一种对抗样本生成方法
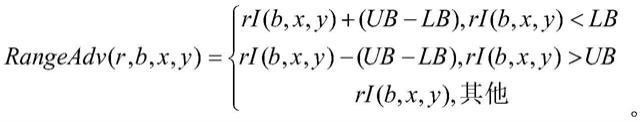
1.本发明属于模式识别技术领域,具体涉及一种对抗样本生成方法。
背景技术:
2.深度神经网络是强大和流行的学习模型,在很多计算机视觉、语音和语言处理任务中实现了最先进的模式识别性能。然而这些网络也容易受到精心设计的对抗性干扰的影响,这些干扰会导致输入的错误分类,对抗性示例是对手破坏预期的系统行为,导致不希望的结果,并可能在这些系统部署到现实世界时造成安全风险。
3.基于对目标网络对抗知识的不同假设,针对对抗攻击的研究主要有两个方向。第一个方向,假设对手对网络架构和训练(或访问标记训练集)产生的参数有详细的了解。对手利用这个信息对给定的图像构造一个扰动,最有效的方法是基于梯度的。第二个方向是,对手限制了对网络的知识,使其不能仅在某些探测输入上观察网络的输出。这种黑盒模型是一种更加现实和适用的威胁模型,但它也更具有挑战性,因为它考虑的是不了解网络架构、参数或训练数据的弱小对手。
技术实现要素:
4.本发明所要解决的技术问题是克服现有技术的不足,提供一种对抗样本生成方法,提取图像中的关键像素点,对其邻域进行扰动,通过贪婪局部搜索方法,构造微小扰动,从而实现图像的错误分类。
5.本发明提供一种对抗样本生成方法,包括如下步骤,
6.步骤s1、输入图像i,对图像进行标准化,标准化图像与原始图像尺寸相同,图像标准化之后的所有坐标均在[lb,ub]范围内,lb和ub为两个常数,且lb<0,ub>0;用t∈r
l
×w×h表示满足上述性质的所有有效图像的空间;对于每个i∈τ,图像中的所有坐标满足(b,x,y)∈[l]
×
[w]
×
[h],i(b,x,y)∈[lb,ub];
[0007]
步骤s2、分类标签为c(i)∈{1,...,c},p和r为扰动系数,图像邻域搜索半径的边长为2d,最大迭代次数为r,每次迭代选择的像素点的个数为t;
[0008]
步骤s3、随机选取10%的像素,初始化集合(p
x
,py),(p
x
,py)i为一组像素位置;第一轮(p
x
,py)0为随机生成的;在随后的每一轮中,均是基于在前一轮中被扰动的一组像素位置形成的;让(p
x
,py)
i-1
表示i-1轮中被扰动区域的中间像素位置,则
[0009]
步骤s4、遍历(p
x
,py)的像素,进行扰动prer(i,p,x,y),获取新的图像集合;
[0010]
扰动的方法为petr(i,p,x,y)=p
×
sign(i(*,x,y)),其中,sign是符号函数,定义为
[0011]
步骤s5、计算新图像集合中每个图像预测原分类标签的概率score(i);选择概率
最大的t个像素点,获取新的像素点集合(p
x
,py);遍历(p
x
,py),对(x,y)∈(p
x
,py)的邻域,进行扰动rangeadv(r,b,x,y),更新原始图像i;范围扰动方法为
[0012]
步骤s6、若则攻击成功,结束;否则,定义攻击的模型为nn,nn的分类结果为:nn(i)=(o1,...,oc),其中oi为图像识别为第i个标签的概率;π(nn(i
p
),k)为模型nn针对图像i的分类的topk个标签;
[0013]
步骤s7、遍历(p
x
,py),以每个像素点为中心,画出边长为2d的正方形,正方形范围内的点都纳入(p
x
,py),转步骤s4。
[0014]
作为本发明的进一步技术方案,从(p
x
,py)集合中随机选择最多128个点,遍历每个点,针对每个点进行扰动并生成一个新的图像,获取一个新图像集合;对新图像集合中的每个图像进行计算,获取分类为原标签的概率值。
[0015]
进一步的,数据标准化之后所有坐标均在[-0.5,0.5]之间。
[0016]
本发明的优点在于,
[0017]
1.对抗攻击的通用性。
[0018]
2.适用于多种目标识别网络,即无需考虑网络架构。
[0019]
3.具有较高的可用性,通过添加微小的扰动,造成图像目标识别失败。
[0020]
4.降低寻找关键像素点的轮数,通过对关键像素点及其邻域添加扰动,能快速实现图像的分类错误。
[0021]
5.根据模型的反馈信息去选择扰动的点,并随即选择对分类结果影响大的点周围的点,进一步进行扰动分析。
附图说明
[0022]
图1为本发明的方法流程示意图。
具体实施方式
[0023]
请参阅图1,本实施例提供本发明一种对抗样本生成方法,包括如下步骤,
[0024]
步骤s1、输入图像i,对图像进行标准化,标准化图像与原始图像尺寸相同,图像标准化之后的所有坐标均在[lb,ub]范围内,lb和ub为两个常数,且lb<0,ub>0;用t∈r
l
×w×h表示满足上述性质的所有有效图像的空间;对于每个i∈τ,图像中的所有坐标满足:(b,x,y)∈[l]
×
[w]
×
[h],i(b,x,y)∈[lb,ub];
[0025]
步骤s2、分类标签为c(i)∈{1,...,c},p和r为扰动系数,图像邻域搜索半径的边长为2d,最大迭代次数为r,每次迭代选择的像素点的个数为t;
[0026]
步骤s3、随机选取10%的像素,初始化集合(p
x
,py),(p
x
,py)i为一组像素位置;第一轮(p
x
,py)0为随机生成的;在随后的每一轮中,均是基于在前一轮中被扰动的一组像素位置形成的;让(p
x
,py)
i-1
表示i-1轮中被扰动区域的中间像素位置,则
[0027]
步骤s4、遍历(p
x
,py)的像素,进行扰动prer(i,p,x,y),获取新的图像集合;
[0028]
扰动的方法为petr(i,p,x,y)=p
×
sign(i(*,x,y)),其中,sign是符号函数,定义为
[0029]
步骤s5、计算新图像集合中每个图像预测原分类标签的概率score(i);选择概率最大的t个像素点,获取新的像素点集合(p
x
,py);遍历(p
x
,py),对(x,y)∈(p
x
,py)的邻域,进行扰动rangeadv(r,b,x,y),更新原始图像i;范围扰动方法为
[0030]
步骤s6、若则攻击成功,结束;否则,定义攻击的模型为nn,nn的分类结果为:nn(i)=(o1,...,oc),其中oi为图像识别为第i个标签的概率;π(nn(i
p
),k)为模型nn针对图像i的分类的topk个标签;
[0031]
步骤s7、遍历(p
x
,py),以每个像素点为中心,画出边长为2d的正方形,正方形范围内的点都纳入(p
x
,py),转步骤s4。
[0032]
该方法具体如下,
[0033]
1.首先定义了标准化和逆标准化函数,为了处理方便,将数据标准化到[-0.5,0.5]之间。
[0034]
标准化函数:
[0035]
normalize(im):
[0036]
im=im
–
(min_+max_)/2
[0037]
im=im/(max_-min_)
[0038]
lb=-1/2
[0039]
ub=1/2
[0040]
return im,lb,ub
[0041]
逆标准化函数:
[0042]
unnormalize(im)
[0043]
im=im*(max_-min_)
[0044]
im=im+(min_+max_)/2
[0045]
return im
[0046]
adv_img,lb,ub=normalizez(adv_img)。
[0047]
2.随机选取一部分像素点,总数不超过全部的10%,最大个数不超过128个。
[0048]
random_locations():
[0049]
n=int(0.1*h*w)
[0050]
n=min(n,128)
[0051]
locations=np.random.permutation(h*w)[:n]
[0052]
p_x=locations%w
[0053]
p_y=location//w
[0054]
pxy=list(zip(p_x,p_y))
[0055]
pxy=np.array(pxy)
[0056]
returnpxy
[0057]
实现扰动函数rangeadv
[0058]
rangeadv(r,ibxy):
[0059]
result=r*ibxy
[0060]
ifresult.any()《lb:
[0061]
result=result+(ub-lb)
[0062]
elseifresult.any()》ub:
[0063]
result=result
–
(ub-lb)
[0064]
result=result.clip(lb,ub)
[0065]
returnresult
[0066]
初始化图像以及(p
x
,py)集合。
[0067]
ii=adv_img
[0068]
pxpy=random_locations()。
[0069]
3.从(p
x
,py)集合中随机选择最多128个点,遍历每个点,针对每个点进行扰动并生成一个新的图像,得到一个新图像集合。对新图像集合。对新图像结合中的每个图像进行计算,得到分类为原标签的概率值。
[0070]
fortry_timeinrange(r):
[0071]
#重新排序,随机选择不超过128个点
[0072]
pxpy=pxpy[np.random.permutation(len(pxpy))[:128]]
[0073]
l=[pert(ii,p,x,y)forx,yinpxpy]
[0074]
#批量返回预测结果,获取原始图像标签的概率
[0075]
defscore(its):
[0076]
its=np.stack(its)
[0077]
its=unnormalize(its)
[0078]
scores=[self.model.predict(unnormalize(ii))[original_label]foritinits]
[0079]
returnscores。
[0080]
4.选择影响力最大的t个点组成新的(p
x
,py)集合,np.argsort返回的是升序排序,因此需要取倒数t个。
[0081]
scores=scores[l]
[0082]
indices=np.argsort(scores)[:-t]
[0083]
pxpy_star=pxpy[indeces]。
[0084]
5.遍历(p
x
,py)集合,同时在原始图像上扰动。
[0085]
针对新生成的图片进行预测,如果分类标签发生变化即说明攻击成功,反之继续。更新(p
x
,py)集合,以每个像素点作为中心,画出边长为2d的正方形,正方形范围内的点都纳
入集合(p
x
,py)。
[0086]
pxpy=[(x,y)for_a,_binpxpy_star]
[0087]
forxinrange(_a
–
d,_a+d+1)
[0088]
foryinrange(_b
–
d,_b+d+1)]
[0089]
pxpy=[(x,y)forx,yinpxpyif0《=x《wand0《=y《h]
[0090]
pxpy=list(set(pxpy))
[0091]
pxpy=np.narry(pxpy)。
[0092]
以上显示和描述了本发明的基本原理、主要特征和优点。本领域的技术人员应该了解,本发明不受上述具体实施例的限制,上述具体实施例和说明书中的描述只是为了进一步说明本发明的原理,在不脱离本发明精神范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护的范围由权利要求书及其等效物界定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1