一种基于深度学习的三维点云数据压缩方法与系统
1.本发明涉及点云数据压缩处理技术领域,尤其涉及一种基于深度学习的三维点云数据压缩方法与系统。
背景技术:
2.点云模型分割是鲁棒目标识别的关键,对机器人自主、自动驾驶等具有重要意义。目前,maturana等人提出了一种有效的点云分割架构,该架构通过将容积占用网格来实现3d目标识别。相反,由于不必要的冗长,qi等人提出了一种局部处理每个点的统一架构,以提高形状分割的效率,并且对输入点的排列不变性具有鲁棒性。landrieu等人用超点图来表示三维形状分割,超点图是将大尺度点云场景分割成几何均匀的元素。brostow等人提出了一种三维形状语义分割的算法,通过将5个3d索引投射回二维图像平面,从而对运动点云的空间布局和环境进行建模。
3.现有的三维网格压缩方法大多基于几何结构,由于其格式不规则,大多数研究人员将这些数据转换为规则的三维体素网格或图像,以便于通过深度学习其中的卷积操作进行权值共享、优化kernel参数等。但是,这会使得数据变得不必要的庞大,并导致一些问题。
4.目前对三维点云模型的压缩研究有很多不同的技术,如小波变换、图变换和层次变换。在该领域,研究人员还开发了有效和高效的3d动画压缩方法。与静态形状相比,这些方法通过研究运动的时间冗余和表面的空间冗余,提高了压缩效率。
5.综上所述,目前技术方案能够实现点云压缩,但是压缩效率仍然是目前国内研究的方向。
6.公开号为cn1110135227a,名为“一种基于机器学习的激光点云室外场景自动分割方法”的中国专利公开了一种利用基于三维卷积神经网络计算特征向量,结合代价函数进行迭代压缩数据的方法。但是本发明基于pointnet神经网络进行语义分割,再利用八叉树算法来实现点云数据的压缩。
技术实现要素:
7.针对背景技术中存在压缩效率不高的具体问题,提供一种基于深度学习的三维点云数据压缩方法与系统,通过结合具有语义标记的三维模型,计算出与基于语义的标准模型的最优对齐,再使用八叉树算法进行压缩,从而使得八叉树编码性能更优越,提高压缩效率。
8.为了实现上述目的,本发明采用的技术方案包括以下各方面。
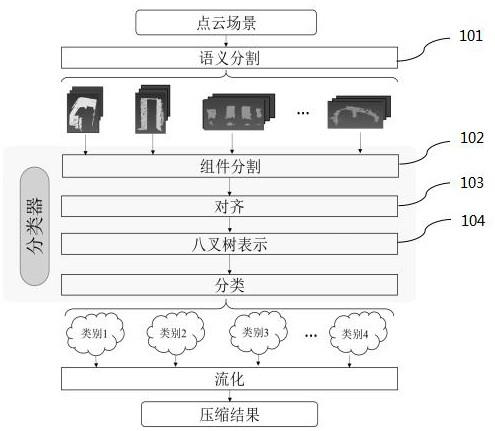
9.一种基于深度学习的三维点云数据压缩方法,包括:步骤101,通过pointnet神经网络对输入的点云数据模型进行语义分割,得到基于语义标记的语义组合模型;步骤102,基于所述语义组合模型进行组件分割得到单个项目;步骤103,基于所述单个项目,计算与基于语义的标准模型的最优对齐,再对点云
数据进行组织排序,得到有序的点云数据模型;步骤104,基于所述有序的点云数据模型利用八叉树表示法获取点云数据模型的空间特征,结合所述空间特征计算三维物体分类,对每个类内的项目进行流化处理实现压缩。
10.优选的,一种基于深度学习的三维点云数据压缩方法中,步骤102具体包括:采用基于密度的非参数聚类算法对所述语义组合模型进行组件分割,以分离成单个项目。
11.优选的,一种基于深度学习的三维点云数据压缩方法中,于,所述基于密度的非参数聚类算法采用mean-shift算法。
12.优选的,一种基于深度学习的三维点云数据压缩方法中,步骤103具体还包括采用迭代最近点算法,将单个项目与基于语义的标准模型对齐。
13.优选的,一种基于深度学习的三维点云数据压缩方法中,所述基于语义的标准模型为自动从每个语义集中选择具有中等数量点的对象优选的,一种基于深度学习的三维点云数据压缩方法中,步骤103具体还包括:采用kd-tree 算法对点云数据进行组织排序。
14.优选的,一种基于深度学习的三维点云数据压缩方法中,步骤104具体还包括:根据所述空间特征表示,用混合层评价来计算所有单个项目的分类,基于分类再对每个类内的项目进行流化处理。
15.优选的,一种基于深度学习的三维点云数据压缩方法中,步骤104具体还包括:采用k-means聚类算法对所述点云数据模型进行三维物体分类,实现将具有相似八叉树结构空间特征的点云数据归为同组。
16.一种基于深度学习的三维点云数据压缩系统,包括:语义分割模块,用于基于pointnet神经网络对输入的点云数据模型进行语义分割,得到基于语义标记的语义组合模型;组件分割模块,用于基于所述语义组合模型进行组件分割得到单个项目;最优对齐模块,用于基于所述单个项目,计算与基于语义的标准模型的最优对齐,再对点云数据进行组织排序,得到有序的点云数据模型;八叉树编码模块,用于基于所述有序的点云数据模型利用八叉树表示法获取点云数据模型的空间特征,结合所述空间特征计算三维物体分类,对每个类内的项目进行流化处理实现压缩。
17.综上所述,由于采用了上述技术方案,本发明至少具有以下有益效果:本发明提供一种基于深度学习的三维点云数据压缩方法与系统,首先基于深度网络技术计算输入的大尺度三维模型的语义标记得到语义组合模型。其次,将语义组合模型分解为单个项目,并计算出与标准对象的最优对齐,再使用八叉树表示法得到空间特征,基于空间特征来计算分类,最后完成对每个类内的项目进行流处理实现压缩。这种三维点云数据压缩方法与系统,利用语义分类提高了八叉树的编码性能,进一步减小了数据冗余,从而提升压缩效率。
附图说明
18.图1是根据本发明示例性实施例的基于语义分类的大规模三维点云场景流建模流
程图;图2为根据本发明示例性实施例的基于“椅子”标记的语义组合模型图;图3为根据本发明示例性实施例的两个基于“椅子”标记的单个项目图与基于语义的标准模型;图4为根据本发明示例性实施例的基于分级八叉树结构的分类流图;图5为根据本发明示例性实施例的基于有无语义分类的率失真曲线对比图;图6为根据本发明示例性实施例的具有41,353,055个点在不同细节层次上的大尺度点云模型流图;图7为根据本发明示例性实施例的使用提议的模型对椅子(顶部)和room2(底部)数据的渐进流图;图8为根据本发明示例性实施例的基于pointnet神经网络模型的压缩系统;图中标记:100-语义分割模块,200-组件分割模块,300-最优对齐模块,400-八叉树编码模块。
具体实施方式
19.下面结合附图及实施例,对本发明进行进一步详细说明,以使本发明的目的、技术方案及优点更加清楚明白。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
20.实施例1本发明基于深度学习的三维点云数据压缩方法,所述基于语义分类的大规模三维点云场景流模型如图1所示,包括如下步骤:步骤101,通过pointnet神经网络对输入的点云数据模型进行语义分割,得到基于语义标记的语义组合模型:具体的,应用一种经典的基于深度网络的技术来计算输入的大尺度三维模型的语义标记,设大比例尺三维模型为m,其中m = {pi|i = 1,2,
···
,n}, n为点数。对每个顶点pi进行语义标注,可表示为:其中t为语义类的个数。
21.使用语义标记,我们获得了包含一组具有相似拓扑的项的语义组合模型,进一步来说,通过对点云数据模型进行基于“椅子”标记的语义分割得到语义组合模型,其中点云数据模型都具有“椅子”拓扑结构,但是在颜色、大小、方向、等方面具有差异,即如图2所示。
22.步骤102,基于所述语义组合模型进行组件分割得到单个项目。
23.具体的,通过进一步分离语义组合模型来研究冗余。本发明采用mean-shift算法作为基于密度的非参数聚类算法进行分割,以分离得到基于语义标记的单个项目。将带有“椅子”标记的语义组合模型进行组件分割,得到基于“椅子”标记的单个模型,即如图3所示的单个椅子,从左到右分别为单个椅子1、单个椅子2、椅子标准模型。
24.语义组合模型被分割成s个单个项目,可表示为:其中,mj为一个语义集;cj为类别数,其受计算点与当前中心之间的最大距离r的影响。
25.步骤103,基于所述单个项目,计算与基于语义的标准模型的最优对齐,并对点云数据进行组织,得到有序的点云数据模型。
26.具体的,由于语义相同的单个项目之间是存在差异的,不利于减少空间冗余。为了减少空间冗余,将语义下的单个项目与基于语义的标准模型对齐。如图3所示,单个椅子与椅子标准模型的最优对齐,即以椅子标准模型的颜色、大小、方向为对齐条件,将具有相似颜色、大小、方向的单个椅子1、2向标准模型对齐。
27.本发明采用icp算法,具体算法如下:在语义相同的单个项目下,用表示空间的第一个点集,第二个点集的对齐匹配变换为使下式的目标函数最小:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)其中,为目标点集,即单个项目;为参考点集,即基于语义的标准模型;r为旋转系数,t为平移系数。
28.icp算法的实质是基于最小二乘法的最优匹配算法,它重复进行“确定对应关系点集-计算最优刚体变换”的过程,目的是找到目标点集与参考点集之间的旋转r和平移t变换,其中对于所述刚性变换采用四元数方法进行处理。可以理解为,通过计算刚性变换矩阵,反复搜索单个项目与基于语义的标准模型之间的最近点,同时计算返回一个匹配错误。这个过程一直重复,直到某个表示正确匹配的收敛条件得到满足。在接下来的步骤中,所有的模型都不执行视差操作。
29.优选的,基于语义的标准模型为自动从每个语义集中选择具有中等数量点的对象。
30.具体的,由于三维点云数据较庞大,我们基于kd-tree (k维树)对点云数据进行组织排序,所述kd-tree是一种带有其他约束条件的二分查找树,用来组织表示 k 维空间中点集合。其节点用(a,v)值对表示,其中a是当前的划分维度,v是划分值。在k维的数据空间中,(a,v)形成一个k-1维的超平面,利用该超平面对数据空间进行划分,将多维空间划分为a值小于v的子空间和a值大于等于v的子空间,其中a选用k个维度中方差最大的维度。
31.kd树可以用来建立多维空间数据集或数据块的索引。利用kd树进行数据查询时,每一步结点的条件判断只要比较其中的一个维,因此通过交替比较不同维的属性值,可以快速查找某个数据点的邻域,不需要知道数据之间的任何拓扑关系,以此得到有序的点云数据模型,以优化八叉树编码的效率。
32.步骤104,基于所述有序的点云数据模型利用八叉树表示法获取点云数据模型的
空间特征,结合所述空间特征计算三维物体分类,对每个类内的项目进行流化处理实现压缩。
33.具体的,使用八叉树表示点云数据模型,可以通过记录一个非叶节点的8个子节点的节点属性来表示输入点云模型,其中每个非叶节点被转换为8位二进制数据,得到基于八叉树层次结构的语义分类,如图4所示。再对八叉树进行分层遍历,得到一维向量:其中,l为展开层。通过确定八叉树的具体层,可以将八叉树编码扩展到不同的级别。因此,给定一个特定的层,每个节点代表所有盒子内的点,如表1所示,时间单位为秒。
34.表1具体的,基于所述八叉树层次结构点云数据模型,计算单个项目的空间特征分类,得到不同的基于语义标签单个项目的混合分类项目。为了提高压缩效果,进一步的探索所有混合分类项目之间的最大空间冗余:其中,w表示八叉树每一层的权值,底层的权值为1,上层每一层的权值乘以8。f2的输出是各单个项目的混合层值。
35.其中,利用k-means聚类算法将具有相似八叉树空间结构的单个项目归同组。k-means聚类算法是在密度参数的基础上,利用欧氏距离来计算数据模型的密度参数,获取所有的密度参数之后,获取k个中心,如果数据对象a到k个中心具有相同的距离,此时排序簇中数据对象到a的密度距离,选择最小的密度距离并将a归至对应的类中,这就可以使数据对象与邻近的数据对象变得更加紧凑,从而实现将具有相似八叉树空间结构的数据对象归为相同的组。
36.最后,可以实现数据的流逐渐增加八叉树的层数,使得点云数据展示出来就越精细,因此可以观察到大量点云数据模型轮廓的细节,如图6、图7所示,通过增加八叉树的层数,得到从左到右基于颜色和轮廓更加清晰的数据模型。
37.同时,语义分割对八叉树表示的编码性能的影响,通过实验数据中可以看出,语义分割明显提高了八叉树的编码性能,如图5所示,在适当的压缩比范围内,同一压缩比的条件下,没有进行最优对齐数据的均方误差高于对齐后数据的均方误差。也就是说,在相同的速率下,我们可以获得更低的均方误差,这是因为语义分割已经进一步探索了点云模型中各个项目中的冗余。
38.本发明还提供一种基于深度学习的三维点云数据压缩系统。图8示意性地示出了
基于深度学习的三维点云数据压缩系统的结构图,具体包括:语义分割模块,用于基于pointnet神经网络对输入的点云数据模型进行语义分割,得到基于语义标记的语义组合模型;组件分割模块,用于基于所述语义组合模型进行组件分割得到单个项目;最优对齐模块,用于基于所述单个项目,计算与基于语义的标准模型的最优对齐,再对点云数据进行组织排序,得到有序的点云数据模型;八叉树编码模块,用于基于所述有序的点云数据模型利用八叉树表示法获取点云数据模型的空间特征,结合所述空间特征计算三维物体分类,对每个类内的项目进行流化处理实现压缩。
39.所述语义分割模块100对输入的点云数据模型基于pointnet神经网络进行语义分割,输出具有语义标记的数据模型至组件分割模块200;所述组件分割模块200对点云数据进行基于语义标记的组件分割,输出多个基于语义的单个项目;所述最优对齐模块300包括,一方面作用于所述单个项目所具有的差异导致的空间冗余,一方面对点云数据模型进行初步空间排序,输出有序的点云数据模型;所述八叉树编码模块400,对所述有序的点云数据模型进行基于八叉树空间结构的分层遍历,最后经过八叉树结构分类得到场景编码。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1