一种基于改进KNN的分布式地铁客流预测方法与流程
一种基于改进knn的分布式地铁客流预测方法
技术领域
1.本发明涉及交通技术领域,具体涉及一种基于改进knn的分布式地铁客流预测方法。
背景技术:
2.现阶段,地铁交通成为人们日常的出行方式。然而,随着城市人口的不断增加,地铁站拥堵问题频繁发生。预测地铁客流极其重要。根据预测的客流人数,地铁站可以实时调度人力物力,以缓解地铁站拥堵的问题。
3.通过分析单个地铁站每日的客流数据,可以发现单个地铁站客流存在一定的规律。本研究提出将单个地铁站的历史入站刷卡数据与预测当天实时刷卡数据相结合,融合knn(k近邻)和lightgbm(light gradient boosting machine),在分布式系统下预测地铁客流的方法。
4.现有的方法存在以下问题:
5.1、传统的预测方法,结果精度不高。
6.2、现有精度较高的预测方法在数据量大时,运行时间较长。
技术实现要素:
7.发明目的:本发明提供了一种基于改进knn的的分布式地铁客流预测方法,其目的在于能够在历史数据庞大的条件下,借助分布式系统并行处理数据的方法建立预测模型来预测当天地铁客流。
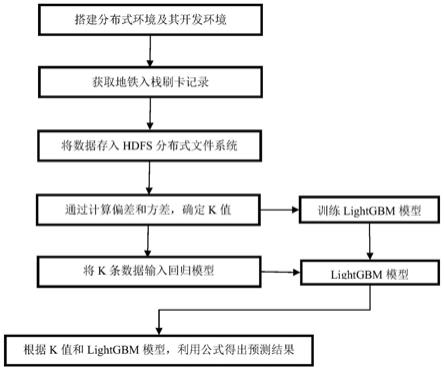
8.一种基于改进knn的的分布式地铁客流预测方法,包括以下步骤:
9.步骤1:搭建hadoop分布式环境,hadoop分布式环境包括hdfs(hadoop distributed file system)分布式文件系统,搭建服务器的spark分布式环境;
10.步骤2:获取具体一个地铁站的所有的历史入站刷卡记录以及预测当天的入站刷卡记录,存入hdfs分布式文件系统;
11.步骤3:根据历史入站刷卡记录,按照小时划分,利用分布式系统统计出一天中每个小时的刷卡数量,作为一小时内的地铁客流;
12.步骤4:分布式地计算所有的历史入站人数与预测当天的入站人数的向量距离,按照向量距离升序排列;
13.步骤5:对于步骤4中得到的数据,选取不同的k值,计算第一至第k个向量距离的偏差和方差,当偏差和方差最小时,得到最优的k值;
14.步骤6:根据最优的k值,利用历史的客流数据,用来训练lightgbm算法模型;
15.步骤7:根据最优的k值,选择k条历史入站人数的数据,输入到lightgbm算法模型,得到k组每小时的预测值。
16.步骤8:根据步骤7得出的k组预测值,利用k近邻模式匹配预测当天每小时的地铁客流。
17.步骤2中,对于历史入站刷卡记录和预测当天的入站刷卡记录,以入站刷卡记录作为入站人数,记录的结构包括记录时间和用户识别号。
18.步骤3中,从hdfs分布式文件系统中读取历史入站刷卡记录数据,并对读取的海量刷卡记录数据进行分布式并行处理,得到每一天的人数数据,一天中按照小时划分。
19.步骤4中,利用了hadoop的mapreduce过程进行计算,mapreduce包括map阶段和reduce阶段,具体包括如下步骤:
20.步骤4-1:读取n天的历史入站人数sn={x
n1
,x
n2
,
…
,x
n24
},x
ni
代表第n天i时的人数,i取值为1~24且i为整数,读取预测当天的数据q={y1,y2,
…
,yk},yk代表预测当天k时的人数,k取值为2~23,且为整数;
21.步骤4-2:分布式计算向量距离具体的,将键值对<i,si>作为map阶段的输入,其中si为第i天的历史入站人数;将<li,i>作为map阶段的输出;
22.在reduce阶段,对<li,i>进行升序排序,并交换参数位置,记为<i,mi>,mi表示升序排列第i位的向量距离,将结果保存到hdfs分布式文件系统。
23.步骤5包括:
24.步骤5-1:读取结果<i,mi>,分布式计算{mi|i=1,2,
…
,k}的偏差b和方差v,具体的,先生成键值对<i,(m1,m2,
…
mi)>,作为map阶段的输入,将<i,(b,v)>作为map阶段的输出;
25.步骤5-2:当k值在1到n之间变化时,存在一个最优的k值,使得偏差b和方差v最低,选取此时的k值。
26.步骤6包括:
27.步骤6-1:初始化变量x=k,预测当天k时的人数;
28.步骤6-2:将历史前k小时的历史入站人数数据作为特征值,第x小时的历史入站人数数据作为目标值;
29.步骤6-3:将历史入站人数数据进行归一化操作;
30.步骤6-4:利用k折交叉验证法训练lightgbm算法模型,lightgbm算法模型记为clf
x
;可以参考:https://lightgbm.readthedocs.io/en/latest/;
31.步骤6-5:更新x=x+1,重复步骤6-2至步骤6-5,直到x=24。
32.步骤7中,将k条历史入站人数数据作为输入,通过lightgbm算法模型clf
x
得到多组预测值λ
xi
,i=1,
…
,k,x=k,
…
,24,λ
xi
代表第i条历史入站人数对应的lightgbm算法预测的第x小时的人数。
33.所述步骤8中根据步骤五得出的k值和步骤7得出的一组预测值λ
x
,利用公式来计算当天的客流预测结果,y
x
表示x时的预测的人数。
34.本发明还包括步骤9:将预测结果可视化,以时间为横坐标,以人数为纵坐标,用两条折线代表实际人数和预测的人数,生成折线图。
35.本发明具有以下优点及有益效果:在分布式系统上并行处理庞大的数据,将数据分散到不同的节点上,使它们同时在不同节点上运行,从而加快计算速度。融合了knn和
lightgbm算法,有效地利用了所有历史数据来预测地铁客流情况,并且模型准确率较高。
附图说明
36.下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述和/或其他方面的优点将会变得更加清楚。
37.图1为本发明的方法实施步骤图。
38.图2为本发明的分布式系统结构图。
39.图3为本发明的具体实施流程图。
40.图4为本发明的预测结果折线图实例。
具体实施方式
41.实施例
42.如图1、图2、图3所示,本实施例提供了一种基于改进knn的的分布式地铁客流预测方法。
43.hadoop及其常用组件集群安装,具体包括:
44.一、用vmware虚拟3台服务器,搭建hadoop集群环境。
45.二、在hadoop集群环境的基础上,搭建3台服务器的spark集群环境。
46.获取一个地铁站的一年内的历史入站刷卡记录以及预测当天的入站刷卡记录,格式为(月-日-时,用户编号)。6月13日历史入站刷卡记录如表1所示:
47.表1
48.时间用户编号6-3-1112200452191956-3-111220045319648
…………
6-3-1212201412157966-3-121220045632146
…………
49.6月21日当天截止12时的入站刷卡记录如表2所示:
50.表2
51.用户编号用户编号6-21-1112200462316546-21-111210346222346
…………
6-21-1213200540965656-21-121320062654975
52.利用hadoop fs-put命令上传历史入站刷卡记录以及预测当天的入站刷卡记录,保存到hdfs分布式文件系统。
53.搭建linux下eclipse开发环境,配置好hadoop插件,导入org.apache.hadoop.fs包,以支持打开文件、读写文件、删除文件等。
54.利用filesystem.open(path f)从hdfs分布式文件系统中打开文件读取数据,并对读取的海量刷卡记录数据进行分布式并行处理,得到历史数据中每一天每小时的刷卡数量,具体处理如下:
55.一、以《月-日-时,用户编号>作为输入的键值对。
56.二、通过一个reduce函数,统计所有数据中“月-日-时”的人数,输出的键值对为《月-日-时,人数>。
57.三、在map函数中,根据每一天的时间段,将上一步的键值对进行分类,统计出每天的情况,输出为《月-日,(时,人数)>。
58.四、在reduce函数中,将上一步的键值对进行处理,把同一天的数据整合在一起,输出为《月-日,{(时,人数),(时,人数)
…
}>。例如6月13日的数据如表3所示:
59.表3
60.时人数51876301775488359875
…………
61.五、将上一步的键值对作为map阶段的输入,计算其与当天的键值对数据的向量距离将《月-日,向量距离>作为map阶段的输出。
62.六、在reduce阶段,对以上结果进行升序排序,将结果保存到hdfs分布式文件系统。例如下表4,与6月21日截至12时的实时车辆数据向量距离最近的是5月26日,为105;其次是5月12日,向量距离为155,3月13日,向量距离198,以及6月5日,向量距离为256。
63.表4
64.日期向量距离li5-261055-121553-131986-05256
…………
65.在spark命令行模式中,利用sc.textfile函数读取《月-日,向量距离>文件。
66.当k值在1到n之间变化时,计算第一至第k个距离的偏差和方差,找到最优的k值,使得偏差和方差最低,这里取k为3。
67.利用microsoft machine learning for apache spark(mmlspark)构建lightgbm模型,以x=k,即预测第k小时为例的步骤如下:
68.步骤1:用spark.createdataframe读取历史数据中每一天每小时的刷卡数量文件,将每日的前k小时的数据作为特征值,第k小时的数据作为目标值。
69.步骤2:用normalizer将数据进行归一化操作。
70.步骤3:用crossvalidator进行k折交叉验证法,以训练lightgbm模型。
71.将3条历史数据输入lightgbm模型,即model.transform函数,得到多组预测值λ
xi
,i=1,
…
,k,x=k,
…
,24,x表示第x小时,i对应k条数据。λ
xi
如表5所示:
72.表5
[0073][0074]
利用公式计算当天x时的客流预测结果,y
x
表示x时的预测的人数,由表4和表5数据预测人数如表6所示。
[0075]
表6
[0076]
时刻1314151617
……
预测的人数8636827008351348 [0077]
根据表6的预测人数结果使用matplotlib画出折线图,如图4所示。
[0078]
本发明提供了一种基于改进knn的分布式地铁客流预测方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1