一种基于用户自定义修正词库的文字修正方法及装置与流程
1.本发明涉及文字识别技术领域,尤其涉及一种基于用户自定义修正词库的文字修正方法及装置。
背景技术:
2.近年来,随着计算机视觉技术的快速发展,图片文字的ocr(optical character recognition,光学字符识别)技术成为了热门的发展方向。在ocr识别过程中,识别结果的准确性至关重要。如果识别结果不准确,可能会带来一些不必要的麻烦,而且还会制约ocr识别技术的发展。
3.因此,需要一种能够提高ocr识别技术准确性的方法。
技术实现要素:
4.本发明通过提供一种基于用户自定义修正词库的文字修正方法及装置,能够提高ocr识别技术准确性。
5.本发明提供了一种基于用户自定义修正词库的文字修正方法,包括:
6.对文档di进行分词处理,得到集合f;所述集合f=cut(di)={w
i1
,w
i2
,
……
,w
im
},其中,m表示文档di经过分词处理之后得到的词语wi的个数;
7.将所述集合f中的词语wi与预设的修正词库中的错误词进行匹配;
8.若匹配成功,用所述修正词库中与所述错误词对应的第一修正词替换词语wi,得到修正后的合集f
′
={w
′
i1
,w
′
i2
,
……
,w
′
im
,},并将所述第一修正词的自动推荐频次m_frequence加一;
9.通过公式计算得到所述第一修正词的绝对置信度a_confidence;其中,δ1表示预设的第一平滑;
10.通过公式计算得到所述第一修正词的相对置信度r_confidence;其中,u_frequence表示所述第一修正词的人工推荐频次;
11.通过公式通过公式计算得到所述第一修正词的混合置信度confidence;其中,σa表示m_confidence的标准差,表示m_confidence的平均值,σr表示u_frequence的标准差,表示u_frequence的平均值;
12.将混合置信度最大的修正词作为所述修正词库中优先推荐的修正词。
13.具体来说,还包括:
14.接收修改指令;所述修改指令包括:修改命令、目标原词及指定修正词;
15.将所述指定修正词与所述预设的修正词库中的第二修正词进行匹配;
16.若匹配成功,用所述第二修正词替换所述目标原词,并将所述第二修正词的人工推荐频次ud_frequence加一;
17.通过公式计算得到所述第二修正词的绝对置信度ac_confidence;其中,mc_frequencei表示所述第二修正词的自动推荐频次,δ2表示预设的第二平滑;
18.通过公式计算得到所述第二修正词的相对置信度rd_confidence;其中,ud_frequencej表示所述第二修正词的人工推荐频次;
19.通过公式通过公式计算得到所述第二修正词的混合置信度e_confidence;其中,σ
a1
表示mc_confidence的标准差,表示mc_confidence的平均值,σ
r1
表示ud_frequence的标准差,表示ud_frequence的平均值;
20.对所述修正词库中修正词的混合置信度进行更新。
21.具体来说,还包括:
22.若匹配不成功,用所述指定修正词替换所述目标原词,并将所述指定修正词添加到所述修正词库中,并赋予所述指定修正词的初始自动推荐频次、人工推荐频次、绝对置信度、相对置信度和混合置信度。
23.具体来说,所述对文档di进行分词处理,包括:
24.通过n-gram统计语言模型对所述文档di进行分词处理。
25.本发明还提供了一种基于用户自定义修正词库的文字修正装置,包括:
26.分词模块,用于对文档di进行分词处理,得到集合f;所述集合f=cut(di)={w
i1
,w
i2
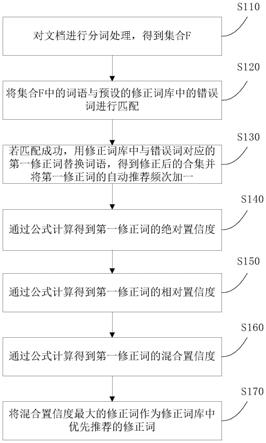
,
……
,w
im
},其中,m表示文档di经过分词处理之后得到的词语wi的个数;
27.第一匹配模块,用于将所述集合f中的词语wi与预设的修正词库中的错误词进行匹配;
28.第一修正模块,用于若匹配成功,用所述修正词库中与所述错误词对应的第一修正词替换词语wi,得到修正后的合集f
′
={w
′
i1
,w
′
i2
,
……
,w
′
im
,},并将所述第一修正词的自动推荐频次m_frequence加一;
29.第一绝对置信度计算模块,用于通过公式计算得到所述第一修正词的绝对置信度a_confidence;其中,δ1表示预设的第一平滑;
30.第一相对置信度计算模块,用于通过公式计算得到所述第一修正词的相对置信度r_confidence;其中,u_frequence表示所述第一修正词的人工推荐频次;
31.第一混合置信度计算模块,用于通过公式第一混合置信度计算模块,用于通过公式计算得到所述第一修正词的混合置信度confidence;其中,σa表示m_confidence的标准差,表示m_confidence的平均值,σr表示u_frequence的标准差,表示u_frequence的平均值;
32.推荐修正词设置模块,用于将混合置信度最大的修正词作为所述修正词库中优先推荐的修正词。
33.具体来说,还包括:
34.修改指令接收模块,用于接收修改指令;所述修改指令包括:修改命令、目标原词及指定修正词;
35.第二匹配模块,用于将所述指定修正词与所述预设的修正词库中的第二修正词进行匹配;
36.第二修正模块,用于若匹配成功,用所述第二修正词替换所述目标原词,并将所述第二修正词的人工推荐频次ud_frequence加一;
37.第二绝对置信度计算模块,用于通过公式计算得到所述第二修正词的绝对置信度ac_confidence;其中,mc_frequencei表示所述第二修正词的自动推荐频次,δ2表示预设的第二平滑;
38.第二相对置信度计算模块,用于通过公式计算得到所述第二修正词的相对置信度rd_confidence;其中,ud_frequencej表示所述第二修正词的人工推荐频次;
39.第二混合置信度计算模块,用于通过公式第二混合置信度计算模块,用于通过公式计算得到所述第二修正词的混合置信度e_confidence;其中,σ
a1
表示mc_confidence的标准差,表示mc_confidence的平均值,σ
r1
表示ud_frequence的标准差,表示ud_frequence的平均值;
40.混合置信度更新模块,用于对所述修正词库中修正词的混合置信度进行更新。
41.具体来说,还包括:
42.第三修正模块,用于若匹配不成功,用所述指定修正词替换所述目标原词,并将所述指定修正词添加到所述修正词库中,并赋予所述指定修正词的初始自动推荐频次、人工推荐频次、绝对置信度、相对置信度和混合置信度。
43.具体来说,所述分词模块,具体用于通过n-gram统计语言模型对所述文档di进行分词处理,得到集合f;所述集合f=cut(di)={w
i1
,w
i2
,
……
,w
im
},其中,m表示文档di经过分词处理之后得到的词语wi的个数。
44.本发明中提供的一个或多个技术方案,至少具有如下技术效果或优点:
45.先对文档进行分词处理,得到集合,并构建了修正词库,该词库记录了用户自定义的常见错误词汇及其修正词汇,将分词结果与修正词库中的错误词汇进行对比。当结果一致时,则确定存在词语错误;建立修正词库纠正模型,该模型针对某一修正词修改支持人工修改与机器推荐两种功能,根据人工修改与机器推荐采纳次数计算该修正词的相对置信度与绝对置信度,通过综合两种置信度计算该修正词的混合置信度。当某一个错误词汇有多个修正词汇时,根据这些修正词汇的混合置信度大小排序推荐修正词。当用户选择机器推荐或者人工纠错时,进行自适应修改,调整修正词的置信度与下一次修正词的推荐策略,从而可以自适应地提供正确率较高的修正方案,进而提高智能推荐的准确性,从而提升用户体验。本发明首先提供了自动的批量修正方法,适用于大批量数据的前期粗粒度处理,可以大大减少人力成本,提高企业平台的工作效率;同时,当人工修正不可避免时,提供了基于高相对置信度的备选修正方案。
附图说明
46.图1为本发明实施例提供的基于用户自定义修正词库的文字修正方法的流程图;
47.图2为具体实施例的原理图;
48.图3为具体实施例中dict的组成结构图;
49.图4为具体实施例中词库纠正模型的伪代码;
50.图5为具体实施例中用户审核修改更新dictionary的伪代码;
51.图6为本发明实施例提供的基于用户自定义修正词库的文字修正装置的模块图。
具体实施方式
52.本发明实施例通过提供一种基于用户自定义修正词库的文字修正方法及装置,能够提高ocr识别技术准确性。
53.本发明实施例中的技术方案为实现上述技术效果,总体思路如下:
54.先对文档进行分词处理,得到集合,并构建了修正词库,该词库记录了用户自定义的常见错误词汇及其修正词汇,将分词结果与修正词库中的错误词汇进行对比。当结果一致时,则确定存在词语错误;建立修正词库纠正模型,该模型针对某一修正词修改支持人工修改与机器推荐两种功能,根据人工修改与机器推荐采纳次数计算该修正词的相对置信度与绝对置信度,通过综合两种置信度计算该修正词的混合置信度。当某一个错误词汇有多个修正词汇时,根据这些修正词汇的混合置信度大小排序推荐修正词。当用户选择机器推荐或者人工纠错时,进行自适应修改,调整修正词的置信度与下一次修正词的推荐策略,从而可以自适应地提供正确率较高的修正方案,进而提高智能推荐的准确性,从而提升用户体验。本发明实施例首先提供了自动的批量修正方法,适用于大批量数据的前期粗粒度处理,可以大大减少人力成本,提高企业平台的工作效率;同时,当人工修正不可避免时,提供了基于高相对置信度的备选修正方案。此外,还可以收集用户的修正结果,对修正词库进行动态更新,优化修正词库,进一步提高了文字识别的效率和准确性。
55.为了更好地理解上述技术方案,下面将结合说明书附图以及具体的实施方式对上述技术方案进行详细的说明。
56.参见图1,本发明实施例提供的基于用户自定义修正词库的文字修正方法,包括:
57.步骤s110:对文档di进行分词处理,得到集合f;集合f=cut(di)={w
i1
,w
i2
,
……
,w
im
},其中,m表示文档di经过分词处理之后得到的词语wi的个数;
58.具体地,对文档di进行分词处理,包括:
59.通过n-gram统计语言模型对文档di进行分词处理。
60.步骤s120:将集合f中的词语wi与预设的修正词库中的错误词进行匹配;
61.步骤s130:若匹配成功,用修正词库中与错误词对应的第一修正词替换词语wi,得到修正后的合集f
′
={w
′
i1
,w
′
i2
,
……
,w
′
im
,},并将第一修正词的自动推荐频次m_frequence加一;
62.步骤s140:通过公式计算得到第一修正词的绝对置信度a_confidence;其中,δ1表示预设的第一平滑;
63.步骤s150:通过公式计算得到第一修正词的相对置信度r_confidence;其中,u_frequence表示第一修正词的人工推荐频次;
64.步骤s160:通过公式步骤s160:通过公式计算得到第一修正词的混合置信度confidence;其中,σa表示m_confidence的标准差,表示m_confidence的平均值,σr表示u_frequence的标准差,表示u_frequence的平均值;
65.步骤s170:将混合置信度最大的修正词作为修正词库中优先推荐的修正词。
66.如果自动推荐的修正词不合适,本发明实施例还提供了人工修正的方式,并还对修正词库进行更新。具体地,本发明实施例还包括:
67.接收修改指令;修改指令包括:修改命令、目标原词及指定修正词;
68.将指定修正词与预设的修正词库中的第二修正词进行匹配;
69.若匹配成功,用第二修正词替换目标原词,并将第二修正词的人工推荐频次ud_frequence加一;
70.通过公式计算得到第二修正词的绝对置信度ac_confidence;其中,mc_frequencei表示第二修正词的自动推荐频次,δ2表示预设的第二平滑;
71.通过公式计算得到第二修正词的相对置信度rd_confidence;其中,ud_frequencej表示第二修正词的人工推荐频次;
72.通过公式
计算得到第二修正词的混合置信度e_confidence;其中,σ
a1
表示mc_confidence的标准差,表示mc_confidence的平均值,σ
r1
表示ud_frequence的标准差,表示ud_frequence的平均值;
73.对修正词库中修正词的混合置信度进行更新。
74.如果修正词库中没有合适的修正词,为了将指定修正词添加到修正词库中,从而对修正词库进行进一步更新,还包括:
75.若匹配不成功,用指定修正词替换目标原词,并将指定修正词添加到修正词库中,并赋予指定修正词的初始自动推荐频次、人工推荐频次、绝对置信度、相对置信度和混合置信度。
76.具体实施例
77.步骤一:参见图2,针对图片、表格、档案、发票等纸质文件内容a,经过ocr文字识别得到文档集合d,其中d={d1,d2,
……
,dn},n表示待识别的纸质文件内容的个数,如公式(1)所示:
78.ocr(a)=d={d1,d2,
……
,dn}
ꢀꢀꢀ
(1)
79.步骤二:针对文档集合d中的每一个文档,对其进行中文分词(cut)处理,即将文档di处理成由多个词语组成的集合,如公式(2)所示:
80.cut(di)={w
i1
,w
i2
,
……
,w
im
}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
81.其中,m表示文档di经过分词处理之后所得词语的个数。
82.对于中文分词cut处理,本发明实施例采用n-gram统计语言模型,结合上下文,相邻词间的相关信息,选择具有最大出现概率的词语组合,实现自动分词。基于n-gram模型的中文分词方法延用了n-gram模型的markov假设。记di=c1c2c3……cj
为待分词的文档字符串,cj为字符,li={w
i1
,w
i2
,
……
,w
im
}为di的一种分词结果。如果第k个词w
ik
(1≤k≤m)的出现仅依赖于它前面的k-1个词,则根据k-1阶markov假设,w
ik
的概率计算公式(3)所示:
[0083][0084]
其中,k0=max(k-j,0),包含m个词的序列l={w
i1
,w
i2
,
……
,w
im
}的概率如公式(4)所示:
[0085][0086]
由式(4)可知,某句子出现的概率与各个词出现的概率乘积相等,参数数目与k值呈指数关系。为了保证算法的计算效率,本发明实施例选择k=2,即一个词的出现概率仅依赖其前面出现的1个词,则有m个词的序列l={w
i1
,w
i2
,
……
,w
im
}的概率如公式(5)所示:
[0087]
[0088]
步骤三:根据公式(5)计算的概率值,选取对文档di的分词结果中概率最大出现概率的词语组合l={w
i1
,w
i2
,
……
,w
im
}。为了纠正对该词语组合中所包含的错别字,首先需要建立用户自定义的修正词库dictionary,为了更好地契合该模型,词库以json格式构建,对于每一个词语构建一个可查询与修改的词典dict。dict的组成结构如图3所示。在图3中,word表示包含错别字的词语,fix_word表示修正词汇,词典dict中保存了多个修改方案。m_frequence表示模型自动推荐修正词汇修改的频次,当错误词word采用模型自动推荐的fix_word修正时,则该fix_word的m_frequence频次加1;u_frequence表示用户人工选择修正词汇修改的频次,当用户认为模型针对错误词word推荐的fix_word是错误的时,用户会自己选择他认为正确的修正词fix_word,则该正确的修正词fix_word的u_frequence频次加1。我们用r_confidence表示使用修正词fix_word的相对置信度,a_confidence表示使用修正词fix_word的绝对置信度,cofidence表示混合置信度。r_confidence和a_confidence的计算方式如公式(6)和(7)所示,其中,表示所有m_frequence的加和,表示所有u_frequence的加和,δ表示平滑,本发明实施例中取值0.001,以防止分母为0。confidence的计算方式如公式(12)所示,其中,和σa分别表示m_confidence的平均值和标准差,分别由公式(8)与公式(10)计算而来,其中count(m_frequence)为m_frequence的计数;和σr分别表示u_frequence的平均值和标准差,分别由公式(9)与公式(11)计算而来,count(u_frequence)为u_frequence的计数。
[0089][0090][0091][0092][0093][0094][0095][0096]
同时,为了解决修正词库的冷启动问题,在构建该修正词库时,前期需要有大量错误词汇、修正词的预料积累。可以结合人工标注的方式建立初始修正词库。
[0097]
步骤四:为实现修正词库纠错模型的自动修改功能,该模型会对文档di实现自动修改得到s={w
′
i1
,w
′
i2
,......,w
′
im
,},对于文档di的分词结果{w
i1
,w
i2
,......,w
im
}中的
每一个词语w
ik
,会在dictionary中查找对应word。如果未查找到,则说明w
ik
词语为正确识别词语;如果查找到,则说明w
ik
词语为错误词语,并在dictionary中查找对应的dict,将混合置信度confidence最高的修正词语作为模型的修改方案,同时dict中对应的m_frequence加1,并且按照公式(12)更新对应的confidence,整个流程的伪代码如图4所示。
[0098]
步骤五:如果用户认为词语w
′
ij
(1<<j<<m)没有错误,则不做任何操作。如果用户认为词语w
′
ij
(1<<j<<m)存在错误,本发明实施例会在dictionary中查找w
′
ij
对应的dict。如果能找到对应的dict,会根据对应dict除w
′
ij
之外中confidence最高的2个词语作为推荐,用户可以根据推荐对w
′
ij
进行一键修改得到w
″
ij
,同时会对dict中相应词语的u_frequence值加1,根据公式(12)更新confidence;如果不能找到对应的dict,用户手动将w
′
ij
修改为w
″
ij
,并在dictionary中创建新的dict={w
′
ij
:[[w
″
ij
],[0],[1],[1]},整个流程的伪代码如图5所示。
[0099]
参见图6,本发明实施例提供的基于用户自定义修正词库的文字修正装置,包括:
[0100]
分词模块100,用于对文档di进行分词处理,得到集合f;集合f=cut(di)={w
i1
,w
i2
,......,w
im
},其中,m表示文档di经过分词处理之后得到的词语wi的个数;
[0101]
具体地,分词模块100,具体用于通过n-gram统计语言模型对文档di进行分词处理,得到集合f;集合f=cut(di)={w
i1
,w
i2
,......,w
im
},其中,m表示文档dj经过分词处理之后得到的词语wj的个数。
[0102]
第一匹配模块200,用于将集合f中的词语wi与预设的修正词库中的错误词进行匹配;
[0103]
第一修正模块300,用于若匹配成功,用修正词库中与错误词对应的第一修正词替换词语wi,得到修正后的合集f
′
={w
′
i1
,w
′
i2
,
……
,w
′
im
,},并将第一修正词的自动推荐频次m_frequence加一;
[0104]
第一绝对置信度计算模块400,用于通过公式计算得到第一修正词的绝对置信度a_confidence;其中,δ1表示预设的第一平滑;
[0105]
第一相对置信度计算模块500,用于通过公式计算得到第一修正词的相对置信度r_confidence;其中,u_frequence表示第一修正词的人工推荐频次;
[0106]
第一混合置信度计算模块600,用于通过公式第一混合置信度计算模块600,用于通过公式计算得到第一修正词的混合置信度confidence;其中,σa表示m_confidence的标准差,表示m_confidence的平均值,σr表示u_frequence的标准差,表示u_frequence的平均值;
[0107]
推荐修正词设置模块700,用于将混合置信度最大的修正词作为修正词库中优先推荐的修正词。
[0108]
如果自动推荐的修正词不合适,本发明实施例还提供了人工修正的方式,并还对
修正词库进行更新。具体地,还包括:
[0109]
修改指令接收模块,用于接收修改指令;修改指令包括:修改命令、目标原词及指定修正词;
[0110]
第二匹配模块,用于将指定修正词与预设的修正词库中的第二修正词进行匹配;
[0111]
第二修正模块,用于若匹配成功,用第二修正词替换目标原词,并将第二修正词的人工推荐频次ud_frequence加一;
[0112]
第二绝对置信度计算模块,用于通过公式计算得到第二修正词的绝对置信度ac_confidence;其中,mc_frequencei表示第二修正词的自动推荐频次,δ2表示预设的第二平滑;
[0113]
第二相对置信度计算模块,用于通过公式计算得到第二修正词的相对置信度rd_confidence;其中,ud_frequencej表示第二修正词的人工推荐频次;
[0114]
第二混合置信度计算模块,用于通过公式第二混合置信度计算模块,用于通过公式计算得到第二修正词的混合置信度e_confidence;其中,σ
a1
表示mc_confidence的标准差,表示mc_confidence的平均值,σ
r1
表示ud_frequence的标准差,表示ud_frequence的平均值;
[0115]
混合置信度更新模块,用于对修正词库中修正词的混合置信度进行更新。
[0116]
如果修正词库中没有合适的修正词,为了将指定修正词添加到修正词库中,从而对修正词库进行进一步更新,还包括:
[0117]
第三修正模块,用于若匹配不成功,用指定修正词替换目标原词,并将指定修正词添加到修正词库中,并赋予指定修正词的初始自动推荐频次、人工推荐频次、绝对置信度、相对置信度和混合置信度。
[0118]
技术效果
[0119]
先对文档进行分词处理,得到集合,并构建了修正词库,该词库记录了用户自定义的常见错误词汇及其修正词汇,将分词结果与修正词库中的错误词汇进行对比。当结果一致时,则确定存在词语错误;建立修正词库纠正模型,该模型针对某一修正词修改支持人工修改与机器推荐两种功能,根据人工修改与机器推荐采纳次数计算该修正词的相对置信度与绝对置信度,通过综合两种置信度计算该修正词的混合置信度。当某一个错误词汇有多个修正词汇时,根据这些修正词汇的混合置信度大小排序推荐修正词。当用户选择机器推荐或者人工纠错时,进行自适应修改,调整修正词的置信度与下一次修正词的推荐策略,从而可以自适应地提供正确率较高的修正方案,进而提高智能推荐的准确性,从而提升用户体验。本发明实施例首先提供了自动的批量修正方法,适用于大批量数据的前期粗粒度处理,可以大大减少人力成本,提高企业平台的工作效率;同时,当人工修正不可避免时,提供了基于高相对置信度的备选修正方案。此外,还可以收集用户的修正结果,对修正词库进行
动态更新,优化修正词库,进一步提高了文字识别的效率和准确性。
[0120]
本发明实施例在用户自定义建立修正词库的基础上,提出了基于用户修正行为的自适应词库更新方法,构建的错词备选推荐词库可以成为企业的数据资产,为企业本身提供了ocr识别数据库支撑。同时,当不同应用领域(表格、档案、发票等纸质文件)的错词推荐词库迭代比较完备时,就可以产生巨大的数据库效益,为企业带来额外的经济收益。
[0121]
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0122]
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0123]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0124]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0125]
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
[0126]
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1