文章中句子的平均长度、j为句子的索引值。
[0063]
图4是本发明中随机森林算法流程图,随机森林是一个包含多个决策树的分类器。如图所示将处理过的样本有放回地抽样后分成两个簇,输入到两颗决策树中,最终得到结果。
[0064]
图5~图6是本发明lstm算法流程图。经上述步骤处理后,数据要经过attention结构处理,接着再输入到lstm层,最后进行展平输入全连接层进行最后的预测。
[0065]
rnn的主线是一条顶部水平贯穿的线,也就是我们所称的长期记忆c线,即细胞状态,它达到了序列学习的目的。而lstm也是以这一条顶部水平贯穿的c线为主线,在每个时间点,都会有一个对应的状态。这个状态记录了之前的信息。在每个时间点,都能通过调节权重的输入,遗忘等方式去修正该状态。lstm主要特点是,通过遗忘门,输入门,输出门对于状态c的影响,最终决定每一个时间点,要忘记多少,记住多少,输出多少,最后把这个状态一直传递下去,从而达到能控制其不会忘记遥远的重要信息,也不会把附近的不重要的信息看的太重的作用。
[0066]
图7是本发明改进的注意力机制流程图。注意力机制是在计算能力有限的情况下,将计算资源分配给更重要的任务。在神经网络学习中,一边而言模型的参数越多则模型的表达能力越强,模型所存储的信息量也越大,但这会带来信息过载的问题,通过引入注意力机制,在众多的输入信息中聚焦于当前任务更为关键的信息,降低对其他信息的关注度,甚至过滤掉无关信息,就能解决信息过载问题,并提高任务处理准确性。对于文本识别来说,给定一篇较为长篇幅的文本,如果要检测部分内容,那只需要把相关的片段挑出来让神经网络进行处理,而不需要把所有内容都输入到网络中。
[0067]
attention机制的基本思想是,打破了传统编码器-解码器结构在编解码时都依赖于内部一个固定长度向量的限制。attention机制的实现是通过保留lstm编码器对输入序
列的中间输出结果,然后训练一个模型对这些输入进行选择性的学习并且在模型输出时将输出序列与之进行关联。
[0068]
如果用键值对来表示输入信息,那么注意力机制就能看成是一种软寻址操作:把输入信息x看做是存储器中存储的内容,元素由地址key(键)和值value组成,当前有个key=query的查询,目标是取出存储器中对应的value值,即attention值。而在软寻址中,并非需要硬性满足key=query的条件来取出存储信息,而是通过计算query与存储器内元素的地址key的相似度来决定,从对应的元素value中取出多少内容。每个地址key对应的value值都会被抽取内容出来,然后求和,这就相当于由query与key的相似性来计算每个value值的权重,然后对value值进行加权求和。加权求和得到最终的value值,也就是attention值。
[0069]
以上的计算可归纳成三个过程:
[0070]
1.根据query和key计算二者的相似度。能用上面所列出的加性模型、点积模型或余弦相似度来计算,得到注意力得分si:
[0071]
si=f(q,ki)
ꢀꢀ⑸
[0072]
2.用softmax函数对注意力得分进行数值转换。一方面能进行归一化,得到所有权重系数之和为1的概率分布,另一方面能用softmax函数的特性突出重要元素的权重:
[0073][0074]
3.根据权重系数对value进行加权求和:
[0075][0076]
si表示注意力得分、αi表示重要元素权重、attention表示最终结果。
[0077]
改进后的attention的结构具体为:
[0078]
a、将数据进行permute处理,转化tensor的维度;
[0079]
b、将a中数据进行reshape处理,改变tensor形状;
[0080]
c、将b中数据传入残差结构的两层3*3的卷积层,数据通过卷积操作之后再与未处理的数据进行相加;
[0081]
d、将c中数据再次进行permute和merge处理;
[0082]
e、将d中数据进行flatten展平操作之后送入全连接层进行预测。
[0083]
摘取了一些关键词检测,得分标准是以0为分界线,正值代表褒义或中性的词,负值代表贬义的词,分数绝对值越高,词汇所代表的情绪就越强烈。所采用的文本为“抑郁来临的时候不是感受不到快乐,而是那快乐轻的像一阵风,倏地一下,路过了一个烈火焚心的人,无济于事。你会突然丧失对于世界的所以兴趣,你想要的,你喜爱的,你追逐的
……
都不再能激发起你任何的渴望。你依然有喜怒哀乐,却丧失了强烈的欲望,像一具尸体彻底地僵死在原地,灵魂还来不及消失,身体却无法动弹。”表1是本发明的实验结果图。
[0084]
表1检测得分表
[0085]
关键词语得分抑郁-2感受不到快乐-1丧失兴趣-1
僵死-4
[0086]
从上述结果能看成,本发明检测词语的褒贬词性得分较为准确。
[0087]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明能有而各种更改。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。因注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1