一种中文文本对抗样本生成的方法、系统及介质
1.本发明涉及信息对抗技术领域,具体涉及一种中文文本对抗样本生成的方法、系统及介质。
背景技术:
2.随着计算设备的更新和算力的提高,深度神经网络(dnn)在人工智能(ai)领域得到了广泛的应用,特别是在计算机视觉(cv)和自然语言处理(nlp)两大任务中,取得了惊人的成就。在深度模型取得优秀成果和广泛应用的同时,深度学习模型的安全问题也日益严重。
3.对抗攻击(adversarial attack)即人们通过给正常样本添加某些噪声,利用人无法感知的扰动,使正常的模型做出异常的预测。虽然深度学习模型在各类任务中表现出色,但是在现实生活生产中,样本总是含有噪声的,模型在对某些噪声数据进行任务的时候就会遇到很多问题。面临现实普遍存在的噪声样本和恶意构造的对抗样本,表现卓越的dnn模型遭受极大的安全威胁。
4.目前,国内外在自然语言处理对抗攻击领域的研究,主要有基于梯度的白盒攻击,例如textfool使用了快速梯度下降法;还有黑盒攻击,基于置信度的文本替换等如deepwordbug、textbugger等。
5.在现实场景中,我们无法获取模型结构和参数信息,可能获取到模型的分类置信度信息,甚至只能获取到模型的最终决策标签,因此基于梯度的攻击方法受到限制。现有攻击流程复杂,需要对目标模型进行多次查询;攻击方法大多只是按照一定算法进行组合优化,不具有学习能力;攻击策略并没有考虑到中文文本的特点,攻击策略单一,借鉴英文文本的攻击策略不适用于中文文本。
技术实现要素:
6.鉴于上述问题,本发明的目的在于提供一种中文文本对抗样本生成的方法,以实现强化学习,且实现多种攻击策略,以及对中文文本的适应,攻击流程简单。
7.本发明通过下述技术方案实现:
8.一种中文文本对抗样本生成的方法,包括如下步骤:
9.获取原始文本数据,且所述原始文本数据为中文文本分类器的输入数据;
10.构建一个深度学习攻击模型,使用数据聚集的方法迭代生成训练数据,并使用强化学习的方法训练模型;
11.使用训练好的攻击模型,输入到所述原始文本数据,以获得对抗样本。
12.在一些实施方式中,所述步骤构建一个深度学习攻击模型,使用数据聚集的方法迭代生成训练数据,并使用强化学习的方法训练模型中,构建一个深度学习攻击模型包括如下子步骤:
13.初始化一个攻击模型架构,所述攻击模型架构包括有嵌入层、编码层、解码层和线
性层;
14.初始化攻击模型的参数。
15.在一些实施方式中,所述步骤初始化一个攻击模型架构,所述攻击模型架构包括有嵌入层、编码层、解码层和线性层中,所述嵌入层、编码层和解码层依次串联,且所述嵌入层长度最大为512,解码层和线性层之间用一个dropout单元连接,所述线性层由768个输入神经单元和1个输出单元的多层感知机构成。
16.在一些实施方式中,所述步骤初始化攻击模型的参数中,包括如下子步骤:
17.使用预训练模型的参数来初始化嵌入层、编码层和解码层;
18.使用随机参数来初始化线性层。
19.在一些实施方式中,所述步骤构建一个深度学习攻击模型,使用数据聚集的方法迭代生成训练数据,并使用强化学习的方法训练模型中,使用数据聚集的方法迭代生成训练数据包括如下子步骤:
20.对原始文本数据的每一个句子,使用jieba分词工具做分词操作,得到每个句子的词语集合s={w1,...,wi,...,wn},其中s表示当前句子,wi表示分词后的第i个词语;
21.对分词操作后的每个词语,计算其显著性,具体计算公式为对分词操作后的每个词语,计算其显著性,具体计算公式为s={w1,
…
,wi,
…
,wn}和其中s(s,wi)表示句子s中第i个词wi的显著性,p(y
true
|s)表示原句子被中文文本分类器分类为y
true
的概率,表示句子s删除wi词语之后剩余的文本,表示文本被中文文本分类器分类为y
true
的概率;
22.对分词操作后的每个词语wi,利用wordnet,构建其同义词集合,作为替换的候选词集合ci={c1,...,cn};
23.构建的候选词集合中的每一个候选词,计算其有效性,具体计算公式如下:e(s,wi,cj)=p(y
true
|s)-p(y
true
|s
′i),s={w1,
…
,wi,
…
,wn}和s
′i={w1,
…
,w
i-1
,cj,w
i+1
…
,wn};其中e(s,wi,cj)表示句子s中第i个词wi的候选词cj的有效性,其中s
′i表示句子s使用候选词cj替换词语wi之后的文本,p(y
true
|s
′i)表示文本s
′i被中文文本分类器分类为y
true
的概率;
24.对每一个wi,和每个词的候选词,给出一个替换的评分score=s(s,wi)*e(s,wi,cj),选择其评分最高的候选词c
′
替换wi,定义为一次替换tpi(s,wi,c
′
),对整个句子合构成一个文本处理集合tp={tp1,
…
,tpn};
25.遍历集合tp,迭代地对原句子进行替换,生成的s
′i数据构成对抗样本候选集;对抗样本候选集即训练数据集的文本数据;遍历对抗样本候选集,并且查询中文文本分类器,如果迭代完攻击策略,受害者模型的输出与原标签一致,则以最后一次迭代的索引作为标签添加进数据集;如果分类结果与原标签不一致,以当前句子在数据集中的索引作为标签添加进数据集;
26.遍历原数据集的每一个句子,实施以上操作步骤,即为迭代生成的训练数据集。
27.在一些实施方式中,所述步骤构建一个深度学习攻击模型,使用数据聚集的方法迭代生成训练数据,并使用强化学习的方法训练模型中,使用强化学习的方法训练模型包括如下子步骤:
28.使用每一次迭代获得的训练数据,对模型进行相应的一次迭代的训练;
29.把训练任务建模为一个多分类问题,对于每个原始句子产生的k条训练数据,输入攻击模型,输出k个分数,使用交叉熵损失函数更新模型参数;
30.完成一次迭代训练之后,继续迭代生成新的训练数据集,做下一次迭代训练。
31.在一些实施方式中,所述步骤使用训练好的攻击模型,输入到所述原始文本数据,以获得对抗样本中,获得对抗样本包括如下子步骤:
32.对原始数据的每一个句子,获得攻击模型的输入数据,所述输入数据为目标句子生成的对抗样本候选集;
33.输入获取的数据,攻击模型输出一个标签,映射这个标签对应的文本数据,即可获得攻击模型生成的对抗样本。
34.本发明的目的之二在于提供一种中文文本对抗样本生成的系统,包括:
35.文本处理模块,所述文本处理模块用于原数据文本的分词操作、词语同义词集构建、计算词语显著性、计算替换词有效性、生成文本处理集合;
36.训练数据生成模块,所述训练数据生成模块用于便利生成文本处理集合,对原始文本进行替换操作,生成训练数据的文本部分;查询中文文本分类器,生成训练数据的标签部分;
37.训练模块,所述训练模块用于初始化模型架构和参数,迭代地生成训练数据和训练模型;
38.攻击模块,所述攻击模块用于向训练好的攻击模型输入原数据,且攻击模型输出对抗样本。
39.本发明的目的之三在于提供一种中文文本对抗样本生成的系统,包括用于执行上述方法的单元。
40.本发明的目的之四在于提供一种一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序包括程序指令,所述程序指令当被处理器执行时,使所述处理器执行上述方法。
41.本发明与现有技术相比,具有如下的优点和有益效果:
42.本发明提供了一种带有深度学习的中文文本对抗样本生成的方法,通过学习模型,适应中文文本,实现多种攻击策略,相对现有技术中英文对抗样本生成的方法,流程更加简单。
附图说明
43.为了更清楚地说明本发明示例性实施方式的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。在附图中:
44.图1为本发明方法主步骤流程示意图;
45.图2为本发明方法一子步骤流程示意图;
46.图3为本发明方法一子步骤流程示意图;
47.图4为本发明方法一子步骤流程示意图;
48.图5为本发明方法一子步骤流程示意图;
49.图6为本发明方法的整体的流程框图。
具体实施方式
50.为使本发明的目的、技术方案和优点更加清楚明白,下面结合实施例和附图,对本发明作进一步的详细说明,本发明的示意性实施方式及其说明仅用于解释本发明,并不作为对本发明的限定。
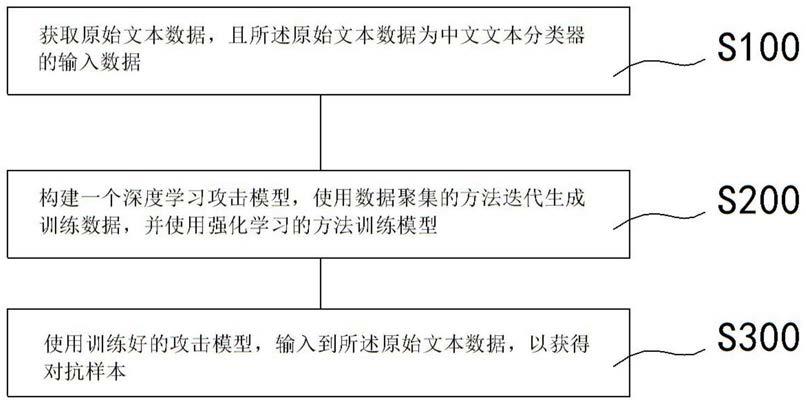
51.如图1和6所示,一种中文文本对抗样本生成的方法,包括如下步骤:
52.s100、获取原始文本数据,且所述原始文本数据为中文文本分类器的输入数据。
53.本步骤中,通过中文文本分类器对输入的数据进行分类,形成需要处理的原始文本数据。
54.s200、构建一个深度学习攻击模型,使用数据聚集的方法迭代生成训练数据,并使用强化学习的方法训练模型。
55.本步骤中利用深度学习技术,形成深度学习共计模型,并进行训练,以满足后续的样本生成。
56.s300、使用训练好的攻击模型,输入到所述原始文本数据,以获得对抗样本。
57.本步骤中通过训练好的攻击模型,并将中文文本的原始文本数据投入攻击模型,进而生成对抗样本。该对抗样本,即为适应的中文文本对抗样本。
58.如图2所示,在一些实施方式中,所述步骤s200中构建一个深度学习攻击模型包括如下子步骤:
59.s210、初始化一个攻击模型架构,所述攻击模型架构包括有嵌入层、编码层、解码层和线性层。
60.本步骤中利用现有的攻击模型架构,并进行初始化,以便于后续的适应性调整。
61.s220、初始化攻击模型的参数。
62.本不中,通过初始化攻击模型的参数,来进行模型整体的调整。
63.在一些实施方式中,所述步骤s210中,所述嵌入层、编码层和解码层依次串联,且所述嵌入层长度最大为512,解码层和线性层之间用一个dropout单元连接,所述线性层由768个输入神经单元和1个输出单元的多层感知机构成。
64.本优选的实施方式中,对攻击模型架构中的嵌入层、编码层和解码层进行了连接及参数限定。
65.如图3所示,在一些实施方式中,所述步骤s220中,包括如下子步骤:
66.s221、使用预训练模型的参数来初始化嵌入层、编码层和解码层。
67.本步骤中,通过预训练模型的参数来处理嵌入层、编码层和解码层,以使得嵌入层、编码层和解码层在本方案中实现适应。
68.s222、使用随机参数来初始化线性层。
69.本步骤中,通过随机参数来初始化线性层,以使得线性层满足训练的需求。
70.在一些实施方式中,所述步骤s200中,使用数据聚集的方法迭代生成训练数据包括如下子步骤:
71.s201、对原始文本数据的每一个句子,使用jieba分词工具做分词操作,得到每个句子的词语集合s={wi,...,wi,...,wn},其中s表示当前句子,wi表示分词后的第i个词语;
72.s202、对分词操作后的每个词语,计算其显著性,具体计算公式为个词语,计算其显著性,具体计算公式为s={w1,
…
,wi,
…
,wn}和其中s(s,wi)表示句子s中第i个词wi的显著性,p(y
true
|s)表示原句子被中文文本分类器分类为y
true
的概率,表示句子s删除wi词语之后剩余的文本,表示文本被中文文本分类器分类为y
true
的概率;
73.s203、对分词操作后的每个词语wi,利用wordnet,构建其同义词集合,作为替换的候选词集合ci={c1,
…
,cn};
74.s204、构建的候选词集合中的每一个候选词,计算其有效性,具体计算公式如下:e(s,wi,cj)=p(y
true
|s)-p(y
true
|s
′i),s={w1,
…
,wi,
…
,wn}和s
′i={w1,
…
,w
i-1
,cj,w
i+1
…
,wn};其中e(s,wi,cj)表示句子s中第i个词wi的候选词cj的有效性,其中s
′i表示句子s使用候选词cj替换词语wi之后的文本,p(y
true
|s
′i)表示文本s
′i被中文文本分类器分类为y
true
的概率;
75.s205、对每一个wi,和每个词的候选词,给出一个替换的评分score=s(s,wi)*e(s,wi,cj),选择其评分最高的候选词c
′
替换wi,定义为一次替换tpi(s,wi,c
′
),对整个句子合构成一个文本处理集合tp={tp1,
…
,tpn};
76.s206、遍历集合tp,迭代地对原句子进行替换,生成的s
′i数据构成对抗样本候选集;对抗样本候选集即训练数据集的文本数据;遍历对抗样本候选集,并且查询中文文本分类器,如果迭代完攻击策略,受害者模型的输出与原标签一致,则以最后一次迭代的索引作为标签添加进数据集;如果分类结果与原标签不一致,以当前句子在数据集中的索引作为标签添加进数据集;
77.s207、遍历原数据集的每一个句子,实施以上操作步骤,即为迭代生成的训练数据集。
78.本优选的实施方式中,给出了获取训练数据集的方法流程,以满足后续的需要。
79.如图4所示,在一些实施方式中,所述步骤s200中,使用强化学习的方法训练模型包括如下子步骤:
80.s2001、使用每一次迭代获得的训练数据,对模型进行相应的一次迭代的训练;
81.s2002、把训练任务建模为一个多分类问题,对于每个原始句子产生的k条训练数据,输入攻击模型,输出k个分数,使用交叉熵损失函数更新模型参数;
82.s2003、完成一次迭代训练之后,继续迭代生成新的训练数据集,做下一次迭代训练。
83.本优选的实施方中,针对强化学习的方法训练,具体给出了三个步骤实现。
84.在一些实施方式中,所述步骤s300中,获得对抗样本包括如下子步骤:
85.s310、对原始数据的每一个句子,获得攻击模型的输入数据,所述输入数据为目标句子生成的对抗样本候选集;
86.s320、输入获取的数据,攻击模型输出一个标签,映射这个标签对应的文本数据,即可获得攻击模型生成的对抗样本。
87.本优选的方式中,针对对抗样本的获得,提供了两个步骤实现。
88.如图5所示,一种中文文本对抗样本生成的系统,包括:
89.文本处理模块,所述文本处理模块用于原数据文本的分词操作、词语同义词集构
建、计算词语显著性、计算替换词有效性、生成文本处理集合;
90.训练数据生成模块,所述训练数据生成模块用于便利生成文本处理集合,对原始文本进行替换操作,生成训练数据的文本部分;查询中文文本分类器,生成训练数据的标签部分;
91.训练模块,所述训练模块用于初始化模型架构和参数,迭代地生成训练数据和训练模型;
92.攻击模块,所述攻击模块用于向训练好的攻击模型输入原数据,且攻击模型输出对抗样本。
93.一种中文文本对抗样本生成的系统,包括用于执行上述方法的单元。
94.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序包括程序指令,所述程序指令当被处理器执行时,使所述处理器执行上述方法。
95.以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1