一种动态转储文档数据的系统的制作方法
1.本发明涉及电数字数据处理的技术领域,特别涉及一种动态转储文档数据的系统。
背景技术:
2.随着社会信息化的不断深入发展,信息化服务逐渐进入了细分领域,同时也涌现出一大批优质的、细分领域的数据服务提供商,他们在各自的细分领域内通过不断的深挖和提炼,沉淀下了很多非常有价值的数据。
3.对于大量资源整合型的企业,为了给客户提供更优质的服务,需要尽可能多的接入外部优质的数据,如何高效且低成本的接入这些数据是这些企业需要考虑的。
4.现有技术中,接入数据用的最多的是类似kettled的这类ktl工具,当然,投入开发力量一个个编码实现接入也是一种常见的选择;前者一般由数据工程师才能操作,一般规模的公司不具备这样的能力,且比较笨重,如果接入量不大的话,投入性价比过低,而后者采用编码的方式则显得非常不灵活,且由于成本高、开发周期长,一般情况下是无法满足一个公司的快速发展战略的。
技术实现要素:
5.本发明解决了现有技术中存在的问题,提供了一种优化的动态转储文档数据的系统,以实现快速且低成本的接入外部数据的能力。
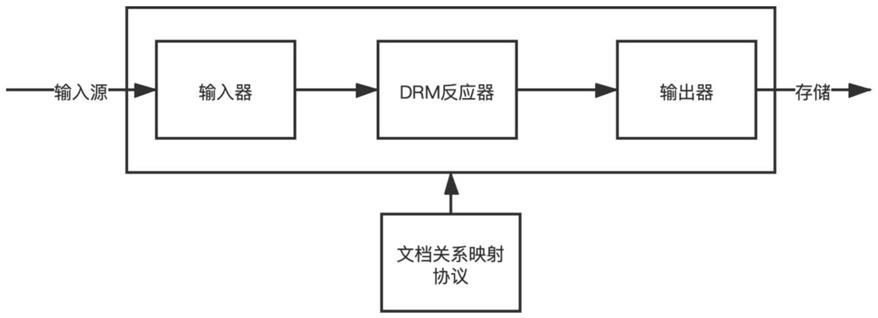
6.本发明所采用的技术方案是,一种动态转储文档数据的系统,所述系统包括顺次连接的输入器、drm反应器和输出器,配合所述系统设置有文档关系映射协议,用于定义文档数据至数据库数据的映射关系。
7.优选地,所述输入器为可扩展,所述输入器的个数对应输入源的个数设置。
8.优选地,配置所述输入器为双星通配模式或多值匹配模式或多变量解析模式或loop循环配置模式。
9.优选地,所述输入器的操作步骤为:a.1 加载输入器相关配置;a.2 构建http请求对象;a.3 请求api结构;a.4 若校验请求接收成功,则进行下一步,否则结束;a.5 转换请求结果为drm反应器支持的数据格式,发送数据至drm反应器,结束。
10.优选地,所述文档关系映射协议为树形结构,包括作为根节点的drm节点,配合所述drm节点设有第一级的子矩阵节点和兄弟矩阵节点,配合任一所述第一级的子矩阵节点和兄弟矩阵节点套设有下一级的子矩阵节点和兄弟矩阵节点;任一级的子矩阵节点和兄弟矩阵节点为1个或多个。
11.优选地,所述drm反应器的操作步骤为:
步骤b.1 加载drm协议配置;步骤b.2 获得输入器发送的预设格式的数据;步骤b.3 以递归且深度优先的方式遍历并转化文档;步骤b.4 输出树形数据矩阵至输出器。
12.优选地,所述步骤b.3包括以下步骤:步骤b.3.1 开始drm对象,根据drm中的文档属性配置,从文档获取文档数据对象;步骤b.3.2 若文档数据对象为集合对象,则遍历数据集合,执行转化子流程,进行下一步,否则,直接进行下一步;步骤b.3.3 根据drm中的矩阵格属性配置,将数据对象转化成矩阵行对象;步骤b.3.4 判断是否存在子矩阵集合,若是,则遍历处理子矩阵drm,返回步骤b.3.1,否则进行下一步;步骤b.3.5 判断是否存在兄弟矩阵集合,若是,则遍历处理兄弟矩阵drm,返回步骤b.3.1,否则结束。
13.优选地,所述输出器为可扩展,所述输出器的个数对应存储方式的个数设置。
14.优选地,所述输出器的操作步骤为:步骤c.1 读入输出器配置;步骤c.2 判断用于存储的数据库是否已创建连接,若否,则初始化数据库连接,进行下一步,否则直接进行下一步;步骤c.3 读入drm反应器处理后的矩阵数据树;步骤c.4 预处理,检查数据库状态并完成数据库表的创建;开启数据库事务;步骤c.5 以递归且深度优先的方式按行遍历矩阵;步骤c.6 若发生异常,则回滚数据库事务,否则提交数据库事务,完成。
15.优选地,所述步骤c.5包括以下步骤:步骤c.5.1 判断矩阵是否为空,若是则结束,否则进行下一步;步骤c.5.2 根据矩阵数据行内的唯一键,在数据库中查找数据;若数据不存在,则进行步骤c.5.4,否则判断是否重建;步骤c.5.3 若重建,则生成删除数据库数据的语句并进行缓存,填入矩阵中该行的唯一键的值,生成可执行语句并执行,进行下一步,否则判断是否更新,若不更新则结束,若更新则记录数据id值并缓存父对象,生成更新数据库数据的语句并做缓存,填入矩阵中该行的唯一键的值,生成可执行的语句并执行,进行步骤c.5.6;步骤c.5.4 生成新增数据库数据的语句并进行缓存;步骤c.5.5 遍历矩阵行中的所有格,将值注入填入新增对象,执行新增sql,并将获取的记录id逐个缓存到父对象;步骤c.5.6 判断是否存在子矩阵集合,若是,则返回步骤c.5.1,否则进行下一步;步骤c.5.7 判断是否存在兄弟矩阵集合,若是,则返回步骤c.5.1,否则结束。
16.本发明涉及一种优化的动态转储文档数据的系统,顺次连接设置输入器、drm反应器和输出器,以配合系统的文档关系映射协议定义文档数据至数据库数据的映射关系,设计原理简单,配置灵活,可扩展性好。
17.本发明实现将现有技术中复杂、低效的编码接入工作转变成简单高效的配置接入
工作的功能,极大提升系统接入外部数据服务的效率,降低成本,整体的实现成本也较低,特别适用于需要控制研发成本的中小型企业。
附图说明
18.图1为本发明的系统结构图;图2为本发明的输入器的操作步骤流程图;图3为本发明中文档关系映射示意图;图4为本发明的drm反应器的操作步骤流程图;图5为本发明中步骤b.3的流程图;图6为本发明的输出器的操作步骤流程图;图7为本发明的步骤c.5的流程图。
具体实施方式
19.下面结合实施例对本发明做进一步的详细描述,但本发明的保护范围并不限于此。
20.如图1所示,本发明涉及一种动态转储文档数据的系统,所述系统包括顺次连接的输入器、drm反应器和输出器,配合所述系统设置有文档关系映射协议,用于定义文档数据至数据库数据的映射关系,输入器、drm反应器和输出器相关的元信息均配置在文档关系映射协议中。
21.本发明是一种灵活、可扩展、轻量级的文档数据转储系统,可用于将外部接口数据转储到本地数据库表中,完成数据接入。
22.本发明中,输入器是可扩展的,当需要支持新的输入源的时候,可以新增一个或多个输入器的实现,以支持对应的新输入源;类似地,输出器也是可扩展的,当需要支持新的存储方式时,可以新增一个或多个输出器的实现,以支持对应是新存储方式。
23.本发明以配置化的方式工作,在实际应用中,只需修改配置文件即可完成一个新文档数据到数据库的存储过程;对应地,系统拥有:一个变量解析器,支持多种变量类型,包括但不限于ognl表达式、groovy script、双下划线(__)变量;一个文档操作算子解析器,支持对数据文档做前置数据处理;其是一个算子集合,以管道模式从前往后顺序执行,即以前一个算子的输出作为下一个算子的输入;一个值操作算子解析器,支持对矩阵格的值做后处理;其是一个算子集合,以管道模式从前往后顺序执行,即以前一个算子的输出作为下一个算子的输入。
24.本发明中,以双星通配模式,可以简化文档属性和关系数据库字段的映射配置;当然,实际应用过程中,输入器不仅为双星通配模式。
25.本发明中,定义树形的数据矩阵结构,能够支持数据转储为关系型数据库中的数据,进而实现父子属性的引用。
26.所述输入器为可扩展,所述输入器的个数对应输入源的个数设置。
27.配置所述输入器为双星通配模式或多值匹配模式或多变量解析模式或loop循环配置模式。
28.如图2所示,所述输入器的操作步骤为:a.1 加载输入器相关配置;a.2 构建http请求对象;a.3 请求api结构;a.4 若校验请求接收成功,则进行下一步,否则结束;a.5 转换请求结果为drm反应器支持的数据格式,发送数据至drm反应器,结束。
29.本发明中,输入器是系统的核心组件之一,负责从外部获取数据,并解析成drm反应器的支持的数据格式,包括但不限于json数据格式。
30.本发明中,给出输入器的相关配置的实施例:{
ꢀꢀꢀꢀ‑‑
输入器相关配置 "type": "api",
ꢀꢀꢀ‑‑
输入器类型,例如:api表示从接口查询数据
ꢀꢀꢀꢀꢀ
"loop": {
ꢀꢀ‑‑
开启循环
ꢀꢀꢀꢀꢀ
"variables": {
ꢀꢀꢀ‑‑
定义循环条件中的使用的变量
ꢀꢀꢀꢀꢀꢀꢀꢀ
"total": "$.result.total",
ꢀꢀ‑‑
自定义参数,此处为获取响应报文中的总记录条数的字段值
ꢀꢀꢀꢀꢀꢀꢀꢀ
"step": 50
ꢀꢀ‑‑
自定义参数
ꢀꢀꢀꢀꢀ
},
ꢀꢀꢀꢀꢀ
"condition": "[ __total 》 __loopindex * __step ]",
ꢀꢀꢀ‑‑
循环条件,满足条件时继续循环,否则结束循环,其中__loopindex为内置变量,表示当前循环次数
ꢀꢀ
},
ꢀꢀꢀꢀꢀ
"metadata": {
ꢀꢀꢀꢀ‑‑
定义各输入器的元信息
ꢀꢀꢀꢀꢀ
"method": "get",
ꢀꢀꢀꢀ‑‑
api输入器的请求类型
ꢀꢀꢀꢀꢀ
"url": "http://notreal.com/api/book/list",
ꢀꢀꢀ‑‑
api输入器的请求url
ꢀꢀꢀꢀꢀ
"documenttype": "application/json",
ꢀꢀ‑‑
api输入器的数据类型,如application/json, application/xml
ꢀꢀꢀꢀꢀꢀ
"variables": {
ꢀꢀ‑‑
自定义变量
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
"key": "abc",
ꢀꢀ‑‑
自定义变量,应用标识
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
"secret": "123",
ꢀꢀ‑‑
自定义变量,应用秘钥
ꢀꢀꢀꢀꢀꢀ
},
ꢀꢀꢀꢀꢀꢀ
"headers": {
ꢀꢀ‑‑
api输入器的请求头参数
ꢀꢀꢀꢀꢀꢀ
"contenttype": "application/x-www-form-urlencoded",
ꢀꢀ‑‑
请求报文编码类型,如application/x-www-form-urlencoded, application/json"token": "{import java.security.messagedigest;def plaintext = __key + __timestamp + __secret;return messagedigest.getinstance('md5').digest(plaintext.bytes).encodehex().tostring().touppercase();}"
ꢀꢀꢀ‑‑
动态生成请求令牌
ꢀꢀꢀꢀꢀꢀ
},
ꢀꢀꢀꢀꢀ
"parameters": {
ꢀꢀ‑‑
api输入器的请求体参数
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
"key": "__key",
ꢀꢀꢀ‑‑
获取自定义变量中的应用标识,并放入请求体参数列表中
ꢀꢀꢀꢀꢀꢀꢀꢀ
"pageindex": "__loopindex",
ꢀꢀꢀꢀ‑‑
用当前循环次数做为当前页
ꢀꢀꢀꢀꢀꢀꢀꢀ
"pagesize": "__step"
ꢀꢀꢀ‑‑
每页记录条数
ꢀꢀꢀꢀꢀ
},
ꢀꢀꢀꢀꢀ
"success": "[ result.status == 200 ]"
ꢀꢀ‑‑
api输入器的数据请求成功判断条件,如result.status == 200,result为接口返回内容
ꢀꢀꢀꢀꢀ
}};以
‘‑‑’
后的注释为各个属性的含义。
[0031]
本发明中,对输入器相关配置包括双星通配模式或多值匹配模式或多变量解析模式或loop循环配置模式;两颗星通配模式表示将文档节点下的所有非对象和非数组型属性自动映射为字段名,字段名为蛇形化后的元素名称,即,将驼峰型的名称转换成蛇形的格式,如,{"field": "*", "element": "*"};多值匹配模式中,系统一般支持三种值类型,元素类型(element)、引用类型(reference)和常量类型(value);元素类型(element)对应数据文档中的元素,支持相对路径查找和绝对路径($.开头的属性名)查找;引用类型(reference):支持以(@)方式引用外部数据和以(.)方式引用父级字段数据,默认表示引用的是父级字段数据;常量类型(value)即原值;三者的优先级顺次为元素类型、引用类型和常量类型;多变量解析模式可以灵活支持值的解析和获取,一般来说,以“$.”表示文档元素型变量、将从源文档中解析值,以“{ ... }”表示groovy脚本型变量,以“[ ... ]”表示ognl表达式型变量,以“__xxx”表示引用变量,如引用定义在loop.variables 和 metadata.variables 中的变量和__loopindex 内置循环下标变量,metadata中可以引用loop中的变量,(但是只能引用非文档元素型的变量,因为文档还未获得),但是loop中不可以引用metadata中的变量;loop循环配置模式中,condition必须为一个ognl表达式,其可用的变量来自于循环变量,其中__loopindex作为循环的标记从1开始递增,表示当前循环次数,循环变量loop.variables中的非文档元素类型,即以“$.”开头的变量将被传递到元变量metadata.variables中,在metadata.headers对象中可以引用循环对象中的变量,比如__loopindex 和__step,groovy script也可以引用这些变量。
[0032]
本发明中,对接外部服务接口的时候,不同的服务提供商对数据请求的格式往往不一样,大部分的服务提供商的接口都需要做接口入参的验签,验签规则也各不相同,本系统的输入器能动态生成签名;同时,还有些接口是分页查询的,输入器就需要能动态生成分页信息;针对这些动态的能力,输入器实现了变量、脚本和loop循环的功能。
[0033]
所述文档关系映射协议为树形结构,包括作为根节点的drm节点,配合所述drm节点设有第一级的子矩阵节点和兄弟矩阵节点,配合任一所述第一级的子矩阵节点和兄弟矩阵节点套设有下一级的子矩阵节点和兄弟矩阵节点;任一级的子矩阵节点和兄弟矩阵节点
为1个或多个。
[0034]
本发明中,文档关系映射(document relationship mapping, a.k.a., drm)协议定义了文档数据到数据库数据的映射关系,是整个系统的核心之一,其作为树形结构,可参考附图3,其中,drm节点为根节点,children和siblings分别用于定义子矩阵节点和兄弟矩阵节点,为矩阵集合,也就是说,同一层可以有多个子矩阵节点和兄弟矩阵节点。
[0035]
本发明中,举例来说,一个矩阵的结构为:{
ꢀꢀ
"document": "$.book",
ꢀꢀ‑‑
文档节点,原始数据,'$.'符号表示文档根节点
ꢀꢀ
"matrix": "t_book",
ꢀꢀꢀꢀ‑‑
矩阵名称,书本矩阵"keys": ["isbn"],
ꢀꢀꢀ‑‑
数据唯一标识"operates": ["tojson()"],
ꢀꢀꢀ‑‑
操作算子,可以用于操作文档
ꢀꢀ
"cells": [
ꢀꢀ‑‑
矩阵内的数据格子
ꢀꢀꢀꢀꢀꢀ
{
ꢀꢀꢀꢀꢀꢀꢀꢀ
"cell": "title",
ꢀꢀꢀꢀ‑‑
格子名称
ꢀꢀꢀꢀꢀꢀꢀꢀ
"element": "title",
ꢀꢀꢀꢀ‑‑
文档元素, 缺省情况下默认同格子名称
ꢀꢀꢀꢀꢀꢀꢀꢀ
"operates": "trim(), length(30)"
ꢀꢀ‑‑
操作算子,对文档返回值做操作
ꢀꢀꢀꢀꢀꢀ
},
ꢀꢀꢀꢀꢀꢀ
{
ꢀꢀꢀꢀꢀꢀꢀꢀ
"cell": "author"
ꢀꢀꢀꢀ‑‑
默认从文档中获取按格子名称获取数据
ꢀꢀꢀꢀꢀꢀ
},
ꢀꢀꢀꢀꢀꢀ
{
ꢀꢀꢀꢀꢀꢀꢀꢀ
"cell": "isbn",
ꢀꢀꢀꢀꢀꢀ
},
ꢀꢀꢀꢀꢀꢀ
{
ꢀꢀꢀꢀꢀꢀꢀꢀ
"cell": "create_user",
ꢀꢀꢀꢀꢀꢀꢀꢀ
"reference": "@operator"
ꢀꢀ‑‑
引用值,
‘
@’符号表示该引用来自于外部传入的参数
ꢀꢀꢀꢀꢀꢀ
},
ꢀꢀꢀꢀꢀꢀ
{
ꢀꢀꢀꢀꢀꢀꢀꢀ
"cell": "create_time",
ꢀꢀꢀꢀꢀꢀꢀꢀ
"value": "now()"
ꢀꢀꢀꢀ‑‑
固定值
ꢀꢀꢀꢀꢀꢀ
}
ꢀꢀ
],
ꢀꢀ
"children": [{}],
ꢀꢀꢀ‑‑
子矩阵(节点)集合
ꢀꢀ
"siblings": [{}]
ꢀ‑‑ꢀ
兄弟矩阵(节点)集合}以
‘‑‑’
后的注释为各个属性的含义。
[0036]
如图4所示,所述drm反应器的操作步骤为:
步骤b.1 加载drm协议配置;步骤b.2 获得输入器发送的预设格式的数据;步骤b.3 以递归且深度优先的方式遍历并转化文档;如图5所示,所述步骤b.3包括以下步骤:步骤b.3.1 开始drm对象,根据drm中的文档属性配置,从文档获取文档数据对象;步骤b.3.2 若文档数据对象为集合对象,则遍历数据集合,执行转化子流程,进行下一步,否则,直接进行下一步;步骤b.3.3 根据drm中的矩阵格属性配置,将数据对象转化成矩阵行对象;步骤b.3.4 判断是否存在子矩阵集合,若是,则遍历处理子矩阵drm,返回步骤b.3.1,否则进行下一步;步骤b.3.5 判断是否存在兄弟矩阵集合,若是,则遍历处理兄弟矩阵drm,返回步骤b.3.1,否则结束。
[0037]
步骤b.4 输出树形数据矩阵至输出器。
[0038]
本发明中,drm反应器负责将输入数据转换成数据矩阵对象,以递归且深度优先的方式遍历并转化文档,其支持json格式的数据输入对象,并将之转化成一个树形数据矩阵输出对象。
[0039]
本发明中,转化子流程包括文档操作和值操作;文档操作算子集合由一个个的操作算子组成,支持管道模式执行,每个操作算子都能对输入文档做处理并返回处理结果;返回的处理结果可以进一步由下一个操作算子做处理,并返回结果;当所有的操作算子都处理完毕后,将结果作为当前drm对象的数据文档,并进行drm数据转化;值操作算子集合对当前矩阵格子的值做后处理,它同样支持管道模式执行。
[0040]
所述输出器为可扩展,所述输出器的个数对应存储方式的个数设置。
[0041]
如图6所示,所述输出器的操作步骤为:步骤c.1 读入输出器配置;步骤c.2 判断用于存储的数据库是否已创建连接,若否,则初始化数据库连接,进行下一步,否则直接进行下一步;步骤c.3 读入drm反应器处理后的矩阵数据树;步骤c.4 预处理,检查数据库状态并完成数据库表的创建;开启数据库事务;步骤c.5 以递归且深度优先的方式按行遍历矩阵;如图7所示,所述步骤c.5包括以下步骤:步骤c.5.1 判断矩阵是否为空,若是则结束,否则进行下一步;步骤c.5.2 根据矩阵数据行内的唯一键,在数据库中查找数据;若数据不存在,则进行步骤c.5.4,否则判断是否重建;步骤c.5.3 若重建,则生成删除数据库数据的语句并进行缓存,填入矩阵中该行的唯一键的值,生成可执行语句并执行,进行下一步,否则判断是否更新,若不更新则结束,若更新则记录数据id值并缓存父对象,生成更新数据库数据的语句并做缓存,填入矩阵中该行的唯一键的值,生成可执行的语句并执行,进行步骤c.5.6;步骤c.5.4 生成新增数据库数据的语句并进行缓存;步骤c.5.5 遍历矩阵行中的所有格,将值注入填入新增对象,执行新增sql,并将
获取的记录id逐个缓存到父对象;步骤c.5.6 判断是否存在子矩阵集合,若是,则返回步骤c.5.1,否则进行下一步;步骤c.5.7 判断是否存在兄弟矩阵集合,若是,则返回步骤c.5.1,否则结束。
[0042]
步骤c.6 若发生异常,则回滚数据库事务,否则提交数据库事务,完成。
[0043]
本发明中,输出器负责将drm反应器生成的数据矩阵输出到外部存储设备,如关系型数据库。
[0044]
本发明中,输出器的相关配置的实施例为:{
ꢀ‑‑
输出器相关配置
ꢀꢀ
"type": "mysql",
ꢀꢀꢀꢀ‑‑
mysql输出器,输出到mysql存储介质
ꢀꢀ
"mode": "pararel",
ꢀꢀ‑‑
并行模式
ꢀꢀ
"workersize": 5,
ꢀꢀꢀꢀ‑‑
工作线程数,默认1
ꢀꢀ
"executor": {
ꢀꢀꢀꢀ‑‑
线程池配置,默认
ꢀꢀꢀꢀꢀ
"customize": "myexecutor",
ꢀꢀ‑‑
自定义线程池
ꢀꢀꢀꢀꢀ
"coresize": "3",
ꢀꢀꢀꢀ‑‑
核心线程数
ꢀꢀꢀꢀꢀ
"maxsize": "10"
ꢀꢀ‑‑
最大线程数
ꢀꢀ
},
ꢀꢀ
"metadata": {
ꢀꢀꢀꢀ‑‑
输出器元信息配置
ꢀꢀꢀꢀꢀ
"url": "jdbc:mysql://127.0.0.1:3306/warehouse",
ꢀꢀꢀꢀ‑‑
mysql输出器的url配置
ꢀꢀꢀꢀꢀ
"username": "demo",
ꢀꢀꢀꢀ‑‑
mysql输出器的连接数据库用户名
ꢀꢀꢀꢀꢀ
"password": "123456"
ꢀꢀꢀ‑‑
mysql输出器的连接数据库密码
ꢀꢀ
}}以
‘‑‑’
后的注释为各个属性的含义。
[0045]
本发明中,输出器以递归和深度优先的方式按行遍历矩阵,遍历矩阵行中的所有格子并将值逐个填入新增对象,此时,解析矩阵的个字数据,判断是否引用父矩阵行的id,若是,则从上一级对象中获取父节点的id并返回,否则直接获得矩阵格子的value并返回。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1