一种基于决策树的学习成绩预测及个性化干预的方法
1.本发明属于智慧教育技术领域,涉及一种基于决策树的学习成绩预测及个性化干预的方法。
背景技术:
2.在在线教育平台中,一个学习者的学习行为会被系统进行详细的记录,研究者收集这些数据,再通过教育大数据对这些数据进行分析,获得学习者的特征,以便提供个性化的推送。其中,学习者与学习成绩之间有许多制约因素,但目前大多数对在线教育中学习成绩预测的研究仅仅考虑了学习者的行为特征,并未考虑学习者的学术背景特征、家庭特征以及学习者的状态变化特征等基本信息,而且筛选的学习者的行为特征也很局限和单一,并将其作为测试指标时,数据类型和样本的数量都十分有限。同时,当预测到影响学习成绩的行为特征并进行干预时,并未根据学习者的个体差异,给出个性化的干预方案。
技术实现要素:
3.本发明的目的是提供一种基于决策树的学习成绩预测及个性化干预的方法,解决了现有技术中存在的对学习者学习成绩预测时仅仅考虑了学习者的行为特征且预测到影响学习成绩的行为特征并进行干预时,并未根据学习者的个体差异给出个性化的干预方案的问题。
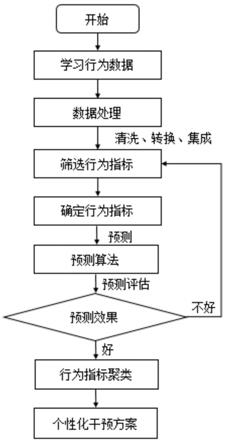
4.本发明所采用的技术方案是,一种基于决策树的学习成绩预测及个性化干预的方法,具体按照如下步骤实施:
5.步骤1,采集学习者的学习行为数据,包括静态数据和动态数据,静态数据包括一大类:学习者的基本信息数据,动态数据包括四大类:学习者在自适应平台的界面交互数据、内容交互数据、测试数据、状态变化数据;
6.步骤2,对步骤1采集的学习行为数据进行处理;
7.步骤3,对经过步骤2处理的学习行为数据中动态数据的进行量化;
8.步骤4,分别选取经步骤2处理的静态数据和经步骤3量化的动态数据中的一部分作为训练集数据,计算训练集中数据之间的相关性,根据相关性确定作为学习成绩预测指标的学习行为变量;
9.步骤5,将训练集中经步骤4确定作为学习成绩预测指标的学习行为对应的训练数据保留,提出其他训练数据得到更新后的训练集,应用决策树算法使用更新后的训练集进行学习成绩预测;
10.步骤6,按照步骤4
‑
5的步骤分别选取经步骤2处理的静态数据和经步骤3量化的动态数据中的一部分作为测试集数据,生成最终的决策树预测模型去预测学习成绩结果;
11.步骤7,通过精确率、准确率和召回率对预测结果进行判断,当精确率、准确率和召回率任意一个不小于90%时,将对应的学习行为指标可以被作为影响学习者成绩的学习行为指标;
12.步骤8,根据步骤7确定的行为指标,进行k
‑
means聚类,确定学习群体;
13.步骤9,根据步骤8确定的具有相同学习行为的不同学习者群体,对于每一类学习者群体提供不同的学习方案。
14.本发明的特征还在于,
15.步骤1中的基本信息数据包括以下小类:户籍所在地、户籍类型、家庭情况、父母受教育程度、是否为寄宿生、是否为留守儿童;
16.步骤1中的学习者在自适应平台的界面交互数据包括以下小类:查看测试结果、浏览资料、浏览公告、帖子的浏览、课程信息的浏览、知识点掌握程度的浏览和点赞量;
17.步骤1中的学习者在自适应平台的内容交互数据包括以下小类:课件下载量、视频下载量、观看视频次数、试卷下载次数、发帖量、回帖量、在线答题次数、提交作业数次数、参与测试评论量和被评论量;
18.步骤1中学习者在自适应平台的测试数据包括以下小类:测试成绩、测试难度、知识点掌握程度、正确率、每道题答题时长、测试消耗时长和测试类型;
19.步骤1中学习者在自适应平台的状态变化数据包括以下小类:登录次数、系统登录时长、累计在线时长、在线时间间隔、离开平台的时长、离开平台的次数和登录时间离线时间。
20.步骤2具体为:
21.步骤2.1,数据清洗:对步骤1采集的数据根据每个变量的合理取值范围和相互关系,检查所拿到的学习者数据是否合乎要求,如果发现超出正常范围、逻辑上不合理或者相互矛盾的数据,对其进行核对和纠正;如果学习者的某些行为数据是无效值和缺失值;
22.其中,若某些学习行为数据与现实情况不符则认为为无效值;
23.若某些学习者的学习行为数据不完整,即就是不完全包括所有学习行为的各个类别,则认为将对应学习者的其他包括的学习行为数据视为缺失值,将其删除;
24.步骤2.2,将清洗的数据整合在一起;
25.步骤2.3,将进行整合的学习行为数据转换成字符串类型,其中,转换后的浮点型字符串保留两位小数。
26.步骤3具体为:
27.步骤3.1,学习者在自适应平台的界面交互数据的量化:
28.测试结果和点赞量直接在自适应平台上根据学习者查看测试结果以及点赞的点击次数来进行累加获得;
29.浏览资料、浏览公告、帖子的浏览、课程信息的浏览、知识点掌握程度的浏览按照学习者对对应资源的浏览时长来进行统计的,学习者每次开始浏览到浏览结束的这段时间即为学习者本次的浏览时长,而总的浏览时长即为每次的浏览时长累加得到,具体如下:
30.学习者对对应资源的浏览时长按照如下公式计算:
[0031][0032]
其中,s
scan
表示学习者浏览某资源的浏览时长,t
leave
和t
enter
表示学习者浏览某个资源的离开时间和进入时间,t表示一个学习者访问该资源的次数;
[0033]
步骤3.2,学习者在自适应平台的内容交互数据的量化:
[0034]
根据学习在自适应平台的学习记录直接对对应的行为进行累加求和获取课件下载量、视频下载量、观看视频次数、试卷下载次数、发帖量、回帖量、在线答题次数、提交作业数次数、参与测试评论量和被评论量;
[0035]
步骤3.3,学习者在自适应平台的测试数据的量化
[0036]
正确率是指在一次阶段测试中答对题目所占比例,定义一套试卷的题目集合为:q={q1,q2,q3,
…
,q
m
},做错题目的集合为:e={e1,e2,e3,
…
,e
k
},,则正确率可表示为:
[0037][0038]
其中,t
correct
表示正确率,和表示题目总数和做错的题目数;
[0039]
学习者的知识点掌握程度为:
[0040]
在对应的知识点下分别选取简单、中等、难题分别x个,其中,简单题的难度值范围为:0
‑
0.3,中等题的难度值范围为:0.4
‑
0.7,难题的难度值范围为:0.8
‑
1.0,则该知识点的掌握程度w按照如下公式计算:
[0041][0042]
其中,b、n、h分别表示简单题、中等题和难题的难度总值,表示答对简单题的难度值之和,表示答对中等题的难度值之和,表示答对难题的难度值之和;
[0043]
测试难度由一套试卷中每个题目的难度累加求均值获得的,一套试卷单个题目的难度可定义为:f={f1,f2,f3,
…
,f
m
},则难度可表示为:
[0044][0045]
其中,f
difficult
表示测试难度,表示该测试卷所有题目的难度值之和,m表示该次测试试卷的题目总数,e为学习者的优秀指数;
[0046]
其中,
[0047]
其中,a为学习者学习知识点的个数,p
i
为学习者对知识点p的掌握程度,根据公式(3)计算得到;
[0048]
测试成绩根据该次测试学习每道题目的分数累加计算得到;
[0049]
测试类型在自适应平台中直接获取,测试类型包括学前测试和学情测试两种类型,其中学前测试用0表示,学情测试用1表示;
[0050]
每道题答题时长指学习者在点击进入该题目到点击进入下一题的时间间隔,在自适应平台中直接获取;
[0051]
测试消耗时长指一套试卷的消耗时长,表示为其中,t
i
为第i个题目答题时长,m为该次测试试卷的题目总数;
[0052]
步骤3.4,学习者在自适应平台的状态变化数据的量化
[0053]
登录次数、系统登录时长、累计在线时长、在线时间间隔、离开平台的时长、离开平台的次数和登录时间、离线时间根据学习者在平台的访问频数累加求得。
[0054]
步骤4具体为:
[0055]
步骤4.1,分别选取经步骤2处理的静态数据的80%和经步骤3量化的动态数据的80%放入训练集,作为训练数据;
[0056]
步骤4.2,计算训练集中任意两个训练数据皮尔森相关系数r,若训练数据为对应的静态数据,则训练数据为经步骤2转换后的字符串值,若训练数据对应动态数据,则训练数据为经步骤3量化后的值,具体按照如下公式计算:
[0057][0058]
其中,g为训练集中训练数据的总数,z
i
为训练集中某类学习行为对应的一个训练数据,为训练集中某类学习行为对应的所有训练数据的均值,y
i
为训练集中不同于z
i
的某类学习行为对应的某个训练数据,为训练集不同于z
i
的某类学习行为对应的所有训练数据的均值;
[0059]
步骤4.3,若计算的r>0或者r<0,则z
i
和y
i
对应的学习行为均作为学习成绩预测指标的学习行为变量。
[0060]
步骤5中应用决策树算法使用更新后的训练集进行学习成绩预测具体按照如下步骤实施:
[0061]
步骤5.1,定义更新后的训练集为:d={(x1,y1),(x2,y2),...,(x
n
,y
n
)},其中,x
i
={x
i(1)
,x
i(2)
,...,x
i(n)
}
t
为输入的特征向量,将经步骤4筛选出的学习行为对应的小类作为一个特征,则x
i
中即就是某个学习行为的小类对应的所有值,n为对应的学习行为的小类对应的值的数量,y
i
∈{1,2,...,k}为小类标记;
[0062]
步骤5.2,计算训练集中任意一个特征a对训练集d的信息增益比gr(d,a)按照如下公式计算:
[0063][0064]
其中,g(d,a)为信息增益,具体按照如下公式计算:
[0065]
g(d,a)=h(d)
‑
h(d|a)
ꢀꢀ
(9)
[0066][0067]
其中,c
k
表示第k个小类,|c
k
|为属于第k个小类c
k
的样本数据量,其中|d|为训练集的样本容量;
[0068]
[0069]
其中,d
i
的划分是根据特征a的每个取值将训练集d分为n个子集d1,d2,...,d
n
,由于d
i
是从训练集中分出来的子集,即d
i
={(x
j
,y
j
),(x
j+1
,y
j+1
),...,(x
n
,y
n
)},j表示第i训练集开始的位置,d
i
具体的划分是在生成决策树的过程中特征a的每个取值与阈值ε的大小关系进行划分数据集的,其中,n为特征a对应的取值数量,|d
i
|为d
i
的样本个数;在计算h(d|a)时,公式中的h(d
i
)是用公式(7)计算的,只需要将d替换为d
i
即可,此时,c
k
表示数据集d
i
中的第k个小类,|c
k
|为属于第k个小类c
k
的样本数据量;
[0070]
步骤5.3,依据步骤5.2计算每个小类特征的信息增益比,然后按照信息增益比从大到小将每个小类特征进行排序依次,选择信息增益比最大的特征a
g
作为开始节点;
[0071]
步骤5.4,若特征a
g
的信息增益比小于其对应小类的阈值ε,则将决策树t归为单结点树,并将训练集d中样本数据最大的小类c
k
作为特征a
g
的类,返回决策树t;
[0072]
若特征a
g
的信息增益比大于等于其对应小类的阈值ε,则根据特征a
g
的每个取值将训练集d划分为n个子集d1,d2,...,d
n
,将d
i
中样本数据最大的小类作为开始节点的类,构建开始节点的子节点,则由开始结点及其子结点构成决策树t,并返回决策树t;
[0073]
步骤5.5,以d
i
为训练集,选择除了a
g
以外的信息增益比最大的特征作为新的类,将其视为a
g
,然后按照步骤5.4的方法执行;不断循环直到所有的特征全部分类完成,返回决策树t,预测结束,将学习成绩的合格或不合格作为最终预测结果。
[0074]
步骤6具体为:
[0075]
将经步骤4.1选取之后剩余的静态数据的20%和动态数据的20%放入测试集,作为测试数据,按照步骤4.2
‑
步骤5.6的方式对测试集数据进行操作,生成最终的决策树预测模型去预测学习成绩结果。
[0076]
步骤7具体为:
[0077]
步骤7.1,确定混淆矩阵;
[0078]
混淆矩阵中包括真实类别和预测类别以及真实类别和预测类别的比较结果,真实类别是学习者在自适应平台中真实的学习成绩的及格情况,预测类别是指通过测试集和决策树预测得到的学习成绩的及格情况,真实类别和预测类别的比较结果包括:
[0079]
若真实类别为及格且预测类别为及格则表示被正确地划分为正例,计被正确地划分为正例的个数为tp;
[0080]
若真实类别为及格且预测类别为不及格则表示被错误地划分为负例,计被错误地划分为负例的个数为fn;
[0081]
若真实类别为不及格且预测类别为及格则表示被错误地划分为正例,计被错误地划分为正例的个数fp;
[0082]
若真实类别为不及格且预测类别为不及格则表示被正确地划分为负例,及被正确地划分为负例的个数为tn;
[0083]
用p指真实类别中及格总数;n指真实类别中不及格的总数;p1指预测类别中及格总数,n1指预测类别中不及格总数;
[0084]
步骤7.2,根据步骤7.1得到的混淆矩阵,计算预测的精确率、准确率和召回率,具体为:
[0085]
精确率precision:
[0086][0087]
准确率accuracy:
[0088][0089]
召回率recall:
[0090][0091]
当精确率、准确率和召回率任意一个不小于90%时,认为该学习行为指标可以被作为影响学习者成绩的指标。
[0092]
步骤8具体为:
[0093]
步骤8.1,根据步骤7确定的影响学习者学习成绩的学习行为指标的个数k,确定得到k个聚类群体,给每个聚类群体选择一个中心点,即就是在每个群里中所选的随机数,即就是聚类中心,对每类学习行为指标对应的数据集中数据的平均值以及该学习行为指标对应的数据集中的每个学习者的数据通过欧式公式计算该数据到每一个聚类中心的距离,数据集为训练集和测试集的总和,如果距离u<0.5则将该学习者归类到本类的聚类群体中;
[0094]
欧式公式具体如下:
[0095][0096]
其中,h表示数据集中的数据,l表示所选择的聚类中心;
[0097]
步骤8.2,根据步骤8.1对所有学习者进行按照学习行为指标进行归类,得到k个学习者群体。
[0098]
步骤9具体为:
[0099]
根据步骤8获得的k类学习者群体,按照步骤8的聚类方法将学习者聚类到对应的学习者群体中,自适应平台中根据聚类的学习者群体推荐平台的相关资源、合适的题目以及推荐当前学的知识点和接下来需要学习的知识点;资源包括有视频、音频、图片、文档、ppt以及教案。
[0100]
本发明的有益效果是
[0101]
(1)本发明有效的利用了学习者在自适应平台的学习行为数据和学习者的基本信息数据,其中学习者的基本信息数据包括:户籍所在地以及户籍类型、家庭情况、父母受教育程度、是否为寄宿生、是否为留守儿童等基本信息,学习行为数据包括:界面交互数据、内容交互数据、测试数据、状态变化数据,从多个角度考虑了可能影响学习成绩的因素,通过皮尔森相关系数进行相关性分析,筛选出可能影响学习成绩的学习行为,并进行标记,为学习成绩预测提供了基础,针对学习成绩预测的结果,通过k
‑
means聚类算法,得到学习者群体,再结合每个学习者的学习风格和学习偏好,为学习者提供个性化的干预方案。学习者不仅可以通过预测结果了解到自身薄弱环节以及不良的学习行为,还可以获得适合自身学习风格的个性化干预方案,从而提高学习者的学习效率和学习成绩。
附图说明
[0102]
图1是本发明一种基于决策树的学习成绩预测及个性化干预的方法的流程图;
[0103]
图2是本发明一种基于决策树的学习成绩预测及个性化干预的方法的实施框图。
具体实施方式
[0104]
下面结合附图和具体实施方式对本发明进行详细说明。
[0105]
本发明一种基于决策树的学习成绩预测及个性化干预的方法,如图1
‑
2所示,具体按照如下步骤实施:
[0106]
步骤1,采集学习者的学习行为数据,包括静态数据和动态数据,静态数据包括一大类:学习者的基本信息数据,动态数据包括四大类:学习者在自适应平台的界面交互数据、内容交互数据、测试数据、状态变化数据;
[0107]
基本信息数据包括以下小类:户籍所在地、户籍类型、家庭情况、父母受教育程度、是否为寄宿生、是否为留守儿童;
[0108]
学习者在自适应平台的界面交互数据包括以下小类:查看测试结果、浏览资料、浏览公告、帖子的浏览、课程信息的浏览、知识点掌握程度的浏览和点赞量;
[0109]
学习者在自适应平台的内容交互数据包括以下小类:课件下载量、视频下载量、观看视频次数、试卷下载次数、发帖量、回帖量、在线答题次数、提交作业数次数、参与测试评论量和被评论量;
[0110]
步骤1中学习者在自适应平台的测试数据包括以下小类:测试成绩、测试难度、知识点掌握程度、正确率、每道题答题时长、测试消耗时长和测试类型;
[0111]
学习者在自适应平台的状态变化数据包括以下小类:登录次数、系统登录时长、累计在线时长、在线时间间隔、离开平台的时长、离开平台的次数和登录时间离线时间;
[0112]
步骤2,对步骤1采集的学习行为数据进行处理,具体为:
[0113]
步骤2.1,数据清洗:对步骤1采集的数据根据每个变量的合理取值范围和相互关系,检查所拿到的学习者数据是否合乎要求,如果发现超出正常范围、逻辑上不合理或者相互矛盾的数据,对其进行核对和纠正;如果学习者的某些行为数据是无效值和缺失值;
[0114]
其中,若某些学习行为数据与现实情况不符则认为为无效值,例如学习者在该平台的所有浏览时长不可以为负值,如果已有数据中存在这样的值,视其为无效值,将其删除;
[0115]
若某些学习者的学习行为数据不完整,即就是不完全包括所有学习行为的各个类别,则认为将对应学习者的其他包括的学习行为数据视为缺失值,将其删除,例如:一个学习者的所有学习行为数据中,只显示了该学习者的界面交互数据,将这样的数据视为缺失值,将其删除;
[0116]
步骤2.2,将清洗的数据整合在一起;在对数据进行清洗后,需要处理后的数据整合在一起,方便在后期数据分析时使用;
[0117]
步骤2.3,将进行整合的学习行为数据转换成字符串类型,其中,转换后的浮点型字符串保留两位小数,在自适应平台中,学习者的所有数据都是以符合数据库要求的类型和方式存储在数据库中,而这种方式只是将学习者的数据进行了保存,起到一个收集数据的作用,本发明是要根据这些数据做具体的数据分析,所以这样数据不符合后期的数据分析,因此需要对学习者的学习行为数据进行类型转换,将文本类型转换为字符串类型,整型不需要变化,浮点型保留两位小数;
[0118]
步骤3,对经过步骤2处理的学习行为数据中动态数据的进行量化;具体为:
[0119]
步骤3.1,学习者在自适应平台的界面交互数据的量化:
[0120]
测试结果和点赞量直接在自适应平台上根据学习者查看测试结果以及点赞的点击次数来进行累加获得;
[0121]
浏览资料、浏览公告、帖子的浏览、课程信息的浏览、知识点掌握程度的浏览按照学习者对对应资源的浏览时长来进行统计的,学习者每次开始浏览到浏览结束的这段时间即为学习者本次的浏览时长,而总的浏览时长即为每次的浏览时长累加得到,具体如下:
[0122]
学习者对对应资源的浏览时长按照如下公式计算:
[0123][0124]
其中,s
scan
表示学习者浏览某资源的浏览时长,t
leave
和t
enter
表示学习者浏览某个资源的离开时间和进入时间,t表示一个学习者访问该资源的次数;
[0125]
步骤3.2,学习者在自适应平台的内容交互数据的量化:
[0126]
根据学习在自适应平台的学习记录直接对对应的行为进行累加求和获取课件下载量、视频下载量、观看视频次数、试卷下载次数、发帖量、回帖量、在线答题次数、提交作业数次数、参与测试评论量和被评论量;
[0127]
步骤3.3,学习者在自适应平台的测试数据的量化
[0128]
正确率是指在一次阶段测试中答对题目所占比例,定义一套试卷的题目集合为:q={q1,q2,q3,
…
,q
m
},做错题目的集合为:e={e1,e2,e3,
…
,e
k
},,则正确率可表示为:
[0129][0130]
其中,t
correct
表示正确率,和表示题目总数和做错的题目数;
[0131]
学习者的知识点掌握程度为:
[0132]
在对应的知识点下分别选取简单、中等、难题分别x个,其中,简单题的难度值范围为:0
‑
0.3,中等题的难度值范围为:0.4
‑
0.7,难题的难度值范围为:0.8
‑
1.0,则该知识点的掌握程度w按照如下公式计算:
[0133][0134]
其中,b、n、h分别表示简单题、中等题和难题的难度总值,表示答对简单题的难度值之和,表示答对中等题的难度值之和,表示答对难题的难度值之和;
[0135]
测试难度由一套试卷中每个题目的难度累加求均值获得的,一套试卷单个题目的难度可定义为:f={f1,f2,f3,
…
,f
m
},则难度可表示为:
[0136]
[0137]
其中,f
difficult
表示测试难度,表示该测试卷所有题目的难度值之和,m表示该次测试试卷的题目总数,e为学习者的优秀指数;
[0138]
其中,
[0139]
其中,a为学习者学习知识点的个数,p
i
为学习者对知识点p的掌握程度,根据公式(3)计算得到;
[0140]
测试成绩根据该次测试学习每道题目的分数累加计算得到;
[0141]
测试类型在自适应平台中直接获取,测试类型包括学前测试和学情测试两种类型,其中学前测试用0表示,学情测试用1表示;
[0142]
每道题答题时长指学习者在点击进入该题目到点击进入下一题的时间间隔,在自适应平台中直接获取;
[0143]
测试消耗时长指一套试卷的消耗时长,表示为其中,t
i
为第i个题目答题时长,m为该次测试试卷的题目总数;
[0144]
步骤3.4,学习者在自适应平台的状态变化数据的量化
[0145]
登录次数、系统登录时长、累计在线时长、在线时间间隔、离开平台的时长、离开平台的次数和登录时间、离线时间根据学习者在平台的访问频数累加求得;
[0146]
步骤4,分别选取经步骤2处理的静态数据和经步骤3量化的动态数据中的一部分作为训练集数据,计算训练集中数据之间的相关性,根据相关性确定作为学习成绩预测指标的学习行为变量;具体为:
[0147]
步骤4.1,分别选取经步骤2处理的静态数据的80%和经步骤3量化的动态数据的80%放入训练集,作为训练数据;
[0148]
步骤4.2,计算训练集中任意两个训练数据皮尔森相关系数r,若训练数据为对应的静态数据,则训练数据为经步骤2转换后的字符串值,若训练数据对应动态数据,则训练数据为经步骤3量化后的值,具体按照如下公式计算:
[0149][0150]
其中,g为训练集中训练数据的总数,z
i
为训练集中某类学习行为对应的一个训练数据,为训练集中某类学习行为对应的所有训练数据的均值,y
i
为训练集中不同于z
i
的某类学习行为对应的某个训练数据,为训练集不同于z
i
的某类学习行为对应的所有训练数据的均值;
[0151]
步骤4.3,若计算的r>0或者r<0,则z
i
和y
i
对应的学习行为均作为学习成绩预测指标的学习行为变量;
[0152]
(1)若r>0,则说明数据集和训练集中的z
i
和y
i
之间是正相关,即变量z
i
的值越大则变量y
i
的值越大,那么像这种关系的变量说明学习者在日常学习过程中会因为其中一个表现的比较差而导致另一个出现差的结果,这种数据变量z
i
和y
i
对应的学习行为是需要作为学习成绩预测的指标进行筛选出来的。
[0153]
(2)若r<0,则说明数据集和训练集中的z
i
和y
i
之间是负相关,即变量z
i
的值越大则变量y
i
的值越小,像这种关系的变量说明学习者在日常学习过程中会因为其中一个表现的比较的突出反而导致另一个出现差的结果,这种数据变量z
i
和y
i
对应的学习行为是需要作为学习成绩预测的指标进行筛选出来的。
[0154]
(3)若r=0,则说明数据集和训练集中的z
i
和y
i
之间不是线性相关的,即行为变量z
i
的值越大则行为变量y
i
之间可能存在其他关系,在进行学习成绩预测的过程中可以忽略这些指标。
[0155]
步骤5,将训练集中经步骤4确定作为学习成绩预测指标的学习行为对应的训练数据保留,提出其他训练数据得到更新后的训练集,应用决策树算法使用更新后的训练集进行学习成绩预测;
[0156]
决策树通常是一个递归地选择最优特征并根据该特征对训练数据进行分割,使得对各个子数据集有一个最好的分类的过程。这一过程对应着对特征空间的划分,也对应着决策树的构建。开始,构建根结点,将所有训练数据都放在根结点。选择一个最优特征,按照这一特征将训练数据集分割成子集,使得各个子集有一个在当前条件下最好的分类。如果这些子集已经能够被基本正确分类,那么构建叶结点,并将这些子集分到所对应的叶结点中去:如果还有子集不能被基本正确分类,那么就对这些子集选择新的最优特征,继续对其进行分割,构建相应的结点。如此递归地进行下去,直至所有训练数据子集被基本正确分类,或者没有合适的特征为止。最后每个子集都被分到叶结点上,即都有了明确的类。
[0157]
其中,应用决策树算法使用更新后的训练集进行学习成绩预测具体按照如下步骤实施:
[0158]
步骤5.1,定义更新后的训练集为:d={(x1,y1),(x2,y2),...,(x
n
,y
n
)},其中,x
i
={x
i(1)
,x
i(2)
,...,x
i(n)
}
t
为输入的特征向量,将经步骤4筛选出的学习行为对应的小类作为一个特征,则x
i
中即就是某个学习行为的小类对应的所有值,n为对应的学习行为的小类对应的值的数量,y
i
∈{1,2,...,k}为小类标记;
[0159]
步骤5.2,计算训练集中任意一个特征a对训练集d的信息增益比gr(d,a)按照如下公式计算:
[0160][0161]
其中,g(d,a)为信息增益,具体按照如下公式计算:
[0162]
g(d,a)=h(d)
‑
h(d|a)
ꢀꢀ
(9)
[0163][0164]
其中,c
k
表示第k个小类,|c
k
|为属于第k个小类c
k
的样本数据量,其中|d|为训练集的样本容量;
[0165][0166]
其中,d
i
的划分是根据特征a的每个取值将训练集d分为n个子集d1,d2,...,d
n
,由于d
i
是从训练集中分出来的子集,即d
i
={(x
j
,y
j
),(x
j+1
,y
j+1
),...,(x
n
,y
n
)},j表示第i训练集开始的位置,d
i
具体的划分是在生成决策树的过程中特征a的每个取值与阈值ε的大小关
系进行划分数据集的,其中,n为特征a对应的取值数量,|d
i
|为d
i
的样本个数;在计算h(d|a)时,公式中的h(d
i
)是用公式(7)计算的,只需要将d替换为d
i
即可,此时,c
k
表示数据集d
i
中的第k个小类,|c
k
|为属于第k个小类c
k
的样本数据量;
[0167]
步骤5.3,依据步骤5.2计算每个小类特征的信息增益比,然后按照信息增益比从大到小将每个小类特征进行排序依次,选择信息增益比最大的特征a
g
作为开始节点;
[0168]
步骤5.4,若特征a
g
的信息增益比小于其对应小类的阈值ε,则将决策树t归为单结点树,并将训练集d中样本数据最大的小类c
k
作为特征a
g
的类,返回决策树t;
[0169]
若特征a
g
的信息增益比大于等于其对应小类的阈值ε,则根据特征a
g
的每个取值将训练集d划分为n个子集d1,d2,...,d
n
,将d
i
中样本数据最大的小类作为开始节点的类,构建开始节点的子节点,则由开始结点及其子结点构成决策树t,并返回决策树t;
[0170]
步骤5.5,以d
i
为训练集,选择除了a
g
以外的信息增益比最大的特征作为新的类,将其视为a
g
,然后按照步骤5.4的方法执行;不断循环直到所有的特征全部分类完成,返回决策树t,预测结束,将学习成绩的合格或不合格作为最终预测结果;
[0171]
步骤6,按照步骤4
‑
5的步骤分别选取经步骤2处理的静态数据和经步骤3量化的动态数据中的一部分作为测试集数据,生成最终的决策树预测模型去预测学习成绩结果,具体为:
[0172]
将经步骤4.1选取之后剩余的静态数据的20%和动态数据的20%放入测试集,作为测试数据,按照步骤4.2
‑
步骤5.6的方式对测试集数据进行操作,生成最终的决策树预测模型去预测学习成绩结果;
[0173]
步骤7,通过精确率、准确率和召回率对预测结果进行判断,当精确率、准确率和召回率任意一个不小于90%时,将对应的学习行为指标可以被作为影响学习者成绩的学习行为指标;具体为:
[0174]
步骤7.1,确定混淆矩阵;
[0175]
混淆矩阵中包括真实类别和预测类别以及真实类别和预测类别的比较结果,真实类别是学习者在自适应平台中真实的学习成绩的及格情况,预测类别是指通过测试集和决策树预测得到的学习成绩的及格情况,真实类别和预测类别的比较结果包括,如表1所示,
[0176]
表1
[0177][0178]
若真实类别为及格且预测类别为及格则表示被正确地划分为正例,计被正确地划分为正例的个数为tp(true positives);
[0179]
若真实类别为及格且预测类别为不及格则表示被错误地划分为负例,计被错误地划分为负例的个数为fn(false negatives);
[0180]
若真实类别为不及格且预测类别为及格则表示被错误地划分为正例,计被错误地划分为正例的个数fp(false positives);
[0181]
若真实类别为不及格且预测类别为不及格则表示被正确地划分为负例,及被正确地划分为负例的个数为tn(true negatives);
[0182]
用p指真实类别中及格总数;n指真实类别中不及格的总数;p1指预测类别中及格总数,n1指预测类别中不及格总数;
[0183]
步骤7.2,根据步骤7.1得到的混淆矩阵,计算预测的精确率、准确率和召回率,具体为:
[0184]
精确率precision:
[0185][0186]
准确率accuracy:
[0187][0188]
召回率recall:
[0189][0190]
当精确率、准确率和召回率任意一个不小于90%时,认为该学习行为指标可以被作为影响学习者成绩的指标;
[0191]
步骤8,根据步骤7确定的行为指标,进行k
‑
means聚类,确定学习群体;具体为:
[0192]
步骤8.1,根据步骤7确定的影响学习者学习成绩的学习行为指标的个数k,确定得到k个聚类群体,给每个聚类群体选择一个中心点,即就是在每个群里中所选的随机数,即就是聚类中心,对每类学习行为指标对应的数据集中数据的平均值以及该学习行为指标对应的数据集中的每个学习者的数据通过欧式公式计算该数据到每一个聚类中心的距离,数据集为训练集和测试集的总和,如果距离u<0.5则将该学习者归类到本类的聚类群体中;
[0193]
欧式公式具体如下:
[0194][0195]
其中,h表示数据集中的数据,l表示所选择的聚类中心;
[0196]
步骤8.2,根据步骤8.1对所有学习者进行按照学习行为指标进行归类,得到k个学习者群体;
[0197]
步骤9,根据步骤8确定的具有相同学习行为的不同学习者群体,对于每一类学习者群体提供不同的学习方案,具体为:
[0198]
根据步骤8获得的k类学习者群体,按照步骤8的聚类方法将学习者聚类到对应的学习者群体中,自适应平台中根据聚类的学习者群体推荐平台的相关资源、合适的题目以及推荐当前学的知识点和接下来需要学习的知识点;资源包括有视频、音频、图片、文档、ppt以及教案。
[0199]
本发明从自适应平台获得学习行为数据后,首先,需要对这些数据进行清洗、转换和集成等预处理操作,从而让数据集更有规则;其次,将从学习者的静态数据和动态数据提取可能影响学习成绩的行为指标作为预测指标;最后,将预测指标和决策树预测算法相结
合去预测可能影响学习成绩的行为指标,再根据准确率、精确率和召回率评估预测算法,当拿到最终确定的行为指标后,通过k
‑
means聚类算法确定拥有该行为特征的学习者群体,并对不同学习群体根据不同的行为提供个性化的干预方案,提前预防学习者存在的潜在问题,从而提高学习者的效率。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1