一种高镍锍浮选过程建模中的数据样本筛选及重构方法与流程
1.本发明涉及高镍锍浮选工艺数据建模技术领域,更具体的是涉及高镍锍浮选过程建模中的数据样本筛选及重构方法技术领域。
背景技术:
2.高镍锍浮选工艺是镍冶炼过程中的重要步骤,目的是对火法加工后的镍-铜人工矿进行进一步分离。高镍硫浮选过程的复杂性导致目前未能由准确的解析模型可以用来指导生产。为提高浮选品位和产率,有必要对浮选过程进行建模,并用模型来指导生产并进行优化。
3.因为实际浮选过程的复杂性,建模方法只能采用基于数据的建模方法,又由于系统参数之间存在较大的时滞性,因此采用循环神经网络(rnn)是一种比较适当的方法。
4.由于浮现工艺过程的复杂性,实时工况数据中多存在突变、为零、不更新等状况,从建模角度来讲这些数据都为无效数据。根据实际工况的规则对无效数据进行剔除后,实时工况数据在时间上变得不连续。这样的数据无法直接作为样本进行数据建模,必须要进行数据重构。重构后的数据可以直接作为样本对模型进行训练。
技术实现要素:
5.本发明的目的在于提出一种高镍锍浮选过程建模中的数据样本筛选及重构方法,以解决背景技术中提出的问题。
6.本发明为了实现上述目的具体采用以下技术方案:
7.一种高镍锍浮选过程建模中的数据样本筛选及重构方法,包括如下步骤:
8.步骤1:根据高镍锍浮选工艺过程实际状况,确定每个单独的浮选柱参数变化影响最终品位的滞后时间长度,选取系统滞后参数p,并按照此参数进行数据重组;
9.步骤2:以系统滞后参数p作为系统许可的滞后时间最大值,从零开始按照一定时间间隔取多个不同值作为系统滞后时间,分别进行建模,以模型精度来选择最优的系统滞后时间,选取均方根误差来评判模型精度;
10.步骤3:辨识标记出用于建模的数据中的无效数据,所述无效数据包括数据为空、数据不变、数据突变;
11.步骤4:按照整个滞后时间内的所有输入参数和当前时间输出参数关联的方式构建一个样本,对无效数据筛除后的不连续数据集合进行有效性抽样,能够满足样本范围内为有效数据的抽取为一个样本,构建相互独立的样本数据集,对抽取出的样本进行矩阵重组,进行rnn建模,将rnn模型本身的输入滞后和输出滞后参数都设置为零。
12.步骤1中所述系统滞后参数p为系统分析过程得出的一个包含时间冗余的参数。
13.步骤3中所述无效数据包括生产启停阶段数据。
14.综上所述,由于采用了上述技术方案,本发明的有益效果是:
15.本发明根据高镍锍实际工况对数据进行预处理,剔除掉无效数据,得到在时间上
不连续的一些数据块。解决了由于浮现工艺过程的复杂性,实时工况数据中多存在突变、为零、不更新等状况,在建模过程中这些数据都为无效数据,如果根据实际工况的规则对无效数据进行剔除后,实时工况数据在时间上又变得不连续,这样的数据无法直接作为样本进行数据建模的技术问题。本发明通过对数据样本筛选重构再进行rnn建模,重构后的数据可以直接作为样本对模型进行训练,适应了系统的长时滞特征,提高了高镍锍浮选工艺浮选品位和产率。
附图说明
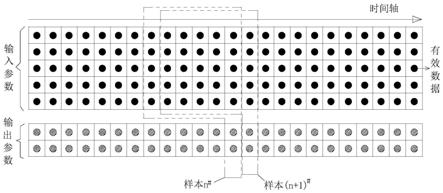
16.图1为本发明连续时间数据样本抽取方法示意图;
17.图2为本发明时间不连续数据集合时数据筛选方法示意图;
18.图3为本发明的独立样本示意图。
具体实施方式
19.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。
20.因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
21.实施例
22.本实施例提供一种高镍锍浮选过程建模中的数据样本筛选及重构方法,包括如下步骤:
23.步骤1:根据高镍锍浮选工艺过程实际状况,确定每个单独的浮选柱参数变化影响最终品位的滞后时间长度,选取系统滞后参数p,并按照此参数进行数据重组;
24.步骤2:系统滞后参数p为系统分析过程得出的一个包含时间冗余的参数,为降低计算规模,提高建模计算效率,以系统滞后参数p作为系统许可的滞后时间最大值,从零开始按照一定时间间隔取多个不同值作为系统滞后时间,分别进行建模,以模型精度来选择最优的系统滞后时间,选取均方根误差来评判模型精度;
25.步骤3:辨识标记出用于建模的数据中的无效数据,所述无效数据包括数据为空、数据不变、数据突变,生产启停阶段数据无法反映正常工作状况,因此结合生产记录将启停阶段数据也全部标记为“无效”;
26.步骤4:按照整个滞后时间内的所有输入参数和当前时间输出参数关联的方式构建一个样本,对无效数据筛除后的不连续数据集合进行有效性抽样,能够满足样本范围内为有效数据的抽取为一个样本,构建相互独立的样本数据集,对抽取出的样本进行矩阵重组,进行rnn建模,将rnn模型本身的输入滞后和输出滞后参数都设置为零。
27.本发明具体的操作如下:如图1-3所示,选取模型输入参数n,系统滞后时间p,样本数量k,则重组后的矩阵为n
×
p
×
k矩阵。
28.具体的,用于建模的数据首先辨识出数据为空(数据采集系统未采集到数据)、数据不变(传感器未更新数据)、数据突变(非正常工作状态)、生产启停阶段数据,将这些时段数据标记为“无效”,特别说明只要有某一数据无效,则该时刻所有数据无法用于建模,都被标记为无效。启停阶段数据无法反映正常工作状况,因此结合生产记录将启停阶段数据也全部标记为“无效”。
29.此时有效的实时数据在时间轴上是不连续的,下面就是独立样本抽取过程。
30.按照时间顺序,以rnn输入滞后时间p为长度读取实时数据,如果在该时间间隔内数据都为有效,则这段时间的所有输入参数和最后时刻的输出参数被抽取出来形成一个独立样本。数据继续往后走一个时间间隔,如果数据仍然有效,则取这个时刻之前p内的所有输入参数和当前输出参数作为第二个独立样本。以此类推。
31.在此过程中,遇到输入参数有无效状况,直接跳过。当出现输出参数有效时,开始计数,如果往后p时间间隔中所有输入参数有效,且p时刻输出参数也有效,同样开始独立样本的抽取。如果计数过程中出现输入参数无效值,计数停止,当所有输入参数有效时,重新开始计数。
32.如果遇到输出参数为无效状况,直接跳过。当输出参数变成有效时,检查当前时刻之前p时间内输入参数是否有效。如果有效,则将当前时刻前p时间内输入参数和当前时刻的输出参数抽出为独立样本,如果无效,继续往前所搜,在每一次输出参数有效的情况都所搜当前时刻之前p时间内的输入参数是否有效。
33.所有抽出的独立样本重新组成矩阵形式,用于rnn建模,并将rnn输入滞后和输出滞后都设置为零。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1