富文本文档的风险检测方法、装置及可读存储介质与流程
1.本技术涉及网络安全技术领域,尤其涉及富文本文档的风险检测方法、装置及可读存储介质。
背景技术:
2.富文本文档(rich text format,rtf文档),是一种采用ascii作为编码格式的文档,rtf文档能够被多种解析器解析。由于不同解析器对rtf文档规范中未进行严格要求(或者不够细化)的内容存在理解差异,所得到的解析结果也会出现差异。上述这种差异性,使得攻击者能在rtf文档中插入恶意对象,并对其字符串流进行混淆,得以绕过普通的第三方解析工具,达到静态反检测的目的。
3.因此,现有技术中检测富文本文档风险的方法不准确。
技术实现要素:
4.本技术提供一种富文本文档的风险检测方法、装置及可读存储介质,用以解决现有技术中存在的检测富文本文档风险的方法不准确的问题。
5.第一方面,本技术提供一种富文本文档的风险检测方法,所述方法包括:
6.在富文本文档中,定位第一数据流;其中,所述第一数据流是设定的第一控制字前的起始符与所述起始符匹配的结束符之间的数据;
7.读取所述第一数据流中控制字的读位属性,基于所述读位属性删除或保留所述第一数据流中控制字后的数据,得到第一数据;其中,当读位属性为删除时,指示删除对应控制字之后到相邻的下一个控制字之间的数据;
8.基于所述第一数据中的内嵌对象或者链接,确定所述富文本文档存在风险。
9.上述操作通过读取第一数据流中控制字的读位属性,确定了第一数据流中的混淆内容并删除,解决了恶意对象针对富文本文档混淆后导致富文本文档无法正常检测的问题,即解决了检测富文本文档存在风险的方法不准确的问题。
10.一种可能的实施方式,所述第一控制字为objdata。
11.一种可能的实施方式,所述在富文本文档中,定位第一数据流之前,包括:
12.检测富文本文档是否包含基础恶意特征;其中,所述基础恶意特征指任一安全解析软件识别出的恶意特征;
13.若是,则确定所述富文本文档存在风险;若否,则定位第一数据流。
14.通过检测基础恶意特征,可以提高检测富文本文档存在风险的效率。一种可能的实施方式,所述基础恶意特征包括:不合规的头部标志、可疑的文档创建者和最后修改者、头部前或后的设定范围内出现控制字、非期望控制字、控制字连续次数超过第一阈值、特定字符使用次数超过第二阈值、控制字长度超过第三阈值、两个16进制字符中出现非期望字符。
15.一种可能的实施方式,所述读取所述第一数据流中控制字的读位属性,包括;
16.当读取到任一控制字的读位属性为空时,则基于所述读位属性的追溯性,依次向所述任一控制字之前追溯距离最近的控制字的读位属性,直到确定所述任一控制字的读位属性;其中,所述追溯性指所述任一控制字的读位属性与距离最近的,同级控制字或者上级控制字的读位属性相同。
17.一种可能的实施方式,所述基于所述第一数据中的内嵌对象或者链接,确定所述富文本文档存在风险,包括;
18.当所述第一数据中包含常规解析方法未解析到的所述内嵌对象或者链接时,确定所述第一数据流中包括混淆内容,确定所述富文本文档存在风险。
19.第二方面,本技术提供一种富文本文档的风险检测装置,所述装置包括:
20.定位单元:用于在富文本文档中,定位第一数据流;其中,所述第一数据流是设定的第一控制字前的起始符与所述起始符匹配的结束符之间的数据;
21.读取单元;用于读取所述第一数据流中控制字的读位属性,基于所述读位属性删除或保留所述第一数据流中控制字后的数据,得到第一数据;其中,当读位属性为删除时,指示删除对应控制字之后到相邻的下一个控制字之间的数据;
22.确定单元:用于基于所述第一数据中的内嵌对象或者链接,确定所述富文本文档存在风险。
23.一种可能的实施方式,所述装置还包括基础单元,具体用于检测富文本文档是否包含基础恶意特征;其中,所述基础恶意特征指任一安全解析软件识别出的恶意特征;若是,则确定所述富文本文档存在风险;若否,则定位第一数据流。
24.一种可能的实施方式,所述读取单元具体用于当读取到任一控制字的读位属性为空时,则基于所述读位属性的追溯性,依次向所述任一控制字之前追溯距离最近的控制字的读位属性,直到确定所述任一控制字的读位属性;其中,所述追溯性指所述任一控制字的读位属性与距离最近的,同级控制字或者上级控制字的读位属性相同。
25.第三方面,本技术还提供一种可读存储介质,包括:
26.存储器,
27.所述存储器用于存储指令,当所述指令被处理器执行时,使得包括所述可读存储介质的装置完成如第一方面及任一种可能的实施方式所述的方法。
附图说明
28.图1为本技术提供的一种富文本文档的风险检测方法的流程图;
29.图2为本技术提供的第一数据流未经过混淆前以及混淆后的对比图;
30.图3为本技术提供的一种富文本文档的风险检测装置的结构示意图。
具体实施方式
31.针对上述现有技术存在的检测rtf文档风险的方法不准确的问题,本技术实施例针对当前恶意对象插入rtf文档的混淆手段,提出富文本文档的风险检测方法:在富文本文档中定位第一数据流后,读取第一数据流中控制字的读位属性并解析,从而确定富文本文档中的内容是否被混淆,即确定了富文本文档包含混淆内容,存在风险。
32.需要说明的是,本技术中将所有富文本格式文档统称为富文本文档。
33.以下针对本技术实施例中所使用的技术术语进行解释:
34.富文本格式文档:是指一种采用ascii作为编码格式的跨平台办公文档,该文档可以在支持ascii编码格式的多种软件上打开。例如,word,wps等办公软件。
35.控制字:是一种rtf文档的基本组成单位,由格式化的字符串名称组成,控制字用于定义文档要输出的内容。控制字以前缀斜杠\开头,后面接英文字符串作为控制字名称。控制字名称之后的数字字符是控制字参数。一般地,控制字的格式如下:
36.\《ascii英文字符》《ascii数字字符》《空格/回车换行》《数据流(可选)》。
37.例如:\rtlch\fcs1\af31507;本例中包含三个控制字,分别是\rtlch、\fcs和\af。其中\fcs的参数为1,\af的参数为31507。
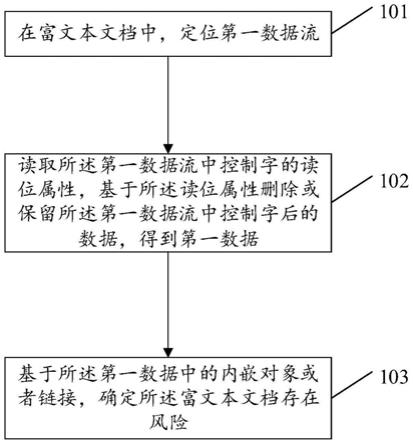
38.例如:\objdata 0105000002000000
…
;本例中的控制字为\objdata,没有参数,接了一个空格,后面的01050
…
是对应的数据流。
39.16进制字符(串):指一种范围是0~9,a~f或a~f的ascii字符。一个字符代表4比特,两个字符代表1个字节。例如字符串“313233”,代表0x31,0x32和0x33。
40.为了更好的理解上述技术方案,下面通过附图以及具体实施例对本技术技术方案做详细的说明,应当理解本技术实施例以及实施例中的具体特征是对本技术技术方案的详细的说明,而不是对本技术的技术方案的限定,在不冲突的情况下,本技术实施例以及实施例中的技术特征可以相互组合。
41.请参考图1,本技术提供一种富文本文档的风险检测方法,用以解决现有技术中存在的检测富文本文档风险的方法不准确的问题,该方法具体可以包括以下实现步骤:
42.步骤101:在富文本文档中,定位第一数据流。
43.其中,所述第一数据流是设定的第一控制字前的起始符与所述起始符匹配的结束符之间的数据。
44.本技术实施例中的起始符可以是“{”,则结束符是与之匹配的“}”。
45.本技术实施例中,设定第一控制字可以是objdata。
46.需要说明的是,在定位第一数据流之前,可以首先检测富文本文档是否包含基础恶意特征。其中,基础恶意特征指任一安全解析软件能识别出的恶意特征。
47.基础恶意特征包括不合规的头部标志、可疑的文档创建者和最后修改者、头部前或后的设定范围内出现控制字、非期望控制字、控制字连续次数超过第一阈值、特定字符使用次数超过第二阈值、控制字长度超过第三阈值、两个16进制字符中出现非期望字符。
48.具体地,不合规的头部标志指,富文本文档头部包括1以外的其他数字。例如,2,3,4等。正常不存在风险的rtf文档头部标志一定包括{\rtf1,表示rtf文档的版本是rtf 1.x。
49.可疑的文档创建者和最后修改者:文档创建者以及最后修改者填写位置为空,或者填写内容是恶意文档曾用名的集合,或异类名称。其中。异类名称包括高权限用户名,安全公司名称等。正常不存在风险的rtf文档的创建者和最后修改者为作者控制字或操作控制字。
50.头部前或后的设定范围内出现控制字:例如,pict、page、objdata、object、objocx、objw、objautlink等。
51.非期望控制字:指以斜杠开头,格式与控制字一致,但是无法识别的控制字。非期望控制字往往会干扰16进制字符的解析。
52.特定字符使用次数超过第二阈值:特定字符主要指第一数据流中的特定字符使用次数超过第二阈值。本技术实施例中第一数据流为objdata数据流,特定字符为空格和制表符。可以设置为,当任一objdata数据流中,空格和制表符的使用次数超过20次,确定该rtf文档包含基础恶意特征。
53.控制字长度超过第三阈值:控制字包括控制字名称和控制字参数。当存在控制字参数时,本技术实施例中将第三阈值设置为252;当不存在控制字参数时,控制字仅包括控制字名称,本技术实施例将第三阈值设置为254。
54.两个16进制字符中出现非期望字符:两个16进制字符之间的期望字符为空格和换行,则两个16进制字符中的非期望控制字符为除了空格和换行以外的字符。例如,花括号、斜杠、非可见字符、逗号、句号等。
55.在本技术实施例中,若检测出富文本文档包含上面任意一个基础恶意特征,即可以确定该富文本文档存在风险,不必执行步骤101;否则,在检测结束后则对富文本文档执行步骤101。
56.步骤102:读取所述第一数据流中控制字的读位属性,基于所述读位属性删除或保留所述第一数据流中控制字后的数据,得到第一数据。
57.其中,当读位属性为删除时,指示删除对应控制字之后到相邻的下一个控制字之间的数据。
58.具体地,若rtf文档中不存在风险时,则第一数据流中不包含无意义数据(字符),即解析第一数据流时默认所有控制字的读位属性为保留。第一数据流中内嵌对象和链接以16进制字符表示,而恶意对象所采用的混淆手段主要是针对第一数据流中内嵌对象或者链接对象所实施的,因此恶意对象用于混淆的字符种类为16进制字符,即读位属性所述指示的删除或保留数据,主要用于对保留或删除16进制字符进行判断。若恶意对象未采取混淆手段,那么常规的检测方法可以通过检测出基础恶意特征确定该富文本文档存在风险,当恶意对象采用混淆手段对第一数据流处理后,则存在不能解析出恶意特征的可能性。因此基于每一个控制字读位属性确定是否保留该控制字至下一个控制字之间数据,可以将恶意对象混淆在第一数据流中的无意义字符删除,促使通过混淆手段隐藏在无意义字符周围的恶意对象暴露出来。
59.需要说明的是,因存在混淆,可能无法直接识别16进制字符的开始位置或者结束位置,所以本技术实施例针对第一数据流中的数据,进行顺序逐一解析,并且,每次识别控制字之后,根据控制字的读位属性,确定是否保留控制字之后数据的解析结果。
60.读位属性具有追溯性。当读取到任一控制字的读位属性为空时,则基于所述读位属性的追溯性,依次向所述任一控制字之前追溯距离最近的控制字的读位属性,直到确定所述任一控制字的读位属性;其中,所述追溯性指所述任一控制字的读位属性与距离最近的,同级控制字或者上级控制字的读位属性相同。由此可见,若位于某个子数据组中的当前控制字的读位属性为空,则对该控制字到下一个控制字之间的数据,可以按照上一个位于该组的控制字的读位属性进行解析。
61.以下针对读位属性以及同级数据组进行具体描述:
[0062]“{}”表示一个数据组,并且“{}”中可以嵌套多个“{}”数据组。若在“{}”之间包含多个或多层“{}”,则首个“{”至与之对称出现的“}”之间的“{}”,称作子数据组。
[0063]
例如,以下是objdata数据流中的一个片段,
[0064]
{
…
\objdata
…
《\namea
…
{\nameb\
…
\namec
…
\named
…
\namee
……
\namei
…
\namej
…
\namek
…
\namel}\namem
…
\namen》
…
},上述{
…
\objdata
…
《\namea
…
{\nameb\
…
\namec
…
\named
…
\namee
……
\namei
…
\namej
…
\namek
…
\namel}\namem
…
\namen》
…
}是一个数据组;其中,{\nameb
……
\namel}对于namea、namem和namen来说是次级子数据组,namea、namem和namen对{\nameb
……
\namel}是上级数据组的控制字,namea、namem和namen之间是同级关系。因控制字的读位属性包括保留、删除,空(未查询到),objdata的读位属性对应保留。在对该片段进行解析时,执行读位属性的追溯性应满足以下需求:
[0065]
对于子数据组,nameb到namec之间数据的解析依赖于nameb的读位属性;namec到named之间数据的解析依赖于namec的读位属性;named到namee之间数据的解析依赖于named的读位属性;依次类推。
[0066]
若namek的读位属性为空,则向前追溯到namej。若namej的读位属性为空,则向前追溯到namei。依次类推,在当前组内,最远可追溯到nameb。
[0067]
若nameb的读位属性为空,则应当跨出该组,向前追溯到离该组最近的上一级控制字namea。
[0068]
若namem的读位属性为空,则向前追溯到最近一个同级控制字namea;若namea的读位属性为空,同理,向前追溯到最近一个同级控制字。
[0069]
确定objdata中控制字的读位属性后,可以确定是否保留该控制字后数据的解析结果。针对控制字后所包括的数据,在读取到后可以识别出该数据的数据类型并确定使用相对应的解析规则,因此,当控制字后的数据包括多种数据类型,则解析方法可以基于该控制字后与数据类型相对应的解析规则依次跳转。控制字包括控制字名称和控制字参数。也就是说,在解析过程中,“\”为控制字标志,遇到“\”后的英文字母,则识别出读取到控制字名称,则使用控制字解析规则;若控制字后的数字于控制字紧邻,则识别出读取到控制字参数,使用控制字解析规则;若控制字后的数字与控制字名称或控制字参数非紧邻,二者之间被空格或其他符号分隔开,则识别出读取到16进制字符,使用16进制字符解析规则。
[0070]
例如,存在片段《\objdata 16089846e2e33\efg{\abc0000}45715541》,该片段中读取到“\”确定其后的数据为控制字,接着读取到objdata,针对objdata基于控制解析字规则解析,确定objdata为第一控制字,其读位属性为保留其后数据信息;接着读取到16089846e2e3,因16089846e2e33与objdata之间非紧邻状态,存在一个空格,则确定16089846e2e33为16进制字符即基于16进制字符解析规则解析并保留;同理,针对efg基于控制字解析规则解析,同时可以确定efg的读位属性;进一步地,读取到“\”确定接下来为控制字,则读取abc并确定其后数据是否保留。进一步地,依次读取0000},当读取到}时,确定次级数据组{\abc0000}结束,其中因0000于abc紧邻,则确定0000为abc的控制字参数。接着读取到45715541,因开始符和结束符“{}”将45715541与控制字efg分隔开,若efg的读位属性为保留,则确定针对45715541基于16进制字符规则解析并保留;若efg的读位属性为删除,则确定删除针对45715541的解析结果;若efg的读位属性为空,则根据读位属性的追溯性,读取objdata的读位属性为保留,确定针对45715541基于16进制字符规则解析并保留。
[0071]
基于上述方法,可以确定恶意对象用于混淆的控制字以及字符串并删除,进而执
行下一步骤;相反,若该片段存在风险,且解析时不考虑读位属性,默认该片段的读位属性为保留,直接针对片段《\objdata16089846e2e33\efg{\abc0000}45715541》进行解析,则第一数据中包含该片段中所有数据的解析结果,该结果中所包括的公式等内容,因存在风险的混淆不能正常体现。
[0072]
步骤103:基于所述第一数据中的内嵌对象或者链接,确定所述富文本文档存在风险。
[0073]
第一数据流用于保存内嵌对象或者链接,例如公式编辑器,脚本语言,可以被攻击者用于插入恶意对象。因此,本技术实施例中针对第一数据流的解析结果(第一数据),即可判断rtf文档是否存在风险。
[0074]
因为本技术实施例是在常规检测方法无法正常读取rtf文档,或者未检测出rtf文档中存在风险之后实施的,即在常规解析结果中,未解析到内嵌对象或者链接;而通过删除第一数据流中,读位属性为删除的控制字后的无意义数据,所得到的第一数据中包含内嵌对象或链接,则可以确定常规解析方法不能正常读取rtf文档的原因是,第一数据流经过混淆具备抗检测功能,第一数据流中包括混淆内容。根据恶意对象插入rtf文档的混淆手段,可以判断该rtf文档中存在风险。
[0075]
进一步地,可以针对第一数据再次进行恶意检测,即判断第一数据的内嵌对象或者链接是否具备恶意特征,进而确定是否存在风险。
[0076]
本方法可以提高静态检测rtf文档存在风险的效率。
[0077]
以下基于具体的实例对本技术实施例所提供的方法,做进一步说明:
[0078]
(一)以下为一个未经过混淆的第一数据流的片段:
[0079]
{\objdata
[0080]
d0200dl5020000000b0000006551754174694f4e2e3300
[0081]
因控制字objdata后为回车符,则,
[0082]
d0200dl5020000000b0000006551754174694f4e2e3300为16进制字符,针对该16进制字符串进行解析,可以得到,d0200d15指示,ole版本,可以是任意值;02000000指示,format_id。此处为02000000,代表内嵌对象。0b000000为标志。6551754174694f4e2e3300为class name,是一个0结尾的ascii字符串,此处为"equation.3"字符串,代表内嵌对象是公式编辑器3。
[0083]
此处需要说明的是,设置format_id时,只能设置为0x00000001或0x00000002,否则对象头不合法。其中,0x00000001为010000000;0x00000002为02000000,代表内嵌对象。
[0084]
(二)针对上述片段混淆进恶意对象后,可能的一种形式为:
[0085]
{\objdata
[0086]
d0200dl502{00\mlim\{454416270wevaspvztr454416270}{\macc\}}00000b0000006551754174694f4e2e3300
[0087]
如图2所示,在上述片段中,用于指示format_id的字符串02000000被左括号“{”,以及\mlim\{454416270wevaspvztr454416270}{\macc\}}分隔开。
[0088]
在常规解析过程中,读到02后的“{”时,若安全解析软件不能识别,将“{”开头的子数据组{00\mlim\{454416270wevaspvztr454416270}{\macc\}}删除,则会导致其中的00丢失,不能形成有意义的format_id,若继续往下解析,因常规解析方法针对第一数据流不考
虑控制字的读位属性,默认保存所有字符,则保存控制字mlim后字符串,这导致format_id为02000000的字符串被打断,仍然不能形成有意义的format_id。而在解析数据流的过程中,需在解析到format id之后,确定开始读取定位内嵌对象;当format id不能正常解析时,则内嵌对象也不能被正常定位并解析,即导致了第一数据流不能正常解析。
[0089]
当利用本技术实施例中的方法,基于控制字的读位属性,进行解析时,在读取mlim时,确定mlim为控制字,进一步确定控制字mlim的读位属性为删除,则删除其后16进制字符串的解析结果,就可以将用于混淆的字符串删除。由此可见,在第一数据的解析过程中,通过读位属性确定删除用于混淆的内容之后,即可以顺利解析出format id,则可以继续读取到6551754174694f4e2e3300,根据本例第一部分中针对不存在风险的片段解析分析可知,6551754174694f4e2e3300解析出内嵌对象是公式编辑器3。较之常规解析方法,使用本方案解析本例第二部分中被混淆的第一数据流片段得到内嵌对象是公式编辑器3。因此可以确定该内嵌对象是经过混淆的,根据恶意对象常见的混淆手段,可以确定第一数据流存在风险,即该rtf文档存在风险。
[0090]
值得说明的是,本例中针对rtf文档中常规的format id进行混淆为恶意对象的混淆手段之一;除此之外,还可以将恶意代码16进制字符串shellcode混淆后插入,这种情况同样可以根据上述步骤完成检测,确定shellcode所在的rtf文档存在风险。
[0091]
基于同一发明构思,本技术实施例中提供一种富文本文档的风险检测装置,该装置与前述图1所示富文本文档的风险检测方法对应,该装置的具体实施方式可参见前述方法实施例部分的描述,重复之处不再赘述,参见图3,该装置包括:
[0092]
定位单元201:用于在富文本文档中,定位第一数据流;其中,所述第一数据流是设定的第一控制字前的起始符与所述起始符匹配的结束符之间的数据。
[0093]
具体地,设定第一控制字为objdata。
[0094]
读取单元202;用于读取所述第一数据流中控制字的读位属性,基于所述读位属性删除或保留所述第一数据流中控制字后的数据,得到第一数据;其中,当读位属性为删除时,指示删除对应控制字之后到相邻的下一个控制字之间的数据。
[0095]
具体地,读位属性具有追溯性。当读取到任一控制字的读位属性为空时,则基于所述读位属性的追溯性,依次向所述任一控制字之前追溯距离最近的控制字的读位属性,直到确定所述任一控制字的读位属性;其中,所述追溯性指所述任一控制字的读位属性与距离最近的,同级控制字或者上级控制字的读位属性相同。
[0096]
确定单元203:用于基于所述第一数据中的内嵌对象或者链接,确定所述富文本文档存在风险。
[0097]
具体地,当所述第一数据中包含常规解析方法未解析到的所述内嵌对象或者链接时,确定所述第一数据流中包括混淆内容,确定所述富文本文档存在风险。
[0098]
所述富文本文档的风险检测的装置还包括,基础单元,具体用于检测富文本文档是否包含基础恶意特征;其中,所述基础恶意特征指任一安全解析软件识别出的恶意特征;若是,则确定所述富文本文档存在风险;若否,则定位第一数据流。
[0099]
具体地,基础恶意特征包括:不合规的头部标志、可疑的文档创建者和最后修改者、头部前或后的设定范围内出现控制字、非期望控制字、控制字连续次数超过第一阈值、特定字符使用次数超过第二阈值、控制字长度超过第三阈值、两个16进制字符中出现非期
望字符。
[0100]
基于同一发明构思,本技术实施例还提供一种可读存储介质,包括:
[0101]
存储器,
[0102]
所述存储器用于存储指令,当所述指令被处理器执行时,使得包括所述可读存储介质的装置完成如上所述的富文本文档的风险检测方法。
[0103]
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将装置的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。上述描述的系统,装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
[0104]
在本发明所提供的几个实施例中,应该理解到,所揭露的装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述模块或单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
[0105]
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
[0106]
另外,在本技术各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
[0107]
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本技术的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)或处理器(processor)执行本技术各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:通用串行总线闪存盘(universal serial bus flash disk)、移动硬盘、只读存储器(read-only memory,rom)、随机存取存储器(random access memory,ram)、磁碟或者光盘等各种可以存储程序代码的介质。
[0108]
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1