1.本发明属于数字信息的传输技术领域,具体涉及为一种云端的混合分布式文件存储方法。
背景技术:2.云端存储服务多数使用分布式文件存储系统作为后端存储系统,用户上传的文件,如文档文件、图像文件或音乐文件,通常小于10mb。因此,云存储中的大多数文件为小于10mb的小文件。占少是的大文件,例如电影、操作系统映像文件,通常大于1gb。因此,我们可以假设,大部分的文件为小文件,只有少受10%~20%的文件,为大文件,云端存储的文件分布类似于重尾分布。
3.随着云端存储服务的普及,写入吞吐量可能成为云服务的瓶颈。而如果要充分提升云端存储的写入吞吐量,充分利用重尾分布至关重要。尚未有利用文件的重尾分布,来提升云端写入吞吐量的研究方案。
技术实现要素:4.针对现有技术的不足,本发明提供了一种云端的混合分布式文件存储方法。
5.为实现以上目的,本发明通过以下技术方案予以实现。
6.一种云端的混合分布式文件存储方法,包括以下步骤:步骤1,至少一个云端服务器安装有ssbox,且所有云端服务器的ram内存都在ceph和hdfs之间共享,且云端服务器的硬盘被划分为两个大小相等的分区,一个用于ceph,另一个用于hdfs;步骤2,根据待写入的文件大小对待写入的文件进行初步分类;测量ceph和hdfs对不同大小的文件所花费的写入时间,然后确定分隔点α和β:当文件大小小于α时,hdfs的写入时间超过ceph,且两者的写入时间差异性为5%,此时ceph为优选;当文件大小大于β时,ceph的写入时间超过hdfs,且两者的写入时间差异性为5%,此时hdfs为优选;将文件大小小于α的待写入的文件分配给ceph,将文件大小大于β的待写入的文件分配给hdfs;文件大小介于α和β之间的文件,进入下一步处理;步骤3,文件大小介于α和β之间的待写入的文件,使用knn方法预测该文件更适合于哪种分布式文件系统。
7.进一步,步骤1中,ssbox使用hdfs api将数据写入hdfs,并使用posix将数据写入ceph;数据存储位置将记录于数据库postgresql。
8.进一步,步骤2中,α为500mb,β为800mb。
9.进一步,步骤3中,knn方法如下:1) 获取k个近邻样本点;2) 初始化所有分类的样本点个数为0;
3) 统计k个近邻样本点中各个分类的样本点的数量;4) 确定所有分类中样本点数量的最大值和最小值;5) 统计未知样本属于各个分类的概率。
10.进一步,一种云端的混合分布式文件存储方法,还包括步骤4,ram内存和并行写入机制:在ram内存中缓存大于40mb的大文件,并通过并行写入进行管理,将ram内存中缓存的文件分配到ceph或hdfs中。
11.与现有技术相比,本发明具备以下有益效果:本方案,针对大量的小文件和小量的大文件,采用不同的分布式文件存储方法,混合了hdfs和ceph两种文件存储系统并整合到云端存储系统ssbox中,用以提升系统的效能。具体的,通过文件大小的预处理、利用k
‑
nearest neighbors方法来改进文件分配决策、ram内存和并行写入机制,将文件适应性地分配到ceph或者hdfs中,致力于提升读写性能。模拟显示,本方案的混合分布式文件存储方法,在写入吞吐量上比单纯的ceph和hdfs高出大约两倍的写入吞吐量。
附图说明
12.图1为数据组1的文件吞吐量趋势图;图2为数据组2的文件吞吐量趋势图。
具体实施方式
13.下面将结合附图,对本发明的技术方案进行清楚、完整地描述。
14.ceph是一个分布式文件系统,支持对象存储、块存储、文件存储,同时加入了复制和容错功能,避免单点故障,使用副本实现容错。ceph更适合大量小文件。
15.hdfs是一个分布式文件系统,具有高容错性的特点,提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。hdfs更适合少量大文件。
16.ssbox是一个类似于drophox的系统,提供从saas到paas的服务,主要由nginx、memcached、postgresql、servercore和ceph组成,可以作为公有云或者私有云的解决方案。
17.一种云端的混合分布式文件存储方法,包括以下步骤:步骤1,至少一个云端服务器安装有ssbox,且所有云端服务器的ram内存都在ceph和hdfs之间共享,且云端服务器的硬盘被划分为两个大小相等的分区,一个用于ceph,另一个用于hdfs;ssbox使用hdfs api将数据写入hdfs,并使用posix将数据写入ceph;数据存储位置将记录于数据库postgresql。
18.步骤2,根据待写入的文件大小对待写入的文件进行初步分类。
19.测量ceph和hdfs对不同大小的文件所花费的写入时间,然后确定分隔点α和β:当文件大小小于α时,hdfs的写入时间超过ceph,且两者的写入时间差异性为5%,此时ceph为优选;当文件大小大于β时,ceph的写入时间超过hdfs,且两者的写入时间差异性为5%,此时hdfs为优选。
20.因此,将文件大小小于α的待写入的文件分配给ceph,将文件大小大于β的待写入的文件分配给hdfs;文件大小介于α和β之间的文件(包含点α和点β),进入下一步处理。
21.通过实验模拟,得到α为500mb,β为800mb。
22.步骤3,文件大小介于α和β之间的待写入的文件,使用knn方法预测该文件更适合于哪种分布式文件系统。
23.为了将文件很好地分配到ceph或hdfs中,以提升写入性能。本方案除了利用直观的方法来确定文件的分配之外,还利用k
‑
nearest neighbors方法(以下简称knn方法)来改进文件的分配决策。
24.knn方法是一种非参数惰性学习方法。非参数学习方法,对其底层数据分布不做任何假设,更符合现实,因为现实数据通常不会映射到任何理论数据。惰性学习方法,是一种不预先对训练数据进行泛化的学习方法,不做任何模型训练,训练时间开销为零。
25.knn方法的思路:如果一个样本在特征空间中的k个最近邻(最相似)的样本中的大多数都属于某一个类别,则该样本也属于这个类别。
26.1) 获取k个近邻样本点;2) 初始化所有分类的样本点个数为0;3) 统计k个近邻样本点中各个分类的样本点的数量;4) 确定所有分类中样本点数量的最大值和最小值;5) 统计未知样本属于各个分类的概率(0
‑
1之间)。
27.通过knn方法来进行分类,是本领域的常用分类手段,例如公开号cn104063472a的中国专利公开的《一种优化训练样本集的knn文本分类方法》。因此,不再赘述。
28.步骤4,ram内存和并行写入机制。在ram内存中缓存大于40mb的大文件,并通过并行写入进行管理,将ram内存中缓存的文件分配到ceph或hdfs中。
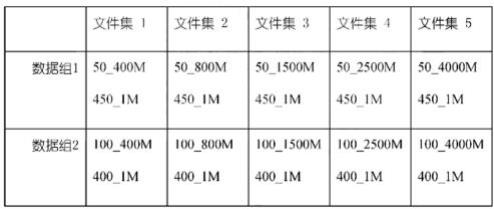
29.通过步骤1和步骤2,混合分布式文件存储方法的写入吞吐量已经比单一的ceph或hdfs高出1.5倍左右。
30.由于可利用的ram内存越多,可以实现的写入吞吐量就越大。引入ram内存和并行机制后,将写入吞吐量提升到原始ceph或hdfs的1.5倍到2倍。
31.利用ram内存作为缓存的开销,包括文件写入ram内存和从ram内存读取文件的时间。此外,文件可以在ram内存并行读取以及并行写入hdfs。
32.文件大小40mb~120mb之间的文件在ceph的写入时间可能几乎两倍于ram内存写入时间。
33.当多个文件上传到云存储系统ssbox,如果拥有足够的ram内存空间(例如100g),则在ram内存中缓存大文件,并通过并行写入进行管理。
34.将大文件缓存于ram内存,而不是小文件,其原因如下:1.将大文件写入ram内存比写入hdfs或ceph快10倍甚至20倍,写入ram内存之后,可以将文件从ram内存并行写入hdfs。这种情况下,虽然ram内存中缓存文件可能会产生一些开销,但是,可以通过多线程将文件写入hdfs来减轻负担。
35.2.小文件(大约小于40mb)写入ceph的时间,比写入ram内存同时并行写入ceph或hdfs更短。
36.为了验证本方案,建立一个包含五个quanta节点的集群。quanta是一个开源社交媒体平台。每个节点都是一台配备有20个intel cpu内核和qdr infiniband(40gbps)的服务器。所有磁盘都在ceph和hdfs之间共享。硬盘被划分为两个大小相等的分区,一个用于ceph,另一个用于hdfs。ssbox将部署于其中一个节点中,ssbox使用hdfs api将数据写入
hdfs,并使用posix将数据写入ceph。数据存储位置将记录于数据库postgresql。
37.创建10个文件集,并在本地和ssbox两种环境下进行模拟实验,因此,有两个数据组,分别对应本地和ssbox两种环境。每个数据组包含5个文件集。这10个文件集,包含了500个文件,其中包含了一些大文件和一些小文件。每个文件的大小是随机的。所有文件包含不同的内容。
38.表1为10个文件集的组成表。
39.图1为数据组1的文件吞吐量趋势图。图2为数据组2的文件吞吐量趋势图。hlr表示混合分布式文件存储方法,hsr表示混合分布式文件存储以及ram内存和并行写入。从图1中可见,ceph和hdfs所对应的写入吞吐量因为不同的文件集而出现严重的波动。也就是说,ceph和hdfs的写入吞吐量对文件的大小很敏感。从图1中可见,hlr和hsr均要优于ceph和hdfs。
40.然后,hsr在两个数据组中的第一个文件集具有非常高的吞吐量,约为900mb/s,大约是ram内存写入时间的一半。第一个文件集的大多数大文件都可以被ceph访问。
41.接着,hsr在两个数据组中的第五个文件集的吞吐量出现下降的现象。这是因为ram内存的大小已经不足以存储所有大文件。当大文件很大时,ram内存只能允许缓存小文件,而小文件对于并行写入并没有什么优势。因此,当文件集由一些非常大的文件组成时,hsr的写入吞吐量是呈下降的趋势。
42.最后,hsr的最佳应用场景是第三个文件集。该文件集的大文件在800mb到2gb。原因是ceph需要较长的时间来写入大文件。随着大文件大小的增加,hlr的写入吞吐量会接近于hdfs。
43.此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。