一种渐进式高精度人体脚型重建方法
1.本发明属于计算机与三维脚型重建相结合领域,尤其涉及一种渐进式高精度人体脚型重建方法。
背景技术:
2.随着科技的进步和生活水平的提高,借助科技的力量定制自己的专属产品,逐渐成为用户的热门需求,个性化制鞋产业也因此蓬勃发展。在该产业中,从业人员通过采集用户的脚型三维模型和脚型测量参数,再根据脚型三维模型和脚型测量参数调整鞋楦尺寸,设计出与用户脚型相符合的定制鞋类款式。这种个性化制鞋方法通常对从业人员有着较高的专业知识要求,并且需要昂贵的三维扫描仪设备来获取脚型模型。因此整个制鞋流程效率低,且费用较高,难以推广。
3.三维物体重建是计算机视觉领域的热点研究问题。三维物体重建指的是从一张或者多张图像重建出图像中物体的完整三维模型。该技术在人机交互、自动驾驶、游戏设计等多个场景都有广泛的应用前景。传统的三维物体重建技术主要通过在多张标定好的图像中寻找特征点的对应关系,使用多视角立体几何(multi-view stereo)恢复物体的三维信息。这种方法对场景的光照、物体的纹理等有严格的要求,难以进一步推广到实际应用场景中。并且由于物体的遮挡等原因,这种方法通常无法重建出完整的三维物体形状。
4.深度学习技术在最近的几年里迅速发展,并在一系列计算机视觉相关的任务中取得了显著的进展。在基于深度学习的三维物体重建方法中,按照图像类型可分为两类:一类是基于rgb图像的三维物体重建,这类方法以rgb图像作为输入,并通过深度卷积神经网络提取图像特征并重建物体的三维形状;另一类是基于深度图像的三维物体重建,这类方法以深度图像作为输入,将其表示为体素模型或三维点云,使用深度卷积神经网络从中提取特征并重建三维物体形状。
5.可视外壳(visual hull)是对多张图像的投影视锥求交生成的一种三维形体。该形体可以看作是图像中物体的粗糙三维模型,同时融合了图像以及对应的相机内外参信息。以可视外壳作为输入,在其基础上进行三维物体重建,能更好地融合多张图像包含的物体信息,重建出更高精度的三维物体形状。
技术实现要素:
6.本发明的目的在于针对现有技术无法重建高精度人体脚型的不足,提供一种针对特定类别物体(即人体脚型)的三维重建方法。具体地,本发明提供一种渐进式高精度人体脚型重建方法,根据图像和对应的相机参数,构造可视外壳作为人体脚型的粗糙三维形状。针对人体脚型可视外壳和人体脚型网格形状,基于深度学习,建立脚型可视外壳特征学习模型、脚型网格特征学习模型、特征转换模型。以图像和相机参数作为输入,构建可视外壳,提取可视外壳特征,转换为网格特征,重建脚型三维形状。本发明简化了传统脚型重建方法的复杂流程,降低了数据采集过程中对场景光照、物体纹理的要求,使用渐进式人体脚型重
建方法能够快速准确地重建出高精度的三维脚型形状。
7.本发明的目的是通过以下技术方案来实现的:一种渐进式高精度人体脚型重建方法,包括如下步骤:
8.(1)构建粗糙脚型形状。在公开的人体脚型三维模型数据集上,指定相机内参,使用随机的相机外参生成不同相机视角下的脚部轮廓图。使用三张脚部轮廓图以及图像对应的相机内外参,通过反投影的方式计算每张图像在世界坐标系下的视锥空间。对所有图像的视锥空间进行求交,得到脚型的可视外壳,并将其进行体素化,表示为三维体素模型。该三维体素模型表示的可视外壳即为粗糙脚型形状。在得到可视外壳后,对可视外壳的包围盒中心点进行坐标对齐等后处理。
9.(2)建立人体脚型可视外壳特征学习模型。人体脚型可视外壳特征学习模型为自编码器(auto encoder)结构,以步骤(1)构建的人体脚型可视外壳作为输入,提取脚型可视外壳特征并重建脚型可视外壳。自编码器由编码器(encoder)和解码器(decoder)两部分构成。编码器从三维体素模型表示的脚型可视外壳中提取特征。解码器对脚型可视外壳特征进行解码,重建出脚型可视外壳。人体脚型可视外壳特征学习模型通过自监督学习(self-supervised learning)的方法进行模型训练,计算输入的可视外壳与输出的可视外壳两者之间的损失函数,优化模型参数。
10.(3)建立人体脚型网格特征学习模型。人体脚型网格特征学习模型为自编码器(auto encoder)结构,以人体脚型三维网格作为输入,提取脚型网格特征并重建脚型网格模型。自编码器由编码器和解码器两部分组成。编码器从脚型网格中提取特征。解码器从脚型网格特征提取脚型网格模型的pca形状参数,并通过反主成分分析(inverse pca)方法由形状参数重建脚型三维网格。人体脚型网格特征学习模型通过自监督学习的方法进行模型训练,计算输入的脚型三维网格与输出的脚型三维网格两者之间的损失函数,优化模型参数。
11.(4)建立人体脚型可视外壳特征和网格特征之间的特征转换模型。特征转换模型为多层感知机结构(multi layer perception)。特征转换模型将脚型可视外壳特征学习模型和脚型网格特征学习模型进行连接,以脚型可视外壳特征学习模型提取到的可视外壳特征作为输入,将其转换为脚型网格特征,并使用脚型网格特征学习模型的解码器重建脚型三维网格。特征转换模型通过监督学习(supervised learning)的方法进行模型训练,计算重建的脚型三维网格与真实的脚型三维网格之间的损失函数,优化模型参数。
12.(5)在进行高精度体脚型重建时,使用脚型可视外壳特征学习模型的编码器、脚型网格特征学习模型的解码器和特征转换模型进行脚型重建。以三张脚部轮廓图和对应的相机内外参作为输入,首先构造可视外壳作为粗糙脚型,再通过可视外壳特征学习模型的编码器网络提取脚型的可视外壳特征,随后使用特征转换模型将可视外壳特征转换为脚型的三维网格特征,最后利用脚型网格特征学习模型的解码器网络进行高精度三维脚型重建,输出高精度的三维脚型形状。
13.进一步的,所述步骤(1)中,相机外参在脚部前方、左侧、右侧三个方向分别随机生成,保证生成的脚型轮廓图在三个方向上分布均匀。在对脚型可视外壳进行体素化时,依据脚型长宽高的2:1:1比例关系,对世界坐标系下原点周围的320mm*160mm*160mm的三维空间进行离散化,将可视外壳表示为256*128*128的三维体素模型,其中每个体素尺寸为
1.25mm。
14.进一步的,所述步骤(2)中,人体脚型可视外壳特征学习模型为自编码器结构,由编码器和解码器两部分组成。编码器使用3d卷积网络和全连接网络从脚型可视外壳提取特征。解码器使用全连接网络和3d反卷积网络对编码器提取的特征进行解码,重建脚型可视外壳形状。模型训练时的损失函数为输入脚型可视外壳与重建脚型可视外壳逐体素的二元交叉熵损失(binary cross-entropy)。
15.进一步的,所述步骤(3)中,人体脚型网格特征学习模型为自编码器结构,由编码器和解码器两部分组成。编码器使用图卷积网络从脚型三维网格提取特征。解码器使用全连接网络从脚型网格特征预测脚型的pca形状参数,通过反pca的方法由pca形状参数重建脚型三维网格。模型训练时的损失函数为输入脚型三维网格与重建脚型三维网格逐顶点的l2距离。脚型网格模型的pca形状参数和每个参数对应的正交向量由公开的人体脚型三维模型数据集通过pca分解得到。
16.进一步的,所述步骤(4)中,脚型可视外壳特征和脚型网格特征之间的特征转换模型为多层感知机结构,并使用瓶颈层(bottleneck layer)进行特征降维,减轻模型的过拟合问题。模型训练时的损失函数为重建脚型三维网格与真实脚型三维网格逐顶点的l2距离。特征转换模型与人体脚型可视外壳特征学习模型和人体脚型网格特征学习模型一起进行联合训练。
17.本发明的有益效果:使用渐进式高精度人体脚型重建方法可以通过相机/手机等移动设备采集脚部照片,进行高精度脚型重建,减少了传统脚型重建方法的复杂流程,降低了数据采集过程中对场景光照、物体纹理的要求,能够快速准确地重建出高精度的三维脚型形状。
附图说明
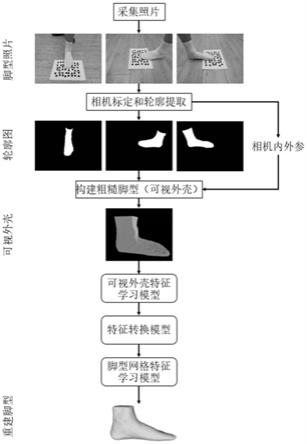
18.图1为本发明方法具体实施方式的流程图示例;
19.图2为本发明的网络模型的详细网络结构图示例。
具体实施方式
20.本发明的具体实施方式如图1所示。本发明提供的渐进式高精度人体脚型重建方法,具体实施步骤如下:
21.(1)首先采集多张不同角度的棋盘格照片,并基于这些照片对相机进行内参标定,获取相机的焦距、光心、畸变等内参参数。然后结合外定标参照物(a4纸、棋盘格标定纸、散乱点标定纸等),采集三张用户脚部不同方位(前方、左侧、右侧)的照片,并根据外定标参照物计算每张照片的相机外参。最后人工处理采集到的脚型照片,提取出脚部区域的轮廓图。
22.(2)以三张脚部区域轮廓图和每张图像对应的相机内外参作为输入,构建脚型的可视外壳,将其表示为三维体素模型,作为人体脚型的粗糙模型。计算可视外壳的包围盒,并根据包围盒中心位置,对可视外壳进行中心对齐后处理。
23.(3)以处理之后的可视外壳作为输入,通过人体脚型可视外壳特征学习模型提取脚型可视外壳的特征,使用特征转换模型将可视外壳特征转换为脚型网格特征,最后由人体脚型网格特征学习模型从脚型网格特征预测脚型pca形状参数,并通过反pca方法重建人
体脚型三维网格模型。
24.其中,针对步骤(3)中可视外壳特征学习模型的建立过程,其具体建立方法如下:
25.可视外壳特征学习模型基于自编码器结构,由编码器e
vh
和解码器d
vh
两部分组成。可视外壳特征学习模型使用编码器学习可视外壳特征,并使用解码器从学习到的可视外壳特征重建脚型可视外壳,通过自监督学习的方式进行模型训练,更好地获取人体脚型可视外壳特征。
26.编码器e
vh
以人体脚型可视外壳的三维体素模型x
vh
作为输入。编码器e
vh
由6层3d卷积层和1层全连接层组成。每层3d卷积层后紧跟最大池化层和leaky relu非线性激活单元。全连接层后紧跟leaky relu非线性激活单元,用来提取脚型可视外壳特征y
vh
。
27.解码器d
vh
以脚型可视外壳特征y
vh
作为输入。解码器d
vh
由1层全连接层和6层3d反卷积层组成。除最后一层3d反卷积层外,其余所有层后均紧跟relu非线性激活单元,最后一层3d反卷积层后紧跟sigmoid激活单元,输出重建的可视外壳每个体素的概率值,并通过阈值函数输出重建的可视外壳体素模型
28.脚型可视外壳特征学习模型的损失函数l
vh
的计算公式为:
[0029][0030]
其中n为脚型可视外壳的体素数量,和分别是输入可视外壳和重建可视外壳的第i个体素。
[0031]
其中,针对步骤(3)中脚型网格特征学习模型的建立过程,其具体建立方法如下:
[0032]
脚型网格特征学习模型基于自编码器结构,由编码器e
mesh
和解码器d
mesh
两部分组成。脚型网格特征学习模型使用编码器学习人体脚型网格特征,并使用解码器由学习到的网格特征重建脚型的三维网格模型,通过自监督学习的方式进行模型训练,更好地获取人体脚型网格特征。
[0033]
编码器e
mesh
以人体脚型三维网格模型x
mesh
作为输入。编码器e
mesh
由4层图卷积层组成。每层图卷积层后紧跟1eaky relu非线性激活单元。最后使用最大池化层对所有顶点的特征进行融合,用来提取脚型网格特征y
mesh
。
[0034]
解码器d
mesh
以脚型网格特征y
mesh
作为输入。解码器d
mesh
由5层全连接层。除最后一层全连接层外,其余所有层后均紧跟relu非线性激活单元,最后一层全连接层直接输出预测的脚型pca形状参数,并通过反pca方法输出重建的脚型三维网格模型
[0035]
脚型网格特征学习模型的损失函数l
mesh
的计算公式为:
[0036][0037]
其中m为脚型三维网格模型的顶点数量,和分别是输入脚型三维网格和重建脚型三维网格的第i个顶点。
[0038]
其中,针对步骤(3)中的特征转换模型的建立过程,其具体建立方法如下:
[0039]
脚型特征转换模型t
vh2mesh
基于多层感知机结构,以脚型可视外壳特征y
vh
作为输
入,由2层全连接层组成,每层全连接层后紧跟leaky relu非线性激活单元,输出脚型网格特征y
mesh
。第一层全连接层作为瓶颈层,其通道数为输入/输出特征通道数的一半,用来减轻模型的过拟合问题。输出的脚型网格特征再由脚型网格特征学习模型的解码器d
mesh
来重建脚型网格模型x
′
mesh
,用于与真实脚型网格模型x
mesh
计算损失,训练特征转换模型。
[0040]
特征转换模型的损失函数l
vh2mesh
的计算公式为:
[0041][0042]
其中m为脚型三维网格模型的顶点数量,和分别是真实脚型三维网格和重建脚型三维网格的第i个顶点。
[0043]
实施例
[0044]
(1)首先对相机进行内定标,并使用内定标后的相机采集人体脚型三个视角(前方、左侧、右侧)的带外定标参照物的照片。采集照片时,在地面上放置一张包含固定数量的散乱点的a4纸,作为外定标参照物,用户脚踩在a4纸长边的中心位置并在照片采集期间保持不动。采集照片时需保证整个脚部区域和a4纸都出现在照片内。在完成照片采集后,对照片中脚部区域提取轮廓图,同时计算每张照片对应的相机外参。
[0045]
(2)使用三张脚部轮廓图和对应的相机内外参,计算脚型可视外壳,并将其表示为三维体素模型。对得到的脚型可视外壳,根据其包围盒进行中心对齐后处理。
[0046]
(3)将处理后的脚型可视外壳作为输入,利用可视外壳特征学习模型的编码器提取脚型可视外壳特征,由特征转换模型将可视外壳特征转换为脚型网格特征,使用脚型网格特征学习模型的解码器重建脚型三维网格模型,作为输出。
[0047]
上述实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改和改变,都落入本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1