对UOF文档进行转换的方法与流程
对uof文档进行转换的方法
技术领域
1.本发明涉及文档转换处理的技术领域,特别涉及对uof文档进行转换的方法。
背景技术:
2.uof(uified office document format)文档是基于xml的开放式文档格式,其又被称作“标文通”文档。在对uof文档进行转换的过程中存在文档解析出错以及转换内容无法打开的问题。同时现有的uof文档转换技术存在转换速度慢且无法进行二次开发的问题,这导致无法对uof文档进行批量转换和二次开发,从而严重影响uof文档的转换体验感。
技术实现要素:
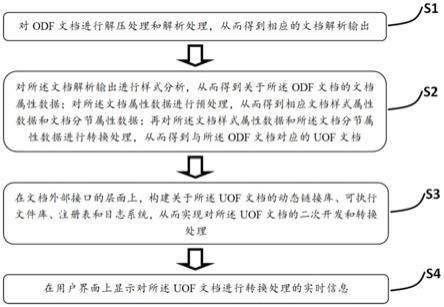
3.针对现有技术存在的缺陷,本发明提供对uof文档进行转换的方法,其包括对odf文档进行解压处理和解析处理,从而得到相应的文档解析输出;对文档解析输出进行样式分析,从而得到关于odf文档的文档属性数据;对文档属性数据进行预处理,从而得到相应文档样式属性数据和文档分节属性数据;再对文档样式属性数据和文档分节属性数据进行转换处理,从而得到与所述odf文档对应的uof文档;并在文档外部接口的层面上,构建关于uof文档的动态链接库、可执行文件库、注册表和日志系统,从而实现对uof文档的二次开发和转换处理;最后在用户界面上显示对所述uof文档进行转换处理的实时信息,其在基础层、转换层、外部接口层和用户界面层这四个层面上对uof文档进行转换,从而实现对uof文档进行批量转换和二次开发。
4.本发明提供对uof文档进行转换的方法,其特征在于,其包括如下步骤:
5.步骤s1,对odf文档进行解压处理和解析处理,从而得到相应的文档解析输出;
6.步骤s2,对所述文档解析输出进行样式分析,从而得到关于所述odf文档的文档属性数据;对所述文档属性数据进行预处理,从而得到相应文档样式属性数据和文档分节属性数据;再对所述文档样式属性数据和所述文档分节属性数据进行转换处理,从而得到与所述odf文档对应的uof文档;
7.步骤s3,在文档外部接口的层面上,构建关于所述uof文档的动态链接库、可执行文件库、注册表和日志系统,从而实现对所述uof文档的二次开发和转换处理;
8.步骤s4,在用户界面上显示对所述uof文档进行转换处理的实时信息;
9.进一步,在所述步骤s1中,对odf文档进行解压处理和解析处理,从而得到相应的文档解析输出具体包括:
10.步骤s101,基于开源代码zip utils设计形成文档解压缩模块,并利用所述文档解压缩模块对所述odf文档进行解压处理,从而得到所述odf文档包含xml文档;
11.步骤s102,基于开源项目xerces c++设计形成sax解析模块,并利用所述sax解析模块对所述xml文档进行解析处理,从而得到相应的文档解析输出;
12.进一步,在所述步骤s102中,利用所述sax解析模块对所述xml文档进行解析处理,从而得到相应的文档解析输出具体包括:
13.利用所述sax解析模块对所述xml文档进行解析处理,以此对所述xml文档进行逐行扫描和解析处理,从而得到相应的xml文档解析结果和文档静态表,以此作为所述文档解析输出;
14.进一步,在所述步骤s2中,对所述文档解析输出进行样式分析,从而得到关于所述odf文档的文档属性数据具体包括:
15.对所述文档解析输出进行样式分析,从而得到所述odf文档包含的段落属性数据、文字属性数据、大纲属性数据、表格属性数据和图像属性数据;
16.再定义getid函数对所述段落属性数据、所述文字属性数据、所述大纲属性数据、所述表格属性数据和所述图像属性数据进行处理,从而生成所述段落属性数据、所述文字属性数据、所述表格属性数据和所述图像属性数据各自对应的属性编号值;
17.进一步,在所述步骤s2中,对所述文档解析输出进行样式分析,从而得到所述odf文档包含的段落属性数据、文字属性数据、大纲属性数据、表格属性数据和图像属性数据;再定义getid函数对所述段落属性数据、所述文字属性数据、所述大纲属性数据、所述表格属性数据和所述图像属性数据进行处理,从而生成所述段落属性数据、所述文字属性数据、所述表格属性数据和所述图像属性数据各自对应的属性编号值具体包括:
18.所述文档中的不同属性的数据在进行连接时会在不同属性的数据中间存在一串连接符,根据所述连接符能够将所述文档解析输出分割成多个属性数据,接着根据每个属性数据中每个字节的属性定义将属性定义相同的属性数据归为一类,然后再定义getid函数以此根据归为一类的属性数据中每个字节的属性定义得到其对应的属性编号值,其具体过程为:
19.步骤s201,利用下面公式(1),根据所述连接符将所述文档解析输出分割成多个属性数据,
20.其中1≤i≤m-n+1
ꢀꢀꢀꢀ
(1)
21.在上述公式(1)中,μi表示所述解析输出的文档中第i个字节处属于分割点的判定值;d
i+a
表示所述文档解析输出中第i+a个字节的二进制形式数值;p
1+a
表示所述连接符的第1+a个字节的二进制形式数值;n表示所述连接符的字节总数;m表示所述文档解析输出的字节总数;
22.将i的值从1取值到m-n+1得到所有满足μi=0的i值,在所述所有满足μi=0的i值处的字节与其上一个字节的中间处作为分割点,对所述文档解析输出进行分割,分割完成后得到多个属性数据;
23.步骤s202,通过上述步骤s201分割得到的多个属性数据,每个属性数据内部中每个字节的属性定义都是一致的,并且每个属性定义的名称也是由多个字节构成,利用下面公式(2),根据每个属性数据中每个字节的属性定义将属性定义相同的属性数据归为一类,
24.其中r1≠r2(2)
25.在上述公式(2)中,h(r1,r2)表示分割完成后的第r1个属性数据与第r2个属性数据能否归为一类的判定值;t
r1,e
表示分割完成后的第r1个属性数据的属性定义名称中的第e个字节的二进制形式数值;t
r2,e
表示分割完成后的第r2个属性数据的属性定义名称中的第e个字节的二进制形式数值;b
r1
表示分割完成后的第r1个属性数据的属性定义名称中的
字节总数;b
r2
表示分割完成后的第r2个属性数据文档的属性定义名称中的字节总数;min()表示求取括号内的最小值;
26.若h(r1,r2)≠0,表示分割完成后的第r1个属性数据与第r2个属性数据中字节的属性定义名称不同,即不能进行合并;
27.若h(r1,r2)=0,表示分割完成后的第r1个属性数据与第r2个属性数据中字节的属性定义名称相同,即能够进行合并;
28.通过上述步骤s202对分割得到的多个属性数据两两进行对比,将对比后的具有相同属性定义名称的属性数据全部合并归为一类,而合并为一类的属性数据即为所述段落属性数据、所述文字属性数据、所述大纲属性数据、所述表格属性数据或者所述图像属性数据;
29.步骤s203,利用下面公式(3)作为getid函数,根据合为一类的属性数据中的字节个数以及合为一类的属性数据的属性定义名称,得到其对应的属性编号值,
30.getid(c)={tc<<l[(sc)2]+(sc)2}
10
ꢀꢀꢀꢀ
(3)
[0031]
在上述公式(3)中,getid(c)表示合为一类的属性数据文档中的第c类属性数据文档的属性编号值;tc表示合为一类的属性数据文档中的第c类属性数据文档的属性定义名称所对应的二进制形式数值;sc表示合为一类的属性数据文档中的第c类属性数据文档的字节个数;()2表示将括号内的数值转换为二进制形式;l[(sc)2]表示将sc转换为二进制形式后二进制数的位数;{}
10
表示将括号内的数值转换为10进制;
[0032]
进一步,在所述步骤s2中,对所述文档属性数据进行预处理,从而得到相应文档样式属性数据和文档分节属性数据具体包括:
[0033]
将所述odf文档包含的meta.xml文档、styles.xml文档、content.xml文档、uof.xml文档和rules.xml文档中段落属性数据、文字属性数据、大纲属性数据对应的属性编号值进行存储,从而作为所述文档样式属性数据和文档分节属性数据;
[0034]
进一步,在所述步骤s2中,对所述文档样式属性数据和所述文档分节属性数据进行转换处理,从而得到与所述odf文档对应的uof文档具体包括:
[0035]
对所述文档样式属性数据和所述文档分节属性数据进行主转换处理和后继转换处理;其中,
[0036]
所述主转换处理包括定义分别关于metatranslator、stylestranslator、contenttranslator的三种转换方式;并利用上述三种转换方式对所述文档样式属性数据和所述文档分节属性数据进行转换处理,从而将所述odf文档包含的meta.xml文档、styles.xml文档和content.xml文档进行转换处理;
[0037]
所述后继转换处理包括对所述uof.xml文档和所述rules.xml文档进行转换处理;
[0038]
再将对所述meta.xml文档、所述styles.xml文档和所述content.xml文档进行主转换处理的结果,以及对所述uof.xml文档和所述rules.xml文档进行后继转换处理的结果进行压缩,从而得到与所述odf文档对应的uof文档;
[0039]
进一步,在所述步骤s3中,在文档外部接口的层面上,构建关于所述uof文档的动态链接库、可执行文件库、注册表和日志系统,从而实现对所述uof文档的二次开发和转换处理具体包括:
[0040]
在文档外部接口的层面上,构建关于所述uof文档的动态链接库,再利用所述动态
链接库为用户提供对所述uof文档的二次开发功能,从将所述uof文档能够集成到不同办公软件;
[0041]
在文档外部接口的层面上,构建关于所述uof文档的可执行文件库和注册表,再在所述可执行文件库形成的界面上,通过修改所述注册表的方式实现uof文档的批量转换;
[0042]
在文档外部接口的层面上,构建关于所述uof文档的日志系统,再利用所述日志系统记录文档转换的时间;
[0043]
进一步,在所述步骤s3中,在所述可执行文件库形成的界面上,通过修改所述注册表的方式实现uof文档的批量转换具体包括:
[0044]
在所述可执行文件形成的界面上,通过直接使用右键菜单或者使用命令行的方式修改所述注册表的方式实现uof文档的批量转换;
[0045]
进一步,在所述步骤s4中,在用户界面上显示对所述uof文档进行转换处理的实时信息具体包括:
[0046]
在用户界面上形成相应的信息展示窗口,所述信息展示窗口用于显示文档转换所处的阶段以及每个阶段对应的转换时间。
[0047]
相比于现有技术,该对uof文档进行转换的方法包括对odf文档进行解压处理和解析处理,从而得到相应的文档解析输出;对文档解析输出进行样式分析,从而得到关于odf文档的文档属性数据;对文档属性数据进行预处理,从而得到相应文档样式属性数据和文档分节属性数据;再对文档样式属性数据和文档分节属性数据进行转换处理,从而得到与所述odf文档对应的uof文档;并在文档外部接口的层面上,构建关于uof文档的动态链接库、可执行文件库、注册表和日志系统,从而实现对uof文档的二次开发和转换处理;最后在用户界面上显示对所述uof文档进行转换处理的实时信息,其在基础层、转换层、外部接口层和用户界面层这四个层面上对uof文档进行转换,从而实现对uof文档进行批量转换和二次开发。
[0048]
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
[0049]
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
[0050]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0051]
图1为本发明提供的对uof文档进行转换的方法的流程示意图。
具体实施方式
[0052]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他
实施例,都属于本发明保护的范围。
[0053]
参阅图1,为本发明实施例提供的对uof文档进行转换的方法的流程示意图。该对uof文档进行转换的方法包括如下步骤:
[0054]
步骤s1,对odf文档进行解压处理和解析处理,从而得到相应的文档解析输出;
[0055]
步骤s2,对该文档解析输出进行样式分析,从而得到关于该odf文档的文档属性数据;对该文档属性数据进行预处理,从而得到相应文档样式属性数据和文档分节属性数据;再对该文档样式属性数据和该文档分节属性数据进行转换处理,从而得到与该odf文档对应的uof文档;
[0056]
步骤s3,在文档外部接口的层面上,构建关于该uof文档的动态链接库、可执行文件库、注册表和日志系统,从而实现对该uof文档的二次开发和转换处理;
[0057]
步骤s4,在用户界面上显示对该uof文档进行转换处理的实时信息。
[0058]
上述技术方案的有益效果为:该对uof文档进行转换的方法包括对odf文档进行解压处理和解析处理,从而得到相应的文档解析输出;对文档解析输出进行样式分析,从而得到关于odf文档的文档属性数据;对文档属性数据进行预处理,从而得到相应文档样式属性数据和文档分节属性数据;再对文档样式属性数据和文档分节属性数据进行转换处理,从而得到与所述odf文档对应的uof文档;并在文档外部接口的层面上,构建关于uof文档的动态链接库、可执行文件库、注册表和日志系统,从而实现对uof文档的二次开发和转换处理;最后在用户界面上显示对所述uof文档进行转换处理的实时信息,其在基础层、转换层、外部接口层和用户界面层这四个层面上对uof文档进行转换,从而实现对uof文档进行批量转换和二次开发。
[0059]
优选地,在该步骤s1中,对odf文档进行解压处理和解析处理,从而得到相应的文档解析输出具体包括:
[0060]
步骤s101,基于开源代码zip utils设计形成文档解压缩模块,并利用该文档解压缩模块对该odf文档进行解压处理,从而得到该odf文档包含xml文档;
[0061]
步骤s102,基于开源项目xerces c++设计形成sax解析模块,并利用该sax解析模块对该xml文档进行解析处理,从而得到相应的文档解析输出。
[0062]
上述技术方案的有益效果为:基于开源代码zip utils设计形成文档解压缩模块,能够使得该文档解压缩模块对所有odf文档具有解压缩普适性,并且还能够便于根据实际需要来对开源代码zip utils进行编辑而提高文档解压缩模块的解压缩保真性。其次,基于开源项目xerces c++设计形成sax解析模块,其能够对xml文档进行全面的逐行解析,从而有效避免解析遗漏的情况发生。
[0063]
优选地,在该步骤s102中,利用该sax解析模块对该xml文档进行解析处理,从而得到相应的文档解析输出具体包括:
[0064]
利用该sax解析模块对该xml文档进行解析处理,以此对该xml文档进行逐行扫描和解析处理,从而得到相应的xml文档解析结果和文档静态表,以此作为该文档解析输出。
[0065]
上述技术方案的有益效果为:sax(simple api for xml)是一种功能xml解析的替代方法,其是对文档进行逐行扫描,其能够一边对文档进行扫描一边解析,这能够保证对文档进行全面无遗漏的扫描,同时也能够提高文档解析的速度。
[0066]
优选地,在该步骤s2中,对该文档解析输出进行样式分析,从而得到关于该odf文
档的文档属性数据具体包括:
[0067]
对该文档解析输出进行样式分析,从而得到该odf文档包含的段落属性数据、文字属性数据、大纲属性数据、表格属性数据和图像属性数据;
[0068]
再定义getid函数对该段落属性数据、该文字属性数据、该大纲属性数据、该表格属性数据和该图像属性数据进行处理,从而生成该段落属性数据、该文字属性数据、该表格属性数据和该图像属性数据各自对应的属性编号值。
[0069]
上述技术方案的有益效果为:文档内部通常包括段落、文字、大纲、表格和图像等不同类型的文档样式内容,这些文档样式内容都具有自身的特点,通过对该文档解析输出进行样式分析能够有针对性地将每种文档样式的属性内容分别提取出来。随后通过定义合适的getid函数来定义每种属性数据设定相应的属性编号值,这样能够保证每种属性数据的编号值唯一性和便于后续对每种属性数据进行合适的处理。
[0070]
优选地,在该步骤s2中,对该文档解析输出进行样式分析,从而得到该odf文档包含的段落属性数据、文字属性数据、大纲属性数据、表格属性数据和图像属性数据;再定义getid函数对该段落属性数据、该文字属性数据、该大纲属性数据、该表格属性数据和该图像属性数据进行处理,从而生成该段落属性数据、该文字属性数据、该表格属性数据和该图像属性数据各自对应的属性编号值具体包括:
[0071]
该文档中的不同属性的数据在进行连接时会在不同属性的数据中间存在一串连接符,根据该连接符能够将该文档解析输出分割成多个属性数据,接着根据每个属性数据中每个字节的属性定义将属性定义相同的属性数据归为一类,然后再定义getid函数以此根据归为一类的属性数据中每个字节的属性定义得到其对应的属性编号值,其具体过程为:
[0072]
步骤s201,利用下面公式(1),根据该连接符将该文档解析输出分割成多个属性数据,
[0073]
其中1≤i≤m-n+1
ꢀꢀꢀꢀ
(1)
[0074]
在上述公式(1)中,μi表示该解析输出的文档中第i个字节处属于分割点的判定值;d
i+a
表示该文档解析输出中第i+a个字节的二进制形式数值;p
1+a
表示该连接符的第1+a个字节的二进制形式数值;n表示该连接符的字节总数;m表示该文档解析输出的字节总数;
[0075]
将i的值从1取值到m-n+1得到所有满足μi=0的i值,在该所有满足μi=0的i值处的字节与其上一个字节的中间处作为分割点,对该文档解析输出进行分割,分割完成后得到多个属性数据;
[0076]
步骤s202,通过上述步骤s201分割得到的多个属性数据,每个属性数据内部中每个字节的属性定义都是一致的,并且每个属性定义的名称也是由多个字节构成,利用下面公式(2),根据每个属性数据中每个字节的属性定义将属性定义相同的属性数据归为一类,
[0077]
其中r1≠r2
ꢀꢀ
(2)
[0078]
在上述公式(2)中,h(r1,r2)表示分割完成后的第r1个属性数据与第r2个属性数据能否归为一类的判定值;t
r1,e
表示分割完成后的第r1个属性数据的属性定义名称中的第e个字节的二进制形式数值;t
r2,e
表示分割完成后的第r2个属性数据的属性定义名称中的第e个字节的二进制形式数值;b
r1
表示分割完成后的第r1个属性数据的属性定义名称中的
字节总数;b
r2
表示分割完成后的第r2个属性数据文档的属性定义名称中的字节总数;min()表示求取括号内的最小值;
[0079]
若h(r1,r2)≠0,表示分割完成后的第r1个属性数据与第r2个属性数据中字节的属性定义名称不同,即不能进行合并;
[0080]
若h(r1,r2)=0,表示分割完成后的第r1个属性数据与第r2个属性数据中字节的属性定义名称相同,即能够进行合并;
[0081]
通过上述步骤s202对分割得到的多个属性数据两两进行对比,将对比后的具有相同属性定义名称的属性数据全部合并归为一类,而合并为一类的属性数据即为该段落属性数据、该文字属性数据、该大纲属性数据、该表格属性数据或者该图像属性数据;
[0082]
步骤s203,利用下面公式(3)作为getid函数,根据合为一类的属性数据中的字节个数以及合为一类的属性数据的属性定义名称,得到其对应的属性编号值,
[0083]
getid(c)={tc<<l[(sc)2]+(sc)2}
10
ꢀꢀꢀꢀ
(3)
[0084]
在上述公式(3)中,getid(c)表示合为一类的属性数据文档中的第c类属性数据文档的属性编号值;tc表示合为一类的属性数据文档中的第c类属性数据文档的属性定义名称所对应的二进制形式数值;sc表示合为一类的属性数据文档中的第c类属性数据文档的字节个数;()2表示将括号内的数值转换为二进制形式;l[(sc)2]表示将sc转换为二进制形式后二进制数的位数;{}
10
表示将括号内的数值转换为10进制。
[0085]
上述技术方案的有益效果为:利用上述公式(1)根据连接符将文档解析输出分割成多个属性数据,进而根据连接符将文档解析输出准确的分割成多个不同属性的数据,方便后续的归类以及确定属性编号值;再利用上述公式(2)根据每个属性数据中每个字节的属性定义将属性定义相同的属性数据合为一类,进而将同属性的数据按照属性定义名称进行合并,进而分析得到odf文档包含的段落属性数据、文字属性数据、大纲属性数据、表格属性数据和图像属性数据;最后利用上述公式(3)根据合为一类的属性数据中的字节个数以及合为一类的属性数据的属性定义名称,得到其对应的属性编号值,使得求得的属性编号值可以准确的反应出数据文档的属性特点以及数据内部的字节数,并且与其他属性的数据可以严格的分隔开,进而可以根据属性编号值准确的确定数据的属性以及字节个数,保证编号的唯一性以及针对性。
[0086]
优选地,在该步骤s2中,对该文档属性数据进行预处理,从而得到相应文档样式属性数据和文档分节属性数据具体包括:
[0087]
将该odf文档包含的meta.xml文档、styles.xml文档、content.xml文档、uof.xml文档和rules.xml文档中段落属性数据、文字属性数据、大纲属性数据对应的属性编号值进行存储,从而作为该文档样式属性数据和文档分节属性数据。
[0088]
上述技术方案的有益效果为:该odf文档通常包括meta.xml文档、styles.xml文档、content.xml文档、uof.xml文档和rules.xml文档这几种不同类型的文档,这些文档各自的属性数据并不相同,按照这些属性数据各自的属性编号值进行分类存储,从而便于后续快速和准确地读取相应的属性数据进行转换处理。
[0089]
优选地,在该步骤s2中,对该文档样式属性数据和该文档分节属性数据进行转换处理,从而得到与该odf文档对应的uof文档具体包括:
[0090]
对该文档样式属性数据和该文档分节属性数据进行主转换处理和后继转换处理;
其中,
[0091]
该主转换处理包括定义分别关于metatranslator、stylestranslator、contenttranslator的三种转换方式;并利用上述三种转换方式对该文档样式属性数据和该文档分节属性数据进行转换处理,从而将该odf文档包含的meta.xml文档、styles.xml文档和content.xml文档进行转换处理;
[0092]
该后继转换处理包括对该uof.xml文档和该rules.xml文档进行转换处理;
[0093]
再将对该meta.xml文档、该styles.xml文档和该content.xml文档进行主转换处理的结果,以及对该uof.xml文档和该rules.xml文档进行后继转换处理的结果进行压缩,从而得到与该odf文档对应的uof文档。
[0094]
上述技术方案的有益效果为:通过上述主转换处理对应的三种转换方式能够从文字、格式和内容这三方面进行转换,从而便于对文档进行全面的分析。而通过上述后继转换处理,能够对文档的其他类型文档数据进行转换,从而提高对文档的转换有效性。
[0095]
优选地,在该步骤s3中,在文档外部接口的层面上,构建关于该uof文档的动态链接库、可执行文件库、注册表和日志系统,从而实现对该uof文档的二次开发和转换处理具体包括:
[0096]
在文档外部接口的层面上,构建关于该uof文档的动态链接库,再利用该动态链接库为用户提供对该uof文档的二次开发功能,从将该uof文档能够集成到不同办公软件;
[0097]
在文档外部接口的层面上,构建关于该uof文档的可执行文件库和注册表,再在该可执行文件库形成的界面上,通过修改该注册表的方式实现uof文档的批量转换;
[0098]
在文档外部接口的层面上,构建关于该uof文档的日志系统,再利用该日志系统记录文档转换的时间。
[0099]
上述技术方案的有益效果为:通过在文档外部接口的层面上,利用动态链接库、可执行文件库、注册表和日志系统对该uof文档进行二次开发、批量转换和转换时间的记录,这样能够提高该uof文档的功能开发扩展以及便于进行大规模的转换,从而提高转换效率。
[0100]
优选地,在该步骤s3中,在该可执行文件库形成的界面上,通过修改该注册表的方式实现uof文档的批量转换具体包括:
[0101]
在该可执行文件形成的界面上,通过直接使用右键菜单或者使用命令行的方式修改该注册表的方式实现uof文档的批量转换。
[0102]
上述技术方案的有益效果为:通过直接使用右键菜单或者使用命令行的方式修改该注册表的方式实现uof文档的批量转换,能够为用户进行文档的批量转换提供多种不同的选择方式。
[0103]
优选地,在该步骤s4中,在用户界面上显示对该uof文档进行转换处理的实时信息具体包括:
[0104]
在用户界面上形成相应的信息展示窗口,该信息展示窗口用于显示文档转换所处的阶段以及每个阶段对应的转换时间。
[0105]
上述技术方案的有益效果为:通过在用户界面的信息展示窗口中显示文档转换所处的阶段以及每个阶段对应的转换时间,这样用户能够实时和准确地获得文档的转换进度信息。
[0106]
从上述实施例的内容可知,该对uof文档进行转换的方法包括对odf文档进行解压
处理和解析处理,从而得到相应的文档解析输出;对文档解析输出进行样式分析,从而得到关于odf文档的文档属性数据;对文档属性数据进行预处理,从而得到相应文档样式属性数据和文档分节属性数据;再对文档样式属性数据和文档分节属性数据进行转换处理,从而得到与所述odf文档对应的uof文档;并在文档外部接口的层面上,构建关于uof文档的动态链接库、可执行文件库、注册表和日志系统,从而实现对uof文档的二次开发和转换处理;最后在用户界面上显示对所述uof文档进行转换处理的实时信息,其在基础层、转换层、外部接口层和用户界面层这四个层面上对uof文档进行转换,从而实现对uof文档进行批量转换和二次开发。
[0107]
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1