一种基于股票社区关系图谱的交互风险团伙识别方法与流程
1.本发明涉及一种基于股票社区关系图谱的交互风险团伙识别方法,属于反欺诈方法技术领域。
背景技术:
2.股票市场中常遇到一些不法团伙通过股票社区刷量提高曝光影响力、发布引流信息或将股民引流到社交软件或直播间进行群体性非法荐股等手段,诱骗投资者高价买入非法牟利,这不仅扰乱市场秩序及侵害投资者利益,并对股票社区平台的企业造成不良影响。线上的欺诈风险变化多样,以往传统的、单一的针对个体风险的反欺诈手段,以及利用规则引擎和有监督机器学习算法的检测,已经不能解决当前市场环境下不断出现的新的作弊欺诈风险模式,以及有组织、有规模的形成团伙分工的风险检测。
3.例如:公开号为cn109918511a的发明专利申请(以下简称“文献【1】”),公开了一种基于bfs和lpa的知识图谱反欺诈特征提取方法,其包括以下步骤:步骤一、对原始数据标准化,将原始数据转化为不同维度下的标注数据,进行清洗、转换,形成符合知识图谱建模的数据;步骤二、知识图谱模型构建,包含本体构建、语义标注和信息抽取。对消费金融反欺诈领域的欺诈团案问题,文献【1】使用基于标签传播的实体子团挖掘方法,挖掘实体子团信息,提取对应的特征变量。
4.公开号为cn110188198a的发明专利申请(以下简称“文献【2】”),公开了一种基于知识图谱的反欺诈方法及装置,所述方法包括:从数据源中抽取实体、实体属性数据以及关系数据;对所述实体属性数据进行筛选与处理,并利用处理过的实体属性数据以及所述关系数据构建知识图谱,所述知识图谱包括第一类节点和第二类节点,所述第一类节点为已知标签的节点,所述第二类节点为待预测标签的节点;基于所述知识图谱,预测所述第二类节点的标签。
5.公开号为cn112053221a的发明专利申请(以下简称“文献【3】”),公开一种基于知识图谱的互联网金融团伙欺诈行为检测方法,所述方法包括以下步骤:获取多个预设数据源的用户的个人申请信息、操作行为埋点数据和黑名单数据;对申请信息和操作行为埋点数据进行预处理后切分训练集和测试集,根据黑名单命中情况标记客户为欺诈节点和未标记节点,然后求出欺诈节点与其相邻用户节点之间的相似度和归属因子,对未标记节点的欺诈风险评估,采用neo4j图数据库构建知识图谱,对验证集欺诈风险评估结果测试,对实时申请用户欺诈行为检测并处理。
6.公开号为cn110223168a的发明专利申请(以下简称“文献【4】”),公开了一种基于企业关系图谱的标签传播反欺诈检测方法及系统,包括以下步骤:s1、建立企业黑名单库;s2、构建关系图谱:筛选关系数据库中列入关系图谱的相关表格及字段,抽取关系型数据库对象实体及实体关系;s3、基于自建黑名单库以及企业关系图谱对企业进行反欺诈检测:基于黑名单库标识关系图谱黑名单节点,提取黑名单节点连接子图,运用标签传播算法识别各连接子图中的欺诈企业节点,并预估企业反欺诈的概率。
7.公开号为cn110413707a的发明专利申请(以下简称“文献【5】”),公开了一种互联网中欺诈团伙关系的挖掘与排查方法,获取互联网金融数据,采用知识图谱的构建原理构建金融关系图谱,在构建的金融关系图谱基础上,通过聚类算法挖掘出具有相似行为的群体,通过对群体的构成进行分析,实现对欺诈团伙的识别,完成对欺骗团伙关系的挖掘与排查。
8.公开号为cn108681936a的发明专利申请(以下简称“文献【6】”),公开了一种基于模块度和平衡标签传播的欺诈团伙识别方法,包括:利用id特征结合用户自身已知的欺诈标识,对所有用户计算两两相似度,建立相似度矩阵,通过相似度矩阵建立关联图;对建立的图运行louvain算法得出每个节点所属的社区及层级信息;以每个节点所属的社区、层级信息及欺诈标识作为每个节点初始的社区信息,运行平衡标签传播过程得到每个节点最终所属社区,再根据是否归属共同社区划分网络,根据传播获得的欺诈标识划分欺诈团伙。
9.公开号为cn111369139a的发明专利申请(以下简称“文献【7】”),公开了一种个体信用评估方法,获取用户的关系网络和不良事件的信息为基础;建立假设条件,设置用户节点的风险权重,获取与用户节点u相连的n个其它用户节点集合;于利用时间函数分析处理用户发生不良信用事件节点的风险权重,将风险权重传导给与用户当前节点相连的节点;对个性化pagerank算法进行改进同时通过该算法遍历所有节点,并计算出关系网络中所有节点的不良信用事件的风险权重;按照风险权重排序,得到基于不良信用事件影响的用户风险排序表。
10.公开号为cn110348978a的发明专利申请(以下简称“文献【8】”)公开了一种基于图计算的风险团伙识别方法、装置、设备和存储介质,该方法,包括:接收业务请求,所述业务请求包含业务类型及用户属性信息;对所述业务类型、所述用户属性信息及与所述业务请求对应的历史业务数据,进行社会网络分析,以生成对应的社会网络;根据凝聚度从所述社会子网络分割出与所述业务请求对应的子网络;将所述子网络的邻接矩阵输入预设的预测模型,获得所述业务请求对应的风险团伙识别结果。
11.公开号为cn109299811a的发明专利申请(以下简称“文献【9】”),公开了一种基于复杂网络的欺诈团伙识别和风险传播预测方法,包括以下步骤:获取个体属性;确定所述主体属性和非主体属性的属性值唯一编码;数据过滤;建立存储和计算的数据结构;建立连通图,将所述主体属性值和非主体属性值抽象为节点,将主体属性值和非主体属性值的归属关系抽象为连接所述节点的边,所述节点和边组成连通图;根据所述连通图获取模型图;根据所述数据结构计算模型参数;根据所述模型参数进行欺诈团伙识别和欺诈风险传播预测。
12.公开号为cn110569509a的发明专利申请(以下简称“文献【10】”),公开了一种风险团伙识别的方法及装置,其中所述方法包括:获取在设定时间窗口内注册的多个账户以及各账户的注册信息;根据各账户的注册信息,确定任意两账户之间的相似度;基于所述相似度对所述多个账户进行聚类,获得一个或多个账户集合;针对各账户集合,若判定该账户集合中的账户数量满足设定条件时,则将该账户集合作为风险团伙数据。
13.上述技术方案存在以下问题:
14.1)文献【1】、文献【2】、文献【3】、文献【4】、文献【5】主要面临的风险主要是信贷领域的欺诈风险和信用风险:如在申请贷款时评估放贷风险等。而在股票社区金融领域场景中,
面临的风险是社区交互异常团伙风险及产生的欺诈行为。由于场景不同,具体的风险特征及团体特征有所不同。
15.2)文献【2】只包含一种实体,即为企业,实体较为单一,因而其构建的网络也非大规模网络。
16.3)文献【2】和文献【3】简单来讲都是通过已标记节点来预测评估未标记节点的风险,其中,文献【2】是根据lightgbm来进行预测评估,文献【3】是根据相邻节点的相似度和归属因子来进行,均未提出对于构建的网络进行进一步挖掘分析及团伙识别方法等。文献【8】简单描述就是构建社区然后依据凝聚度来进行社区划分,通过预测模型获取风险团伙识别,并没办法在团伙在未知用户节点风险的情况下进行风险团伙的挖掘。
17.4)文献【1】、文献【4】和文献【5】均使用lpa标签传播算法用于判断用户是否具有欺诈风险。但目前该算法的缺点就在于迭代结果震荡,在实际情况中存在不收敛问题,但相关文献中暂未提出此类问题对应的相关解决方法。
18.5)文献【5】中提到了多个图算法,包括:社团发现算法fast unfolding、重叠社区检测算法bigclam、lpa标签传播算法、图嵌入等,由于算法各自本身所具备的优缺点在不同业务细分场景解决不同问题里面并未给出详细的解决方案,比如fast unfolding又名louvain也可以对重叠社区进行检测,lpa本身也支持社区发现等。
19.6)文献【6】提出线上支付业务如何有效、及时地识别频繁发生的线上欺诈行为成为迫切需要解决的问题。为了解决该问题,文献【6】通过构建的关联图利用louvain算法及平衡标签传播获取最终所属社区及欺诈标识划分的欺诈团伙。文献【6】中虽然提到其所公开的技术方案具有优秀的准确率,但实施中需对所有邻居节点进行模块度增益计算的迭代方式,对是否能够解决大规模图的及时性并未给出对应的解决方法。
20.7)文献【7】使用到了改进的个性化pagerank算法用于个体信用评估方法,具体为对需评估信用个体用户所在关系网络中的所有用户进行排序,得到基于不良信用事件影响的用户信用风险排序表,从而评估出个体信用风险大小。文献【7】并未针对所在图对应社区关系整体进行风险评估,且时间衰减仅作用于有不良事件的节点,并未能广泛的适用于网络关系。
21.8)文献【9】是根据连通图获取模型图后分层级,第一模型图是通过深度、广度优先搜索来挖掘,对第一模型图中个体间公用非主体属性值作为边来构建第二模型图,基于此来进行欺诈团伙识别和欺诈风险传播。文献【9】所公开的检测方法同样也不适用于刷量风险用户及风险团伙的场景。
22.9)文献【10】主要通过相似度进行聚类获得账户集合,用于检测批量注册等风险团伙识别,文献【10】检测风险团体并未使用到图技术及对于网络关系的挖掘与异常发现。
技术实现要素:
23.本发明的目的是:克服现有技术中互联网金融行业反欺诈技术在上述中的不足。
24.为了达到上述目的,本发明的技术方案是提供了一种基于股票社区关系图谱的交互风险团伙识别方法,其特征在于,包括以下步骤:
25.s1采集服务端日志数据以及具体行为埋点的客户端埋点日志数据,对采集到的数据进行预处理后,得到构建关系图谱的输入数据;
26.s2基于上一步获得的数据抽取信息,包括对实体的抽取、对实体关系的抽取以及对属性的抽取,其中:
27.对实体的抽取包括抽取用户实体、设备终端实体、帖子实体及股票实体;
28.依据用户、帖子实体、股票以及设备终端之间的关联关系,提取用户实体、设备终端实体、帖子实体以及股票实体之间的关系,将实体关系分为社区交互行为类关系以及非社区交互行为类关系,其中,用户实体相互之间的关系、用户实体与帖子实体之间的关系、用户实体与股票实体之间的关系为社区交互行为类关系;用户实体与与设备终端实体之间的关系、帖子实体与股票实体之间的关系为非社区交互行为类关系;
29.对属性的抽取包括对实体的属性的抽取以及对实体关系的属性的抽取,属性包括从步骤s1得到的输入的数据中直接统计、抽取得到的指标数据,也包括依据结合指标数据得到的标签;
30.s3构建关系图谱模型
31.基于步骤s2抽取得到的实体、实体属性、实体间的关系、实体间关系的属性的海量数据构建两类关系图谱模型:一类是根据非社区交互行为类关系构建的通用关系图谱,以实现风险团伙的识别及对通用团伙规模进行定义;另一类是根据社区交互行为类关系构建的社区交互关系图谱,进行交互中存在刷量行为风险的团伙识别,以及团伙中用户的影响力判断,从而标记出用户在团伙中担任的角色挖掘;
32.s4风险识别,包括以下步骤
33.s4.1基于通用关系图谱利用louvain算法划分通用社区得到通用社区划分结果,从而实现对通用团伙的识别;
34.louvain算法分为实时线和离线两部分,离线处理具体包括以下步骤:
35.s4a.1.1初始化离线数据,通用关系图谱中每个节点作为一个独立社区;
36.s4a.1.2根据先验的业务知识对通用关系图谱做预剪枝,有效地减少用于图计算的数据量及产生的运算量;
37.s4a.1.3对于每个节点i,依次把节点i分配到其每个邻居节点所在社区,计算分配前后模块度增量δq,记录δq最大的邻居节点,且最大的δq》0;则把节点i分配到δq最大的邻居节点所在的社区,否则放弃此次划分;
38.其中,模块度q按下式(1)计算:
[0039][0040]
式(1)中,a
i,j
表示节点i和节点j之间边的权重,计算公式如下式(2)所示:
[0041][0042]
式(2)中,情况1表示根据边的属性的指标数据需要体现数值的绝对差异,情况2表示根据边的属性的指标数据需要体现方向的相对差异;δ
′
是自定义参数;
[0043]
式(1)中,ki=∑
jai,j
,表示所有与节点i相连的边的权重之和;kj表示所有与节点j
相连的边的权重之和;表示所有边的权重之和;ci表示顶点i所属的社区,cj表示顶点j所属的社区;
[0044]
s4a.1.4重复步骤s4a.1.3,直到所有节点对应社区不再变化;
[0045]
s4a.1.5对通用关系图谱进行压缩,将所有在同一个社区的节点压缩成一个新节点,社区内节点之间的边的权重转化成新节点的环的权重,社区间的边权重转化为新节点间的边权重;
[0046]
s4a.1.6重复步骤4a.1.1,直到整个通用关系图谱的模块度不再发生变化;
[0047]
s4a.1.7过滤合并及剪枝。
[0048]
实时线处理时,对于实时新增节点i的处理包括以下步骤:
[0049]
s4b.1.1对于新增节点i,把新增节点i随机分配到其一个邻居节点所在社区,计算分配前后模块度增量δq,其中,模块度q按照式(1)计算;
[0050]
步骤s4b.1.2若上一步计算得到的δq不大于阈值,则随机选择另外一个邻居节点,返回步骤s4b.1.1,否则,把新增节点i分配到当前邻居节点所在的社区,结束此次划分;
[0051]
s4.2基于社区交互关系图谱进行刷量团伙及用户角色识别
[0052]
通过lockinfer算法进行刷量lockstep行为风险团伙检测发现和改进个性化pagerank算法来获取交互关系网络中的用户节点的欺诈传播分值,用于用户角色判定,具体包括以下步骤:
[0053]
步骤s4.2.1通过lockinfer算法检测刷量行为风险团伙
[0054]
定义s为源节点用户,则s为源节点用户集合,t为目标节点用户,则t为目标节点用户集合,则步骤s4.2.1具体包括以下步骤:
[0055]
步骤s4.2.1.1基于选择种子算法选出具有疑似lockstep行为的种子节点组成的种子节点集,其中,选择种子算法具体包括以下步骤:
[0056]
步骤s4.2.1.1.1对交互关系图谱进行奇异值分解,基于k-svd算法计算邻接矩阵a的左奇异向量u和右奇异向量v,用左奇异向量u两两组合绘制谱子空间:
[0057]
对每一个对(i,j),1≤i<j≤k,k为k-svd的迭代次数,绘制左奇异向量u
i vsuj的谱子空间,ui为第i次迭代获得的左奇异向量,uj为第j次迭代获得的左奇异向量,寻找如下表中出现"rays"、"staircase"和"pearls"的异常现象:
[0058][0059]
[0060]
步骤s4.2.1.1.2将谱子空间利用霍夫变换从笛卡尔坐标系转化为极坐标系,即对于谱子空间中每一个用户节点u
x
,x≤n,n为用户节点的总个数,有下式(3):
[0061][0062]
式(3)中,笛卡尔坐标(u
i,x
,u
j,x
)转化成极坐标(r
x
,θ
x
),r
x
为用户节点u
x
的极坐标半径,θ
x
为用户节点u
x
的极坐标角度;
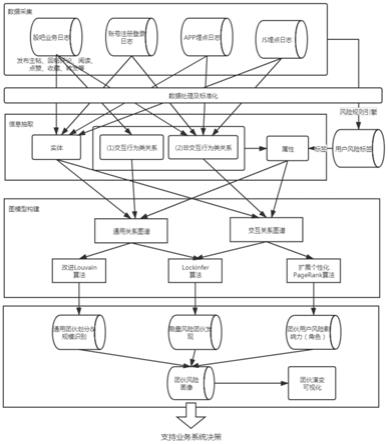
[0063]
步骤s4.2.1.1.3绘制节点的r频率和θ频率分布直方图,有下式(4):
[0064][0065]
式(4)中,freq(r)为节点的r频率,freq(θ)为节点的θ频率;
[0066]
步骤s4.2.1.1.3检测出上一步所获得的直方图的尖峰,并将尖峰所对应的节点集作为种子节点集;
[0067]
步骤s4.2.1.1.4通过业务经验对种子节点集中的种子节点进行进一步的过滤,获得最终的种子节点集;
[0068]
步骤s4.2.1.2进行lockstep传播:根据上一步选出的种子节点集,在社区交互关系图谱中通过传播lockstep值,检测具有lockstep行为的用户节点,具体算法传播流程如下:
[0069]
步骤s4.2.1.2.1初始化:
[0070]
定义种子节点集中的种子节点为第0轮的lockstep刷量行为用户;
[0071]
由源节点集合s及目标节点集合t构成m
×
n矩阵(s,t),m≤m,n≤n,社区交互关系图谱的邻接矩阵a的大小为m
×
n;
[0072]
最小的lockstep异常密集块规模m
min
×nmin
以及对应的密度阈值其中,密度阈值表示为下式(5):
[0073][0074]
式(5)中,d=d(a)表示邻接矩阵a的密度,当时,则认为矩阵(s,t)(s,t)是邻接矩阵a中第一个lockstep异常密集块;
[0075]
定义时间衰减权重邻接矩阵w1=(w
1i,j
),则有:
[0076][0077]
式中,γ表示衰减常数,其值表示历史信息衰减的速率,需要考虑有限的历史信息;h为节点i和节点j连接后经过的时间,h=0表示当前关系;
[0078]
步骤s4.2.1.2.2从源节点用户集合s传播lockstep到目标节点用户集合t;s-》t:以lockstep刷量用户源节点用户作为种子节点,统计每个目标节点用户关联到的具有lockstep刷量行为源节点用户数,若比例超过阈值且规模大于n
min
,则标记为具有
lockstep刷量行为的目标节点用户,即
[0079]
步骤s4.2.1.2.3从目标节点用户集合t传播lockstep到源节点用户集合s
[0080]
t-》s:统计每个源节点用户关联到的具有lockstep刷量行为目标节点用户数(如:源节点用户关注了多少具有lockstep刷量行为的目标节点用户),若比例超过阈值且规模大于m
min
,则标记为具有lockstep刷量行为的源节点用户,即
[0081]
步骤s4.2.1.2.4重复步骤s4.2.1.2.2及步骤s4.2.1.2.3直至收敛;
[0082]
步骤s4.2.2通过改进个性化pagerank算法获取欺诈传播分值,包括以下步骤:
[0083]
步骤s4.2.2.1获得社区交互关系图谱的包含两类节点的二分图g=(ν,ε):e(v1,v2)∈ε|v1∈ν1and v2∈ν2,其中,ν表示实体节点,ν1ν2分别表示二分图的两类节点,一类是用户账号实体节点,另一类是用户发帖对应的帖子实体节点;ε表示边,e(v1,v2)表示二分图的两类节点ν1ν2对应的边;
[0084]
步骤s4.2.2.2通过pagerank算法计算二分图中所有节点的分值:
[0085]
定义时间衰减权重邻接矩阵w
2n
×m=(w
2i,j
)如下式(7)所示:
[0086][0087]
式(7)中,μ为加权常数,d为时间区间内频发操作的密度;
[0088]
pagerank算法每次重新游走选择在特定节点集合中选择一个节点开始,则
[0089]
有:
[0090][0091]
将时间衰减权重邻接矩阵w
2i,j
扩展成(i+j)
×
(i+j)的对称矩阵q:
[0092][0093]
式(8)中,w'i×j表示的是w
i,j
的转置矩阵;
[0094]
将对称矩阵q进行列归一化后得到对称矩阵q
norm
,则迭代传播过程转变为式(9)所示:
[0095][0096]
式(9)中,向量和大小均为i+j,向量表示节点对应的pagerank分值,对于用户和帖子的关系而言,为用户和帖子的重启随机游走时被选中的概率;
[0097]
最终得到的分值可解释为用户节点在团伙中的重要性,即影响力,值越高代表用户节点在团伙中的重要性越高。
[0098]
优选地,步骤s1中,采集的数据包括:包含用户账号注册登录在内的api服务端日志,用于获取用户账号和终端设备间的关系;用户账号在网络社区进行交互操作服务端日志;发帖审核后台日志数据,包括对用户的审核处置标识以及对帖子的处置标识。
[0099]
优选地,步骤s2中,所述用户实体为用户账号id,所述设备终端实体为设备终端id,所述帖子实体为帖子id,所述股票实体为股票代码
[0100]
优选地,步骤s2中,用户实体的属性中的标签包括用户风险画像标签,根据行为及意图,用户风险画像标签分为账号安全类风险标签以及账号业务行为类风险标签;
[0101]
则在步骤s4.2.1.1中,除选择种子算法外,还可以将业务专家定义筛选的具有对应用户风险画像标签及业务审核结果的用户节点选取为种子节点,进而组成种子节点集。
[0102]
优选地,步骤s3中,在进行关系图谱构建时,将边的属性中的指标数据用作过滤筛选条件,根据业务专家设计的规则模型,选取边的属性中对应指标数据符合建图标准的边进行构建。
[0103]
与现有技术相比,本发明具有如下优点:
[0104]
1)目前针对关系图谱的反欺诈风险检测识别主要集中于金融信贷领域机构对于评估放贷风险、面向资产管理公司消费金融领域的反欺诈识别等场景,如:利用企业关系网络进行分析与挖掘关系体现的欺诈风险,通过已经标记到的风险用户来进行潜在风险预警等。由于其较为单一的实体关系,如仅把企业作为实体,并不适用于当前场景中实体更为多样化、关系更为错综复杂的情况。本发明中根据股票社区产生的较为错综复杂关系的特征,从较单一的实体关系,到可实现社区股民用户间及用户与其他实体间的复杂关系网络所暴露体现的欺诈风险的行为进行的分析与挖掘。
[0105]
2)已有技术中较多的算法依赖如neo4j图形算法库提供的原始算法,没有针对性进行算法改进来适配当前需要解决的业务问题。本发明中在模型选择上选择了与场景较为适配的算法,如lpa标签传播算法较为高效,但由于其存在随机选择的情况,因此会出现迭代结果震荡的缺点,在实际业务场景中会有不收敛问题,不利于后续团伙的持续跟踪以及业务处置。因此本发明选择改进的louvain算法,由于算法其较为优越的稳定性,并优化改进解决了时效性问题,以及模块度中边的权重计算来提高对业务模型的适配度。
[0106]
3)已有技术提出根据关系网络图谱利用社区划分算法或根据邻接节点的相似度去判断用户是否具有欺诈风险,目前无法有效解决当前场景中针对不同风险行为及意图的团体识别、及团伙中用户所担任的角色识别。本发明中利用lockinfer算法及选取种子的策略来发现刷量行为团体,可支持业务后续对刷量行为团体进行具体意图分析。并且本发明使用改进的pagerank算法获取团伙成员在关系中的影响力分值,从而进一步获取成员在团伙中所承担的角色,最后获得团体综合风险画像来支持业务系统,对用户来进行差异化处置。
附图说明
[0107]
图1为本发明实例提供方法的原理框架图;
[0108]
图2为本发明实例提供方法中交互关系构建网络的图例。
具体实施方式
[0109]
下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本技术所附权利要求书所限定
的范围。
[0110]
本发明提供的一种基于股票社区关系图谱的交互风险团伙识别方法具体包括以下步骤:
[0111]
s1数据采集、数据处理及标准化
[0112]
根据业务需求中需要对风险团伙进行检测识别的具体场景来规划需要采集的服务端日志数据以及具体行为埋点的客户端埋点日志数据。将采集到的数据根据业务专家定义的数据标准进行划分,目的是实现数据根据业务逻辑及用户交互行为类型进行划分。并对这些数据进行数据清理、加工、转换后,形成做为构建关系图谱的输入数据。
[0113]
本实施例中,采集的数据主要包括用户账号所有app/js客户端行为埋点日志,获取用户账号和设备终端的关系,具体字段举例如下表所示。
[0114][0115][0116]
本实施例中,主要分以下几类数据进行采集:
[0117]
1.用户账号注册登录等api服务端日志,获取用户账号和设备间的关系,具体字段举例如下表所示。
[0118][0119]
2.用户账号在社区进行交互操作服务端日志,如:发布主帖、回帖评论、阅读、点赞、收藏、转发等交互行为,具体字段举例如下表所示。
[0120]
a.发布主帖:
[0121][0122]
b.发布回帖:
[0123]
[0124][0125]
点赞、收藏、转发等交互行为数据结构同理。
[0126]
3.发帖审核后台日志,具体分为两类:
[0127]
a.对用户审核处置标识:
[0128]
字段备注说明发布回帖用户账号id依照用户账号id生成格式规范约束用户当前授信状态如:禁言、可疑、正常用户、优质用户等用户授信时间对用户审核,后台标记时间
[0129]
b.对帖子的处置标识:
[0130][0131]
s2信息抽取
[0132]
本发明构建的关系图谱主要分为节点、边、属性,因此在本步骤中进行用于构建关系图谱的信息抽取,主要分为:对实体的抽取、对实体关系的抽取以及对属性的抽取。
[0133]
s2.1实体抽取
[0134]
目前本领域的实体抽取与传统文本抽取过程不同,本发明关注实体在产生交互行为的用户本身外,还包含对应的帖子实体、股票实体、设备终端实体,每个实体为一个节点。
[0135]
本实施例中,用户实体:用户账号id(通行证id);
[0136]
设备终端实体:设备终端id;
[0137]
帖子实体:帖子id(根据主帖id以及该主贴的回帖id,用拼接逻辑进行处理成统一代码id);
[0138]
股票实体:股票代码。
[0139]
s2.2实体关系抽取
[0140]
依据用户、帖子实体、股票以及设备终端之间的关联关系,提取用户实体、设备终端实体、帖子实体以及股票实体之间的关系。本发明基于是否是社区交互行为的规则来区分获取实体之间的关系,将其分为以下两类:
[0141]
1.社区交互行为类关系,进一步包括:
[0142]
a.用户账号与用户账号之间的关系,包括关注订阅、@提到指定用户账号等用户账号之间直接产生交互行为的直接关系,也包括通过用户账号-帖子-用户账号获得的用户账号所产生的间接关系;
[0143]
b.用户账号与帖子之间的关系,包括发布主帖、回帖评论、阅读、点赞、收藏、转发等用户账号之间通过帖子等载体完成交互的行为;
[0144]
c.用户账号与股票之间的关系,包括用户账号关注股票等用户交互行为关系。
[0145]
2.非社区交互行为类关系,进一步包括:
[0146]
a.用户账号与设备终端关系,包括用户注册登录、用户发帖等点赞时操作对应的用户账号与设备终端id的关系;
[0147]
b.帖子与股票关系,包括发布主帖和回帖所归属具体股票吧。
[0148]
s2.3属性抽取
[0149]
通常,属性抽取是指从文本中抽取出实体的属性信息,如:“用户”的“年龄”、“性别”等属性。而在本发明中的实体属性一方面关注的是实体本身的属性,如用户风险画像标签;另一方面关注的是实体之间关系的属性。即在本发明中,即抽取每个实体的属性,作为节点的属性,也抽取实体之间关系的属性,作为边的属性。本发明中,属性包括依据专家规则从步骤s1输入的数据中直接统计、抽取得到的指标数据,也包括依据专家规则结合指标数据得到的标签。
[0150]
在本发明中,节点的属性通常以标签为主,而边的属性通常以指标数据为主。
[0151]
提取的用户账号实体的属性为:用户账号实体属性主要用户反映用户信息及特征,包括且不限于姓名、年龄、性别、账号注册时间、账号注册来源等,用户行为统计指标,以及给用户账号标记的风险画像标签。
[0152]
提取的设备终端实体的属性为:设备信息包括且不限于设备终端类型、型号、厂家,设备行为统计指标(如:设备首次发帖、设备近7日发帖数等相关指标数据等),以及给设备标记的风险画像标签及风险等级(如:模拟器、改机工具、hook框架、逆向工具、第三方android rom、root等);用于发现团伙中利用模拟器、改机工具等模拟app设备并大批量篡改设备信息的账号。
[0153]
提取的帖子实体的属性为:帖子统计指标,包括且不限于帖子字数、帖子相似度分值、帖子人气指数等。
[0154]
提取的股票实体(股票代码)的属性为:属性主要覆盖股票本身的市场价值属性及股票社区热度等方面,包括且不限于股票当前市值,股票是否小盘股,近7日个股吧热度排名指数、近7日个股吧情绪指数等。
[0155]
提取的实体间关系的属性为:根据不同的实体所产生的关系,构建对应能反映实体间关系的特性的指标来构建关系属性。
[0156]
在本实施例中,用户实体的属性中的标签可以包括用户风险画像标签,根据行为及意图,将用户风险画像标签细分为账号安全类风险标签以及账号业务行为类风险标签,具体举例如下:
[0157]
注册机用户:账号安全类风险,利用注册工具进行批量注册登录账号;
[0158]
发帖机用户:业务行为类风险标签,利用发帖工具进行大规模发帖的业务行为;
[0159]
疑似引流用户:业务行为类风险标签,账号在个人信息及发帖内容中发布引流信息;包含且不限制于:个人简介、个人头像、实盘模拟炒股组合名称,主帖、评论、帖子内容中图片等;
[0160]
疑似水军用户:业务行为类风险标签,账号进行刷赞、刷粉、刷评论置顶热评等;
[0161]
禁言用户:审核后台中对于部分用户账号进行禁言操作。
[0162]
用户实体的属性中的指标数据举例为:用户首次发帖时间、用户近7日发帖数、用户历史发帖数、用户近7日删帖数、用户历史发帖数等相关指标数据等。
[0163]
作为【用户-终端设备】关系属性(即用户节点与终端设备节点之间的边的属性)中的指标数据举例为下表:
[0164][0165][0166]
边的属性视实体之间相互关系的不同而不同,在后续步骤中可通过这些抽取的边的属性中的指标数据来进行边的权重的计算。
[0167]
并且,在后续步骤s3进行关系图谱构建时,将边的属性中的指标数据用作过滤筛选条件减小资源消耗。具体而言,根据业务专家设计的规则模型,选取边的属性中对应指标数据符合建图标准的边进行构建,例如:若用户仅在某设备上登录一天,且对应无发帖记录,则在构建关系图谱时,过滤此条关系,不构建对应的边。
[0168]
s3构建关系图谱模型
[0169]
基于步骤s2抽取得到的实体、实体属性、实体间的关系、实体间关系的属性的海量数据用python构建了亿级别的两类关系图谱模型:一类是根据通用关系即非社区交互行为类关系构建的通用关系图谱,以实现风险团伙的识别及对通用团伙规模进行定义;另一类是根据社区交互行为类关系构建的社区交互关系图谱,进行交互中存在刷量行为风险的团伙识别,以及团伙中用户的影响力判断,从而标记出用户在团伙中担任的角色挖掘。
[0170]
s4风险识别
[0171]
s4.1基于通用关系图谱划分通用社区
[0172]
通用关系图谱先基于通用关系进行连通图构建,再融合了复杂网络的社群发现算法进行社区划分。在算法选型中,综合考虑到其效率与准确率、稳定性,通用关系图谱的构建选择社区发现算法中基于模块度(modularity)的社区发现算法louvain算法。louvain算法支持多层聚类,能够发现层次性的社区结构。louvain算法先把所有用户划分为小组,然后以小组为单位进一步聚类成大组,以此来发现更大或更为隐蔽的团伙。
[0173]
louvain算法需遍历全部节点而不适配时效性较高的业务场景,及会出现模块度
增量小时社区间合并问题,为解决上述问题,本发明对原始的louvain算法进行了改进。
[0174]
首先,louvain算法的思路是要找出各实体节点归属社团,并且让划分结构的模块度最大。通过计算模块度增量δq来进行社区发现,模块度增量δq就是把一个孤立节点放入一个社区后来计算模块度的变化。但是由于大部分开销用于计算和比较全部邻居节点模块度增益,大规模社区需遍历全部节点,不适应于要求时效性较高的场景。针对这个问题,本发明引入随机邻居louvain算法(random neighbor louvain)的思路来改进原算法,实时线随机抽取节点计算模块度增量是否高于设定阈值来进行社区划分,离线则继续遍历全部节点,后续对比实时线和离线算法结果,进行业务干预差异修正。
[0175]
其次,louvain算法进行社区划分时,计算模块度增量时是利用社区内边连接数目减去随机图中节点与该社群连接边数。当图的规模非常大后,那么在随机情况下当出现节点的度很小,意味着节点连到任一社区的概率都非常小,即模块度增量非常小,那么只要两个社区之间有一条边相连,社区都会合并。为了解决这个问题,需要给边设置权重用于模块度计算,本发明权重的计算方法根据指标逻辑是关注数值上的绝对差异还是方向上的相对差异来获取。
[0176]
算法具体流程如下:
[0177]
本发明的louvain算法分为实时线和离线两部分,离线处理具体包括以下步骤:
[0178]
s4a.1.1初始化离线数据,通用关系图谱中每个节点作为一个独立社区;
[0179]
s4a.1.2根据先验的业务知识对通用关系图谱做预剪枝,有效地减少用于图计算的数据量及产生的运算量;
[0180]
s4a.1.3对于每个节点i,依次把节点i分配到其每个邻居节点所在社区,计算分配前后模块度增量δq,记录δq最大的邻居节点,且最大的δq》0;则把节点i分配到δq最大的邻居节点所在的社区,否则放弃此次划分;
[0181]
其中,模块度q按下式(1)计算:
[0182][0183]
式(1)中,a
i,j
表示节点i和节点j之间边的权重,计算公式如下式(2)所示:
[0184][0185]
式(2)中,情况1表示根据边的属性的指标数据需要体现数值的绝对差异,情况2表示根据边的属性的指标数据需要体现方向的相对差异;δ
′
是自定义参数;对应情况1及情况2的划分,具体举例如下表所示:
[0186]
指标项指标项内容边的权重计算指标1是否注册终端关注相对差异,使用余弦距离指标2是否发帖终端关注相对差异,使用余弦距离指标3登录终端历史活跃天数关注数值的绝对差异,使用欧式距离指标4近30天登录终端活跃天数关注数值的绝对差异,使用欧式距离指标5用户终端累计发帖天数关注数值的绝对差异,使用欧式距离
[0187]
式(1)中,ki=∑
jai,j
,表示所有与节点i相连的边的权重之和;kj表示所有与节点j相连的边的权重之和;表示所有边的权重之和;ci表示顶点i所属的社区;
[0188]
s4a.1.4重复步骤s4a.1.3,直到所有节点对应社区不再变化;
[0189]
s4a.1.5对通用关系图谱进行压缩,将所有在同一个社区的节点压缩成一个新节点,社区内节点之间的边的权重转化成新节点的环的权重,社区间的边权重转化为新节点间的边权重;
[0190]
s4a.1.6重复步骤4a.1.1,直到整个通用关系图谱的模块度不再发生变化;
[0191]
s4a.1.7过滤合并及剪枝。
[0192]
实时线处理时,对于实时新增节点i,将对其全部邻居节点进行模块度增益计算的迭代方式转变为从所有邻居节点中随机抽取一个节点j计算δq是否高于阈值,从而进行社群划分,算法的其余步骤不变,后续对比实时线算法结果和离线算法结果,参照离线算法结果对实时线算法结果进行修正,具体包括以下步骤:
[0193]
s4b.1.1对于新增节点i,把新增节点i随机分配到其一个邻居节点所在社区,计算分配前后模块度增量δq,其中,模块度q按照式(1)计算;
[0194]
步骤s4b.1.2若上一步计算得到的δq不大于阈值,则随机选择另外一个邻居节点,返回步骤s4b.1.1,否则,把新增节点i分配到当前邻居节点所在的社区,结束此次划分。
[0195]
本实施例中,构建连通图,并基于上述改进louvain算法获取的划分社区结果具体举例如下表所示:
[0196]
字段字段说明连通图id构建联通图的id团伙id连通图划分社区后的id,用作团伙id节点id实体节点的id节点类型实体节点的类型,如:用户、app设备终端等更新时间计算更新的时间
[0197]
s4.2基于社区交互关系图谱进行刷量团伙及用户角色识别
[0198]
由于黑产会通过注册掌握大量用户账号,在社区中养号,将部分具有不同售卖价值的账号转卖给下游进行定向收割或者根据下游客户定向完成任务等。如养成大v号自称“老师”、“专家”、“股神”,通过各类小号刷任务(批量为定向帖子点赞、评论来置顶帖子增加曝光、批量关注目标用户等)、在股吧中烘托形象及鼓吹其股票,骗取普通股民的信任来实现引流、非法荐股的目的。
[0199]
本发明基于社区交互关系图谱,通过lockinfer算法进行刷量lockstep行为风险团伙检测发现和改进个性化pagerank算法来获取交互关系网络中的用户节点的欺诈传播分值,用于用户角色判定。
[0200]
步骤s4.2具体包括以下步骤:
[0201]
步骤s4.2.1通过lockinfer算法检测刷量行为风险团伙
[0202]
定义s为源节点用户,则s为源节点用户集合,t为目标节点用户,则t为目标节点用
户集合。根据不同场景,源节点用户s及目标节点用户t具体定义如下:
[0203]
1.点赞:s为对帖子进行点赞的用户,t为帖子被点赞的用户;
[0204]
刷量行为:批量点赞的行为;
[0205]
2.评论:s为对帖子进行评论的用户,t为帖子被评论的用户;
[0206]
刷量行为:批量评论的行为;
[0207]
3.刷转发:s为对帖子进行转发操作的用户,t为被转发帖子的用户;
[0208]
刷量行为:批量转发的行为;
[0209]
4.刷关注:s为进行关注订阅操作的用户,t为被关注订阅的用户;
[0210]
刷量行为:批量关注的行为。
[0211]
黑产通过掌握的账号,批量为某个股吧帖子批量点赞、回复、转发等行为增加曝光,或者为某个用户刷量增加粉丝作弊的行为被称为lockstep刷量行为。因此引入lockinfer算法对其进行检测,本根据实际业务场景需求进行了适当了变化,如选择种子节点的策略和在传播过程中删除了和度无关的传播的逻辑,判断当前场景中,传播是和度相关的。
[0212]
在实际作弊场景中,刷量用户为了规避检测会使用各类刷量策略绕过风控,比如:
[0213]
说明1.黑产团伙控制的僵尸粉丝(s)不会全部都关注/回复/.../点赞布置刷量任务的用户(t);会关注/回复/.../点赞部分正常用户、大v用户来伪装自己。
[0214]
说明2.不同黑产团伙之间会存在协同模式,如刷量目标用户(t)将刷量任务分配给多个黑产团伙(s)。
[0215]
说明3.刷量目标用户(t)的粉丝中除了僵尸粉丝外,还会存在通过吸粉手段吸引的部分正常用户。
[0216]
目前可根据lockinfer算法对股吧交互关系中存在lockstep刷量行为的团伙进行检测,具体的算法流程如下:
[0217]
步骤s4.2.1.1选出具有疑似lockstep行为的种子节点组成的种子节点集。
[0218]
lockinfer算法支持随机选取种子节点,但选择合适的种子节点可以加快检测速度,因此根据选取种子节点的策略进行选择,具体包括以下内容:
[0219]
根据如下选取种子节点的策略中的任意一种进行选择:
[0220]
策略1:将业务专家定义筛选的具有对应用户风险画像标签及业务审核结果的用户节点选取为种子节点,进而组成种子节点集;
[0221]
策略2:根据选择种子的算法进行,具体包括以下步骤:
[0222]
步骤s4.2.1.1.1对交互关系图谱进行奇异值分解,基于k-svd算法计算邻接矩阵a的左奇异向量u和右奇异向量v,用左奇异向量u两两组合绘制谱子空间:
[0223]
对每一个对(i,j),1≤i<j≤k,k为k-svd的迭代次数,绘制左奇异向量u
i vsuj的谱子空间,ui为第i次迭代获得的左奇异向量,uj为第j次迭代获得的左奇异向量。
[0224][0225]
步骤s4.2.1.1.2将谱子空间利用霍夫变换从笛卡尔坐标系转化为极坐标系,即对于谱子空间中每一个用户节点u
x
,x≤n,n为用户节点的总个数,有下式(3):
[0226][0227]
式(3)中,笛卡尔坐标(u
i,x
,u
j,x
)转化成极坐标(r
x
,θ
x
),r为极坐标半径,θ为极坐标角度。
[0228]
步骤s4.2.1.1.3绘制节点的r频率和θ频率分布直方图,有下式(4):
[0229][0230]
式(4)中,freq(r)为节点的r频率,freq(θ)为节点的θ频率;
[0231]
步骤s4.2.1.1.3使用中值滤波(median filter)算法检测出上一步所获得的直方图的尖峰,并将尖峰所对应的节点集作为种子节点集;
[0232]
步骤s4.2.1.1.4通过业务经验对种子节点集中的种子节点进行进一步的过滤,获得最终的种子节点集。
[0233]
步骤s4.2.1.2进行lockstep传播:根据上一步选出的种子节点集,在社区交互关系图谱中通过传播lockstep值,检测具有lockstep行为的用户节点,具体算法传播流程如下:
[0234]
步骤s4.2.1.2.1初始化:
[0235]
1.定义种子节点集中的种子节点为第0轮的lockstep刷量行为用户;
[0236]
2.由源节点集合s及目标节点集合t构成m
×
n矩阵(s,t),m≤m,n≤n,社区交互关系图谱的邻接矩阵a的大小为m
×
n;
[0237]
3.最小的lockstep异常密集块规模m
min
×nmin
以及对应的密度阈值其中,密度阈值表示为下式(5):
[0238][0239]
式(5)中,d=d(a)表示邻接矩阵a的密度,当时,则认为矩阵(s,t)(s,t)
是邻接矩阵a中第一个lockstep异常密集块;
[0240]
4.定义时间衰减权重邻接矩阵w=(w
i,j
),则有:
[0241][0242]
式中,γ表示衰减常数,其值表示历史信息衰减的速率,需要考虑有限的历史信息;h为节点i和节点j连接后经过的时间,h=0表示当前关系。
[0243]
步骤s4.2.1.2.2从源节点用户集合s传播lockstep到目标节点用户集合t
[0244]
s-》t:以lockstep刷量用户源节点用户作为种子节点,统计每个目标节点用户关联到的具有lockstep刷量行为源节点用户数(如:目标节点用户被多少具有lockstep刷量行为的源节点用户关注),若比例超过阈值且规模大于n
min
,则标记为具有lockstep刷量行为的目标节点用户,即
[0245]
步骤s4.2.1.2.3从目标节点用户集合t传播lockstep到源节点用户集合s
[0246]
t-》s:统计每个源节点用户关联到的具有lockstep刷量行为目标节点用户数(如:源节点用户关注了多少具有lockstep刷量行为的目标节点用户),若比例超过阈值且规模大于m
min
,则标记为具有lockstep刷量行为的源节点用户,即
[0247]
步骤s4.2.1.2.4重复步骤s4.2.1.2.2及步骤s4.2.1.2.3直至收敛。
[0248]
利用下表示例通过上述步骤获得的结果:
[0249]
字段字段说明团伙id具体的团伙id用户id用户实体节点的idlockstep标记标记lockstep follower/followee的详情lockstep值图传播中获取的lockstep值更新时间计算更新的时间
[0250]
步骤s4.2.2通过改进个性化pagerank算法获取欺诈传播分值
[0251]
pagerank算法是一种通过网页间连接数量和质量来计算网页重要性的技术。在反欺诈场景中,可类比成黑产团伙成员间的连接数量和质量,用于黑产成员重要性分析,从而进一步分析成员在团伙中担任的角色。
[0252]
本发明引入改进个性化pagerank的概念,该类算法的提出用于针对公司偷税漏税的欺诈检测,而未使用到交互关系中检测交互风险团体及用于其交互风险意图的深入分析,判断用户在团伙中的重要性、影响力;进一步挖掘定义风险用户在团伙中承担的角色。
[0253]
社区交互关系图谱的网络结构主要分为两种:单一实体图和二分图,如图2中的图例举例:
[0254]
【用户-用户】则为单一实体图,对应关系选取为:关注。
[0255]
【用户-帖子-用户】则为二分图,存在两种不同的实体,用户、帖子;用户和用户之前是通过帖子间接关联上的。
[0256]
步骤s4.2.2进一步包括以下步骤:
[0257]
步骤s4.2.2.1获得包含两类节点的二分图g=(ν,ε):e(v1,v2)∈ε|v1∈ν1and v2∈ν2,其中,ν表示实体节点,ν1ν2分别表示二分图的两类节点,一类是用户账号实体节点,另一类是用户发帖对应的帖子实体节点;ε表示边,e(v1,v2)表示二分图的两类节点ν1ν2对应的边;
[0258]
本发明中,二分图中分别是两类节点,一类是用户账号id,另一类是用户发帖对应的帖子id。
[0259]
步骤s4.2.2.2通过pagerank算法计算二分图中所有节点的分值,迭代传播过程标识为下式(6):
[0260][0261]
向量和大小均为i+j,向量表示节点对应的pagerank分值,对于用户和帖子的关系而言,为用户和帖子的重启随机游走时被选中的概率。
[0262]
传统的pagerank算法迭代传播过程标识为a表示n
×
m邻接矩阵,本发明的式(7)中由进行列归一化后的对称矩阵q
norm
替换邻接矩阵a,对称矩阵q
norm
通过以下步骤获得:
[0263]
定义时间衰减权重邻接矩阵wn×m=(w
i,j
),由于会存在一种情况,是黑产团伙采用协作模式,在历史的某一个时间段集中的去进行频繁的操作,完全随着时间衰减后对于部分历史区间频繁的活动会损失,因此将时间衰减权重邻接矩阵wn×m=(w
i,j
)定义为下式(8):
[0264][0265]
式(8)中,μ为加权常数,d为时间区间内频发操作的密度;
[0266]
每次重新游走选择在特定节点集合中选择一个节点开始,则有:
[0267][0268]
将时间衰减权重邻接矩阵w
i,j
扩展成(i+j)
×
(i+j)的对称矩阵q:
[0269][0270]
式(9)中,w'i×j表示w
i,j
转置矩阵;
[0271]
将对称矩阵q进行列归一化后得到对称矩阵q
norm
,则迭代传播过程转变为式(7)所示。
[0272]
最终得到的分值可解释为用户节点在团伙中的重要性,即影响力,值越高代表用户节点在团伙中的重要性越高。
[0273]
步骤s4可以概括为:
[0274]
通用关系图谱建图后,通过改进louvain算法模型进行社区划分,发现达到业务约定团体规模大小的团体,再根据用户节点对应的风险标签对整体团体风险进行业务定义,抽象成团体指标来对用户团体进一步进行跟踪;
[0275]
交互关系图谱建图后,通过lockinfer算法模型发现刷量团体进行定向风险分析
与挖掘,并对于有刷量风险的用户进行风险标签标记,并输出整体风险团伙;
[0276]
交互关系图谱建图后,通过改进个性化pagerank算法模型获得pagerank分值来标识其风险传播程度来判断成员在风险传播中的重要性,即风险影响力,进而进一步定义用户在团体中的角色,如;团伙领袖、团伙骨干、团伙成员等。
[0277]
一种可行的示例如下表所示:
[0278][0279][0280]
综合上述各项结果,进行团伙合并及剪枝,刻画团伙风险画像,支持业务系统进一步做业务策略处理,同时将结果数据导入neo4j图数据库来存储,方便业务查询及可视化监控团体演变情况。
[0281]
本发明提供一种基于股票社区关系图谱的交互风险团伙识别方法,具体涉及到股票社区反欺诈风险控制领域的团伙发现技术,与现有技术相比,其优点:
[0282]
(1)把数据采集中获取到关系从其较为单一的实体关系,到可实现支持股票社区股民复杂交互关系网络所暴露体现的欺诈风险的分析与挖掘。
[0283]
(2)在建图时,区分通用关系和交互关系来构建,同时观测用户和终端形成的通用团伙及社区交流互动关系形成的交互团伙,并通过实体节点所构成图结构的差异,进一步通过不同的算法来进行定向的分析与挖掘。
[0284]
(3)不依赖如neo4j等图形算法库提供等原始算法,根据业务场景进行针对性算法
改进来解决稳定性和时效性的平衡,并优化部分项的计算来适配业务模型输出。
[0285]
(4)利用算法及定义相关指标,有效解决当前场景中针对不同风险行为及意图的团伙分析与识别、及团伙中用户担任风险角色的识别,实现业务系统差异化决策处理。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1