一种高效的零知识证明加速器及方法
1.本公开涉及电子信息技术,具体涉及一种高效的零知识证明加速器及方法。
背景技术:
2.零知识证明(zero knowledge proofs,zkp)是一种强大的密码学协议。简而言之,其中证明者(prover)知道问题的答案,他需要向验证者(verifiers)证明“他知道答案”这一事实,但是要求验证者不能获得答案的任何信息。目前,零知识证明由于其极高的隐私性及简洁性,对于提供隐私保全的验证特别有用。在区块链领域有许多应用,例如安全多方计算,分布式存储,可验证外包数据库,链下扩容,在线拍卖等等。然而,零知识证明在应用中一个重要的障碍在于证明者生成证明的过程非常耗时,因为生成证明包含大量大位宽数据在有限域上的多项式计算(包括快速数论变换及快速数论逆变换)和椭圆曲线多标量乘法。
3.采用通用中央处理器(cpu)或图形处理器(gpu)对零知识证明进行计算,不但功耗高,并且计算慢。基于现场可编程门阵列(fpga)或专用集成电路(asic)实现的零知识证明加速器在计算速度及效能方面有较高的提升。
4.现有技术采用流水线架构的专用集成电路实现零知识证明加速器,其内部实现了对多项式计算和椭圆曲线多标量乘法的加速,但由于椭圆曲线多标量乘法采用pippenger算法与粗粒度流水线架构实现,导致加速器内部需要数十个大数模乘硬件电路,直接导致其需要超大数量的dsp单元。因此,asic需要超大的芯片面积,而过大的芯片面积容易导致芯片量产的不良率升高。然而,如果用fpga实现,也很难在一颗dsp资源有限的fpga芯片上部署这样的流水线架构的专用集成电路。
技术实现要素:
5.有鉴于此,本技术的主要目的在于提供一种用于加速零知识证明算法的加速器,通过高效利用硬件资源方法,从而实现使用少数的数字信号处理(dsp)单元就可以实现对高复杂度的零知识证明算法的加速。
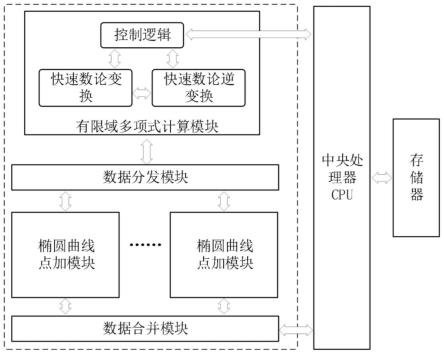
6.一方面,本发明提出了一种高效的零知识证明加速器,所述加速器包括数据合并模块、多个椭圆曲线点加模块、数据分发模块、有限域多项式计算模块;所述有限域多项式计算模块将椭圆曲线的点与标量数据进行快速数论变换与快速数论逆变换,以完成有限域多项式计算,输出第一计算结果;所述数据分发模块将第一计算结果中的椭圆曲线点乘计算分解成椭圆曲线点加计算,并将需要进行点加计算的一组点分发给一个椭圆曲线点加模块;所述多个椭圆曲线点加模块在空间上进行并行计算,并将点加结果输出给数据合并模块进行合并打包。
7.优选地,在所述加速器中,所述椭圆曲线点加模块包括数据流控制单元;所述数据流控制单元将椭圆曲线点加计算分解为多步计算公式,每一步计算公式只包含一次大数模乘或者大数模加或者大数模减计算。
8.优选地,在所述加速器中,所述数据流控制单元能够同时输入多个椭圆曲线点组
合,并对同时输入的多个椭圆曲线点组合进行流水线并行计算。
9.优选地,在所述加速器中,一个所述椭圆曲线点加模块用一个大数模乘电路实现。
10.另一方面,本发明提出了一种高效的零知识证明方法,所述方法包括下述步骤:
11.s100、获取需要计算的椭圆曲线的点与标量数据;
12.s200、将所述数据经过多次的快速数论变换与快速数论逆变换,完成有限域高次多项式计算;
13.s300、将有限域高次多项式计算的计算结果中的椭圆曲线点乘运算分解为多个并行进行的椭圆曲线点加运算,每个椭圆曲线点加运算依次对椭圆曲线上的点组合进行点加运算;
14.s400、将椭圆曲线点加运算的计算结果进行合并。
15.优选地,在所述方法中,所述s400还包括下述步骤:
16.s401、将每个点组合对应的点加运算分解为多步计算公式,每一步计算公式只包含一次大数模乘或者大数模加或者大数模减计算。
17.优选地,在所述方法中,所述s401之后还包括下述步骤:
18.s402、采用多级流水线方式将多个点组合按公式进行并行计算。
19.优选地,在所述方法中,所述每个椭圆曲线点加运算通过一个大数模乘电路实现。与现有技术相比:
20.本发明可以为零知识证明计算提供一个高算力高效能的硬件载体。本发明采用一种细粒度的流水线架构,即只需一个大数模乘硬件电路即可对椭圆曲线点加计算进行流水计算加速。同时,如果将多个大数模乘硬件电路集成,可以实现对多个椭圆曲线点加计算进行并行加速。因此,本发明比现有技术更加灵活适用于不同规模的asic和fpga。
附图说明
21.为了更清楚地说明本技术实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
22.图1本发明实施例中的零知识证明加速器框架示意图;
23.图2是本发明实施例中的椭圆曲线点加模块示意图;
24.图3是本发明实施例中的大数模乘流水线示意图示意图。
具体实施方式
25.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
26.本技术的说明书和权利要求书的术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含。例如,包含了一系列步骤或设备的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或设备,而是可包括没有清楚地列出的或对于这些过程、方
法、产品或设备固有的其他步骤或设备。
27.为使本技术的目的、技术方案和优点更加清楚,下面以具体实施例对本发明的技术方案进行详细说明。下面几个具体实施例可以相互结合,对于相同或相似的概念或过程可能在某些实施例不再赘述。
28.在一个实施例中,采用了一种高效的零知识证明加速器,所述加速器包括数据合并模块、多个椭圆曲线点加模块、数据分发模块、有限域多项式计算模块;所述有限域多项式计算模块将椭圆曲线的点与标量数据进行快速数论变换与快速数论逆变换,以完成有限域多项式计算,输出第一计算结果;所述数据分发模块将第一计算结果中的椭圆曲线点乘计算分解成椭圆曲线点加计算,并将需要进行点加计算的一组点分发给一个椭圆曲线点加模块;所述多个椭圆曲线点加模块在空间上进行并行计算,并将点加结果输出给数据合并模块进行合并打包。
29.在这个实施例中,如图1所示,可以是加速器通过所在系统上的cpu将需要计算的椭圆曲线的点与标量数据从存储设备中读取后,传输给加速器,也可以是将加速器单独集成为一个装置,在该装置中配置一个数据读取模块,从存储设备中获取需要计算的椭圆曲线的点与标量数据。读取到加速器上的椭圆曲线的点与标量数据,经过上万/亿次计算的快速数论变换与快速数论逆变换,完成有限域多项式计算。计算结果通过数据分发模块分发给椭圆曲线点加模块,数据分发模块是实现包括pippenger算法在内的将椭圆曲线点乘分解为椭圆曲线点加的模块。椭圆曲线点加模块用于对点组合进行点加计算,可以集成多个椭圆曲线点加模块,从而实现在空间上进行并行计算。最后将计算结果通过数据合并模块打包,并发送给cpu或直接写入其它存储设备。
30.由于每一个椭圆曲线点加模块会被输入多个需要进行点加运算的点组合,为了进一步加速计算,对输入的多个椭圆曲线点加计算进行并行加速。
31.更优地,为了进一步加速计算,在数据流控制单元采用多级流水线方式按公式进行并行计算。在这种优化计算方式下,椭圆曲线点加计算,在数据流控制单元被分解成了公式1、公式2、
…
、公式n,并解析了各个公式之间的数据依赖性。一个公式即一个大数模乘,需要多个时钟周期才能计算完成。因而,没有数据依赖关系的大数模乘或者大数模加或者大数模减计算之间就可以并行执行。
32.对椭圆曲线点加模块内部实现进行细粒度流水线实现后,椭圆曲线点加模块对硬件的需求大大减小,一个椭圆曲线点加模块的计算可以通过一个大数模乘硬件电路实现,从而使加速器更加灵活适用于不同规模的asic和fpga。其中,大数模乘硬件电路可以是任何架构的多级模乘架构。通常大数模乘硬件电路包含dsp电路阵列、加法树电路、取模电路。大数分成多个位宽较小的数,将其通过dsp电路阵列进行乘法运算。乘法运算结果通过加法树电路累加。累加的结果通过取模电路计算得到大数模乘结果。
33.在一个实施例中,椭圆曲线点加模块通过数据流控制单元将每个椭圆曲线点加计算分解多步计算公式,这些公式可能会因椭圆曲线上的坐标点不同而不同。每一步计算公式只包含一次大数模乘或者大数模加或者大数模减计算。如图2所示,数据流控制单元的输入点组合有{p00,p01}、{p10、p11}、{p02,p21}、{p30、p31}
……
,将它们的椭圆曲线点加分解成多步公式,每步计算公式只包含一次大数模乘或者大数模加或者大数模减计算,计算后将结果合并,依次得到合并后的点{p0},{p1},{p2},{p3}
……
。
34.图3示意了一个多级流水线大数模乘,要将椭圆曲线上点组合{p00,p01}、{p10、p11}、{p02,p21}、{p30、p31}进行点加计算,获得点加结果{p0},{p1},{p2},{p3}。在数据流控制单元被分解成公式1、公式2、
…
、公式n。假设完成一个公式计算需要5个操作,每个操作需要一个时钟周期。在第一个时钟周期,对公式1(p00,p01)执行第一操作;在第二个时钟周期,对公式1(p00,p01)执行第二操作,同时对公式1(p10,p11)执行第一个操作;在第三个时钟周期,对公式1(p00,p01)执行第三操作,对公式1(p10,p11)执行第二操作,对公式1(p20,p21)执行第一操作;在第四个时钟周期,对公式1(p00,p01)执行第四操作,对公式1(p10,p11)执行第三操作,对公式1(p20,p21)执行第二操作,对公式1(p30,p31)执行第一操作;在第五个时钟周期,对公式1(p00,p01)执行第五操作,对公式1(p10,p11)执行第四操作,对公式1(p20,p21)执行第三操作,对公式1(p30,p31)执行第二操作,对公式2(p10,p11)执行第一个操作。至此,公式1(p10,p11)完成计算。以此类推,直至最后完成公式n(p10,p11)计算,将公式1(p10,p11),公式2(p10,p11),
……
公式n(p10,p11)的计算结果合并,得到点{p0}。
35.通过采用多级流水并行计算,使得同时输入多个椭圆曲线点组合,采用一个大数模乘硬件电路即可实现一个椭圆曲线点加模块的加速计算,现有技术pipezk,每个椭圆曲线点加模块内包含的大数模乘电路有16个。因此,本发明可以更加高效地利用硬件资源。进一步地,根据硬件资源规模,特别是fpga的逻辑计算资源,可以灵活配置集成多个大数模乘硬件电路进行椭圆曲线多标量乘法的并行计算,从而实现对高复杂度的零知识证明算法的加速。
36.经模拟验证,在计算bls12-381椭圆曲线点加时候,在100个时钟周期内,可以完成5组共10个用雅可比坐标表示的椭圆曲线的点的点加。同时,26位
×
17位的dsp单元只需要345个。
37.基于上述硬件计算器设计,本发明提出了一种高效的零知识证明方法,所述方法包括下述步骤:
38.s100、获取需要计算的椭圆曲线的点与标量数据;
39.s200、将所述数据经过次的快速数论变换与快速数论逆变换,完成有限域高次多项式计算;
40.s300、将有限域高次多项式计算的计算结果中的椭圆曲线点乘运算分解为多个并行进行的椭圆曲线点加运算,每个椭圆曲线点加运算依次对椭圆曲线上的点组合进行点加运算;
41.s400、将椭圆曲线点加运算的计算结果进行合并。
42.在一个实施例中,将步骤s400进一步优选以便于加速运算,即:将每个点组合对应的点加运算分解为多步计算公式,每一步计算公式只包含一次大数模乘或者大数模加或者大数模减计算。
43.在另一个实施例,基于前述将每个点组合对应的点加运算分解为多步计算公式,进一步解析了公式之间的数据依赖性,将没有数据依赖关系的大数模乘或者大数模加或者大数模减计算之间进行并行执行,即采用多级流水线方式将多个点组合进行并行计算。具体地,将公式计算过程进行进一步细化分解多个操作,每个时钟周期完成一个操作。
44.优选地,在所述方法中,所述每个椭圆曲线点加运算通过一个大数模乘电路实现。与现有技术相比:
45.本发明可以为零知识证明计算提供一个高算力高效能的硬件载体。本发明采用一种细粒度的流水线架构实现时间上的并行计算,即只需一个大数模乘硬件电路即可对椭圆曲线点加计算进行流水计算加速。同时,将多个大数模乘硬件电路集成,可以在空间上实现对多个椭圆曲线点加计算进行并行加速。因此,本发明比现有技术更加灵活适用于不同规模的asic和fpga。
46.综上所述,以上仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1