一种基于变异粒子群的云计算资源态势预测方法及系统
1.本发明涉及云计算技术领域,特别是涉及一种基于变异粒子群的云计算资源态势预测方法及系统。
背景技术:
2.云计算是整合大量云端计算资源,在短时间内完成对亿万量级的数据进行处理并返回给用户的新兴计算模型,由于其具有低成本和灵活性高等优点使之具有强大的发展潜力。但由于云环境资源负载的动态性,在计算过程中会尽可能多的分配资源来保证服务的稳定性,导致服务器资源过多的闲置和浪费。态势预测技术通过采集历史数据,利用模型来对未来资源趋势进行预测。通过态势预测可以更好的为资源分配提供依据,避免大规模资源空闲引发浪费。目前的预测方法主要包括统计模型、神经网络以及组合模型。
3.基于统计模型进行预测,由于其计算速度快,系统占用负担小,导致实现起来较为容易,但相对预测精度较低误差较大。基于神经网络预测,相比于统计模型提高了预测精度,但仍存在模型复杂和求解速度慢等问题。基于组合模型预测包括以下现有方法,集成模型优化神经网络云资源需求预测方法,该方法可以根据需求对资源进行合理预测,但是当需求并行出现,预测实时性有待提高;基于卷积神经网络与支持向量机的云资源预测模型,该模型的预测精度明显高于现阶段的云资源预测方法,但该模型随着时间增加预测精度会随之降低;基于平均模型与长短期记忆神经网络组合预测模型,该模型降低了资源实时预测的误差,但该模型针对于实时预测的精度较低;基于粒子群对神经网络模型进行优化的方法,具有简单容易实现,收敛速度快等特点,但利用粒子群算法存在容易陷入局部最优解等问题。
技术实现要素:
4.有鉴于此,本发明提供了一种基于变异粒子群的云计算资源态势预测方法及系统,提高预测精度和收敛速度,以解决云计算资源负载资源闲置,资源分配不合理以及资源利用率低等问题。
5.为实现上述目的,本发明提供了如下方案:
6.一种基于变异粒子群的云计算资源态势预测方法,包括:
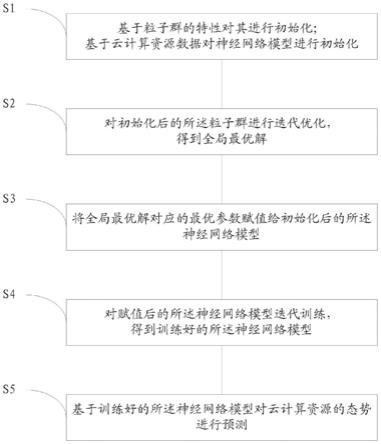
7.基于粒子群的特性对其进行初始化;基于云计算资源数据对神经网络模型进行初始化;
8.对初始化后的所述粒子群进行迭代优化,得到全局最优解;
9.将全局最优解对应的最优参数赋值给初始化后的所述神经网络模型;
10.对赋值后的所述神经网络模型迭代训练,得到训练好的所述神经网络模型;
11.基于训练好的所述神经网络模型对云计算资源的态势进行预测。
12.优选地,所述基于粒子群的特性对其进行初始化;基于云计算资源数据对神经网络模型进行初始化,包括:
13.基于所述粒子群的特性对所述粒子群的数量、惯性权重、学习参数和最大迭代次数进行初始化;
14.采用随机数对所述粒子群的全局最优位置、个体最优位置和个体最优速度进行初始化;
15.基于云计算资源数据对神经网络模型进行初始化。
16.优选地,所述对初始化后的所述粒子群进行迭代优化,得到全局最优解,包括:
17.对所述粒子群进行迭代优化,并获取当前迭代的惯性权重,进一步得到当前迭代的粒子速度;
18.基于当前迭代的所述粒子速度更新当前迭代的粒子位置;
19.基于当前迭代的所述粒子位置得到当前迭代的适应度值;
20.判断当前迭代的次数是否达到最大迭代次数,若没有达到,则继续迭代优化,若达到,则选取最优的所述适应度值为所述全局最优解,输出最优的所述适应度值对应的所述粒子位置。
21.优选地,所述对赋值后的所述神经网络模型迭代训练,得到训练好的所述神经网络模型,包括:
22.基于训练数据集对赋值后的所述神经网络模型迭代训练;将训练数据集输入赋值后的所述神经网络模型,计算所述训练数据集与样本的欧氏距离;
23.基于径向基函数对所述欧氏距离进行非线性变换,得到非线性数据集;
24.对所述非线性数据集和权重系数集进行相乘得到输出数据集;
25.判断当前迭代次数是否达到最大迭代次数,若达到,则得到训练好的所述神经网络模型,若没有达到,则继续进行迭代训练,直至达到最大迭代次数。
26.本发明还提供了一种基于变异粒子群的云计算资源态势预测系统,包括:
27.初始化模块,基于粒子群的特性对其进行初始化;基于云计算资源数据对神经网络模型进行初始化;
28.优化模块,对初始化后的所述粒子群进行迭代优化,得到全局最优解;
29.赋值模块,将全局最优解对应的最优参数赋值给初始化后的所述神经网络模型;
30.训练模块,对赋值后的所述神经网络模型迭代训练,得到训练好的所述神经网络模型;
31.预测模块,基于训练好的所述神经网络模型对云计算资源的态势进行预测。
32.优选地,所述初始化模块包括:
33.第一初始化单元,基于所述粒子群的特性对所述粒子群的数量、惯性权重、学习参数和最大迭代次数进行初始化;
34.第二初始化单元,采用随机数对所述粒子群的全局最优位置、个体最优位置和个体最优速度进行初始化;
35.第三初始化单元,基于云计算资源数据对神经网络模型进行初始化。
36.优选地,所述优化模块包括:
37.迭代计算单元,对所述粒子群进行迭代优化,并获取当前迭代的惯性权重,进一步得到当前迭代的粒子速度;
38.粒子位置单元,基于当前迭代的所述粒子速度更新当前迭代的粒子位置;
39.粒子适应度单元,基于当前迭代的所述粒子位置得到当前迭代的适应度值;
40.第一判断单元,判断当前迭代的次数是否达到最大迭代次数,若没有达到,则返回至所述迭代计算单元,若达到,则选取最优的所述适应度值为所述全局最优解,输出最优的所述适应度值对应的所述粒子位置。
41.优选地,所述训练模块包括:
42.迭代训练单元,基于训练数据集对赋值后的所述神经网络模型迭代训练;将训练数据集输入赋值后的所述神经网络模型,计算所述训练数据集与样本的欧氏距离;
43.非线性单元,基于径向基函数对所述欧氏距离进行非线性变换,得到非线性数据集;
44.输出单元,对所述非线性数据集和权重系数集进行相乘得到输出数据集;
45.第二判断单元,判断当前迭代次数是否达到最大迭代次数,若达到,则得到训练好的所述神经网络模型,若没有达到,则返回至所述迭代训练单元。
46.根据本发明提供的具体实施例,本发明公开了以下技术效果:
47.本发明涉及一种基于变异粒子群的云计算资源态势预测方法及方法,所述方法包括:基于粒子群的特性对其进行初始化;基于云计算资源数据对神经网络模型进行初始化;对初始化后的所述粒子群进行迭代优化,得到全局最优解;将全局最优解对应的最优参数赋值给初始化后的所述神经网络模型;对赋值后的所述神经网络模型迭代训练,得到训练好的所述神经网络模型;基于训练好的所述神经网络模型对云计算资源的态势进行预测。本发明提高了预测精度和收敛速度,解决了由于云计算资源负载资源闲置,导致的资源分配不合理和资源利用率低等问题。
附图说明
48.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
49.图1为本发明基于变异粒子群的云计算资源态势预测方法流程图;
50.图2为本发明柯西分布函数图像示意图;
51.图3为本发明径向基函数神经网络模型结构图;
52.图4为本发明基于变异粒子群的云计算资源态势预测系统结构图。
53.符号说明:1-初始化模块,2-优化模块,3-赋值模块,4-训练模块,5-预测模块。
具体实施方式
54.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
55.本发明的目的是提供一种基于变异粒子群的云计算资源态势预测方法及系统,提高预测精度和收敛速度,以解决云计算资源负载资源闲置,资源分配不合理以及资源利用
率低等问题。
56.为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
57.图1为本发明基于变异粒子群的云计算资源态势预测方法流程图。如图1所示,本发明提供了一种基于变异粒子群的云计算资源态势预测方法,包括:
58.步骤s1,基于粒子群的特性对其进行初始化;基于云计算资源数据对神经网络模型进行初始化。
59.具体地。所述步骤s1包括:
60.步骤s11,基于所述粒子群的特性对所述粒子群的数量、惯性权重、学习参数和最大迭代次数进行初始化。
61.步骤s12,采用随机数对所述粒子群的全局最优位置、个体最优位置和个体最优速度进行初始化。
62.步骤s13,基于云计算资源数据对神经网络模型进行初始化。
63.步骤s2,对初始化后的所述粒子群进行迭代优化,得到全局最优解。
64.进一步地,所述步骤s2包括:
65.步骤s21,对所述粒子群进行迭代优化;
66.步骤s22,获取当前迭代次数的惯性权重,进一步得到当前迭代的粒子速度。所述惯性权重的计算公式为:
[0067][0068]
式中:ω为惯性权重,ω
min
为惯性权重的最小值,取0.4,ω
max
为惯性权重的最大值,取0.9,f为当前迭代次数的适应度函数值,f
avg
为适应度函数值的平均值,f
min
为适应度函数值的最小值。
[0069]
所述粒子速度的计算公式为:
[0070][0071]
为第j次迭代第i个粒子的速度,i∈n,j∈g,n为粒子的总数量,g为最大迭代次数,c1和c2为学习参数,pbest
j-1
为第j-1次迭代的最优粒子位置,gbest为第j次迭代之前的最优粒子位置,即为第j次迭代之前所有迭代优化中的最优粒子位置,rand(0,1)为(0,1)之间的随机数,为第j-1次迭代第i个粒子的位置,为收敛因子,c=c1+c2,当c1=c2=2.05时,此时粒子群具有最好的收敛性能。
[0072]
步骤s23,基于当前迭代的所述粒子速度更新当前迭代的粒子位置。计算公式如下:
[0073][0074]
式中:为第j次迭代第i个粒子的位置,cauchy(0,1)为柯西分布函数生成的(0,
1)之间的随机数,柯西分布函数如图2所示。
[0075]
步骤s24,基于当前迭代的所述粒子位置得到当前迭代的适应度值。具体为:将当前迭代的所述粒子位置赋值给初始化后的所述神经网络模型,初始化后的所述神经网络模型基于输入的训练数据集得到预测值,基于所述预测值和真实值得到所述适应度值。计算公式如下:
[0076][0077]
式中:ej为第j次迭代的适应度值,为粒子群第j次迭代神经网络模型第i个位置的真实值,为粒子群第j次迭代神经网络模型第i个位置的预测值。
[0078]
步骤s25,判断当前迭代的次数是否达到最大迭代次数,若没有达到,则返回至“步骤s21”,若达到,则选取最优的所述适应度值为所述全局最优解,输出最优的所述适应度值对应的所述粒子位置。
[0079]
步骤s3,将全局最优解对应的最优参数赋值给初始化后的所述神经网络模型。具体为根据节点数目依次将所述粒子位置赋值给所述神经网络模型。本实施例中,所述神经网络模型采用径向基函数神经网络模型,包括输入层,隐藏层和输出层,其结构如图3所示。
[0080]
步骤s4,对赋值后的所述神经网络模型迭代训练,得到训练好的所述神经网络模型。
[0081]
优选地,所述步骤s4包括:
[0082]
步骤s41,将所述训练数据集输入赋值后的所述神经网络模型,计算所述训练数据集与样本的欧氏距离。
[0083]
步骤s42,基于径向基函数对所述欧氏距离进行非线性变换,得到非线性数据集。计算公式如下:
[0084][0085]
式中:r(x
p-cq)为训练数据集中第p个值x
p
对应的非线性值,p∈m,m为训练数据集中数据的总数量,exp为以自然常数e为底的指数函数,σ为隐藏节点常数,cq为隐藏节点高斯函数的中心量。
[0086]
步骤s43,对所述非线性数据集和权重系数集进行相乘得到输出数据集。
[0087]
计算公式如下:
[0088][0089]
式中:ω
p
为隐藏节点对应输出层的权重系数。
[0090]
步骤s44,判断当前迭代次数是否达到最大迭代次数,若达到,则得到训练好的所述神经网络模型,若没有达到,则返回至“步骤s41”。
[0091]
步骤s5,基于训练好的所述神经网络模型对云计算资源的态势进行预测。
[0092]
图4为本发明基于变异粒子群的云计算资源态势预测系统结构图。如图所示,本发明提供了一种基于变异粒子群的云计算资源态势预测系统,包括:初始化模块1、优化模块
2、赋值模块3、训练模块4和预测模块5。
[0093]
所述初始化模块1基于粒子群的特性对其进行初始化;基于云计算资源数据对神经网络模型进行初始化。
[0094]
所述优化模块2对初始化后的所述粒子群进行迭代优化,得到全局最优解。
[0095]
所述赋值模块3将全局最优解对应的最优参数赋值给初始化后的所述神经网络模型。
[0096]
所述训练模块4对赋值后的所述神经网络模型迭代训练,得到训练好的所述神经网络模型。
[0097]
所述预测模块5基于训练好的所述神经网络模型对云计算资源的态势进行预测。
[0098]
作为一种可选的实施方式,本发明所述初始化模块1包括:第一初始化单元、第二初始化单元和第三初始化单元。
[0099]
所述第一初始化单元基于所述粒子群的特性对所述粒子群的数量、惯性权重、学习参数和最大迭代次数进行初始化。
[0100]
所述第二初始化单元采用随机数对所述粒子群的全局最优位置、个体最优位置和个体最优速度进行初始化。
[0101]
所述第三初始化单元基于云计算资源数据对神经网络模型进行初始化。
[0102]
作为一种可选的实施方式,本发明所述优化模块2包括:迭代计算单元、粒子位置单元、粒子适应度单元和第一判断单元。
[0103]
所述迭代计算单元对所述粒子群进行迭代优化,并获取当前迭代的惯性权重,进一步得到当前迭代的粒子速度。
[0104]
所述粒子位置单元基于当前迭代的所述粒子速度更新当前迭代的粒子位置。
[0105]
所述粒子适应度单元基于当前迭代的所述粒子位置得到当前迭代的适应度值。
[0106]
所述第一判断单元判断当前迭代的次数是否达到最大迭代次数,若没有达到,则返回至所述迭代计算单元,若达到,则选取最优的所述适应度值为所述全局最优解,输出最优的所述适应度值对应的所述粒子位置。
[0107]
作为一种可选的实施方式,本发明所述训练模块4包括:迭代训练单元、非线性单元、输出单元和第二判断单元。
[0108]
所述迭代训练单元基于训练数据集对赋值后的所述神经网络模型迭代训练;将训练数据集输入赋值后的所述神经网络模型,计算所述训练数据集与样本的欧氏距离。
[0109]
所述非线性单元基于径向基函数对所述欧氏距离进行非线性变换,得到非线性数据集。
[0110]
所述输出单元对所述非线性数据集和权重系数集进行相乘得到输出数据集;
[0111]
所述第二判断单元判断当前迭代次数是否达到最大迭代次数,若达到,则得到训练好的所述神经网络模型,若没有达到,则返回至所述迭代训练单元。
[0112]
本发米昂通过引入自适应调整粒子群参数,增加粒子群的搜索空间,避免粒子群容易陷入局部最优解,并将训练得到的参数应用到径向基函数神经网络模型上进行进一步的优化,防止传统随意选取参数会引起的预测精度低和泛化能力不佳等问题。将优化后的模型运用到云计算环境中,通过云计算历史的数据预测未来资源的发展趋势,对资源进行合理分配,避免资源浪费。
[0113]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0114]
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1