一种基于表情和语音双模态的儿童情感识别算法的制作方法
1.本发明涉及情感识别,具体涉及一种基于表情和语音双模态的儿童情感识别算法。
背景技术:
2.儿童的情绪有着各种各样的表达方式,如语音、表情、姿态、动作等,我们可以从中提取有效信息,进行正确分析。而语音和表情信息最为其中最为明显和最容易分析的特征,得到了广泛的研究和应用。心理学家mehrabian给出了一个公式:情感表露=7%的言辞+38%的声音+55%的面部表情,可见人的语音和表情信息涵盖93%的情感信息,是交流信息中的核心。在情绪表达的过程中,通过面部表情变化能够有效且直观地表达出内心情感,是情感识别最为重要的特征信息之一,语音特征同样也能表达出丰富的情感。
3.传统的单模态识别可能存在单一情感特征不能很好地表征情感状态的问题,例如,在表达悲伤的情感时,面部表情可能没有较大变化,但此时可以从低沉、低缓的语音特征中分辨出悲伤失落的情绪。多模态识别使得不同模态间的信息能够互补,为情感识别提供更多信息,提高情感识别的准确率。
4.但目前,单模态情感识别研究较为成熟,针对多模态的情感识别方法还有待发展和完善。因此,多模态情感识别具有十分重要的实际应用意义,而作为最为显性的语音特征、表情特征,基于二者的双模态情感识别具有重要的研究意义和应用价值。在传统双模态情感识别中,采用加权方法忽略了各特征对于情感识别的贡献度,不利于对情感进行准确地判断识别。
技术实现要素:
5.(一)解决的技术问题
6.针对现有技术所存在的上述缺点,本发明提供了一种基于表情和语音双模态的儿童情感识别算法,能够有效克服现有技术所存在的不能对情感进行准确判断识别的缺陷。
7.(二)技术方案
8.为实现以上目的,本发明通过以下技术方案予以实现:
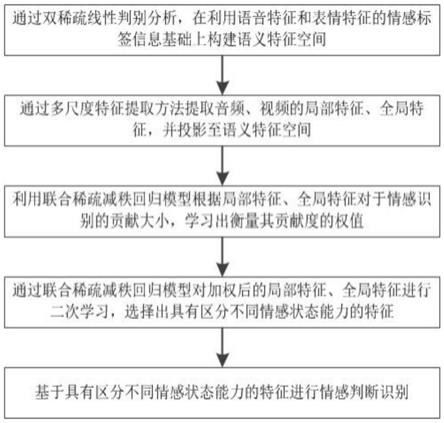
9.一种基于表情和语音双模态的儿童情感识别算法,利用语音特征和表情特征的情感标签信息构建语义特征空间,通过多尺度特征提取方法提取音频、视频的局部特征、全局特征,并将音频、视频的局部特征、全局特征投影至语义特征空间,语义特征空间从中选择出对情感分类具有贡献的重要特征,进行情感判断识别。
10.优选地,所述通过多尺度特征提取方法提取音频的局部特征,包括:
11.以预设采样周期对音频进行采样,得到各音频帧,并对各音频帧进行傅里叶变化,得到语谱图;
12.对输出门卷积神经网络进行模型训练,利用训练好的输出门卷积神经网络对语谱图进行特征提取,得到音频的局部特征。
13.优选地,所述输出门卷积神经网络包括多个卷积层,每一个卷积层后连接一个对应的池化层,所述池化层用于在时域和/或频域进行降采样,各池化层在时域上的总降采样率小于在频域上的总降采样率。
14.优选地,所述语谱图的横坐标为音频帧对应的时间,所述语谱图的纵坐标为音频帧对应的频谱值。
15.优选地,所述通过多尺度特征提取方法提取视频的局部特征,包括:
16.利用卷积层对图像进行提取得到特征图,通过rpn网络对特征图进行进行目标检测与精确定位,得到候选区,并通过fastr-cnn网络中的roi pooling层对候选区进行最大池化,输出一组包括多个维度相同的视频局部特征。
17.优选地,所述通过rpn网络对特征图进行进行目标检测与精确定位,得到候选区,包括:
18.通过rpn网络对特征图进行卷积计算,得到尺度变换后的特征图;
19.利用softmax函数对尺度变换后的特征图中的锚框进行分类,得到含有目标物体的前景候选区;
20.计算尺度变换后的特征图中锚框的边框回归偏移量,得到精确候选区;
21.基于前景候选区、精确候选区得到预候选区,并基于nms剔除尺寸较小以及超出边界的预候选区,得到候选区。
22.优选地,所述通过fast r-cnn网络中的roi pooling层对候选区进行最大池化,包括:
23.将精确候选区映射到特征图的对应位置,在特征图上得到映射后的精确候选区;
24.将映射后的精确候选区划分为多个大小相同的子窗口,并对每个子窗口进行最大池化,得到一组包括多个维度相同的视频局部特征。
25.优选地,所述通过多尺度特征提取方法提取音频、视频的全局特征,包括:
26.将多组音频局部特征、视频局部特征分别进行dac特征融合,使得类内的相关性最大化、类间的相关性最小,分别得到音频、视频的全局特征。
27.优选地,所述语义特征空间通过双稀疏线性判别分析,在利用语音特征和表情特征的情感标签信息基础上构建而成,所述双稀疏线性判别分析在将音频、视频的局部特征、全局特征投影至语义特征空间的过程中,根据语音、表情的特征对情感分类的贡献,从音频、视频的局部特征、全局特征中选择重要特征。
28.优选地,所述语义特征空间从中选择出对情感分类具有贡献的重要特征,进行情感判断识别,包括:
29.利用联合稀疏减秩回归模型根据局部特征、全局特征对于情感识别的贡献大小,学习出衡量其贡献度的权值,并且通过联合稀疏减秩回归模型对加权后的局部特征、全局特征进行二次学习,选择出具有区分不同情感状态能力的特征。
30.(三)有益效果
31.与现有技术相比,本发明所提供的一种基于表情和语音双模态的儿童情感识别算法,通过双稀疏线性判别分析,在利用语音特征和表情特征的情感标签信息基础上构建语义特征空间,通过多尺度特征提取方法提取音频、视频的局部特征、全局特征,并投影至语义特征空间,利用联合稀疏减秩回归模型根据局部特征、全局特征对于情感识别的贡献大
小,学习出衡量其贡献度的权值,并且通过联合稀疏减秩回归模型对加权后的局部特征、全局特征进行二次学习,选择出具有区分不同情感状态能力的特征,从而能够根据特征对于情感识别的贡献度确定对应权值,并且能够基于具有区分不同情感状态能力的特征对情感进行准确判断识别。
附图说明
32.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
33.图1为本发明的流程示意图。
具体实施方式
34.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
35.一种基于表情和语音双模态的儿童情感识别算法,如图1所示,利用语音特征和表情特征的情感标签信息构建语义特征空间,通过多尺度特征提取方法提取音频、视频的局部特征、全局特征,并将音频、视频的局部特征、全局特征投影至语义特征空间,语义特征空间从中选择出对情感分类具有贡献的重要特征,进行情感判断识别。
36.语义特征空间通过双稀疏线性判别分析,在利用语音特征和表情特征的情感标签信息基础上构建而成,双稀疏线性判别分析在将音频、视频的局部特征、全局特征投影至语义特征空间的过程中,根据语音、表情的特征对情感分类的贡献,从音频、视频的局部特征、全局特征中选择重要特征。
37.语义特征空间从中选择出对情感分类具有贡献的重要特征,进行情感判断识别,包括:
38.利用联合稀疏减秩回归模型根据局部特征、全局特征对于情感识别的贡献大小,学习出衡量其贡献度的权值,并且通过联合稀疏减秩回归模型对加权后的局部特征、全局特征进行二次学习,选择出具有区分不同情感状态能力的特征。
39.本技术技术方案中,利用用联合稀疏减秩回归模型能够根据特征对于情感识别的贡献度确定对应权值,并对加权后的局部特征、全局特征进行二次学习,选择出具有区分不同情感状态能力的特征,从而能够基于具有区分不同情感状态能力的特征对情感进行准确判断识别。
40.通过多尺度特征提取方法提取音频的局部特征(即儿童的语音特征),包括:
41.以预设采样周期对音频进行采样,得到各音频帧,并对各音频帧进行傅里叶变化,得到语谱图;
42.对输出门卷积神经网络进行模型训练,利用训练好的输出门卷积神经网络对语谱图进行特征提取,得到音频的局部特征。
43.语谱图的横坐标为音频帧对应的时间,语谱图的纵坐标为音频帧对应的频谱值。
44.输出门卷积神经网络包括多个卷积层,每一个卷积层后连接一个对应的池化层,池化层用于在时域和/或频域进行降采样,各池化层在时域上的总降采样率小于在频域上的总降采样率。
45.其中,每一个卷积层包括至少两层,前层的输出作为后层的输入,每一层包括第一通道和第二通道,所述第一通道和所述第二通道分别采用不同的非线性激活函数,第一通道的非线性激活函数为双曲函数tanh,第二通道的非线性激活函数为s型函数sigmoid。
46.通过多尺度特征提取方法提取视频的局部特征(即儿童的表情特征),包括:
47.利用卷积层对图像进行提取得到特征图,通过rpn网络对特征图进行进行目标检测与精确定位,得到候选区,并通过fastr-cnn网络中的roi pooling层对候选区进行最大池化,输出一组包括多个维度相同的视频局部特征。
48.其中,通过rpn网络对特征图进行进行目标检测与精确定位,得到候选区,包括:
49.通过rpn网络对特征图进行卷积计算,得到尺度变换后的特征图;
50.利用softmax函数对尺度变换后的特征图中的锚框进行分类,得到含有目标物体的前景候选区;
51.计算尺度变换后的特征图中锚框的边框回归偏移量,得到精确候选区;
52.基于前景候选区、精确候选区得到预候选区,并基于nms剔除尺寸较小以及超出边界的预候选区,得到候选区。
53.其中,通过fast r-cnn网络中的roi pooling层对候选区进行最大池化,包括:
54.将精确候选区映射到特征图的对应位置,在特征图上得到映射后的精确候选区;
55.将映射后的精确候选区划分为多个大小相同的子窗口,并对每个子窗口进行最大池化,得到一组包括多个维度相同的视频局部特征。
56.本技术技术方案中,在通过多尺度特征提取方法提取音频的局部特征、视频的局部特征后,还需要获取关于音频、视频的全局特征。
57.通过多尺度特征提取方法提取音频、视频的全局特征,包括:
58.将多组音频局部特征、视频局部特征分别进行dac特征融合,使得类内的相关性最大化、类间的相关性最小,分别得到音频、视频的全局特征。
59.以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不会使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1