一种基于多任务特征提取网络的视觉惯性SLAM系统的制作方法
一种基于多任务特征提取网络的视觉惯性slam系统
技术领域
1.本发明涉及视觉惯性slam系统,更具体的,涉及一种基于多任务特征提取网络的视觉惯性slam系统。
背景技术:
2.近年来,随着人工智能技术的研究与发展,智能移动机器人已经越来越多地出现在工业制造、农业生产、交通运输、社会服务、医疗康复、太空探索等诸多领域,并发挥了重要作用。在智能移动机器人的应用当中,机器人可以通过传感器在未知的环境中来感知自身在三维空间中的位置以及周围的环境结构,从而实现自主定位、地图构建和路径规划等功能。以上功能的实现被称为即时定位与地图构建技术(simultaneous localization and mapping,简称slam)。因此,slam技术是智能移动机器人在未知的环境中进行工作的核心技术。
3.早期slam技术所使用的传感器主要是激光雷达,经过几十年的发展,激光雷达在精度和稳定性方面都有出色表现。但是激光雷达普遍价格昂贵,且难以应用于对重量、体积、功耗等要求较高的智能移动设备,这给slam技术的推广使用加大了难度。近年来,随着相机技术和计算机视觉的发展,以及计算机硬件技术不断提高,使用相机作为传感器的视觉slam技术取得了巨大突破。视觉slam技术所依赖的视觉传感器可以从周围环境中获取丰富的图像信息,而视觉传感器价格低廉且轻量化使得视觉slam技术可以有更加广泛的应用。同时,cpu和gpu技术的成熟使计算机处理图像的能力大大提升。所以,视觉slam技术已经成为了学术研究的热点。
4.传统slam系统所依赖的传统的特征提取算法依赖于人工设计,这在某些特定场景中是有效和实用的。然而,面对复杂多变的场景,如光线不足、照明过度、纹理缺失等,它们的性能并不稳定,甚至可能无法运行。深度学习作为机器学习最重要的一个分支,在特征提取、匹配等众多计算机视觉领域中取得了迅速的发展。这为视觉slam的发展提供了新的方向。
5.针对传统特征提取算法难以处理低纹理等复杂场景的问题,本技术采用一种简化的多任务卷积神经网络来进行特征检测。该网络生成的特征点与描述子相比较传统方法具有更好的鲁棒性,这使得slam系统的位姿估计结果更加准确和稳定,且具有良好的实时性。针对视觉传感器在运动过快时存在获取图像模糊和两两帧重叠区域过少的问题,为了弥补视觉传感器在这方面的不足,本技术采用视觉传感器和惯性传感器融合的策略。
6.伴随着技术的发展和应用进入新阶段,slam所面对的场景更加复杂多变,这就对原有技术提出了新的要求。传统slam系统所依赖的传统的特征提取算法依赖于人工设计,这在某些特定场景中是有效和实用的。然而,面对纹理缺失等复杂多变的场景时,它们的性能并不稳定,甚至可能无法运行。另外纯视觉的slam系统在相机运动过快,导致获取图像模糊和两两帧重叠区域过少的情况下,其表现很难达到精确定位的要求。
技术实现要素:
7.为了解决上述至少一个技术问题,本发明提出了一种基于多任务特征提取网络的视觉惯性slam系统。
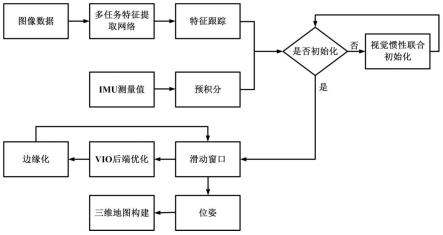
8.本发明第一方面提供了一种基于多任务特征提取网络的视觉惯性slam系统,包括:多任务特征提取网络与三维地图构建模块;
9.获取图像数据信息,将图像数据信息输入多任务特征提取网络,对特征进行检测跟踪,
10.传感器数据处理完成后,检查系统是否已完成初始化,如果未初始化,则对系统进行视觉惯性联合初始化;
11.初始化完成后,使用滑动窗口对固定数目的关键帧的位姿、imu偏差进行优化,从而进行位姿估计,
12.三维地图构建模块将结合系统估计出的相机位姿与相机视频流,利用surfel模型和变形图完成三维重建。
13.本发明一个较佳实施例中,利用surfel模型和变形图完成三维重建,具体包括:通过位姿估计和优化得到精确的相机位姿,
14.将双目相机获得的每幅图像的像素点投影到世界坐标系中,通过点云数据融合,得到surfel三维地图。
15.本发明一个较佳实施例中,多特征提取网络由一个共享的主干网和两个子模块组成,两个子模块包括位置模块与描述子模块,位置模块包括两个卷积层,其中一个卷积层使用relu激活函数,另一个卷积层使用sigmoid激活函数,描述子模块接收主干网处理后的图片,有两个卷积层,信道数均为256,在每个卷积层之后是relu激活函数,根据位置模块输出的特征点相对位置坐标p
relative
,采用双三次插值生成对应的描述子d
image
。
16.本发明一个较佳实施例中,主干网包括四个卷积层,四个卷积层中的信道数为32-64-128-256,积层之间都有一个最大池化层,共三个最大池化层,每个最大池化层的跨距和内核大小都为2,在每个最大池层之后,后续卷积层的通道数将增加一倍,因此通过主干网处理后,输出图片的一个像素是输入图片的8x8个像素。
17.本发明一个较佳实施例中,所述位置模块预测输入图像的特征点的相对位置坐标p
relative
,从相对位置坐标p
relative
转换到图像像素坐标p
image
的映射由以下公式计算:
18.p
image,x
=(c+p
relative,x
)
·f19.p
image,y
=(r+p
relative,y
)
·f20.其中,c是x坐标的列输入索引,r是y坐标的行输入索引。f是下采样因子,并且f=8。
21.本发明一个较佳实施例中,所述surfel模型包括若干个surfel面元,变形图包括若干个节点。
22.本发明一个较佳实施例中,每个节点σn包含了旋转矩阵σr,平移矩阵σ
t
,时间和位置σg,受到变形图影响后的面元的位置由以下公式给出:
[0023][0024]
其中ωn(ms)表示节点σn对面元影响的权重,则ωn(ms)可以表示为:
[0025][0026]
其中d
max
表示ms到最近面元的欧式距离。
[0027]
本发明一个较佳实施例中,还包括自监督训练框架,所述自监督训练框架包括若干张用于训练的图像,每张用于训练的图像会被分成两张,其中一张是保持不变的原始图像a,另一张是通过变换矩阵和随机非空间图像增强变换后的的图像b;
[0028]
通过多任务网络分别检测a、b两张图像的特征点和描述子,然后从a、b两张图像中建立点对应;
[0029]
在损失函数中使用点对应来训练模型;
[0030]
假设a、b两张图像中共有n个点对,每个点对的距离用欧氏距离表示:
[0031][0032]
其中,表示图像a中特征点的位置,表示图像b中特征点的位置,t表示变换矩阵,并且变换矩阵t与图像a到图像b的变换矩阵相同。
[0033]
本发明的上述技术方案相比现有技术具有以下优点:
[0034]
(1)本技术提出一种简化的多任务特征提取网络来代替传统特征提取算法进行特征检测。该网络具有更好的特征提取精度,且生成的特征与orb特征保持相同的描述子格式,具有良好的可移植性,并且基本满足了slam系统的实时性需求。
[0035]
(2)本技术采用视觉传感器和惯性传感器融合的策略,通过对imu数据进行流行上的预积分,在系统前端实现了一种松耦合确定系统初值的方法,同时将视觉中的参考坐标系和惯性坐标系对齐,通过最小化组合能量函数,在滑动窗口中对固定数量的关键帧位姿和imu误差进行优化,从而有效克服相机抖动及场景变化过快等问题,弥补了视觉传感器在这方面的不足。
[0036]
(3)为了确保三维地图模型在三维重建过程中的全局一致性,并使得重建模型尽可能密集地覆盖三维环境,通过surfel模型,系统可以获取点云的个体信息,将点云按时间节点分为刚完成重建的点云和以前重建过的点云,将两种点云区域对齐,实现点云融合,接着使用用四个代价函数的和来实现点云的优化。
附图说明
[0037]
图1是本发明实施例的一种基于多任务特征提取网络的视觉惯性slam系统的框图。
[0038]
图2是本发明实施例的surfel模型的面元。
[0039]
图3是本发明实施例的变形图。
具体实施方式
[0040]
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本技术的实施例及实施例中的特征可以相互组合。
[0041]
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的其他方式来实施,因此,本发明的保护范围并不受下面公开
的具体实施例的限制。
[0042]
如图1-3,所示,本发明提供了一种基于多任务特征提取网络的视觉惯性slam系统,包括:多任务特征提取网络与三维地图构建模块;
[0043]
获取图像数据信息,将图像数据信息输入多任务特征提取网络,对特征进行检测跟踪,
[0044]
传感器数据处理完成后,检查系统是否已完成初始化,如果未初始化,则对系统进行视觉惯性联合初始化;
[0045]
初始化完成后,使用滑动窗口对固定数目的关键帧的位姿、imu偏差进行优化,从而进行位姿估计,
[0046]
三维地图构建模块将结合系统估计出的相机位姿与相机视频流,利用surfel模型和变形图完成三维重建。
[0047]
具体地,传感器数据处理完成后,检查系统是否已完成初始化,如果未初始化,则对系统进行视觉惯性联合初始化。初始化的主要目的是获得系统优化所需的参数和初始值。因为视觉惯性slam系统是一个高度非线性的系统,所以初始值的选择会直接影响整个系统的跟踪精度。因此,需要进行初始化来提供正确的参数和初始值。初始化的参数在系统运行过程中是保持不变的,如绝对尺度和重力加速度。而初始值包括前几帧的位姿、速度信息、三维特征位置以及imu加速度计和陀螺仪的偏差。通过视觉惯性联合初始化,将惯性位姿和视觉位姿相结合,得到系统的初始估计值。
[0048]
初始化完成后,使用滑动窗口对固定数目的关键帧的位姿、imu偏差进行优化,从而实现高精度的位姿估计。其中滑动窗口将待优化的关键帧限制在一定的数量来控制优化的规模,而边缘化用于将一些较旧或者不满足要求的关键帧剔除以保持窗口大小不变。
[0049]
最后,三维地图构建模块将结合系统估计出的相机位姿与相机视频流,利用surfel模型和变形图完成三维重建。
[0050]
根据本发明实施例,利用surfel模型和变形图完成三维重建,具体包括:通过位姿估计和优化得到精确的相机位姿,
[0051]
将双目相机获得的每幅图像的像素点投影到世界坐标系中,通过点云数据融合,得到surfel三维地图。
[0052]
多特征提取网络由一个共享的主干网和两个子模块组成,两个子模块包括位置模块与描述子模块,位置模块包括两个卷积层,其中一个卷积层使用relu激活函数,另一个卷积层使用sigmoid激活函数,描述子模块接收主干网处理后的图片,有两个卷积层,信道数均为256,在每个卷积层之后是relu激活函数,根据位置模块输出的特征点相对位置坐标p
relative
,采用双三次插值生成对应的描述子d
image
。
[0053]
该多任务网络的输入是单张图像。主干网有四个卷积层,四个卷积层中的信道数为32-64-128-256。通道数的选择是根据经验确定的,通过设置几组候选值,根据实验结果选择最佳值。为了加快收敛速度和更容易求解梯度,每个卷积层后是relu激活函数。卷积层之间都有一个最大池化层,共三个最大池化层,每个最大池化层的跨距和内核大小都为2。在每个最大池层之后,后续卷积层的通道数将增加一倍,因此通过主干网处理后,输出图片的一个像素是输入图片的8x8个像素。
[0054]
生成特征点的子模块,也就是位置模块,它接收主干网处理后的图片。位置模块有
两个卷积层,信道数为256和256,前一个卷积层后是relu激活函数,而为了将位置预测限制在区间[0,1]内,后一个卷积层后是sigmoid激活函数。在这里使用回归进行特征点检测,从而实现自监督的训练。并且,因为位置模块的输入图像是原图像的1/64,在一定程度上避免了特征点的聚集,实现特征点均匀分布。对于具有3个池化层的网络,位置模块可以预测输入图像的特征点的相对位置坐标p
relative
,从相对位置坐标p
relative
转换到图像像素坐标p
image
的映射由以下公式计算:
[0055]
p
image,x
=(c+p
relative,x
)
·f[0056]
p
image,y
=(r+p
relative,y
)
·fꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0057]
其中,c是x坐标的列输入索引,r是y坐标的行输入索引。f是下采样因子,并且f=8。
[0058]
生成描述子的子模块,也就是描述子模块。与位置模块类似,它接收主干网处理后的图片,有两个卷积层,信道数均为256,在每个卷积层之后是relu激活函数。根据位置模块输出的特征点相对位置坐标p
relative
,采用双三次插值生成对应的描述子d
image
。
[0059]
为了实现自监督的特征检测,采用自监督训练框架。在这个框架中,每张用于训练的图像会被分成两张,其中一张是保持不变的原始图像,设为a,另一张是通过变换矩阵(如旋转、缩放和透视变换)和随机非空间图像增强(如亮度和噪声)变换后的的图像,设为b。为了计算损失函数,需要使用多任务网络结构分别检测a、b两张图像的特征点和描述子,然后从a、b两张图像中建立点对应。最后,在损失函数中使用点对应来训练模型。那么假设a、b两张图像中共有n个点对,每个点对的距离用欧氏距离表示:
[0060][0061]
其中,表示图像a中特征点的位置,表示图像b中特征点的位置。t表示变换矩阵,并且变换矩阵t与图像a到图像b的变换矩阵相同,使图像a中的特征点映射到图像b中。
[0062]
训练特征点和描述子的损失函数由两个损失项组成:
[0063]
l
total
=α
pt
l
pt
+α
desc
l
desc
ꢀꢀꢀꢀꢀ
(3)
[0064]
其中,前一项损失l
pt
是特征点损失,后一项l
desc
是描述子损失。每一个损失项都有一个对应的权重项,分别是α
pt
和α
desc
。
[0065]
特征点损失l
pt
能够确保在不同角度和不同光线强度下都能检测到相同的特征点,具体表示形式为:
[0066][0067]
第一项中α
position
是对应的权重项。用于确保图像a和图像b中预测的两个对应的特征点是同一个特征点,可以简化为式(2)的给出的表达形式:
[0068][0069]
第二项中用以确保特征点的可信度。分数越高,对应特征点的可重复性越强,具体表示为:
[0070][0071]
其中,表示所有点对之间的平均距离:
[0072][0073]
最初,该网络生成随机位置的特征点。随着训练次数增加,点对之间的距离将逐渐减少,从而提高特征点的定位。因此,该网络能够根据所提供的训练数据和经过变换后的数据,学习到均匀分布且准确的特征点。
[0074]
总损失中的描述子损失l
desc
,使用hinge损失函数来确定。首先定义一个单应诱导对应s
ij
:
[0075][0076]
其中,g
ij
表示对应两点间的像素间隔。
[0077]
则每组描述子损失可以表示为:
[0078][0079]
其中,m
p
是hinge损失中的正裕度,mn是hinge损失中的负裕度。权重项λd用于平衡对应点与非对应点。
[0080]
最后,描述子损失l
desc
可以表示为:
[0081][0082]
基于surfel的三维地图构建方法如下:
[0083]
通过位姿估计和优化可以得到精确的相机位姿,然后将双目相机获得的每幅图像的像素点投影到世界坐标系中,最后通过点云数据融合,得到精确的surfel三维地图,在surfel的表示中,三维点的位置信息可以通过双目相机测得的深度数据获得。
[0084]
图2表示surfel面元,其中每个圆表示一个surfel面元,三维地图的表面由多个面元组成;图3表示变形图,其中点表示节点,线表示边。每个surfel面元位置ms都会受到变形图i(ms,σ)中节点的影响,并且许多节点和边可以一起组成一个变形图。每个节点σn包含了旋转矩阵σr,平移矩阵σ
t
,时间和位置σg。那么,受到变形图影响后的面元的位置由以下公式给出:
[0085][0086]
其中ωn(ms)表示节点σn对面元影响的权重,则ωn(ms)可以表示为:
[0087][0088]
其中d
max
表示ms到最近面元的欧式距离。点云按时间节点分为刚完成重建的点云和以前重建过的点云,将两种点云区域对齐,实现点云融合。融合的两点之间的对应关系可以表示为:
[0089][0090]
其中表示目标点云的位置,表示当前帧点云的位置,和分别表示和
对应的时间戳。接下来用四个代价函数的和来优化点云。
[0091]
第一个代价函数利用forbenius范数对每个节点的位姿进行,表示为:
[0092][0093]
第二个代价函数利用正则化保证变形图的连续,表示为:
[0094][0095]
第三个代价函数是使q中误差最小化的约束项,其中由式(11)解得,可以表示为:
[0096][0097]
最后,为了将新的点云数据加入到三维地图中,我们用第四个代价函数将非活动区域的点云固定并对目标点进行优化:
[0098][0099]
基于以上的四个代价函数可以得到总的代价函数,表示为:
[0100]etotal
=ω
roterot
+ω
regereg
+ω
conecon
+ω
pinepin
ꢀꢀꢀ
(18)
[0101]
其中,对应的权重设置为ω
rot
=1,ω
reg
=10,ω
con
=100和ω
pin
=100。
[0102]
因此,通过全局相机位姿优化可以得到的精确的新位姿,新的相机位姿影响节点优化,从而对surfel模型产生影响,利用surfel模型和变形图对点云进行融合和优化,最终得到精确的三维地图。
[0103]
本技术硬件方面:主要使用小觅d1010双目视觉惯性相机,其中内置有六轴imu;计算机的主要配置为intel core i7-9700kf cpu、geforce rtx 2080 super gpu以及16gb的运行内存;
[0104]
软件编程:以c/c++与python为主,主要在ubuntu系统下进行实验编程;
[0105]
位姿估计与三维重建策略:借鉴当前先进的slam算法,设计一套面向复杂场景的实时性slam实验平台,该实验平台集数据的实时采集、数据的实时处理、数据的后期优化处理,该实验平台可以面向复杂场景进行位姿估计与三维重建。
[0106]
本技术的策略是采用手持式双目视觉惯性相机采集数据,使用本技术的系统和rovio,s-msckf,s-viorb三种先进的视觉惯性里程计估计位姿并进行对比。由于在真实场景中无法获取相机运行的精确真实轨迹,系统在ros中运行时,使用ros中的三维可视化工具rviz订阅系统发布的位姿数据,从而可以实现轨迹路线的绘制和实时显示,为了验证本技术的视觉惯性slam系统在三维重建方面的精确性和稳定性,在不同场景中进行了实验,系统采用多任务特征提取网络提取特征点,这可以很好地处理低纹理的困难场景,从而确保了系统在精确的相机位姿估计下完成三维重建。另外,surfel模型可以直接获取点云的个体信息,将点云区域对齐,实现点云优化和融合。
[0107]
本发明技术方案具有以下有益效果:
[0108]
本技术提出一种简化的多任务特征提取网络来代替传统特征提取算法进行特征检测。该网络具有更好的特征提取精度,且生成的特征与orb特征保持相同的描述子格式,具有良好的可移植性,并且基本满足了slam系统的实时性需求。
[0109]
本技术采用视觉传感器和惯性传感器融合的策略,通过对imu数据进行流行上的预积分,在系统前端实现了一种松耦合确定系统初值的方法,同时将视觉中的参考坐标系和惯性坐标系对齐,通过最小化组合能量函数,在滑动窗口中对固定数量的关键帧位姿和imu误差进行优化,从而有效克服相机抖动及场景变化过快等问题,弥补了视觉传感器在这方面的不足。
[0110]
为了确保三维地图模型在三维重建过程中的全局一致性,并使得重建模型尽可能密集地覆盖三维环境,本技术提出一种基于surfel模型的三维重建方法,通过surfel模型,系统可以获取点云的个体信息,将点云按时间节点分为刚完成重建的点云和以前重建过的点云,将两种点云区域对齐,实现点云融合,接着使用用四个代价函数的和来实现点云的优化。
[0111]
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
[0112]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对上述实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的上述实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
[0113]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1