基于指令流混合模式学习的低污染缓存预取系统及方法
1.本发明涉及计算机体系结构技术领域,尤其涉及一种基于指令流混合模式学习的低污染缓存预取系统及方法。
背景技术:
2.缓存是现代处理器中的一种重要机制,将常用数据从内存拷贝到缓存中,后续数据访问可以直接从缓存读取,从而减少慢速dram内存的访问次数,提升处理器性能。缓存的容量是有限的,在实际使用中发生缓存失效是不可避免的。缓存预取技术预测程序将要使用的数据,并将这些数据提前读取到缓存中,减少缓存失效的次数。
3.缓存访问行为是复杂的,处理器中缓存系统接收到的访存序列会受到处理器乱序执行的干扰。同时,不同模式的访存指令会互相交织在一起,进一步增大了在缓存系统中预测访存行为的难度。现有的缓存预取方法均不能有效的解决未来访存序列预测困难的问题。
技术实现要素:
4.本发明的目的在于提供一种基于指令流混合模式学习的低污染缓存预取系统及方法,以减少访存序列预测过程中所面对的不确定性,提高预取地址预测的准确性。
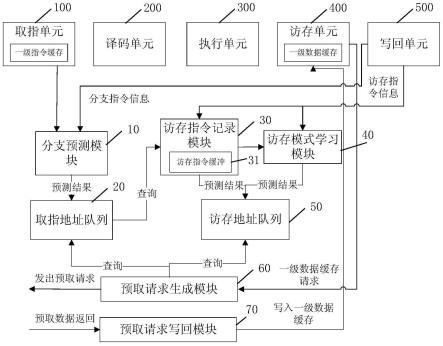
5.为了实现上述目的,本发明提供了一种基于指令流混合模式学习的低污染缓存预取系统,包括主流水线和分支预测子流水,所述分支预测子流水包括分支预测模块、取指地址队列、访存指令记录模块、访存模式学习模块、访存地址队列、预取请求生成模块和预取请求写回模块;所述分支预测模块设置为采用提前预测技术,对目标程序的指令流进行预测并将预测结果写入取指地址队列中;所述访存指令记录模块设置为依次记录已经提交的访存指令的信息,将这些访存指令的信息写入到其访存指令缓冲中;同时,每当取指地址队列写入新的条目项时,用该条目项所对应的指令块的起始地址查询所述访存指令缓冲,以通过查询尝试得到访存指令序列并将其输出至访存指令学习模块和访存地址队列;所述访存模式学习模块设置为将访存指令序列记录在其访存历史缓冲中,根据访存历史缓冲中保存的历史信息对访存指令的访存模式进行学习,并根据学习到的访存模式来预测访存指令序列中每条访存指令的访存物理地址并写入访存地址队列;所述预取请求生成模块设置为在一级数据缓存接收到新的请求时,检索所述取指地址队列和访存地址队列,为即将进入主流水线的指令块分别生成一级指令缓存和一级数据缓存的预取请求并将其发送到缓存系统中,以获取拿到数据的预取请求;所述预取请求写回模块设置为将拿到数据的预取请求暂存在其预取队列中,使得位于预取队列头部的拿到数据的预取请求根据所述预取请求之前的指令提交情况等待写回或者立即写回至一级缓存。
6.所述分支预测模块设置为将预测结果以指令块为粒度写入取指地址队列中;且所述分支预测模块设置为执行:
7.a1:在每个周期,将当前预测地址所在的指令块作为当前指令块,将当前预测地址
作为当前指令块的预测起始地址;根据当前指令块的预测起始地址确定从当前指令块开始的固定预测窗口;
8.a2:在获得当前指令块的预测起始地址后,在当前指令块中对分支指令进行检索和预测,以判断当前指令块是否命中跳转的分支指令;
9.a3:根据判断结果,若当前指令块未命中跳转的分支指令,说明当前指令块中没有分支指令或者识别到的分支指令均未跳转,则将当前指令块的信息作为分支预测模块的预测结果写入取指地址队列;随后,确定下一指令块的预测起始地址,并将下一指令块作为新的当前指令块,并回到步骤a2,直到当前指令块为固定预测窗口中的最后一个指令块,此时当前预测地址根据固定预测窗口中的指令块的个数自增,以进入下一个周期;
10.否则,从命中的跳转的分支指令中选择线性地址最小的第一个跳转的分支指令作为当前指令块的结尾地址,将当前指令块的信息作为预测结果写入取指地址队列,同时将当前预测地址更新为第一个跳转的分支指令的跳转地址,以进入下一个周期;
11.或者,所述分支预测模块设置为将预测结果以指令块为粒度写入取指地址队列中;且所述分支预测模块设置为执行:
12.步骤a1’:在每个周期,将当前预测地址所在的指令块作为当前指令块,将当前预测地址作为当前指令块的预测起始地址;随后,根据当前指令块的预测起始地址确定从当前指令块开始的固定预测窗口中的所有指令块的预测起始地址;
13.步骤a2’:根据各个指令块的预测起始地址,在各个指令块中对分支指令进行检索和预测,以判断各个指令块是否命中跳转的分支指令;
14.步骤a3’:根据判断结果,若所有指令块均未命中跳转的分支指令,则将所有指令块的信息作为分支预测模块的预测结果依次写入取指地址队列;当前预测地址根据固定预测窗口中的指令块的个数自增,以进入下一个周期;
15.否则,若存在至少一个指令块命中至少一个跳转的分支指令,则从命中的跳转的分支指令中选择线性地址最小的第一个跳转的分支指令作为当前指令块的结尾地址,将当前指令块及其前面的所有指令块的信息作为预测结果写入取指地址队列,同时将当前预测地址更新为第一个跳转的分支指令的跳转地址,以进入下一个周期。
16.所述主流水线包括依次连接的取指单元、译码单元、执行单元、访存单元和写回单元,在所述分支预测模块中,所述指令块的位宽等同于所述取指单元在取指时的位宽;
17.所述指令块的信息包括指令块的行线性地址、行物理地址、起始偏移、结束偏移以及跳转位;在将指令块的信息写入取指地址队列时,将指令块的预测起始地址拆分为高位的行线性地址和低位的起始偏移,并通过行线性地址查询tlb得到行物理地址,并将得到的行线性地址、行物理地址和起始偏移写入取指地址队列的条目项中的对应域;此外,如果指令块命中的跳转的分支指令,则第一个跳转的分支指令的末尾字节偏移作为结束偏移写入取指地址队列;否则,取指地址队列中的结束偏移设置为63。
18.所述取指地址队列每一条目项的结构为:
19.《valid,line_addr,phys_addr,begin_offset,end_offset,taken》,
20.其中,valid表示有效位;line_addr表示行线性地址;phys_addr表示行物理地址;begin_offset表示起始偏移;end_offset表示结束偏移;taken表示跳转位;
21.所述取指地址队列还设有提交指针,读指针和写指针;取指地址队列的提交指针
指向下一个将提交的指令所在的指令块在取指地址队列中的条目项;取指地址队列的读指针指向下一个将读取的指令所在的指令块在取指地址队列中的条目项;取指地址队列的写指针指向分支预测模块下一次写入的位置;在处理器的主流水线刷新发生后,根据刷新类型,取指地址队列的读指针和写指针回滚到分支刷新的位置或者提交指针的位置;
22.所述访存指令缓冲的每一个表项的结构为:
23.《lineaddr,phyaddr,insttype,memlen》,
24.其中,lineaddr表示访存指令的指令线性地址;phyaddr表示访存指令在上一次执行时的访存物理地址;insttype表明访存指令的类型,insttype∈{directinst,indirectinst},其中directinst表示直接访存指令,indirectinst表示间接访存指令;memlen表明访存指令的访存长度;
25.所述访存历史缓冲是一个由访存指令的pc作为索引的阵列,访存历史缓冲中的每一个表项都记录有同一访存指令过去12次的访存物理地址;
26.且所述访存地址队列中每一条目项的结构为:
27.《valid,inst_line_addr,mem_phys_addr,memlen,inst_queue_index》,
28.其中,valid表示有效位;inst_line_addr表示指令线性地址;mem_phys_addr表示访存物理地址;memlen表示访存长度;inst_queue_index表示取指地址队列索引;
29.所述访存地址队列具有提交指针、读指针和写指针;在主流水线发生分支刷新时,访存地址队列的读指针和写指针回滚到分支刷新的位置。
30.所述分支预测模块设置为:若取指地址队列写满则暂停预测过程;取指地址队列是否写满根据所述取指地址队列的写指针和提交指针的结合来判断。
31.在访存指令记录模块中,所述访存指令的信息包括访存指令的pc、指令线性地址、访存指令的访存地址、类型以及访存长度;
32.所述访存指令记录模块设置为在查询过程中使用访存指令缓冲的所有表项中的访存指令的指令线性地址进行命中判定,在访存指令命中时得到访存指令在访存指令缓冲中的位置和类型,从而通过查询访存指令缓冲中所有的访存指令来尝试得到访存指令在访存指令缓冲中的位置和类型;在进行命中判定时,当访存指令缓冲中存在一条访存指令的指令线性地址的高位标签和新的条目项所对应的指令块的行线性地址相同,并且其低位偏移大于等于指令块的起始偏移,小于等于指令块的结束偏移,则访存指令命中,得到位于该访存指令在访存指令缓冲中的位置和类型。
33.所述访存模式学习模块包括步长预测器和时间关联预测器,使得访存模式学习模块在访存历史缓冲的基础上通过步长预测器和时间关联预测器实现步长模式和时间关联模式的学习和预测;
34.所述步长预测器的每一条目项用于记录一种步长模式,所述步长模式是指步长访存序列;步长预测器的每一条目项包括一个步长访存序列的标签、上一次地址、上一次步长、可信计数器、当前模式、首地址、最大计数器和方向;
35.所述时间关联预测器的每一条目项用于记录一种时间关联模式,时间关联模式是指一个时间关联访存序列,所述时间关联预测器的每一条目项包括时间关联模式、时间关联序列长度和时间关联序列。
36.所述预取请求生成模块根据取指地址队列的读指针来确定即将进入主流水线的
指令块;
37.所述预取请求生成模块设置为执行如下步骤:
38.b1:在收到一级数据缓存收到新请求的消息后,检索取指地址队列,获得其读指针的位置,将在读指针上添加一预取提前量后的位置作为预取起始,将以预取起始为第一个预取指令块的连续n个预取指令块作为即将进入主流水线的指令块,为即将进入主流水线的指令块生成相应的一级指令缓存的预取请求;
39.b2:接收取指地址队列所反馈的各个预取指令块的指针,使用这些预取指令块的指针检索访存地址队列中的取指地址队列索引,获取各个预取指令块中包含的访存指令以及其访存物理地址,根据访存指令的访存物理地址来生成一级数据缓存的预取请求;
40.b3:将一级指令缓存的预取请求和一级数据缓存的预取请求均发送给缓存系统,以获取拿到数据的预取请求。
41.所述预取请求写回模块设置为:对于位于预取队列的头部的预取请求,将检索访存地址队列在其提交指针之后和所述预取请求之前的未提交指令集,判断在未提交指令集中是否存在一级缓存的阵列中与所述预取请求同组的其他访存指令并将判断结果作为所述预取请求之前的指令提交情况;若判断为存在与所述预取请求同组的其他访存指令,并且与所述预取请求同组的访存指令个数至少为缓存阵列的路数,则将所述预取请求等待写回,否则,将所述预取请求立即写回一级缓存。
42.另一方面,本发明提供一种基于指令流混合模式学习的低污染缓存预取方法,包括:
43.s1:利用分支预测模块,采用提前预测技术,对目标程序的指令流进行预测并将预测结果写入取指地址队列中;取指地址队列写满则暂停预测过程;
44.s2:利用访存指令记录模块,记录已经提交的访存指令的信息,将这些访存指令的信息写入到一访存指令缓冲中;每当取指地址队列写入新的条目项时,用该条目项所对应的指令块的起始地址查询所述访存指令缓冲,以通过查询尝试得到访存指令序列并将其输出至访存指令学习模块和访存地址队列;
45.s3:利用访存指令学习模块,将访存指令序列记录在访存历史缓冲中,根据访存历史缓冲中保存的历史信息对访存指令的访存模式进行学习,并根据学习到的访存模式来预测访存指令序列中每条访存指令的访存物理地址,将每条访存指令的访存物理地址写入到一访存地址队列;
46.s4:利用预取请求生成模块,在一级数据缓存接收到新的请求时,检索所述取指地址队列和访存地址队列,为即将进入主流水线的指令块分别生成一级指令缓存和一级数据缓存的预取请求并将其发送到缓存系统中,以获取拿到数据的预取请求;
47.s5:利用预取请求写回模块,将拿到数据的预取请求暂存在其预取队列中,使得位于预取队列头部的拿到数据的预取请求根据所述预取请求之前的指令提交情况等待写回或者立即写回至一级缓存。
48.本发明的基于指令流混合模式学习的低污染缓存预取系统的预测对象具体到每条访存指令,为每条访存指令单独记录历史信息,所以学习的是指令级访存行为降低了预测的复杂性;并且根据处理器主流水的写回单元反馈的已经提交的访存指令所组成的序列进行模式学习,预测对象是行为简单的单条的独立访存指令,可以避免乱序执行的干扰,提
高了访存序列预测的准确性。综上,本发明的基于指令流混合模式学习的低污染缓存预取系统通过上述方式减少了访存序列预测过程中所面对的不确定性,明显减少缓存失效发生的次数,提高了预取地址预测的准确性。
附图说明
49.图1是本发明的基于指令流混合模式学习的低污染缓存预取系统及方法所适用的其中一种处理器微架构的结构示意图。
50.图2是本发明的基于指令流混合模式学习的低污染缓存预取系统及方法所适用的另一种处理器微架构的结构示意图。
51.图3是根据本发明的一个实施例的基于指令流混合模式学习的低污染缓存预取系统的整体框架图。
52.图4是如图3所示的基于指令流混合模式学习的低污染缓存预取系统的分支预测模块的预测流程图。
53.图5是本发明的基于指令流混合模式学习的低污染缓存预取系统的取指地址队列及其提交指针、读指针和写指针的位置关系示意图。
54.图6是本发明的基于指令流混合模式学习的低污染缓存预取系统的访存指令缓冲的查询过程示意图。
55.图7(a)是传统的时间关联预取算法的原理图。
56.图7(b)是本发明的基于指令流混合模式学习的低污染缓存预取系统中基于访存历史缓冲的访存模式学习过程的原理图。
57.图8是本发明的基于指令流混合模式学习的低污染缓存预取系统的步长预测器的条目项的结构示意图。
58.图9是本发明的基于指令流混合模式学习的低污染缓存预取系统的预取请求生成模块的工作原理图。
59.图10是本发明的基于指令流混合模式学习的低污染缓存预取系统的一级数据缓存的预取请求的写回等待过程的原理图。
具体实施方式
60.下面通过具体实施示例,对本发明做进一步详细说明。
61.本发明的基于指令流混合模式学习的低污染缓存预取系统及方法适用于图1所示的处理器微架构中。所述处理器微架构至少包含取指、译码、执行、访存和写回这5个阶段,这五个阶段分别对应取指单元100、译码单元200、执行单元300、访存单元400和写回单元500,上述的取指单元100、译码单元200、执行单元300、访存单元400和写回单元500构成了主流水线。一级缓存分为一级指令缓存和一级数据缓存,其中一级指令缓存位于cpu的主流水线中的取指单元100,一级数据缓存位于cpu的主流水线中的访存单元400。
62.本发明同样适用于包含图1所示功能的更为复杂的处理器微架构中,更复杂的处理器微架构中可能会将某个阶段进行细化,比如可以将执行阶段拆分为重命名、调度和执行三个子阶段。
63.如图2所示,根据现有技术中的提前预测技术,处理器微架构中还可以包含分支预
测单元600,分支预测单元600可以通过预测队列与取指单元进行交互。具体来说,分支预测单元600对未来程序指令流进行预测,并将预测结果以对齐指令块为粒度写入预测队列700中。预测队列700中的每一条目项包含指令块的起始地址、结尾地址以及其它分支指令信息。分支预测单元600和取指单元100之间类似生产者-消费者关系。取指单元100每周期从预测队列700中读取一条目项,并根据读取的条目项从缓存系统中读取相应的指令块数据,然后将指令块数据发送给主流水线的后续单元(即译码单元200、执行单元300、访存单元400和写回单元500)来执行该指令块中包含的指令。本发明的基于指令流混合模式学习的低污染缓存预取方法在应用于包含分支预测单元600的处理器微架构中时,可以将分支预测单元600和预测队列700分别作为本发明系统的分支预测模块和取指地址队列,从而减少具体实施的工作量。
64.图3是根据本发明的一个实施例的基于指令流混合模式学习的低污染缓存预取系统的整体框架图。如图3所示,所述基于指令流混合模式学习的低污染缓存预取系统在现有的处理器微架构(包括取指单元100、译码单元200、执行单元300、访存单元400和写回单元500)的基础上,还包括分支预测模块10、取指地址队列20、访存指令记录模块30、访存模式学习模块40、访存地址队列50、预取请求生成模块60和预取请求写回模块70七个模块。这七个模块共同组成了执行速率快于主流水线的预测子流水,于处理器的主流水(即取指单元100、译码单元200、执行单元300、访存单元400和写回单元500的顺序执行)外独立运行,各个模块在预测子流水中的先后的执行次序是分支预测模块10
→
取指地址队列20
→
访存指令记录模块30
→
访存模式学习模块40
→
访存地址队列50。预取请求生成模块60和预取请求写回模块70是比较独立的模块,预取请求生成模块60设置为选择恰当的时机检索取指地址队列和访存地址队列,生成一级指令缓存和一级数据缓存的预取请求,并将预取请求发送到缓存系统(如二级、三级缓存)中。预取请求写回模块70暂存已经拿到数据的预取请求。这些预取请求具备写入一级缓存的数据,但是为了防止写入过程中从一级缓存中踢出重用距离比预取请求更小的缓存项,因此预取请求需要在预取请求写回模块70的队列中等待可以写回的时刻。预取请求生成模块60和其它5个预测子流水的组成模块之间的关系类似生产者-消费者,通过预测子流水填充取指地址队列20和访存地址队列50,而预取请求生成模块60检索这两个队列。
65.(一)分支预测模块10
66.分支预测模块10是预测子流水的起始点。分支预测模块10设置为:采用提前预测技术,对目标程序的指令流进行预测并将预测结果以指令块为粒度(即以对齐指令块的形式)写入取指地址队列20中;取指地址队列20写满则暂停预测过程。
67.由此,取指地址队列中保存的就是一个个指令块(包含额外的分支指令信息)。而由于取指单元访问一级指令缓存时也是按照固定位宽(64b)的指令块的形式进行的,所得到的取指地址队列20中的条目项用于作为取指单元100中的一级指令缓存的未来访问序列,也就是目标程序的指令流的访问序列的预测结果。
68.其中,分支预测模块10通过在每个周期判断固定预测窗口的所有指令块中是否存在跳转的分支指令,根据判断结果来对目标程序的指令流进行预测。在每个周期的预测过程都在当前预测地址的基础上进行,当前预测地址更新则进入下一个周期。分支预测模块10中一个很重要的功能是维护当前预测地址,这是一个48位的线性地址。
69.维护当前预测地址包括:如果预测到跳转的分支指令,该跳转的分支指令的跳转地址将会更新为当前预测地址;也就是说,分支预测模块10是一个自循环的分支预测单元,分支预测模块10的预测结果除了写入取指地址队列20之外,预测结果中的跳转的分支指令的跳转地址将作为当前预测地址被回传给分支预测模块10自身,作为下一次预测周期的起始地址。另外,在处理器初始化阶段或者主流水线发生刷新时,取指单元会将初始化地址或者刷新地址发送给分支预测模块10用以更新当前预测地址。
70.图4示出了分支预测模块10的预测流程。分支预测模块的固定预测窗口为多个指令块的宽度,即每周期可以预测多个连续的指令块,指令块的位宽等同于取指单元100在取指时的位宽,便于和取指单元100的交互。
71.分支预测模块的固定预测窗口为多个64b指令块,即每周期可以预测多个连续的64b指令块,选择64b的指令块是用于匹配取指单元100的在访问一级指令缓存时的带宽。
72.如图4所示,所述分支预测模块10设置为执行如下步骤:
73.步骤a1:在每个周期(即当前预测地址初始化或者更新时),将一级指令缓存中的当前预测地址所在的指令块作为当前指令块,将当前预测地址作为当前指令块的预测起始地址;根据当前指令块的预测起始地址确定从当前指令块开始的固定预测窗口;
74.由于对目标程序的指令流的预测以对齐的指令块为粒度,每个周期的固定预测窗口为多个指令块的宽度,即每周期可以预测多个指令块,比如32b的固定预测窗口可以拆分成2个16b的指令块并行预测。在本实施例中,假设当前预测地址是5,分支预测模块10的每周期的固定预测窗口是128b,即每周期预测2个对齐的64b指令块。第一个64b指令块的预测起始地址就是当前预测地址(也就是5),指令块范围是[5,63];第二个64b指令块的预测起始地址是64,指令块范围是[64,127]。由于是对齐的指令块,每个指令块的默认起始地址是64b的整数倍。然而考虑到预测过程中第一个指令块的起始地址可能不是64b的整数倍,因为这个地址可能是从某个分支指令跳转过来的,没有办法保证这个地址是严格对齐的;因此预测过程中的第二个指令块(以及第三、四等)的起始地址一定是64b的整数倍。
[0075]
步骤a2:在获得当前指令块的预测起始地址后,在当前指令块中对分支指令进行检索和预测,以判断当前指令块是否命中跳转的分支指令;
[0076]
其中,分支预测模块10需要利用一种现有的分支预测算法来实现分支指令的预测。本发明并不依赖特定的分支预测算法,现有的分支预测算法都适用于分支预测模块。以常见的tage分支预测算法为例,首先使用当前指令块的预测起始地址检索btb(branch target buffer,分支目标缓冲器),根据btb中保存的分支指令位置识别当前指令块中包含的所有分支指令。这个识别过程可能会命中多条分支指令。然后对识别出的每条分支指令的跳转方向和跳转地址进行预测,以确定这些分支指令中是否存在跳转的分支指令。
[0077]
步骤a3:根据判断结果,若当前指令块未命中跳转的分支指令,说明当前指令块中没有分支指令或者识别到的分支指令均未跳转,则将当前指令块的信息作为分支预测模块10的预测结果写入取指地址队列;随后,确定下一指令块的预测起始地址,并将下一指令块作为新的当前指令块,并回到步骤a2,直到当前指令块为固定预测窗口中的最后一个指令块,此时当前预测地址根据固定预测窗口中的指令块的个数自增,从而实现当前预测地址的更新,进入下一个周期;
[0078]
否则,即当前指令块命中跳转的分支指令,说明在指令块中识别到的分支指令有
一个或者多个预测跳转,则从命中的跳转的分支指令中选择线性地址最小的第一个跳转的分支指令作为当前指令块的结尾地址,将当前指令块的信息作为预测结果写入取指地址队列,同时将当前预测地址更新为第一个跳转的分支指令的跳转地址,以进入下一个周期。
[0079]
也就是说,如图4所示,在本实施例中,分支预测模块每周期所预测的多个指令块是按照串行次序逐个预测的,即每一次根据当前指令块的预测起始地址去计算其下一个指令块的预测起始地址。
[0080]
指令块的信息包括指令块的行线性地址、行物理地址、起始偏移、结束偏移以及跳转位,等等。
[0081]
分支预测模块10在每个周期的预测过程中使用的地址(如当前指令块的预测起始地址,等等)均是线性地址形式。然而,取指地址队列20保存的地址为物理地址形式,这是由于缓存系统中使用的地址都是物理地址,缓存替换决策模块60将使用候选项的物理地址检索取指地址队列和访存地址队列。因此,取指地址队列20中保存的地址需要是线性地址对应的物理地址。
[0082]
因此,根据当前指令块的预测起始地址可以确定当前指令块的行线性地址和起始偏移,在当前指令块的信息中的行线性地址写入取指地址队列时,先需要经过tlb(translation lookaside buffer,转译后备缓冲区)的检索以得到行物理地址,并将行线性地址和行物理地址均保存在取指地址队列20中。
[0083]
具体来说,在将指令块的信息写入取指地址队列20时,需要将48位的指令块的预测起始地址拆分为高42位的行线性地址和低6位的起始偏移,并通过42位的行线性地址查询tlb得到34位的行物理地址,并将得到的行线性地址、行物理地址和起始偏移写入取指地址队列20的条目项中的对应域。此外,如果指令块命中的跳转的分支指令,则第一个跳转的分支指令的末尾字节偏移作为结束偏移写入取指地址队列20;否则,取指地址队列20中的结束偏移设置为63。此外,如果当前指令块命中跳转的分支指令,则将取指地址队列20中的条目项中的跳转位置1。
[0084]
因为每个指令块的预测是相对独立的,在其他实施例中,也可以采用并行的方式同时预测多个指令块的预测起始地址。
[0085]
相应地,所述分支预测模块10设置为执行如下步骤:
[0086]
步骤a1’:在每个周期(即当前预测地址初始化或者更新时),将当前预测地址所在的指令块作为当前指令块,将当前预测地址作为当前指令块的预测起始地址;随后,根据当前指令块的预测起始地址确定从当前指令块开始的固定预测窗口中的所有指令块的预测起始地址;
[0087]
如上文所述,如果第一个指令块的范围是[5,63],第二个指令块的范围就是[64,127],第三个指令块的范围就是[128,191]。除了第一个指令块外,其它指令块的起始地址都是64b对齐的。
[0088]
步骤a2’:根据各个指令块的预测起始地址,在各个指令块中对分支指令进行检索和预测,以判断各个指令块是否命中跳转的分支指令;
[0089]
步骤a3’:根据判断结果,若所有指令块均未命中跳转的分支指令,则将所有指令块的信息作为分支预测模块10的预测结果依次写入取指地址队列;当前预测地址根据固定预测窗口中的指令块的个数自增;
[0090]
否则,若存在至少一个指令块命中至少一个跳转的分支指令,则从命中的跳转的分支指令中选择线性地址最小的第一个跳转的分支指令作为当前指令块的结尾地址,将当前指令块及其前面的所有指令块的信息作为预测结果写入取指地址队列,同时将当前预测地址更新为第一个跳转的分支指令的跳转地址。
[0091]
(二)取指地址队列20
[0092]
再请参见图3,取指地址队列20设置为以指令块为单位,存放分支预测模块10写入的预测结果,在本发明的设计中,取指地址队列有4096个条目项。在本实施例中,取指地址队列中的每一条目项表示一个64b的指令块的预测结果。64b的宽度是为了和取指单元100在访问一级指令缓存时的64b带宽匹配。
[0093]
取指地址队列每一条目项的结构可以表示为:
[0094]
《valid,line_addr,phys_addr,begin_offset,end_offset,taken》,
[0095]
其中,valid表示有效位;line_addr表示行线性地址;phys_addr表示行物理地址;begin_offset表示起始偏移;end_offset表示结束偏移;taken表示跳转位。
[0096]
其中,行线性地址、起始偏移和结束偏移确定了64b指令块内有效字节的范围,这个有效字节的范围用于检索访存指令记录模块30,查询指令块内存在的访存指令。取指地址队列中的每一个条目项代表一个指令块,每个指令块都包含起始偏移和结束偏移,各个指令块的顺序相连构成了目标程序的指令流。行物理地址用于缓存替换决策模块60查询替换候选项的重用距离时进行地址匹配计算。跳转位用于表示当前条目项对应的数据块是否具有跳转的分支指令。
[0097]
如图5所示,所述取指地址队列20还设有提交指针,读指针和写指针,这三个指针各自指向取指地址队列中的其中一个条目项,每个指针都可以看作为[0,4095]范围内的一个编号。
[0098]
取指地址队列20的提交指针指向下一个将提交的指令所在的指令块在取指地址队列20中的条目项。当某个指令块中的所有指令都在主流水线中提交后,该指令块所对应的条目项可以从取指地址队列中移除,此时提交指针加1。具体来说,主流水线中的写回单元500设置为在每个周期向取指地址队列20反馈正在提交的指令在取指地址队列20中的编号,当这个编号大于提交指针时,可以确认提交指针所指向的指令块中的所有指令均已在主流水线中提交,此时提交指针加1。提交指针之前的条目项并不需要主动清空,分支预测模块10的预测结果只能够写入提交指针之前的条目项,从而自动覆盖提交指针之前的条目项。
[0099]
取指地址队列20的读指针指向下一个将读取的指令所在的指令块在取指地址队列中的条目项。当取指单元100当前读取的指令块中的所有指令被读取完成时,读指针加1,以保证取指地址队列20的读指针一直指向下一个将读取的指令所在的指令块在取指地址队列中的条目项。
[0100]
也就是说,取指地址队列提交指针和读指针之间的指令块已经处于处理器的主流水线中(即从取指单元100到写回单元500的执行流程)。
[0101]
取指地址队列20的写指针指向分支预测模块10下一次写入的位置,用于在分支预测模块10写入新的条目项时确定写入的位置。写指针设置为在每次分支预测模块10写入新的条目项时加1。因此,读指针和写指针之间的指令块是有效预测指令块,写指针和提交指
针结合则可以判断取指地址队列20的空满情况(即取指地址队列20是否写满)。
[0102]
处理器的主流水线刷新发生后,根据刷新类型,读、写指针会回滚到分支刷新的位置或者提交指针的位置。具体来说,当分支刷新发生时(即刷新类型为分支刷新),主流水线中的执行单元300会向取指地址队列20反馈刷新的分支指令在取指地址队列20中的编号作为分支指令刷新指针,读、写指针回滚到分支刷新的位置。当写回刷新发生时(即刷新类型为写回刷新),读、写指针回滚到提交指针的位置。需要说明的是,刷新过程并不会主动清空队列中的数据,只会改变读、写指针的赋值。分支预测不是100%准确的,因此取指地址队列中的预测结果有可能是错误的,此时需要借助刷新过程使得读、写指针回滚,从而把错误的数据清除掉,以重新写入正确数据。
[0103]
(三)访存指令记录模块30
[0104]
再请参见图3,访存指令记录模块30设置为接收写回单元500的反馈的访存指令信息,依次记录其中的已经提交的访存指令的信息,将这些访存指令的信息写入到一访存指令缓冲31中。由此,能够判断指令块中是否包含访存指令。
[0105]
访存指令记录模块30具有访存指令缓冲31,其存储结构为表结构,其具有4096个表项。
[0106]
访存指令的信息(即已经提交的访存指令的信息)包括访存指令的pc、线性地址、访存指令的访存地址、类型以及访存长度等信息。
[0107]
访存指令缓冲31的每一个表项的结构表示为:
[0108]
《lineaddr,phyaddr,insttype,memlen》,
[0109]
其中,lineaddr表示访存指令的指令线性地址;phyaddr表示访存指令在上一次执行时的访存物理地址;insttype表明访存指令的类型,insttype∈{directinst,indirectinst},其中directinst表示直接访存指令,indirectinst表示间接访存指令;memlen表明访存指令的访存长度。
[0110]
访存指令记录模块30还设置为:每当取指地址队列20写入新的条目项时,用该条目项所对应的指令块的起始地址(即行线性地址+起始偏移)查询所述访存指令缓冲31,以通过查询尝试得到访存指令的指令线性地址(即位置)lineaddr和类型insttype,并将其依次作为访存指令序列中的访存指令的取指地址队列索引输出至访存指令学习模块40和访存地址队列50。即,如果指令块中包含多条访存指令,则根据访存指令的指令线性地址(即位置)按顺序排列,以得到访存指令序列。取指地址队列20的新增条目项所对应的访存指令的指令线性地址lineaddr(即位置)作为取指地址队列索引会在之后发送给访存指令记录模块40以供查询,且这个取指地址队列索引会在后续流程中发送给访存地址队列50,以记录访存指令的位置。访存指令的类型则用于访存指令学习模块40在多种模式之间进行选择的。
[0111]
由此,通过访存指令记录模块30,可以根据分支预测模块10预测的程序的指令块序列获得程序的访存指令序列。
[0112]
其中,访存指令记录模块30设置为在查询过程中使用访存指令缓冲31的所有表项中的访存指令的指令线性地址进行命中判定,在访存指令命中时得到访存指令在访存指令缓冲31中的位置和类型,从而通过查询访存指令缓冲31中所有的访存指令来尝试得到访存指令的指令线性地址(即位置)和类型。
[0113]
访存指令缓冲31的查询过程如图6所示。如图6所示,访存指令缓冲31的命中判定是一个包含关系的判定,取指地址队列20中的每一个条目项对应于指令块,其是一个区间范围;因此,在进行命中判定时,需要判定各个访存指令的指令线性地址是否在取指地址队列20写入新的条目项所在的区间范围内,若存在访存指令在所述区间范围内,则该访存指令查询命中,否则,查询命中失败,即没有命中任何访存指令,说明新的条目项对应的指令块中没有访存指令,此时什么操作都不进行。
[0114]
在本实施例中,取指地址队列20新添加的条目项中包括指令块的48位的起始地址和48位的结束地址,可以转化为高42位的线性地址高位标签(即行线性地址)和低6位的起始偏移和结束偏移。因此,在查询过程中,使用指令块的标签和偏移查询访存指令缓冲31中所有的访存指令,当访存指令缓冲31中存在一条访存指令的指令线性地址的高位标签与新的条目项所对应的指令块的行线性地址相同,并且其低位偏移大于等于指令块的起始偏移,小于等于指令块的结束偏移的时候,说明该访存指令位于该指令块中,即该访存指令查询命中,得到访存指令的指令线性地址(即位置)和类型。
[0115]
此外,本发明在访存指令缓冲31的基础上还另外新增了步长预测器和时间关联预测器,这些预测器包含在下文将详述的访存模式学习模块40中,从而能够对符合特定模式的访存指令进行预测。
[0116]
(四)访存模式学习模块40
[0117]
再请参见图3,访存模式学习模块40设置为将访存指令记录模块30发送的访存指令序列记录在访存历史缓冲中,根据访存历史缓冲中保存的历史信息对访存指令的访存模式进行学习,并根据学习到的访存模式来预测访存指令序列中每条访存指令的访存物理地址,将每条访存指令的访存物理地址作为预测结果写入到访存地址队列50。
[0118]
访存模式学习模块40包括访存历史缓冲,其设置为接收处理器写回阶段反馈的访存指令信息(包括pc、类型和访存物理地址),根据访存指令的pc将访存指令的访存物理地址写入访存历史缓冲中该访存指令所对应的表项中,每一条表项为一条历史信息。
[0119]
需要说明的是,访存指令记录模块30的访存指令缓冲31和访存模式学习模块40的访存历史缓冲存在一定的相似性,两者的区别在于:访存指令记录模块30中的访存指令缓冲31保存指令相关信息,比如访存指令的指令线性地址,访存指令类型等;访存指令缓冲中也会保存访存物理地址,但是只记录了上一次的访存物理地址的结果。而访存模式学习模块40中的访存历史缓冲主要是为了记录过往访存历史,记录有过往12次的访存物理地址,在此基础上才可以进行访存模式的学习。由于访存指令缓冲31和访存历史缓冲这两个存储阵列确实存在一定的相似性,所以这两个阵列设计成等大的。虽然访存指令缓冲31和访存历史缓冲逻辑上是两个阵列,但是在具体实现中访存指令缓冲31和访存历史缓冲可以统一存储在同一硬件位置,以合并在一起。
[0120]
访存历史缓冲是一个由访存指令的pc作为索引的阵列,共4096个表项。访存历史缓冲中的每一个表项都是一个12项的循环队列,记录有同一访存指令过去12次的访存物理地址。具有同一pc的访存指令被认定为同一个访存指令。
[0121]
本发明中基于访存历史缓冲的访存模式学习过程同现有算法是有明显区别的。如图7(a)所示,传统的时间关联预取算法基于全局失效缓冲而非访存历史缓冲来进行访存模式的获取,时间关联预取算法中缓存失效是预取请求生成的触发条件,使用缓存失效的地
址a检索全局失效缓冲,获取以地址a作为首地址的地址序列{a,b,c,d}。{b,c,d}这三个地址即为地址a的预取候选项,a,b,c,d均可以用来发送预取请求。为了保证预取请求能够覆盖更多的缓存失效场景,在检索以地址a为首地址的地址序列时一般采用最长匹配原则,以便能够发出更多的预取请求。并且为了防止过多的预取请求浪费缓存系统带宽,发出的预取请求的个数通常受预取深度(degree)的制约。对传统算法而言,地址序列的长度(即预取深度)并不影响预测的准确性,长度只起到控制预取提前量的作用。
[0122]
如图7(b)所示,在本发明中的访存指令m所在的指令块可能在取指地址队列20中出现多次,本发明需要为访存指令m的每次出现独立进行地址预测。如果访存指令m的访存物理地址的行为符合模式{a,b,c,d},a,b,c,d均是访存指令m的访存物理地址,则本发明必须在学习到步长模式的长度为4的前提下才能准确预测访存指令m第五次出现时的访存物理地址为a。因此,经过学习得到的访存模式的步长模式是本发明在学习阶段必须要考虑的因素。
[0123]
因此,所述访存模式学习模块40包括步长预测器和时间关联预测器,使得访存模式学习模块40在访存历史缓冲的基础上通过步长预测器和时间关联预测器实现步长模式、时间关联模式等多种访存模式的学习和预测。
[0124]
本发明的步长预测器基于传统的ibsp(智能盲信号处理方法)算法。在本实施例中,步长预测器的每一条目项用于记录一种步长模式,所述步长模式是指步长访存序列,条目项的结构如图8所示,步长预测器的每一条目项包括一个步长访存序列的标签、上一次地址、上一次步长、可信计数器、当前模式、首地址、最大计数器和方向。也就是说,在传统的ibsp算法的基础上,本发明的步长预测器的条目项扩展了可信计数器,当前模式,首地址以及最大计数器等内容。原本的ibsp算法只需要记录步长信息,因为数据的预取操作仅仅是在当前的访存物理地址的基础上计算出来的。针对步长访存序列{a,a+k,a+2k,...,a+nk}这样的固定步长模式的访存物理地址的序列,本发明的步长预测器不仅要记录其步长k,同时也要记录步长访存序列的起始地址a以及最大计数值n。因此,为了增加步长预测器的准确性,步长预测器增加了可信计数器和当前模式。具体来说,当上一次步长和当前步长相同时,可信计数器加一,否则可信计数器清零。当可信计数器的数值大于某个阈值时,将当前模式置1,表明当前访存指令的行为确实是符合步长模式的。若当前模式为0,则表明当前尚处于学习阶段,学习阶段的步长预测器不输出预测结果。步长预测器还包括步长和方向位,步长始终是正值,方向位决定步长访存序列是递增还是递减。在步长预测器在进行访存指令的条目项分配时,将该条目项的首地址设置为当前的访存物理地址。在步长模式计数过程中,首地址是不更新的,只更新上一次地址为当前最新的访存物理地址,通过这种方式将一个步长访存序列的首地址保存下来。当步长预测器为某条符合步长访存序列的访存指令进行更新时,发现当前的访存指令的访存物理地址恰好等于步长预测器中当前的步长访存序列的首地址,说明该首地址所对应的步长访存序列又被重新执行了一遍。此时将可信计数器的值更新到最大计数器中,使得步长访存序列的头和尾都被记录下来。
[0125]
下面示例性地给出步长模式的识别算法。
[0126]
算法1.步长模式识别算法
[0127]
输入:提交的访存指令pc和物理地址physaddr;
[0128]
输出:是否是步长模式
[0129]
if(当前模式==步长模式);
[0130]
if(当前方向和步长与历史记录不符)
[0131]
if(physaddr==首地址&&(最大计数器==0||可信计数器!=最大计数器))
[0132]
最大计数器=可信计数器;
[0133]
else
[0134]
清空步长相关信息;
[0135]
end if
[0136]
else
[0137]
可信计数器++;
[0138]
if(最大计数器!=0&&可信计数器》最大计数器)
[0139]
最大计数器=可信计数器;
[0140]
end if
[0141]
end if
[0142]
else
[0143]
if(当前方向和步长与历史记录不符)
[0144]
清空步长相关信息;
[0145]
else
[0146]
可信计数器+1;
[0147]
if(可信计数器》学习阈值)
[0148]
当前模式=步长模式;
[0149]
end if
[0150]
end if
[0151]
end if
[0152]
时间关联预测器的每一条目项用于记录一种时间关联模式,时间关联模式是指以固定的次序重复出现的一段访存序列,即,一个时间关联访存序列。所述时间关联预测器的每一条目项包括时间关联模式、时间关联序列长度和时间关联序列。例如我们观察到{a,b,c,d,a,b,c,d}这样的访存序列之后,{b,c,d}这样的序列有很大概率紧接着在a之后出现。指令级访存行为中也存在时间关联模式。
[0153]
算法2.时间关联模式识别
[0154]
输入:过去12次访存物理地址;
[0155]
输出:时间关联信息;
[0156]
将过去12次访存物理地址记录在访存历史缓冲[11:0]中;
[0157]
if(访存历史缓冲[3n-1:0]匹配
[0158]
{a1,a2,
…
,an,a1,a2,
…
,an,a1,a2,
…
,an})
[0159]
时间关联模式=1;
[0160]
时间关联序列长度=n;
[0161]
时间关联序列=访存历史缓冲[n-1:0];
[0162]
end if
[0163]
时间关联预测器依赖访存历史缓冲中记录的每一条访存指令过去12次的访存物
理地址,根据这12次历史信息识别时间关联模式。本发明的算法中相同访存序列重复3次才能确认为时间关联模式,支持序列长度不超过4的时间关联模式。
[0164]
除此基本的时间关联模式之外,本发明算法还支持形如{a,b,c,a+n,b+n,c+n,a+2n,b+2n,c+2n,
…
}这样的“步长-时间关联模式”。
[0165]
(五)访存地址队列50
[0166]
再请参见图3,访存地址队列50用来存放访存指令记录模块30和访存模式学习模块40的预测结果,即访存指令记录模块30所输出的访存指令序列以及访存模式学习模块40所输出的每条访存指令的访存物理地址。访存地址队列50中的内容可以看作一级数据缓存的未来访问序列。
[0167]
访存地址队列50有多个条目项,每个条目项对应于一条访存指令的信息并且对应于取指地址队列20中的一个条目项。访存地址队列50具有对应于取指地址队列20中提交指针、读指针和写指针所指向的条目项的提交指针、读指针和写指针。具体来说,访存地址队列50的提交指针指向下一个将提交的指令在访存地址队列50中的条目项,访存地址队列50的读指针指向下一个将读取的指令在访存地址队列50中的条目项,访存地址队列50的写指针指向访存指令记录模块30和访存模式学习模块40下一次写入的位置。
[0168]
在本实施例中,访存地址队列50有65536个条目项。65536是在取指地址队列20有4096个条目项的基础上得出,由于取指地址队列20的每个条目项代表一个64b对齐的指令块,我们假设每个指令块中最多有16条访存指令,因此4096个指令块中最多包含65536条访存指令。访存地址队列50中的每一条目项对应一条访存指令的信息,每个取指地址队列20中的一个条目项可能对应于访存地址队列50的0到16个条目项。此时,由于并不是所有的64b指令块中都有16条访存指令,访存地址队列50的容量是存在设计冗余的。
[0169]
访存地址队列50中每一条目项的结构表示为:
[0170]
《valid,inst_line_addr,mem_phys_addr,memlen,inst_queue_index》,
[0171]
其中,valid表示有效位;inst_line_addr表示指令线性地址;mem_phys_addr表示访存物理地址;memlen表示访存长度,根据访存物理地址和访存长度可以识别跨行的访存指令;inst_queue_index表示取指地址队列索引,便于在流水线刷新时进行取指地址队列和访存地址队列的同步刷新。
[0172]
其中,指令线性地址inst_line_addr、访存长度memlen和取指地址队列索引inst_queue_index来自访存指令记录模块30中的访存指令缓冲31,访存物理地址mem_phys_addr来自访存模式学习模块40或者访存指令记录模块30。如果访存模式学习模块40识别到该访存指令所属的步长模式和/或时间关联模式,则该访存指令的访存物理地址由访存模式学习模块40中的对应预测器给出;否则,说明访存指令不属于特定模式,则访存物理地址来自于访存指令缓冲31中的访存指令在上一次执行时的物理地址。
[0173]
下面描述访存地址队列50在主流水线发生分支刷新时的刷新流程的原理。在主流水线发生分支刷新时,主流水线的执行单元向取指地址队列20反馈分支指令在取指地址队列20中的编号,取指地址队列20的读、写指针根据分支指令的编号作为分支指令刷新指针进行回滚到分支刷新的位置。同时,分支指令在取指地址队列20中的编号同样也会发送给访存地址队列50,访存地址队列50首先从提交指针的位置开始遍历队列,找到条目项的取指地址队列索引inst_queue_index等于分支指令在取指地址队列20中的编号的第一个条
目项的位置,该位置为分支刷新的位置,然后将访存地址队列50的读、写指针回滚到分支刷新的位置。
[0174]
(六)预取请求生成模块60
[0175]
预取请求生成模块60设置为:当一级数据缓存接收到新的请求时,检索所述取指地址队列20和访存地址队列50,为即将进入主流水线的指令块分别生成一级指令缓存和一级数据缓存的预取请求,并将一级指令缓存和一级数据缓存的预取请求均发送到缓存系统中,以获取拿到数据的预取请求。
[0176]
处理器中的一级缓存分为一级指令缓存和一级数据缓存,取指地址队列和访存地址队列分别是一级指令缓存和一级数据缓存的未来访存序列。而取指地址队列20中保存的是完整的指令序列,包括分支指令、运算指令和访存指令等。访存地址队列50需要从完整的指令流中分离出访存指令,因此取指地址队列20是访存地址队列50的基础。
[0177]
如图9所示为预取请求生成模块60的工作原理图。当访存单元400中的一级数据缓存有新的读/写访问请求到达时,会向预取请求生成模块60发送消息通知有新的读/写发生,作为预取过程的触发事件。预取过程的触发需要一个足够频繁的事件,而只要处理器在运行,就一定会有一级数据缓存的访问,因此选择读/写访问请求作为触发条件能够保证预取的及时性。
[0178]
根据上文所述,访存地址队列50中保存了将要进入处理器的主流水线的访存指令的访存物理地址,因此,访存地址队列50的每一个条目项均是预取请求候选项。但是,预测子流水的预测带宽(128b)大于cpu的主流水线的取指带宽(64b),并且在cpu的主流水线因为某些原因阻塞的情况下,预测子流水依然可以继续工作,因此预测子流水相对于主流水线来说提前预测了很多,分支预测子流水的执行速率在大部分情况下会远远领先于cpu主流水线的执行速率,写入访存地址队列50的访存指令很可能在很久之后才会被程序执行。因此,将预取请求发送到缓存系统最恰当的时机不是指令写入访存地址队列50的时刻,而是指令所对应的指令块将要进入主流水线的时刻。具体来说,所述预取请求生成模块60根据取指地址队列20的读指针来确定即将进入主流水线的指令块。
[0179]
因此,所述预取请求生成模块60设置为执行如下步骤:
[0180]
步骤b1:在收到一级数据缓存收到新请求的消息后,检索取指地址队列20,获得其读指针的位置,将在读指针上添加一预取提前量后的位置作为预取起始,将以预取起始为第一个预取指令块的连续n个预取指令块作为即将进入主流水线的指令块,为即将进入主流水线的指令块生成相应的一级指令缓存的预取请求。由此,为实现一级指令缓存预取请求的发送过程做准备。
[0181]
其中,位于取指地址队列20的读指针之后的指令块都是即将进入流水线的,通过在读指针的基础上添加一预取提前量,作为预取指令块的起始(即预取起始),所述预取提前量为固定值,由实验环节根据最优效果测出,并且预取提前量不改变读指针本身的位置。在本实施例中,所述预取提前量的实际取值为120。每次预取过程会为连续的n个预取指令块发送预取请求。n为预取数,预取数n控制了每次能够发出的预取请求的个数,在本实施例中,预取数n的值为4。
[0182]
在所述步骤b1中,对取指地址队列20中有效预测指令块的个数进行统计——用写指针减去读指针的距离作为有效预测指令块的个数,并根据统计结果决定是否继续执行预
取请求的生成过程。具体来说,只有当统计结果是有效预测指令块个数大于预取提前量和预取数n之和时,才继续进行一级指令缓存的预取请求的生成。
[0183]
一级数据缓存有新的请求到达是预取过程的触发条件,是总开关,而预取提前量和预取数n的类似于控制逻辑中的一个阈值,这个阈值是可以调整的。
[0184]
步骤b2:接收取指地址队列20所反馈的各个预取指令块的指针(即预取指令块在取指地址队列20中的编号),使用这些预取指令块的指针检索访存地址队列50中的取指地址于预取队列头部的拿到数据的预取请求根据所述预取请求之前的指令提交情况等待写回或者立即写回至一级缓存。
[0185]
这些拿到数据的预取请求具备用于写入一级缓存的数据,但是预取请求拿到数据之后立刻写回缓存阵列有可能将缓存中的有效数据踢出。因此,为了防止写入过程中从一级缓存中踢出重用距离比预取请求更小的缓存项,需要将预取请求按照时间顺序依次存入预取队列,并使得预取请求在预取队列中等待可以写回的时刻。
[0186]
预取队列是一个50项的循环队列,位于预取队列头部的是即将要写入缓存的拿到数据的预取请求。预取请求会先在预取队列中进行等待写回的时刻,直到确信一级缓存的阵列中存在一个可替换项,此时写回至一级缓存。其中,若预取请求之前的指令提交情况为访存地址队列50中在预取请求之前没有在一级缓存的阵列中与所述预取指令同组的其他指令尚未提交,则确信一级缓存的阵列中存在一个可替换项,此时将所述预取指令写回至一级缓存。
[0187]
其中,一级缓存的阵列采用最常见的结构,即组相连结构。64项的一级缓存的阵列用16*4矩阵的方式表示,矩阵的行就是“组”,矩阵的列就是“路”。64项的缓存阵列的结构就可以描述为16组,4路。组相连结构的缓存阵列在进行写操作时,首先根据物理地址获取组的编号,然后根据缓存替换策略选择写入的路号,以将预取请求的数据写入。
[0188]
如图10所示为以一级数据缓存预取请求为例的,预取请求的写回等待过程的原理图。根据上文所述,所述预取请求生成模块60在取指地址队列20中根据预取提前量确定预取起始,将访存地址队列50中对应于所述预取起始的预取请求m发送到缓存系统中,获取拿到数据的预取请求。预取请求写回模块70设置为将拿到数据的预取请求暂存在其预取队列中;对于位于预取队列的头部的预取请求m,将检索访存地址队列50在其提交指针之后和预取请求m之前的未提交指令集(未提交指令集包括所述提交指针,但不包括预取请求m),判断在未提交指令集中是否存在一级数据缓存的阵列中与所述预取请求m同组的其他访存指令,并根据判断结果(该判断结果即所述预取请求之前的指令提交情况),若判断为存在与所述预取请求m同组的其他访存指令,并且与所述预取请求m同组的访存指令个数至少为缓存阵列的路数,则将所述预取请求m等待写回,否则,将所述预取请求m立即写回一级数据缓存。
[0189]
如图9中的a,b,c,d四条访存指令的地址和预取请求m同组,假设缓存阵列只有4个路号,同组指令个数恰好等于缓存阵列中路号的数目,则预取请求m替换a,b,c,d中的任何一条指令都是影响性能的。此时需要找到第一条指令a在取指地址队列中的位置l,只有当取指地址队列的提交指针超过l时才能将预取请求m写入缓存阵列。由此,当取指地址队列的提交指针超过l时,可以确定指令a在处理器主流水中一定已经执行完毕了。此时第一条指令a的数据仍然在缓存阵列中,但是因为其已经使用过了,用预取请求m的数据替换第一
条指令a并不会带来性能损失。反之,如果在第一条指令a执行完毕之前就用预取请求m的数据替换第一条指令a,第一条指令a在执行的时候就会产生额外的缓存失效。
[0190]
如果预取请求是一级指令缓存的预取请求,那么就只需要相应地检索取指地址队列20。在程序执行过程中,一级指令缓存未命中的次数相比一级数据缓存是少很多的。本发明的缓存预取方法中更多关注的是数据请求的预取。因此,本发明的实验环节也只针对一级数据缓存进行了实验,因为很多spec程序的一级指令缓存失效次数是0,对一级指令缓存进行预取没有任何实验的意义。
[0191]
本发明的基于指令流混合模式学习的低污染缓存预取系统假设访存地址队列的预测是准确的。如果预测出现错误,此处的逻辑可能会带来一些性能损失。
[0192]
基于上文所述的基于指令流混合模式学习的低污染缓存预取系统,所实现的基于指令流混合模式学习的低污染缓存预取方法,包括:
[0193]
步骤s1:利用一分支预测模块10,采用提前预测技术,对目标程序的指令流进行预测并将预测结果写入取指地址队列中;取指地址队列20写满则暂停预测过程;
[0194]
所述步骤s1包括:
[0195]
步骤a1:在每个周期,将当前预测地址所在的指令块作为当前指令块,将当前预测地址作为当前指令块的预测起始地址;根据当前指令块的预测起始地址确定从当前指令块开始的固定预测窗口;
[0196]
步骤a2:在获得当前指令块的预测起始地址后,在当前指令块中对分支指令进行检索和预测,以判断当前指令块是否命中跳转的分支指令;
[0197]
步骤a3:根据判断结果,若当前指令块未命中跳转的分支指令,说明当前指令块中没有分支指令或者识别到的分支指令均未跳转,则将当前指令块的信息作为分支预测模块10的预测结果写入取指地址队列;随后,确定下一指令块的预测起始地址,并将下一指令块作为新的当前指令块,并回到步骤a2,直到当前指令块为固定预测窗口中的最后一个指令块,此时当前预测地址根据固定预测窗口中的指令块的个数自增,从而实现当前预测地址的更新,进入下一个周期;
[0198]
否则,从命中的跳转的分支指令中选择线性地址最小的第一个跳转的分支指令作为当前指令块的结尾地址,将当前指令块的信息作为预测结果写入取指地址队列,同时将当前预测地址更新为第一个跳转的分支指令的跳转地址,以进入下一个周期。
[0199]
或者,所述步骤s1包括:
[0200]
步骤a1’:在每个周期(即当前预测地址初始化或者更新时),将当前预测地址所在的指令块作为当前指令块,将当前预测地址作为当前指令块的预测起始地址;随后,根据当前指令块的预测起始地址确定从当前指令块开始的固定预测窗口中的所有指令块的预测起始地址;
[0201]
步骤a2’:根据各个指令块的预测起始地址,在各个指令块中对分支指令进行检索和预测,以判断各个指令块是否命中跳转的分支指令;
[0202]
步骤a3’:根据判断结果,若所有指令块均未命中跳转的分支指令,则将所有指令块的信息作为分支预测模块10的预测结果依次写入取指地址队列;当前预测地址根据固定预测窗口中的指令块的个数自增,以进入下一个周期;
[0203]
否则,若存在至少一个指令块命中至少一个跳转的分支指令,则从命中的跳转的
分支指令中选择线性地址最小的第一个跳转的分支指令作为当前指令块的结尾地址,将当前指令块及其前面的所有指令块的信息作为预测结果写入取指地址队列,同时将当前预测地址更新为第一个跳转的分支指令的跳转地址,以进入下一个周期。
[0204]
步骤s2:利用一访存指令记录模块30,记录已经提交的访存指令的信息,将这些访存指令的信息写入到一访存指令缓冲中;每当取指地址队列20写入新的条目项时,用该条目项所对应的指令块的起始地址查询所述访存指令缓冲,以通过查询尝试得到访存指令序列并将其输出至访存指令学习模块和访存地址队列;
[0205]
步骤s3:利用访存指令学习模块40,将访存指令序列记录在访存历史缓冲中,根据访存历史缓冲中保存的历史信息对访存指令的访存模式进行学习,并根据学习到的访存模式来预测访存指令序列中每条访存指令的访存物理地址,将每条访存指令的访存物理地址写入到一访存地址队列;
[0206]
步骤s4:利用预取请求生成模块60,在一级数据缓存接收到新的请求时,检索所述取指地址队列和访存地址队列,为即将进入主流水线的指令块分别生成一级指令缓存和一级数据缓存的预取请求并将其发送到缓存系统中,以获取拿到数据的预取请求;
[0207]
在所述步骤s4中,所述预取请求生成模块60根据取指地址队列20的读指针来确定即将进入主流水线的指令块;
[0208]
步骤s4包括:
[0209]
步骤b1:在收到一级数据缓存收到新请求的消息后,检索取指地址队列,获得其读指针的位置,将在读指针上添加一预取提前量后的位置作为预取起始,将以预取起始为第一个预取指令块的连续n个预取指令块作为即将进入主流水线的指令块,为即将进入主流水线的指令块生成相应的一级指令缓存的预取请求;
[0210]
步骤b2:接收取指地址队列所反馈的各个预取指令块的指针,使用这些预取指令块的指针检索访存地址队列中的取指地址队列索引,获取各个预取指令块中包含的访存指令以及其访存物理地址,根据访存指令的访存物理地址来生成一级数据缓存的预取请求;
[0211]
步骤b3:将一级指令缓存的预取请求和一级数据缓存的预取请求均发送给缓存系统,以获取拿到数据的预取请求。
[0212]
步骤s5:利用预取请求写回模块70,将拿到数据的预取请求暂存在其预取队列中,使得位于预取队列头部的拿到数据的预取请求根据所述预取请求之前的指令提交情况等待写回或者立即写回至一级缓存。
[0213]
在所述步骤s5中,对于位于预取队列的头部的预取请求,将检索访存地址队列50在其提交指针之后和所述预取请求之前的未提交指令集,判断在未提交指令集中是否存在一级缓存的阵列中与所述预取请求同组的其他访存指令并将判断结果作为所述预取请求之前的指令提交情况;若判断为存在与所述预取请求同组的其他访存指令,并且与所述预取请求同组的访存指令个数至少为缓存阵列的路数,则将所述预取请求等待写回,否则,将所述预取请求m立即写回一级缓存。
[0214]
对本发明的实验验证:
[0215]
采用gem5模拟器作为基础实验环境,使用alpha指令集。使用derivo3cpu细粒度cpu模型,分支预测算法为tage_l,一级缓存32kb,二级缓存256kb,取指位宽64b,内存4gb。选择spec2006测试程序对比本发明方式和其他方法的性能。
[0216]
表1不同spec程序读操作失效次数对比队列索引(即inst_queue_index域),获取各个预取指令块中包含的访存指令以及其访存物理地址,根据访存指令的访存物理地址来生成一级数据缓存的预取请求;由此,为实现一级数据缓存预取请求的发送过程做准备。
[0217]
步骤b3:将一级指令缓存的预取请求和一级数据缓存的预取请求均发送给缓存系统,以获取拿到数据的预取请求。
[0218]
其中,预取请求会根据地址将64b对齐的数据从内存中读取出来,写入缓存系统并最终写入到一级缓存中,因此,这里拿到的数据指的就是从内存中读取上来的64b数据。
[0219]
(七)预取请求写回模块70
[0220]
预取请求写回模块70设置为将拿到数据的预取请求暂存在其预取队列中,使得位 未预取stemsbopisbstrideifbtslbm493947494368381635494291187410153940bzip2180765184835184124177324177003172128gemsfdtd586680586701553972586635510435123719gobmk674636963668240661675130258829astar918990919174h264ref2615612638302154652600429155861381hmmer43410440404301943199419244352soplex813733811522624612813817287799230243bwaves57861257870337233757861117437788849sjeng10160120031109099081047511458
[0221]
表2不同spec程序写操作失效次数对比 未预取stemsbopisbstrideifbtslbm427392423352358226393252153874140457bzip2183061824717967182481580915655gemsfdtd333333gobmk583435885758022561754732553317astar655646556459548655643929618915h264ref461146855291461444263017hmmer1685771684881655411685191531746492soplex106596106552898081066057314751185bwaves232323232323sjeng273952787329417272522420628584
[0222]
在进行性能对比的时候我们分别统计了一级数据缓存的读/写操作的缓存失效次数。如表1和表2所示,针对读操作本发明方法相比stride,stems,bop,isb算法缓存失效次数分别平均减少28.26%,51.47%,47.28%,48.75%;针对写操作本发明方法相比stride,stems,bop,isb算法缓存失效次数分别平均减少18.84%,34.28%,33.49%,33.26%。
[0223]
也就是说,当前,缓存系统瓶颈导致高性能处理器的性能无法得到充分发挥,本发明的系统及方法对提升处理器性能有显著的作用。
[0224]
本发明方法适用于所有的处理器微架构,不局限于特定的分支预测算法和指令
集,当然可能由于指令集以及特定处理器微架构的不同,具体实现过程可能稍有变化,但也属于本发明保护的范围。
[0225]
以上实施例仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的精神和范围,本发明的保护范围应以权利要求书所述为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1