一种基于语义边缘对齐的由粗到精的多传感器融合定位方法与流程
1.本发明涉及无人驾驶、视觉定位技术领域,具体来说是一种基于语义边缘对齐的由粗到精的多传感器融合定位方法。
背景技术:
2.高精度定位在机器人自主导航,无人驾驶等领域扮演着重要角色。车辆在自主行驶的过程中每个时刻均需要估计其在地图中的位置,即解决“我在哪”这样一个终极命题。根据所使用的传感器的不同,存在着不同的定位方案。使用最广泛的一种定位方案是结合gnss-imu的惯性导航系统,尽管有着较高的精度和鲁棒性,但其在面对长隧道,高楼林立的闹市区域或遮挡严重的高架桥下等场景的时候,由于gps信号的缺失或者多路径效应的影响,惯性导航系统无法输出高精度的定位估计结果。同时高精度的惯性导航系统因为成本较高而无法进行大规模的商业化生产,从而对其使用造成了限制。激光雷达由于其测量精度高,在无人驾驶的定位感知领域得到了广泛应用。但在大尺度范围内的激光雷达slam中,其地图占据的存储量巨大,同时激光雷达高昂的成本使得其更多的应用在配送,仓储机器人等领域,难以在量产无人驾驶的定位中得到应用。视觉传感器由于其成本低,感知信息丰富的特点在智能汽车领域已经得到了广泛的应用。视觉slam中目前较为成熟的特征点法通过提取图像中的显著特征,在不同时刻的图像间通过匹配建立特征关联,最后在一个非线性优化框架中同时完成地图的构建和位姿的估计,但传统的视觉特征点在面对多变的环境,如光照的变化,天气的变化,视角的变化时容易失效,从而无法鲁棒的完成定位任务。近年来,随着深度学习技术的发展,从图像中进行环境的语义感知变得实时且精确。在无人驾驶环境中,包含了如车道线,路牌,杆子等常见的语义信息,这些信息相对鲁棒,不容易发生变化,从而为定位算法提供了丰富稳定的观测,同时为了克服单一视觉定位稳定性不足的问题,引入了车载低精度gps,车载里程计信息来增加定位输出的鲁棒性和精确性。在这样的背景下,提出了一种基于高精度矢量地图的以视觉传感器为主的多传感器融合定位方法,该方法应用由粗到精的状态估计范式,通过语义边缘对齐来进行车辆位姿的估计。
技术实现要素:
3.本发明的目的在于解决现有技术的不足,提出了一种应用在结构化的场景中,基于高精地图的以视觉语义信息为主的多传感器融合定位方法,在嵌入式平台上可以鲁棒精确的输出载体相对于地图的位姿。
4.为了实现上述目的,设计一种基于语义边缘对齐的由粗到精的多传感器融合定位方法,包括获取高精地图、原始图像、消费级的车载gps以及轮子里程计的步骤,其特征在于方法具体如下:a.输入的原始图像首先会经过语义分割网络进行处理得到语义分割图;b.系统初始化,获取当前车辆的初始化位姿;c.计算当前帧的位姿初值;
d.基于当前帧的位姿初值从高精度地图中搜索语义元素,形成对应的地图元素集合,对三维地图点按照一定的距离进行插值采样形成散点;e.将采样后的三维地图点根据当前帧的位姿初值投影到图像上,并在图像上做均匀采样;f.将地图点在代价图像上的投影点光度残差作为非线性优化问题的优化目标,优化车辆本体的位姿使得投影点整体光度残差最小;位姿优化的残差表达式如下:其中i代表语义代价图像,π为相机成像模型,t_wb代表车辆相对于高精地图的位姿,也就是优化估计的状态量,t_bc表示相机相对于车辆的外参,p_w为三维地图点,1.0为代价图像中的灰度的最大值,即图像中亮度最大值;g.在系统运行的过程中,会实时构建一个基于固定长度的滑动窗口的位姿图;h.当前帧的位姿跟踪结束后,系统输出当前帧的车辆定位结果,即相对于高精地图的位置和姿态。
5.进一步地,输入的原始图像首先会经过语义分割网络进行处理分别得到车道线的语义分割图、杆子的语义分割图和路牌的语义分割图,为了能够在图像上进行代价构建,会对语义分割图像进行交替的图像腐蚀膨胀处理得到代价图像,对于路牌的分割图像,会首先使用拉普拉斯变换方法从二值分割图像中进行边缘提取,然后再进行腐蚀膨胀处理得到路牌对应的非线性优化的代价图像。
6.进一步地,系统初始化具体方法如下:步骤一.获取第一帧的输入,判断第一帧输入的gps信号的有效性, 满足要求则将其记录为第一个有效二维轨迹点,否则退出重新进入步骤a;步骤二.获取第二帧的输入,判断第二帧输入的gps信号的有效性,如果有效且与第一个轨迹点的距离适中,则将其记录为第二个有效二维轨迹点,若不满足条件,则重新进步骤一;步骤三.完成步骤二后,将车辆平面坐标设置为第二个有效轨迹点,车辆高度通过在高精地图中搜索得到,滚动角和俯仰角置为0,航向角根据第一个有效点和第二个有效点的矢量方向确定;步骤四.在步骤三的初始位置和姿态的基础上,进行位姿搜索,设定搜索间隔和搜索数量,计算每种位姿下的语义地图点在代价图像上的投影得分,将投影得分最高的位姿作为当前车辆的初始化位姿。
7.进一步地,步骤c中根据前后两帧的里程计数据计算两帧间的位姿增量,利用位姿增量和前一帧的位姿计算当前帧的位姿初值。
8.进一步地,步骤c中如果当前帧的gps观测为有效状态且定位系统在较长时间内未经过纵向位置的更新,则利用当前帧的gps测量更新当前帧的车辆纵向位置。
9.进一步地,步骤f中优化的时候会采用两阶段优化,第一阶段对所有投影点形成的
残差施加鲁棒核,以对离群点观测对最小二乘优化问题造成的影响进行约束,第二阶段将一阶段优化后残差超过一定阈值的观测进行去除,对剩余观测不施加鲁棒核,重新进行优化求解。
10.进一步地,步骤g中新的帧被加入,最老的帧被移除,当车辆处于静止状态的时候,次新帧会被移除,位姿图中的优化变量包括当前帧以及历史帧的位姿,观测约束包括窗口中每帧的视觉边缘对齐的位姿以及两帧之间的里程计的约束。
11.本发明同现有技术相比,其优点在于:是一种低成本的以视觉传感器为主的高精定位方法,通过融合里程计和车载gps信息获得鲁棒的定位结果,通过提取图像中稳定的语义特征,进行语义边缘对齐来得到车辆位姿的估计,对齐的方式不需要显式的进行三维地图特征和二维图像特征的数据关联,而是隐式的通过最小化投影点的光度残差来进行位姿的估计;是一种低成本,高精度,鲁棒的应用于自动驾驶的定位方法。
附图说明
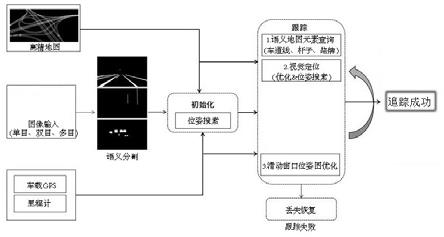
12.图1是本发明高精地图示意图;图2是本发明车道线语义分割图;图3是本发明车道线代价图;图4是本发明路牌语义分割图;图5是本发明路牌代价图;图6是本发明流程图;图7是本发明原始及优化后的位姿地图点投影结果图;图中:a为原始位姿地图点投影结果b为优化后的位姿地图点投影结果。
具体实施方式
13.下面结合附图对本发明作进一步说明,本发明的结构和原理对本专业的人来说是非常清楚的。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
14.本发明提出一种视觉高精定位方法,使得结合单目相机及高精地图数据可以完成高精地图覆盖区域中道路的车辆高精度定位,对地图中的道路语义元素与单目图片中的视觉语义元素进行数据关联,基于优化方法或搜索方法可以对车辆位姿进行估计,构建非线性优化问题使代价最小化,从而完成基于视觉感知的高精度定位。其中所利用的地图语义元素包括但不限于车道线,道路两侧路灯等杆状物体,道路标示牌,停止线等。所采用的高精地图如图1所示。
15.如图6所示,方法流程如下:系统的输入包含离线建好的高精地图,原始图像(不限于单目,双目或多目图像),消费级的车载gps以及轮子里程计。输入的原始图像首先会经过语义分割网络进行处理分别得到车道线的语义分割图,杆子的语义分割图和路牌的语义分割图。如图2所示,为车道线的语义分割图。
16.为了能够在图像上进行代价构建,会对语义分割图像进行交替的图像腐蚀膨胀处理得到代价图像。代价构建指的是图像分割的结果进行后处理,从而形成具有平滑梯度的
图像,进而才能够在图像上进行梯度计算以及非线性优化。
17.图像腐蚀和膨胀是传统计算机视觉领域的基础操作。图像腐蚀剧透对图像“瘦身”的功能,图像膨胀具有对图像“增肥”的功能。
18.如图3为对车道线的语义分割图先进行多次的膨胀,再进行多次的腐蚀,最后进行一次高斯平滑即可得到车道线的代价图像,这个代价图像被用来进行后续的车辆位姿状态估计。
19.对于路牌的分割图像,会首先使用边缘提取算法如拉普拉斯变换等方法从二值分割图像中进行边缘提取,然后再进行腐蚀膨胀处理得到路牌对应的非线性优化的代价图像。如图4为路牌的语义分割图,图5为经过腐蚀膨胀后得到的路牌的代价图像。
20.杆子和车道线的处理方法完全一致,它们在实际场景下基本都是线状物体,因此不需要进行像路牌那样额外的边缘提取,其像车道线分割图像那样直接进行腐蚀膨胀处理即可。
21.定位系统在获得输入后,主要包括系统初始化,位姿跟踪两个步骤。初始化模块需要根据初始帧的输入确定车辆的初始位置和姿态。其方法如下:1.获取第一帧的输入,判断第一帧输入的gps信号的有效性, 满足要求则将其记录为第一个有效二维轨迹点,否则退出重新进入第一步。
22.2.获取第二帧的输入,判断第二帧输入的gps信号的有效性,如果有效且与第一个轨迹点的距离适中,则将其记录为第二个有效二维轨迹点。若不满足条件,则重新进入第一步。
23.3.完成第二步后,将车辆平面坐标设置为第二个有效轨迹点,车辆高度通过在高精地图中搜索得到,滚动角和俯仰角置为0,航向角根据第一个有效点和第二个有效点的矢量方向确定。
24.4.在第三步的初始位置和姿态的基础上,进行位姿搜索。位姿搜索就是搜索出最吻合图像观测的位姿,不限于对位姿的6个自由度进行搜索,包括车辆的横向位置,纵向位置,高度,滚动角,俯仰角,航偏角。
25.设定一定的搜索间隔和搜索数量,如车辆横向位置上搜索间隔为0.2,正负方向上搜索数量均为40,则车辆横向位置的搜索半径为-8m到+8m.对6自由度位姿中的横向位置,航偏角,滚动角进行搜索,计算每种位姿下的语义地图点在代价图像上的投影得分,将投影得分最高的位姿作为当前车辆的初始化位姿。
26.每种车辆位姿下都会对应一种地图元素在图像上的投影结果,我们会基于在代价图像上的投影结果计算投影的得分,比如说当地图中的车道线投影到图像上的车道线的时候,得分就会高,如果因为位姿的不准确没有投影到图像中的对应位置的时候,得分就会低。比如说有100种位姿的假设,并行计算每种位姿假设下的投影得分,将得分最高的位姿假设作为当前车辆的初始化位姿。
27.5.搜索结束后,系统初始化完成,系统进入跟踪状态。
28.初始化完成后,系统进入位姿跟踪状态,其步骤如下:1.根据前后两帧的里程计数据计算两帧间的位姿增量,利用位姿增量和前一帧的位姿计算当前帧的位姿初值。
29.2.如果当前帧的gps观测为有效状态且定位系统在较长时间内未经过纵向位置的
更新,则利用当前帧的gps测量更新当前帧的车辆纵向位置。
30.3.基于当前帧的位姿初值从高精度地图中搜索语义元素,包括车道线,杆子,路牌,形成对应的地图元素集合。对三维地图点按照一定的距离进行插值采样形成散点。
31.4.将采样后的三维地图点根据当前帧的位姿初值投影到图像上,并在图像上做均匀采样。
32.5.将地图点在代价图像上的投影点光度残差作为非线性优化问题的优化目标,优化车辆本体的位姿使得投影点整体光度残差最小。当环境信息丰富的时候如路牌,车道线等元素同时存在的时候,将六自由度位姿作为优化变量。当只存在车道线等元素的时候,只对俯仰角,航偏角,横向位置以及高度这四个自由度的状态量进行优化,在这样的情况下,车辆纵向位置不可观。优化的时候会采用两阶段优化,第一阶段对所有投影点形成的残差施加鲁棒核,以对离群点观测对最小二乘优化问题造成的影响进行约束。第二阶段将一阶段优化后残差超过一定阈值的观测进行去除,对剩余观测不施加鲁棒核,重新进行优化求解。如图7所示,为初始位姿地图点投影结果和优化后的位姿地图点投影结果,经过优化后,投影点均落在代价图像上最亮的区域。
33.上式为位姿优化问题的残差表达式,其中i代表语义代价图像,π为相机成像模型,t_wb代表车辆相对于高精地图的位姿,也就是优化估计的状态量,t_bc表示相机相对于车辆的外参,p_w为三维地图点, 1.0为代价图像中的灰度的最大值,即图像中亮度最大值。
34.6.在系统运行的过程中,会实时构建一个基于固定长度的滑动窗口的位姿图,新的帧被加入,最老的帧被移除。当车辆处于静止状态的时候,次新帧会被移除。位姿图中的优化变量包括当前帧以及历史帧的位姿,观测约束包括窗口中每帧的视觉边缘对齐的位姿以及两帧之间的里程计的约束。通过位姿图优化,可以获得更加鲁棒平滑的位姿输出,有利于无人驾驶系统中下游规划模块的使用。
35.7.当前帧的位姿跟踪结束后,系统输出当前帧的车辆定位结果,即相对于高精地图的位置和姿态。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1