一种基于空洞残差特征金字塔的咽喉器官分割方法
1.本发明属于计算机视觉和模式识别领域,具体涉及一种基于空洞残差特征金字塔的咽喉器官分割方法。
背景技术:
2.近年来鼻咽喉疾病发病率日趋升高,电子喉镜作为观察空腔脏器黏膜最直接有效的手段,其影像已成为临床医生对鼻咽喉疾病诊断和微创诊疗的重要参考依据。对鼻咽喉器官分割从而进行进行定性和定量化分析,是医生进行诊断并制定治疗计划的重要辅助手段。但是临床诊断中图像数据量巨大,人工诊断方式时间成本高,并且容易出现漏检、误检等情况,因此需要借助计算机辅助医生进行诊断。如鼻咽癌是我国常见的十大恶性肿瘤之一,由于发病部位隐蔽,症状和体征多变,早期病症在内镜图像上常被忽视,待发现癌变时,已错过了最佳的治疗时间。
3.鼻咽喉器官处在复杂多变的灰度信息混淆背景下,且器官边界模糊,与背景灰度相似,使得器官分割难度增加。由于鼻咽喉器官的复杂性,使得基于电子内窥镜图像的多器官分割具有较大难度,传统的unet和deeplab系列网络在鼻咽喉多器官分割上存在分割精度偏低的问题。而mask r-cnn以及一些改进的mask r-cnn分割算法在内窥镜图像分割上表现出很大的潜力,但是其中的fpn网络,在连续卷积操作中不可避免地造成的图像信息丢失,不利于对边界不清晰且较小尺度物体的分割。
技术实现要素:
4.本发明的目的是提供一种基于空洞残差特征金字塔(dilated residual pyramid-mask,drp-mask)的咽喉器官分割方法,以克服现有技术存在的在连续卷积操作中不可避免地造成的图像信息丢失,不利于对边界不清晰且较小尺度物体的分割的问题。
5.为实现上述目的,本发明的具体技术方案如下:
6.一种基于空洞残差特征金字塔的咽喉器官分割方法,所述方法包括以下步骤:
7.步骤1:采用drp-fpn网络提取咽喉器官特征,在fpn中每个横向连接引入残差空洞卷积模块感知不同大小的感受野,然后与不同尺度特征层进行融合,得到包含全局信息的特征图;
8.步骤2:采用rpn网络,对特征图的每个特征点设定预定个先验框,同时对各个先验框判断包含目标的可能性,在特征图上生成不同尺寸和长宽比的anchor,然后采用非极大值抑制算法筛选出可能性最大位置信息anchor,得到精确的proposals框;
9.步骤3:采用roi align方法,根据proposals框从特征图中提取候选区域,使用双线性内插法从候选区域中生成尺寸相等且固定的roi区域;
10.步骤4:采用分类网络和边框回归网络,对roi区域计算分类损失和边界框回归损失,确定精确的proposals框的位置和类别;同时采用fcn网络对roi区域进行分割生成掩图。
11.进一步地,步骤1中,所述残差空洞卷积模块包含空洞卷积结构和残差结构,其中空洞卷积结构对每个横向连接使用三个并行空洞卷积操作,卷积核为3
×
3,空洞率分别为2、4、8,然后使用一个3x3的卷积层合并空洞卷积操作得到的特征,最后采用残差结构将空洞卷积后的特征与横向连接特征进行组合得到新的横向特征。
12.与现有技术相比,本发明的有益效果是:
13.本发明采用drp-fpn网络,对fpn中每个横向连接引入dr模块感知不同大小的感受野,然后与不同尺度特征层进行融合,极大提升全局信息提取,空洞卷积通过空洞率控制卷积核所能影响到的像素区域,在保证计算量不增加的前提下,扩大感受野,有效提高了图像分割的平均精度、mdice系数和miou的值,不会造成的图像信息丢失,边界清晰且可实现对较小尺度物体的分割。
附图说明
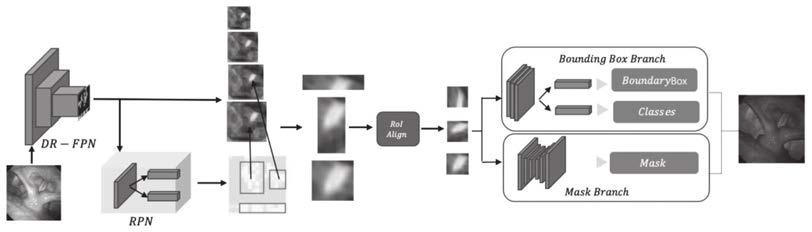
14.图1为本发明实施例中基于空洞残差特征金字塔的咽喉器官分割方法的框架图;
15.图2中(a)、(b)分别为本发明实施例中用于多尺度特征提取的drp-fpn框架图、特征提取阶段的结构图;
16.图3为本发明实施例中区域生成模块anchor覆盖图;
17.图4为本发明实施例中区域生成网络结构图;
18.图5为本发明实施例中不同网络的可视化结果。
具体实施方式
19.下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
20.本发明提出了一个two-stage实例分割模型drp-mask,第一个阶段通过提出的drp模块提取图像特征并生成proposals,第二阶段对proposals进行分类并生成边界框和掩图。
21.如图1所示,本发明提供的一种基于空洞残差特征金字塔(dilated residual pyramid-mask,drp-mask)的咽喉器官分割方法,包括以下步骤:
22.步骤1:采用drp-fpn网络提取咽喉器官特征,在fpn中每个横向连接引入残差空洞卷积模块感知不同大小的感受野,然后与不同尺度特征层进行融合,极大提升全局信息提取;
23.所述融合多尺度特征具体操作为:通过融合上采样,下采样以及对应层的横向连接三部分特征,得到包含细节语义信息和空间信息的特征图,将上采样过程中得到的每一个尺度的特征都与下采样时对应尺度的特征相融合,即横向连接,从而极大提高网络对特征学习能力。
24.所述残差空洞卷积模块包含空洞卷积结构和残差结构,其中空洞卷积结构对每个横向连接使用三个并行空洞卷积操作,卷积核为3
×
3,空洞率分别为2、4、8,然后使用一个3x3的卷积层合并空洞卷积操作得到的特征,最后采用残差结构将空洞卷积后的特征与横向连接特征进行组合得到新的横向特征。
25.步骤2:采用rpn网络,对特征图的每个特征点设定预定个先验框,同时对各个先验
框判断包含目标的可能性,在特征图上生成不同尺寸和长宽比的anchor,然后采用非极大值抑制算法筛选出可能性最大位置信息anchor,得到精确的proposals框;
26.步骤3:采用roi align方法,根据proposals框从特征图中提取候选区域,使用双线性内插法从候选区域中生成尺寸相等且固定的roi区域;
27.步骤4:采用分类网络和边框回归网络,对roi区域计算分类损失和边界框回归损失,确定精确的proposals框的位置和类别;同时采用fcn网络对roi区域进行分割生成掩图。
28.在上述实施例的基础上,进一步详述描述如下,给定一张鼻咽喉图像,我们使用drp-fpn网络提取丰富的语义和空间特征来表示图像。drp-fpn网络结构如图2(a)所示,采用残差空洞卷积模块(dr),融合了上采样、下采样以及对应层的横向连接三部分特征,提取了丰富的特征。为了实现端到端的训练,本实施例提出的残差空洞卷积模块drp共输出四个尺度的特征p5、p4、p3、p2。首先对图像进行连续下采样,得到五个尺度的特征c1、c2、c3、c4、c5,然后从c5开始进行连续上采样得到特征m5、m4、m3、m2,上采样过程中得到的每一个尺度的特征都与下采样时对应尺度的特征相融合,即横向连接。如图2(b)所示,每个横向连接中使用三个空洞卷积操作,卷积核为3
×
3,空洞率分别为2、4、8,将空洞卷积得到的特征与横向连接特征进行融合得到一个新的横向特征,具体表示公式为(1)、(2),如图2(a)所示,生成4路特征图p5,p4,p3,p2大小分别为192
×
192,96
×
96,48
×
48,24
×
24。
29.pi=conv(concatenate(up(p
i-1
),dr(ci)))
ꢀꢀ
(1)
30.dr(ci)=concatenate(dconv(ci,2),dconv(ci,4),dconv(ci,8))+ciꢀꢀ
(2)
31.区域生成模块是小型的神经网络,该网络使用滑动窗口对特征图进行扫描,对每次滑动窗口的中心点在原像素图像上找到其映射点,称之为锚点。以该锚点为中心,生成k个矩形框作为候选框,k的选取满足公式(3)。所生成候选框如图3。该模块的输入是drp生成的多尺度特征图,输出分别为候选框的类别和坐标信息。这里选择候选框与真实box有最大iou为正样本。如果分类为前景则认为这候选框中很可能存在一个目标,对于候选框的位置回归,模型采用真实box与候选框之间的坐标偏置进行训练。结构如图4所示。使用该区域生成模块,保留包含目标可能性最大的anchor,并对其位置和尺寸进行精调。为减少部分anchor互相重叠而导致的重复计算,使用非极大值抑制算法(non maximum suppression,nms)剔除冗余anchor,仅保留nms值最高的anchor。
32.k=scale
×
ratios(scale=3,ratios=3)
ꢀꢀ
(3)
33.经过区域生成网络之后,proposals通常大小不等,需要从这些大小不等的proposals提取出尺寸相等且固定的特征。roi align即可实现这一需求,算法流程如下:
34.(1)遍历每一个候选区域,保持浮点数边界不做量化。
35.(2)将候选区域分割成k x k个单元,每个单元的边界也不做量化。
36.(3)在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。
37.采用分类网络和边框回归网络,对roi区域计算分类损失和边界框回归损失,确定精确的proposals框的位置和类别;同时采用fcn网络对roi区域进行分割生成掩图。
38.采用自建数据集来验证本发明提供的鼻咽喉器官分割方法的有效性。从采集的350份视频数据随中裁剪得到图像分辨率为1060
×
1075的训练集图像8000张,验证集和测
试集分别1000张,在训练过程中对数据集图像采用了随机翻转、色彩抖动、噪声干扰等增强技术来克服神经网络容易产生过拟合现象,最终得到训练集共计16000张,验证集2000张。训练时,图像输入shape为768
×
768,batchsize为8进行训练。每个epoch训练300步,验证20步,共训练100个epoch,初始学习率设置为0.001,衰减权重为0.0001,非极大值抑制iou阈值为0.5。
39.图5为本发明实施例中不同网络的可视化结果,经结果表明,采用本发明的技术方案(drp-mask)得到的分割图像最清晰,分割精度更高。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1