一种针对拥挤人群的精确人体解析方法
1.本发明涉及一种针对拥挤人群的精确人体解析方法,属于计算机视觉及图像应用领域。
背景技术:
2.人体解析是一种细粒度的语义分割任务,旨在识别像素级人体图像的组成部分,如身体部位和衣物,它是多媒体和计算机视觉中的一项基本任务,对于各种不同视觉场景下的问题具有很好的潜力,如行为分析,视频图像理解,智能安防等。公知的方法考虑到存在不同大小的语义特征,使用例如fcn结构,deeplabv1结构,deeplabv3结构,segnet结构,aspp结构,旨在通过提取多尺度的语义特征以提升人体解析。然而仅仅考虑多尺度信息不能很好的考虑像素之间深层关系,对于拥挤场景中人实例间的复杂交互关系不能很好的建模。就技术而言,拥挤人群的人体解析仍有一些关键问题未得到较好解决,主要体现在三个方面:1)背景复杂,背景颜色和人的衣服过于相似;2)人实例数量变化大,其动作姿态多样,复杂的运动环境中的人存在很强的交互,难以确定特征归属问题;3)拥挤环境中存在复杂的遮挡,这其中包括人体的自遮挡、人和物的遮挡以及人体实例间的相互遮挡。这些遮挡对于人体解析的精度影响很大。以上三个方面是拥挤人群中人体解析亟待解决的关键。
3.公知的人体解析方法主要有基于特征增强,基于多任务方法等。例如,zhang x(《neurocomputing》402,2020,375-383)提出一种用于人体解析的语义空间融合网络(ssfnet),以缩小语义间隙,通过聚合多分辨率特征来赋予准确的高分辨率预测。zhang z(《ieee/cvf conference on computer vision and pattern recognition》,2020,8897-8906)提出了一种相关解析器(corrpm),以利用人体语义边缘和姿势特征两者的优势来促进人体解析。然而,这些公知方法虽然利用多尺度语义以及其他任务对人体解析进行了补充,在单人解析上取得了很好的效果,同时也可以结合目标检测算法拓展到多人情况。但是其过度依赖于目标检测方法的精度,未考虑到不同人实例间的关系,很难在人群拥挤的情况下产生很好的效果。专利cn113111848a通过在编码器和和解码器之间每一层特征中添加空洞卷积做多尺度特征融合以加强模型的特征提取能力,解决传统人体解析方法对于人体边缘检测像素精度不够的问题。该方法只是简单的堆叠空洞卷积结构,存在大量的冗余计算,仅仅解决边缘精度并不能很好的适用人体解析任务,本发明则仅在最后一层特征中添加空洞卷积层,并在编解码器中间添加超像素特征表征图像的内部结构,在获得精确边缘的同时可以获得初步的人体结构。专利cn113537072a通过共享主干提取的多尺度特征,非局部化处理后采用联合学习的方式,分别进行姿态估计和人体解析任务。虽然其考虑到了姿态和解析任务的相同点,但是忽略了两个任务之间的差异性,并且该方法仅适用与单人解析情况。
技术实现要素:
4.本发明提供了一种针对拥挤人群的精确人体解析方法,以用于有效地解析拥挤人
群图像,得到精确的人体解析结果,从而满足目前的对拥挤人群解析的精度要求。
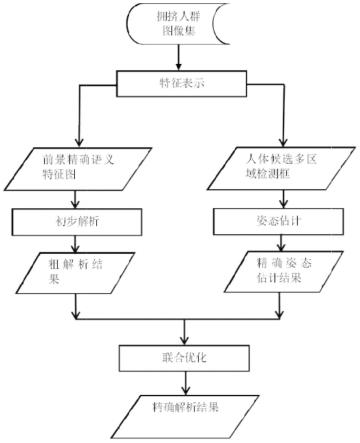
5.本发明的技术方案是:一种针对拥挤人群的精确人体解析方法,首先输入拥挤人群图像集,通过深度残差网络提取粗图像分层特征和超像素特征,对人体图像进行特征表示,得到前景精确语义特征图,并生成人体候选多区域检测框;其次,将前景精确语义特征图上采样到相同大小,并融合在一起生成高分辨率特征,通过初步解析得到人体粗解析结果;然后对候选多区域检测框中的前景精确语义特征进行人体姿态估计,生成人体关节点,细化得到多人精确姿态估计结果;最后,通过计算语义距离损失,将得到的人体粗解析结果和多人精确姿态估计结果进行联合优化,输出最终的精确人体解析结果。
6.所述方法的具体步骤如下:
7.step1、输入拥挤人群图像集中g={g1,g2,...gn},通过深度残差网络提取粗图像分层特征和超像素特征,对人体图像进行特征表示,得到前景精确语义特征图,并生成人体候选多区域检测框;
8.step2、通过双线性插值法将不同尺度的前景精确语义特征图上采样到相同大小,并融合在一起生成高分辨率特征,通过初步解析得到人体粗解析结果。
9.step3、对候选多区域检测框中的前景精确语义特征进行人体姿态估计,定义关节损失函数抑制干涉关节,生成人体关节点,并定义人体姿态关联规则,对生成的所有关节点进行关联连接,细化后得到多人精确姿态估计结果;
10.step4、通过计算语义距离损失,将得到的人体粗解析结果和多人精确姿态估计结果进行联合优化,输出最终的精确人体解析结果。
11.所述step1具体如下:
12.首先,对输入拥挤人群图像集g利用resnet101提取其分层特征p={p1,p2,p3,p4,p5},并使用cob卷积导向边界生成超像素分区系列s={s0,s1,...,sn},其中sn是表示整个图像的超像素,sn中的超像素是s
n-1
中的两个超像素组合。匹配p2,p4,p5的大小选取s中的子集n={n2,n4,n5},其中相邻层次间节点数量是1/4倍。
13.然后,对p2,p4,p5进行特征映射以映射到图矩阵,其中w是完全连接层的可读权重矩阵,||是指串联操作,δ
min
(p
le
)和δ
max
(p
le
)分别代表最小池化和最大池化,p
le
表示联合对应层次超像素分块的网格单元。
14.之后,通过图神经网络提取映射特征的上下文和分层信息,联合特征金字塔解码特征进行融合,为减少冗余计算在图神经网络中添加空间及通道注意力,得到最终的特征表示结果。给定映射节点i及一组相邻节点ci,节点i的空间注意力表示为:其中,m是自我注意头,是节点i邻居节点收集的特征向量集之和。通道注意力表示为道注意力表示为表示节点i及其邻居的特征向量的平均,σ表示sigmod激活的全连接层,与执行元素乘法。注意力最终可表示为其中β是初始化为0的刻度权重。
15.最后,基于特征表示结果,得到前景精确语义特征ff={p'u|1≤u≤5}。并将特征表示结果输入分层级联rpn中得到候选区域,并通过分类和回归预测生成人体候选多区域检测框d={dv},v表示图中的人数。
16.所述step3具体如下:
17.首先对step1中d的所有检测到的人体候选多区域检测框进行仿射变换。
18.然后,将变换后的每个人体分别输入到单人姿态估计模块中,生成关节热图并定义两种关节类型,分别为目标关节和干涉关节其中定义损失以抑制干涉关节,其中rsme是均方根误差函数,k表示第v个人的第k个关节,k为关节总数。
19.之后定义人体姿态关联规则,对生成的所有关节点进行关联连接,生成骨架标注图a={a
l
},l表示生成的连接数。并定义姿态相似性函数f(a
x
,ay,η)=1[d(a
x
,ay|λ,λ)≤η]以消除相似姿态,其中d(
·
)为定义的姿态距离函数,λ,λ为参数集合,η为距离阈值。如果d(
·
)≤η则判定a
x
为冗余,进行消除。d(
·
)具体为d(a
x
,ay|λ)=q(a
x
,ay|η1)+μh(a
x
,ay|η2),其中函数q计算姿势骨架之间匹配关节点的置信度,得出姿态之间匹配的关节数量。函数h计算关节间的空间距离,η1,η2是函数中可调参数,μ是平衡两个距离的权重,λ={η1,η2,μ}。
[0020]
最后通过反仿射变换将恢复原图像坐标,细化生成精确姿态估计结果f
pose
。
[0021]
所述step4具体过程如下:
[0022]
首先将精确姿态估计结果f
pose
与通过step2得到的粗解析结果f
parsing
进行级联,通过人体多区域候选框和姿态约束将不同人体实例的标签进行分割。
[0023]
然后通过定义语义空间距离损失,l
f_parsing
=λ1l
parsing
+l
parsing
l
pose
+λ2l
pose
以减少不同语义之间的差距。其中λ1是解析损失权重,λ2是姿态损失权重,表示粗解析损失,表示姿态估计损失,a表示图像中像素点的总个数;m表示标签类别数;1表示第一类交叉熵损失;yi表示的是第i个像素点的类别;ln(fm)表示预测为第m类语义的概率;n是关节点总数;分别表示第n个关节在图像中的像素坐标和真实坐标。
[0024]
最后通过卷积将级联后的结果映射为n
×
c大小,将解析结果映射到c
×
n大小,融合后输入到3个7
×
7维度为128的卷积层中进行细化,得到最终的精确解析结果。
[0025]
本发明的有益效果是:
[0026]
1、公知的方法在多尺度特征学习中仅采用具有固定拓扑的神经网络在空间和尺度上执行特征交互,忽略了图像的内在结构,导致在传播和交互过程中丢失或减弱基本特征信息。本发明通过将超像素映射到图节点来继承图像内在的层次结构,并融合不同层次和特征提取主干中层子集,不仅能获得增强的多尺度特征,还可以更好融入图像的内在结构,为后续目标检测和分割任务提供更细粒度的特征表示,提高后续人体解析的精度。
[0027]
2、由于拥挤场景下的图像存在背景、姿态复杂,人实例数量变化大,以及相互遮挡等问题。而公知的人体解析方法大多仅考虑多尺度中的像素精度来提升人体解析精度,造成在拥挤场景下模型的退化严重,且未考虑复杂姿态和遮挡环境,很难获得较高的精度。本发明提出自上而下的多人姿态估计,通过精确的目标检测分割不同人体,此外,通过对遮挡
以及复杂姿态进行建模,同时联合自下而上的人体解析得到的人体语义信息,设计语义空间距离损失,实现精确解析拥挤人群图像,具有较高的准确率。
[0028]
3、本发明通过改进的res网络提取共同特征,分别进行人体解析和姿态估计,并将姿态特征映射到人体解析中,对其进行补充,可以有效解决拥挤人体解析中存在的问题。本发明通过在特征表示中添加超像素特征,利用图卷积建立像素间关系,得到精确的前景特征,并且通过同一前景特征分别进行拥挤姿态估计以及粗人体解析。利用拥挤姿态精确关节点特征和人体解析中人体部位特征进行互补,设计联合优化模块,得到精确的人体解析结果,具有较高的精度。
附图说明
[0029]
图1为本发明的流程图。
[0030]
图2为本发明特征表示具体流程图。
[0031]
图3为本发明粗解析具体流程图。
[0032]
图4为本发明精确姿态估计实例图。
[0033]
图5为本发明精确解析结果实例图。
[0034]
图6为本发明精确解析具体流程图。
具体实施方式
[0035]
实施例1:如图1-图6所示,一种针对拥挤人群的精确人体解析方法,包括如下步骤:
[0036]
step1、输入拥挤人群图像集,通过深度残差网络提取粗图像分层特征和超像素特征,对人体图像进行特征表示,得到前景精确语义特征图,并生成人体候选多区域检测框;
[0037]
step2、将前景精确语义特征图上采样到相同大小,并融合在一起生成高分辨率特征,通过初步解析得到人体粗解析结果;
[0038]
step3、对候选多区域检测框中的前景精确语义特征进行人体姿态估计,生成人体关节点,细化得到多人精确姿态估计结果;
[0039]
step4、通过计算语义距离损失,将得到的人体粗解析结果和多人精确姿态估计结果进行联合优化,输出最终的精确人体解析结果。
[0040]
进一步地,可设置,所述step1具体如下:
[0041]
首先,对输入拥挤人群图像集g利用resnet-101提取其分层特征p={p1,p2,p3,p4,p5},并使用cob卷积导向边界生成超像素分区系列s={s0,s1,...,sn},其中sn是表示整个图像的超像素,sn中的超像素是s
n-1
中的两个超像素组合。匹配p2,p4,p5的大小选取s中的子集n={n2,n4,n5},其中相邻层次间节点数量是1/4倍。
[0042]
然后,对p2,p4,p5进行特征映射以映射到图矩阵,其中w是完全连接层的可读权重矩阵,||是指串联操作,δ
min
(p
le
)和δ
max
(p
le
)分别代表最小池化和最大池化,p
le
表示联合对应层次超像素分块的网格单元。
[0043]
之后,通过图神经网络提取映射特征的上下文和分层信息,联合特征金字塔解码特征进行融合,为减少冗余计算在图神经网络中添加空间及通道注意力,得到最终的特征表示结果。给定映射节点i及一组相邻节点ci,节点i的空间注意力表示为:
其中,m是自我注意头,是节点i邻居节点收集的特征向量集之和。通道注意力表示为道注意力表示为表示节点i及其邻居的特征向量的平均,σ表示sigmod激活的全连接层,与执行元素乘法。注意力最终可表示为其中β是初始化为0的刻度权重。
[0044]
最后,基于特征表示结果,得到前景精确语义特征ff={p'u|1≤u≤5}。并将特征表示结果输入分层级联rpn中得到候选区域,并通过分类和回归预测生成人体候选多区域检测框d={dv},v表示图中的人数。
[0045]
进一步地,可设置,所述step3具体如下:
[0046]
首先对step1中所有检测到的人体候选多区域检测框d进行仿射变换。
[0047]
然后,将变换后的每个人体分别输入到单人姿态估计模块中,生成关节热图并定义两种关节类型,分别为目标关节和干涉关节其中定义损失以抑制干涉关节,其中rsme是均方根误差函数,k表示第v个人的第k个关节,k为关节总数。
[0048]
之后定义人体姿态关联规则,对生成的所有关节点进行关联连接,生成骨架标注图a={a
l
},l表示生成的连接数。并定义姿态相似性函数f(a
x
,ay,η)=1[d(a
x
,ay|λ,λ)≤η]以消除相似姿态,其中d(
·
)为定义的姿态距离函数,λ,λ为参数集合,η为距离阈值。如果d(
·
)≤η则判定a
x
为冗余,进行消除。d(
·
)具体为d(a
x
,ay|λ)=q(a
x
,ay|η1)+μh(a
x
,ay|η2),其中函数q计算姿势骨架之间匹配关节点的置信度,得出姿态之间匹配的关节数量。函数h计算关节间的空间距离,η1,η2是函数中可调参数,μ是平衡两个距离的权重,λ={η1,η2,μ}。
[0049]
最后通过反仿射变换恢复原图像坐标,细化生成精确姿态估计结果f
pose
。
[0050]
进一步的可设置,所述step4具体如下:
[0051]
首先将精确姿态估计结果f
pose
与通过step2得到的粗解析结果f
parsing
进行级联,通过人体多区域候选框和姿态约束将不同人体实例的标签进行分割。
[0052]
然后定义语义空间距离损失l
f_parsing
=λ1l
parsing
+l
parsing
l
pose
+λ2l
pose
,以减少不同语义之间的差距。其中λ1是解析损失权重,λ2是姿态损失权重,表示粗解析损失,表示姿态估计损失,a表示图像中像素点的总个数;m表示标签类别数;1表示第一类交叉熵损失;yi表示的是第i个像素点的类别;ln(fm)表示预测为第m类语义的概率;n是关节点总数;分别表示第n个关节在图像中的像素坐标和真实坐标。
[0053]
最后通过卷积将级联后的结果映射为n
×
c大小,并将解析结果映射到c
×
n大小,融合后输入到3个7
×
7维度为128的卷积层中进行细化,得到最终的精确解析结果。
[0054]
实施例2:一种针对拥挤人群的精确人体解析方法,所述方法具体步骤如下:
[0055]
step1、如图2所示,图像(a)为输入的原始图像;对输入的拥挤人群图像(a)利用
resnet-101提取分层特征,见图(b),并使用cob卷积导向边界生成超像素分区系列(e)s={s0,s1,...,sn},其中sn是表示整个图像的超像素,sn中的超像素是s
n-1
中的两个超像素组合。匹配p2,p4,p5的大小选取s中的子集n={n2,n4,n5},其中设置相邻层次间节点数量是1/4倍。
[0056]
然后对p2,p4,p5进行特征映射,具体为先将p2,p4,p5特征映射到l
th
的矩形网格上,再将网格单元分配给超像素网格单元集合p
le
,其中每个网格对应于输入图像(a)的一个小矩形区域。具体公式为其中w是完全连接层的可读权重矩阵,||是指串联操作,δ
min
(p
le
)和δ
max
(p
le
)分别代表最小池化和最大池化。
[0057]
之后,通过图神经网络提取映射特征的上下文和分层信息,见图(d)。三层图神经网络分别用于提取上下文信息、分层信息、上下文信息,每层都有自己的学习参数,不与其他层共享;为减少冗余计算在图神经网络中添加空间及通道注意力,通过联合特征金字塔解码特征进行融合,得到最终的特征表示结果,见图(c)。给定映射节点i及一组相邻节点ci,节点i的空间注意力表示为:其中,m是自我注意头,是节点i邻居节点收集的特征向量集之和。通道注意力表示为节点收集的特征向量集之和。通道注意力表示为表示节点及其邻居的特征向量的平均,σ表示sigmod激活的全连接层,与执行元素乘法。注意力最终可表示为其中β是初始化为0的刻度权重。
[0058]
最后,基于特征表示结果图(c),得到前景精确语义特征ff={p'u|1≤u≤5},显著化后的示例图如(g)所示,将特征表示结果输入分层级联rpn中得到候选区域,并通过分类和回归预测生成人体候选多区域检测框d={dv},见图(f),v表示图中的人数。
[0059]
step1的具体流程图如图2所示。经过step1后,可以得到前景精确语义特征(g)以及人体候选多区域检测框(f)。数据集选自人体解析通用数据集,如cihp,muti-human parsing v2.0等,并以多人图像为主,平均每幅图像包含人数大于3人,共计6万幅左右:分为训练集43683幅,测试集10000幅,验证集10000幅。本实例以拥挤人群图像为输入,利用pytorch进行实验。通过对提出的模型进行第一阶段的训练,再不断调整训练参数,使模型获得较优的前景语义特征以及检测框精度。其第一阶段定量对比如表1所示,本实例与公知方法中其他典型的用于目标检测深度学习模型如fast rcnn、fast rcnn+fpn以及yolov3进行对比,其中params为模型可学习参数数量,gflops为浮点运算次数,test speed为检测速度,ap
bbox
@0.5iou为检测框平均精度,从结果看出虽然计算量相比较大,但是获得了较高的精度。
[0060]
表1
[0061]
方法paramsgflopstest speed/msap
bbox
@0.5ioufast rcnn34.6m172.313.965.6%fast rcnn+fpn64.1m240.65.168.3%yolov3239m-8.1271.7%本发明113m387.625.573.1%
[0062]
step2、如图3所示,以step1前景精确语义特征(a)为输入,通过双线性插值将生成
的多尺度特征p'2,p'4上采样到p'5级别的尺度,并分别使用1
×
1卷积进行特征整理得到p2″
,p4″
用于对齐相同的语义空间,采用(c)所示的aspp结构提取p5'其多尺度特征p5″
。联合p2″
,p4″
,p5″
通过1
×
1的卷积层,以预测所有人体语义区域,分割得到粗解析结果θ表示1
×
1卷积,见图3(b)。
[0063]
step3、首先对step1得到的d中所有检测到的人体候选多区域检测框进行仿射变换。
[0064][0065]
其中β1,β2,β3是参数向量。和分别是变换前和变换后的坐标。
[0066]
然后,如表2所示,按照人体身体部位,定义18个关节点,将变换后的每个人体分别输入到单人姿态估计模块中。生成关节热图如图4(b)所示。再定义两种关节类型,分别为目标关节和干涉关节其中通过定义损失函数以抑制干涉关节,其中rsme是均方根误差函数,k表示第v个人的第k个关节,k为关节总数。在训练时,利用定义的损失函数抑制每个检测框中不属于该人体实例的关节,减少误连接。
[0067]
表2
[0068]
身体部位关节点头部头,颈关节,左眼,右眼上肢左、右肘关节,左、右腕关节下肢左、右踝关节,左、右膝关节躯干左、右肩关节,左、右髋关节、骨盆关节,脊柱关节
[0069]
之后定义人体姿态关联规则,对生成的所有关节点进行关联连接,生成骨架标注图a={a
l
},l表示生成的连接数。并定义姿态相似性函数以消除相似姿态:f(a
x
,ay,η)=1[d(a
x
,ay|λ,λ)≤η],其中d(
·
)为定义的姿态距离函数,λ,λ为参数集合,η为距离阈值。如果d(
·
)≤η则判定a
x
为冗余,进行消除。d(
·
)具体为d(a
x
,ay|λ)=q(a
x
,ay|η1)+μh(a
x
,ay|η2),其中函数q计算姿势骨架之间匹配关节点的置信度,得出姿态之间匹配的关节数量。函数h计算关节间的空间距离,η1,η2是函数中可调参数,μ是平衡两个距离的权重,λ={η1,η2,μ}。具体公式如下:
[0070][0071][0072]
其中表示检测框的中心,表示第n个关节所在位置,表示第n个关节
所在位置的置信度得分。
[0073]
最后通过反仿射变换恢复原图像坐标,细化生成精确姿态估计结果f
pose
,如图4(c)所示。
[0074]
如表1、3及图4所示,经过step3后,可以得到精确姿态估计结果f
pose
,其中step1生成的人体候选多区域检测框作为输入,并进行第二阶段的训练,保留二阶段的最佳训练参数,以便于最后一阶段训练时进行微调。本发明能获得较高精度的检测结果,见表1。同时,基于检测框,得到的人体关节热图,见图4(b)。
[0075]
对于多人姿态估计而言,本发明具有较高的精度,表3给出了本实例与公知方法中其它典型用于模型如mask rcnn、rmpe、hr-net、以及openpose进行对比,其中ap(average precision)为平均准确率,用于计算测试集得精度百分比;oks(object keypoint similarity)为关键点相似度,通过加入尺度的欧式距离进行计算,主要用于多人姿态估计任务中。具体公式如下:
[0076][0077]
其中,v表示在gt中的某个人,vk表示某个人的关键点,表示当前检测的一组关键点与gt中相同id的关键点的欧式距离,表示这个关键点的可见性为1,即关键点无遮挡并且已标注表示关键点有遮挡但已标注,sv表示gt中人的尺度因子,其值为检测框面积的平方根,σv表示id为v的关键点的归一化因子,δ(*)表示如果*成立则为1,否则为0。t为人为手动设置的阈值,从表3中我们取50,75,平均值m和最小值l。
[0078]
表3
[0079]
方法apap
oks=50
ap
oks=75
apmap
l
mask rcnn62.987.667.957.571.3rmpe72.188.879.168.177.9hr-net75.592.483.371.981.5openpose61.884.967.557.168.2本发明76.490.184.572.383.1
[0080]
step4、首先将精确姿态估计结果f
pose
(图4(c))与通过step2得到的粗解析结果f
parsing
(图5(b))进行级联,通过人体多区域候选框和姿态约束将不同人体实例的标签进行分割。
[0081]
然后通过定义语义空间距离损失,l
f_parsing
=λ1l
parsing
+l
parsing
l
pose
+λ2l
pose
以减少不同语义之间的差距。其中λ1是解析损失权重,λ2是姿态损失权重,表示粗解析损失,表示姿态估计损失,a表示图像中像素点的总个数;m表示标签类别数;1表示第一类交叉熵损失;yi表示的是第i个像素点的类别;ln(fm)表示预测为第m类语义的概率;n是关节点总数;分别表示第n个关节在图像中的像素坐标和真实坐标。
[0082]
最后通过卷积将级联后的结果映射为n
×
c大小,将粗解析结果映射到c
×
n大小,
融合后输入到3个7
×
7维度为128的卷积层中进行细化,得到最终的精确解析结果。
[0083]
如图6所示,经过step4后,获得最终的精确解析结果(c)。通过粗解析结果(b)以及前两个阶段训练得到的姿态估计结果(a),再引入空间语义距离损失函数进行第三阶段的训练,表4给出了本实例与公知方法中其它典型用于实例级人体解析模型如nan、m-ce2p、rp-r-cnn在相同数据集下的对比,可以看到本发明的多项指标优于其他公知方法。其中miou计算真实值和预测值两个集合的交集和并集之比,这个比例可以变形为tp(交集)比上tp、fp、fn之和(并集),公式为miou=tp/(fp+fn+tp);pcp
50
为正确部位的百分比,如果预测的标签位置和真实值之间的距离小于总像素的一半(通常表示为pcp@0.5),则认为被正确检测;ap
p
为基于部分的平均精度。
[0084]
表4
[0085][0086]
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1