一种手写数字识别实现方法
1.本发明属于图像识别领域,具体为一种手写数字识别实现方法。
背景技术:
2.目前,人类手写字的识别问题成为了研究热点。这项技术已经被广泛应用在税务表处理、邮件分类和电脑阅卷等方面。在这些应用中通常要求手写数字识别算法具有较高的识别速度和识别精度以及较高的可靠性和稳定性。手写数字的类别虽然只用十种,笔画简单,但是其识别问题仍然存在很大的困难。现有的一些测试结果已经表明,数字的正确识别率并不如印刷体汉字识别正确率高,甚至也不如联机手写体汉字识别率高甚至。主要原因是字体相差不大,每个人的写法不一样,这就使识别更加困难。如何利用设备自动化、智能化、高效的识别数字和字符,提高工作效率则已成为当前亟待解决的研究问题。
3.卷积神经网络的概念在1998年由纽约大学的yann le cun提出,是一个可以成功应用在手写字符识别、车牌识别等很多图像分类上的神经网络。卷积神经网络的本质就是多层感知机的一种。之所以卷积神经网络可以成功应用的在很多方面,主要是因为卷积神经网络的稀疏连接和参数共享可以大大减少网络中参数的数量,使得训练整个卷积神经网络计算量大大降低,变得实际可操作。
4.手写数字识别是cnn领域的经典问题,针对手写体识别领域广泛使用的minist数据集。相较于印刷体数字,手写体数字随意性大,不确定性高,但手写体数字的识别在生活中有着广泛的应用,如银行票据识别、邮件自动分拣以及手机号码识别等。由于cnn具有庞大的参数量与计算量,导致模型无法实现跨平台部署,实用性较差。一方面,各种轻量化小型化网络模型被设计出来,另一方面,由于卷积运算的数据独立性,使得卷积运算的并行加速成为可能。因此,进行手写体数字识别硬件实现有重要的意义
5.cnn模型实现分为训练和推理两部分,目前模型训练阶段的加速是通过cpu+gpu的方式进行,并且已经取得了较好的效果,因此本文主要研究模型推理阶段的硬件加速。在模型的推理阶段,fpga平台以其高性能、低功耗、可重构以及可以在现有的器件上实现领域专用架构,无须开发新的芯片等优点,成为了cnn硬件加速的研究平台。在进行硬件设计时,根据卷积运算的运算量大及参数多等特性,通过分析卷积加速单元的硬件结构,存储及数据传输的特性,研究模型的加速性能与加速平台的资源及带宽之间的关系,模型的功耗与模型中各模块间数据流动的关系,综合考虑加速器结构,性能与功耗之间的关系。
6.但是,由于cnn计算中涉及多种不同类型的运算,如二维卷积运算、非线性激活函数运算、池化(子采样)操作以及全连接层运算,并且这些运算过程往往涉及大量的数据访问以及中间结果数据的存储,这使得采用fpga实现如此复杂和具有庞大计算量的cnn仍然是一项具有挑战的工作,同时大量的浮点数计算会产生精度问题,因此,如何在fpga上高性能地实现应用于手写数字识别的卷积神经网络系统,对于图像识别领域的发展具有重要的理论研究意义和实用价值。
技术实现要素:
7.本发明的目的提出一种手写数字识别实现方法,利用软硬件协同的方式把部分cnn推理过程放到fpga中加速计算,在兼顾识别准确率的同时,加快了识别速度。
8.实现本发明目的的技术方案为:一种手写数字识别实现方法,包括以下步骤:
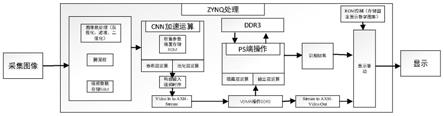
9.步骤1、获取图像数据,在pl端完成视频数据的采集,并对数字采集区域完成图像的预处理;
10.步骤2、将预处理后的数据存储在pl端的bram存储单元中里;
11.步骤3、对卷积神经网络参数进行定点化转换,存入集成arm与fpga的嵌入式平台zynq中的rom ip单元内;
12.步骤4、针对卷积神经网络的卷积核尺寸,构造相应的卷积矩阵,完成预处理后的数据与定点化参数的卷积运算;
13.步骤5、对卷积层运算结果进行激活处理,并对激活结果进行最大池化运算;
14.步骤6、对池化后的数据,构造相应的视频时序,利用video in to axi4-stream ip核和vdma ip核将池化结果传输至ps端ddr;
15.步骤7、ps端完成卷积神经网络的隐藏层和输出层运算,将识别结果通过axi-lite传输至pl端,pl端驱动显示器,在显示画面中实现识别结果的显示功能。
16.优选地,步骤1中对数字采集区域进行的图像的预处理包括:灰度转换、平滑降噪、二值化、降采样处理。
17.优选地,步骤3对卷积神经网络的权重参数值采用定点化运算的方式进行浮点数处理,通过对权值参数扩大一定的整数倍得到定点数。
18.优选地,使用5个rom ip核来存储权重参数,卷积核的大小为5*5,每个rom里面存储150个权重参数,按照5*5矩阵方式排列。
19.优选地,针对卷积神经网络的卷积核尺寸,构造相应的卷积矩阵,完成预处理后的数据与定点化参数的卷积运算,包括:卷积核的输入构造与图像数据的输入构造,分别具体为:
20.卷积核的输入构造:设置参数存储排列顺序,通过rom ip并行拼接完成卷积核排列;在进行卷积运算的时候,开始读取rom中的输入卷积核权重,在经过相应时钟周期之后权重读取停止,将读取的权重缓存到寄存器单元内,并保证单个卷积核的权重值保持不变;当对一整幅输入图像进行卷积运算遍历完之后,输出相应特征图;进行其他卷积核权重读取并与输入图像的运算卷积运算;
21.图像数据的输入构造步骤:通过移位寄存器缓存构造卷积窗口,对输入图像数据进行移位延时,得到输入图像数据的像素矩阵窗口,用卷积核模板对应位置的权重参数与输入的像素矩阵相乘并累加,得出的结果作为窗口中心的输出结果,完成一次卷积运算,得到第一个特征图的第一个输出元素;将输入像素的矩阵窗口,在输入图像区域内,逐行依次滑动,并与第一层卷积核做卷积运算,得到第一个特征图;采用卷积核依次完成卷积运算,得到对应的特征图。
22.优选地,步骤5中对卷积层的结果采用激活函数:relu(x)=max(0,x)处理;选择使用2
×
2的最大值池化来设计池化层;池化窗口的设计和卷积窗口一致,均采用寄存器延时的方式;卷积层和激活函数共有5个时钟的流水线延时,在图像进入卷积层前对图像数据做
行列编号,并作5个时钟的延时处理后与激活函数输出的数据同步进入池化层;对计数延时的行列号分别右移一位,得到池化的索引编号,池化窗口以这个编号进行池化,每两个时钟进行一次池化操作。
23.本发明与现有技术相比,具有以下显著优点:(1)本发明针对手写数字识别硬件实现方法进行优化,通过软硬件协同的方式,在兼顾识别准确率的同时,加速了识别速度;(2)本发明针对原有的手写数字识别算法的基础上做了简化,从而使得整个卷积神经网络结构变的更加简单,更易于在硬件平台实现,充分发挥fpga的优势,同时利用fpga运算的并行性,可以加快运算速度,降低功耗。
24.实现下面结合附图对本发明作进一步详细描述。
附图说明
25.图1为本发明提供的一种手写数字识别实现方法框图。
26.图2为本发明卷积神经网络的计算流程图。
27.图3为本发明所采用cnn流程图。
28.图4为本发明卷积模块运算流程图。
29.图5为本发明relu函数实现逻辑。
30.图6为本发明池化模块运算过程。
31.图7为本发明手写数字识别效果图。
具体实施方式
32.在一个实施例中,一种手写数字识别实现方法,主要包括以下几个步骤:
33.步骤1、获取图像数据,在pl端完成视频数据的采集,并对数字采集区域完成图像的预处理。
34.预处理即是对包含数字的图片进行一系列的处理工作。整个预处理的首要目标是摒弃图片里的无效信息,同时使图像规范化、统一化、这样会方便后面处理过程。通常包括:灰度转换、平滑降噪、二值化、降采样处理。配合卷积神经网络输入层的数据尺寸要求,将采集区域图像压缩成尺寸为28*28大小;
35.步骤2、将预处理后的数据存储在pl端的bram存储单元中里;
36.步骤3、对卷积神经网络参数进行定点化转换,存入集成arm与fpga的嵌入式平台zynq中的rom存储单元内。
37.具体地,由于卷积网络层的权重参数有小数部分,需要进行浮点数运算,大量的浮点数运算会消耗大量运算时间,本发明对卷积神经网络的权重参数值采用定点化运算的方式进行浮点数处理。通过对权值参数扩大一定的整数倍得到定点数,之后将这些定点数参数存到rom内存单元中。在对输入图像数据进行卷积运算的时候,从rom中读出这些已经定点化的参数,来与输入图像进行卷积运算。这样就能将浮点数运算转换成整数间的定点数运算,加速运算过程。通过对扩大倍数的合理设置,可以有效控制运算精度和资源消耗的平衡。
38.本发明使用5个rom ip核来存储权重参数,卷积核的大小为5*5,总共构造30个卷积核。每个卷积核有25个权重参数,所以总共需要存储的权重参数为750个权重参数。每个
rom里面存储150个权重参数,排列顺序按照5*5矩阵方式排列,即第一个rom存储每个卷积核的第一行参数,每个卷积核矩阵一行有5个权重参数;以此类推到最后一个rom存储每个卷积核的第五行权重参数。
39.步骤4、对数据进行卷积运算。针对卷积神经网络的卷积核尺寸,构造30个大小为5*5卷积矩阵,完成卷积运算;
40.本实施例中,根据卷积神经网络的卷积核尺寸,构造5*5大小的卷积矩阵,控制存储在bram中的预处理的数据和存储在rom中的权重参数的读取时序,完成30个卷积核的卷积运算工作,具体分为以下两个步骤:卷积核的输入构造与图像数据的输入。
41.卷积核的输入构造。卷积核的大小为5*5,也就是25个数据,对应25个权重,并且在同一个输入图像的整个过程中是保持不变的。为了保证存储在bram中的预处理的数据和存储在rom中的权重参数在读取的时候一一对应,本发明在步骤4中,要求了参数存储排列顺序,30个5*5卷积核排列是通过5个rom ip并行拼接在一起的。在进行卷积运算的时候,开始读取5个rom中的输入卷积核权重,在经过5个时钟周期之后权重读取停止,将读取的25个权重缓存到寄存器单元内,并保证单个卷积核的权重值保持不变。当对一整幅28*28的输入图像进行卷积运算遍历完之后,输出一个24*24的特征图。之后再进行其他卷积核权重读取并与输入图像的运算卷积运算。
42.在卷积核输入构造过程中要保证两点,一是卷积核输入过程的顺序要对,二是输入的卷积核位置要对(既不能超过,也不能还未达到)。因此在卷积核输入过程中同时数一个卷积核有效信号,用flag来表示,使一个卷积核有效时间恰好为24*24个时钟周期,在有效时间内卷积核恰好到达了正确的位置,然后使flag无效,可以保证卷积核保持不变。
43.图像信号是逐行串行输入,在进行卷积运算步骤操作时,需要同时使用多个邻域像素的灰度值进行计算,所以对预处理后的图像数据构造与卷积核大小匹配的5*5矩阵窗口。具体构造步骤:通过移位寄存器缓存构造卷积窗口,移位寄存器的大小为28个像素,总共需要四个移位寄存器,对输入图像数据进行移位延时,从而得到输入图像数据的5*5像素矩阵窗口,用卷积核模板对应位置的权重参数与输入的5*5的像素矩阵相乘并累加,得出的结果作为窗口中心的输出结果,从而完成一次卷积运算,得到第一个特征图的第一个输出元素。将输入像素的5*5矩阵窗口,在28*28的输入图像区域内,逐行依次滑动,并与第一层卷积核做卷积运算,最终得到第一个24*24大小的特征图。考虑到面积和速度的平衡,如果全部运算会消耗大量的乘法器,所以采用30个卷积核依次完成卷积运算。最终得到30个24*24大小的特征图。
44.虽然卷积层运算模块内使用的乘法器较多,但在耗时方面,本发明提出的方法利用fpga并行运算的特性,可以在同一个时钟内能对25个像素进行运算,同时为了避免组合逻辑延时,在时序设计时均采用四级流水分割数据流,每一级流水运算输入都来自对应上级输出,互不影响。最终输出相比像素输入仅仅延时4个时钟时间。整体实现每个时钟周期都能输出卷积结果,大大提高了系统整体的运算效率。
45.步骤5、对卷积层运算结果进行激活处理,并对激活结果进行最大池化运算;
46.本实施例中,对经过卷积层运算后得到的30个24*24矩阵特征图结果进行激活处理,并对激活后的结果进行2*2最大值池化。卷积层的结果采用激活函数:relu(x)=max(0,x)处理。选择使用2
×
2的最大值池化来设计池化层。由于池化同样是处理串行数据流,所以
池化窗口的设计和卷积窗口一致,均采用寄存器延时的方式。卷积层和激活函数共有5个时钟的流水线延时。为了保证数据流的连续性,在图像进入卷积层前对图像数据做行列编号,并作5个时钟的延时处理后与激活函数输出的数据同步进入池化层。对计数延时的行列号分别右移一位,得到池化的索引编号,池化窗口以这个编号进行池化,每两个时钟进行一次池化操作。
47.步骤6、对池化后的数据,构造相应的视频时序,将池化结果,利用video in to axi4-stream ip核用和vdma ip核将池化结果传输至ps端ddr;
48.步骤7、ps端完成卷积神经网络的隐藏层和输出层运算,最终将识别结果通过axi-lite传输至pl端。pl端驱动显示器,在显示画面中实现识别结果的显示功能。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1