基于单目视觉的多无人机智能识别及相对定位方法
1.本发明属于无人机编队感知研究领域。针对gps拒止环境下无人机编队的定位问题,设计了一种新型多无人机基于单目视觉的智能识别及相对定位算法。
背景技术:
2.近年来,随着无人机技术的高速发展,无人机开始被用来执行一些高复杂性、高动态性和高度不确定的任务。虽然旋翼无人机有着上述众多优势,但由于无人机需要满足轻量化和小型化,单架无人机的效率和性能受限,当执行复杂任务时容错率较低。因此,无人机的任务模式开始由单机执行任务模式向多无人机协同作业方向发展。
3.在军用及民用领域,无人机自主飞行执行任务需要无人机具备定位能力。对单个无人机而言,其搭载的惯性测量单元(inertial measurement unit,imu)可以计算出无人机三轴姿态角、角速度和角加速度,通过imu获取的数据从而可以对无人机进行快速、稳定的姿态控制。而对于无人机编队而言,由于编队内无人机在三维空间中要以一定的结构形式形成某种队形排列,因此编队内的无人机不仅需要自身位置,更需要获取其他无人机的位置。在室内情况下,运动捕捉系统由于其毫米级的定位精度被广泛应用,但运动捕捉系统作为外部设备,也限制着无人机只能在系统覆盖的区域实现定位。在室外情况下,基于全球定位系统(global positioning system,gps)的定位方法已成为主流,但其定位精度不高,在楼宇间以及森林环境下信号微弱甚至丢失。除上述方法外,常用的定位技术还有rtk(real-time kinematic)定位技术、基于视觉的定位技术、基于激光雷达(lidar)的定位技术和超宽带(ultra wide band,uwb)定位技术等。其中,rtk定位技术虽然定位精度较高,但由于其是建立在基站和流动站基础上依赖gps载波相位观测值进行实时动态定位,其本质上仍需要gps信号的覆盖,故和gps缺点一致。而uwb定位技术需要部署多个基站,缺点类似于运动捕捉系统,其定位距离受限于基站的部署位置。
4.因此,在上述方法失效的情况下,无人机一般需要利用自身搭载的传感器来进行自身的定位,其中基于激光雷达定位与基于视觉定位为主要方法。激光雷达具有稳定、精确、实时性好的优点,但由于其价格昂贵、体积和重量的限制使其不能适用于小型无人机系统。视觉传感器具有体积小、重量轻、价格低的优点,虽然其需要较大的计算量的支持,但近年来随着计算机视觉技术的发展、机载计算单元能力的提高,基于视觉的定位方式已经逐渐成为热点。因此,发明基于视觉的定位方法对无人机及其编队自主飞行有着重要意义。
5.目前常见的用于基于视觉的无人机编队相对定位方法可以分为三种:基于自然环境的位姿估计、基于人工标签特征的位姿估计和基于无人机自身特征的位姿估计。其中同时定位与建图(simultaneous localization and mapping,slam)的前端,视觉里程计(visual odometry,vo)是最具有代表性的一种基于自然环境的位姿估计方法,该方法主要是通过相邻图像中的信息估计相机运动,进而获取定位信息。该方法对环境纹理要求较高,要求图像中具有丰富的特征点,一旦相机远离纹理表面时,定位信息会显著性变差,甚至丢失。基于人工标签的位姿估计方法主要是通过在无人机上部署一些人工特征,根据预先设
计好的检测方法,相机从图片中检测上述特征,进而实现相对定位。目前常用的标签主要有二维码标签、圆形标签、h型标签和led标签等。该方法也是较多研究人员目前所采用的方法,优点是计算量小,仅需从图片中检测人工标签即可,具有较快的识别速度与较高的定位精度。但缺点也很明显,定位方法完全依赖人工部署标签,一旦标签丢失或损坏,便无法实现定位,并且在无人机上增加标签会增大无人机负载与飞行阻力等,最终影响无人机的可持续飞行时间。基于无人机自身特征的位姿估计方法主要目的是去标签化,通过深度学习等方法,在环境中提取出无人机自身特征进行定位,也是目前研究的一个热点。该方法优点为不依赖外部条件,仅根据无人机自身特征从环境中分离出无人机,进行相对定位。该方法的主要缺点为涉及到深度学习,计算量较大,但随着近年来机载嵌入式设备算力的快速发展,已经完全具备机载计算机在线识别的要求。
6.2018年,苏黎世联邦理工学院的研究团队提出了一种基于单目视觉的相对位姿估计方法,用于自主近距离编队飞行。该团队通过在master无人机上部署led标签,slave无人机配备单目相机,相机通过捕捉led灯光,间接计算出自己相对于master无人机的位置。该团队还使用卡尔曼滤波器将计算出的相对位置与飞控中的imu获得的数据进行了数据融合。最后进行了3d仿真以及室内实验,将估计出的相对位置数据与运动捕捉系统获得的数据进行对比,实验效果较好。之后在室外进行了进一步的实验验证,验证了算法的可靠性。
7.2016年,美国亚利桑那州立大学的研究人员提出了一种基于单目视觉的无人机相对定位框架。两架无人机均配备单目相机,以两个单目相机的相对姿态估计策略为基础,在相机连续运动中求解无人机的相对运动位姿。该方法要求同一时刻,两架无人机拍摄的图片有重叠区域,之后通过分离并匹配该重叠区域的共同特征来估计无人机之间的相对位姿,通过三角测量的方法进行尺度还原,最终实现无人机的相对定位。该团队首先在gazebo仿真环境验证了方法的有效性。之后在室外环境下,以一架无人机和一台用于模拟静止无人机的摄像机进行了室外实验验证,并和gps获得的数据进行了对比,取得了良好的定位效果。
8.2019年,捷克理工大学的研究团队创新性地提出了一种基于uvdar(ultraviolet direction and ranging)传感器的无人机编队相对定位方法。uvdar传感器系统基于紫外光线原理,利用紫外光谱提供相对位置和偏航测量值用于无人机控制,进而引导follower无人机至leader无人机指定的位置和方向。无人机上搭载紫外摄像机,和多个能够发射紫外光线的标记点构成uvdar传感器系统。该方法在室外条件下进行了验证,证明了用于编队飞行的可靠性。
技术实现要素:
9.为克服现有技术的不足,本发明旨在针对gps拒止环境下无人机编队的定位问题,设计一种新型多无人机基于单目视觉的智能识别及相对定位算法,进行了微型无人机编队实时飞行实验。本发明采用的技术方案是,多无人机基于单目视觉的智能识别及编队相对定位方法,在跟随无人机上,根据单目视觉信息,并利用基于darknet的卷积神经网络在线检测识别视野中的领航无人机,利用识别结果计算出跟随无人机自身相对领航机的相对位置,利用控制算法实现跟随无人机对领航机跟踪。
10.采用的卷积神经网络为具有24层网络的yolov3-tiny,该网络架构采用全卷积的
方式,无全连接层,最后输出的特征图送入yolo层,yolo层采用基于anchor的预测方法来取代全连接层。
11.采用的卷积神经网络具体结构如下:
12.(1)卷积层
13.a.卷积计算
14.卷积的主要功能是指卷积核即滤波器通过在输入图片上滑动,通过卷积操作从而得到一组新的图像特征;
15.b.批归一化
16.输入为一个小批量样本:i={λ1,...,λn};输出:{yi=bn
λ,β
(λi)},其具体展开如(1)所示.
[0017][0018]
其中,ε为大于0的常数,作用为防止分母等于0,γ,β为需要学习的模型参数,采用滚动平均值式(2)的方法来替代式(1)中平均值μi的计算;
[0019][0020]
c.激活函数
[0021]
yolo层前的卷积层输出经过的激活函数为线性激活函数linear(f(x)=x),其余卷积层都经过非线性激活函数leakyrelu处理后输出;
[0022]
(2)最大值池化层maxpool
[0023]
池化层pooling layer通常在卷积层之后使用,用于进行降采样,网络池化层均采用最大值池化方式;
[0024]
(3)上采样层upsample与特征融合层route
[0025]
采样层使用了最近邻差值方法,该差值方法无需计算,通过将与待求像素距离最近的邻像素的像素值赋值给待求像素值来实现;
[0026]
特征融合层的作用是将浅层卷积网络与深层卷积网的输出特征图在深度方向上进行拼接,特征融合的作用是保留浅层特征图的信息,为之后yolo层的预测保留更多的特征;
[0027]
(4)yolo层
[0028]
yolo层对全连接层进行了取代,作用是在全卷积神经网络输出的特征图上进行分类和定位回归,共采用两个yolo层,分别负责不同尺度特征图的预测,实现多尺度预测,即大网格预测大物体,小网格预测小物体,每个网格会由三个先验框即anchor进行预测。
[0029]
预测流程设计;
[0030]
输入图片通过卷积神经网络提取特征,得到n
×
n大小的特征图,然后再将输入图像平均分成n
×
n个网格,根据训练集中提供的bbox真值,目标的中心坐标落在哪个网格中,
就由该网格来预测该目标m每个网格会有固定数量的边界框参与预测,预测使用的先验边界框是预先通过k-means聚类得到的固定大小的锚框anchor,此外,预测得到的特征图除上述n
×
n的两个特征维度外,还有纵向的深度维度,大小为b*(5+c),其中b表示每个网格所需要预测的边界框数量,c表示边界框的类别,5表示bbox的四个坐标信息和目标置信度;
[0031]
卷积神经网络需要为每个bbox预测四个坐标值,网络输出t
x
,ty,tw,th为相对目标中心网格左上角坐标的偏移值,其中t
x
表示目标中心网格左上角坐标x方向的偏移值,ty表示目标中心网格左上角坐标y方向的偏移值,tw为矩形框宽度方向上的偏移量,th为矩形框高度方向上的偏移量;进而通过式(4)计算得出预测的bbox坐标值,其中c
x
,cy为目标中心网格距图像坐标系原点的偏移量,lw,lh表示为锚框的宽和高,σ(
·
)为sigmoid函数,其值域为(0,1)起归一化作用,计算结果b
x
,by,bw,bh表示预测得到的bbox坐标,以网格为单位:
[0032][0033]
卷积神经网络除了需要预测bbox坐标外,还需要预测出类别置信度得分其计算公式如式(5),其中pr(classi)表示目标属于类别i的概率,指预测框和真值框之间的交叠比iou(intersection over union),pr(classi|object)指条件类别概率,表示在目标已经存在的前提下目标属于类别i的概率,pr(objecti)表示bbox框是否包含目标的概率:
[0034][0035]
得到上述预测值即实现了对领航无人机的识别。
[0036]
损失函数设计;
[0037]
损失函数loss分为三个部分,定位损失、目标置信度损失和分类损失;
[0038]
(1)定位损失
[0039]
使用最小平方误差mse损失函数,其表达式为式(6),其中,s表示网格共有s*s个,每个网格有b个候选锚框,t
xi
,t
yi
,t
wi
,t
hi
表示网络输出值即预测值,表示真值,以上数据表示预测/真值坐标相对网格左上角坐标的偏移量,系数目的是提升对小物体的检测效果,以及表示第i个网格的第j个锚框anchor是否负责预测该目标,若负责预测为1,否则为0,该定位损失函数是通过计算定位框的坐标预测值与真值之间的差值平方的和得到:
[0040][0041]
使用基于giou的定位损失函数替代mse来作为网络的定位损失函数项,iou即交并比,计算的是预测边框面积和真实边框面积的交集和并集的比值,计算公式为式(7),进行
优化后计算公式为式(8),引入最小包围区域c,进而定位损失函数表示为式(9):
[0042][0043][0044][0045]
(2)目标置信度损失
[0046]
目标置信度损失函数如式(10)所示,其中co表示物体的置信度,为真值,与含义相反:
[0047][0048]
(3)分类损失
[0049]
对于检测物体的分类问题使用二元交叉熵bce(binary cross entropy)函数,如式(11)所示,其中ρ(c)表示类别c的分类概率,以及表示真值:
[0050][0051]
最终的损失函数即为上述三部分相加,loss=l
giou
+l
conf
+l
cla
。
[0052]
相对定位解算;
[0053]
单目相机的成像过程可用针孔相机模型来描述,相机坐标系原点设置于摄像机的光心o即针孔模型中的针孔处,习惯上z轴指向相机正前方,根据右手坐标系,x轴和y轴分别指向相机右侧和下侧,从而构成相机坐标系o-x-y-z,设p点为现实世界的空间点,经过光心o投影后,落在物理成像平面坐标系o
′‑
x
′‑y′‑z′
上,成像点为p
′
,设p的坐标为[x y z]
t
,p
′
的坐标为[x
′ꢀy′ꢀz′
]
t
,焦距f大小为像素平面到小孔的距离,从而,根据相似三角形关系,得式(12):
[0054][0055]
相机的最终输出为由像素点组成的图片,需要建立像素坐标系o-μ-ν,通常定义方式为:图片左上角第一个像素点位置为原点o,μ轴向右和x正半轴平行,ν轴向下和y轴负半轴平行,从物理成像平面坐标系转换至像素坐标系,经过了缩放与平移,设在μ轴和ν轴分别缩放了p和q倍,原点平移坐标为则物理成像平面p
′
到像素平面的转换关系如式(13)所示:
[0056][0057]
代入式(12),得到
[0058][0059]
其中f
x
=pf,fy=qf,像素f单位为米,p、q单位为像素/米,故f
x
、fy的单位为像素,进一步将式(14)写为矩阵形式得:
[0060][0061]
式(15)中,由元素f
x
,fy,组成的r
3*3
矩阵即为相机的内参数矩阵k,采用张氏标定法进行相机标定;
[0062]
[x y z]
t
为图片中像素坐标系[μ ν]
t
所对应的相机坐标系下的三维坐标,也是相对定位算法最终要求得的坐标,根据相似三角形原理,可以计算得出深度信息z如式(16)所示,其中w
uav
为由无人机轴距计算出的无人机水平宽度,μ
uav
为无人机在图片中的像素宽度:
[0063][0064]
无人机控制算法设计;
[0065]
根据计算出的无人机相对位置关系,以无人机的速度为控制输入,对跟随无人机位置进行控制,其中采用pid控制器,控制输入u如式(17)所示:
[0066][0067]
其中pd∈r3为期望相对位置输入,pb=[x y z]
t
∈r3为机体坐标系下的无人机位置。k
p
,ki,kd分别为控制器的p、i、d项控制参数。
[0068]
本发明的特点及有益效果是:
[0069]
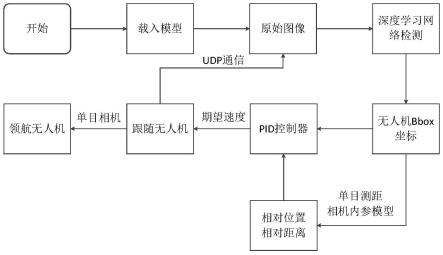
1.本发明针对gps拒止环境下无人机编队相对定位问题,本发明基于单目视觉信息,采用深度学习的方法在线识别微型无人机(仅80g),计算编队内无人机相对位置坐标。实现了无需直接通讯,仅使用视觉信息且无需辅助标签(如led、apriltag等标记)的情况下达成无人机编队控制;
[0070]
2.本发明基于背景减法实现无人机数据集自动标注及搭建,减少人工标注数据集的时间成本与不准确性;搭建基于darknet的卷积神经网络,合理选取不同损失函数分别进行离线训练,对比训练模型检测效果,提高模型在线识别无人机的精度;最后进行了微型无人机编队实时飞行实验验证,证明所提方法的有效性。
附图说明:
[0071]
图1是本发明所采用的无人机编队硬件平台;
[0072]
图2是基于深度学习的无人机编队视觉相对定位软件架构;
[0073]
图3是背景减法示意图;
[0074]
图4是数据集获取方法示意图;
[0075]
图5是数据集标注流程图;
[0076]
图6是用于地面站和模型训练的移动工作站;
[0077]
图7是人工标注和使用mse损失函数训练模型识别效果;
[0078]
图8是基于背景减法标注和mse损失函数训练模型识别效果;
[0079]
图9是基于背景减法标注和giou损失函数训练模型识别效果;
[0080]
图10是实验场景和跟随无人机视角图;
[0081]
图11是坐标系定义;
[0082]
图12是无人机编队形成及悬停;
[0083]
图13是实验1的x轴相对坐标;
[0084]
图14是实验1的y轴相对坐标;
[0085]
图15是实验1的z轴相对坐标;
[0086]
图16是实验1的无人机三维距离;
[0087]
图17是基于视觉的无人机编队矩形飞行实验图;
[0088]
图18是实验2的x轴相对坐标;
[0089]
图19是实验2的y轴相对坐标;
[0090]
图20是实验2的z轴相对坐标;
[0091]
图21是实验2的无人机三维距离。
具体实施方式
[0092]
本发明旨在针对gps拒止环境下,无人机编队内部成员相对定位问题,设计了一种新型多无人机基于单目视觉的智能识别及相对定位算法。技术方案整体概述如下:在跟随无人机上,根据单目视觉信息,并利用基于darknet的卷积神经网络在线检测识别视野中的领航无人机,利用识别结果计算出从属无人机自身相对领航机的相对位置,利用控制算法实现从属无人机对领航机跟踪。具体设计步骤如下:
[0093]
步骤1)卷积神经网络架构设计;
[0094]
卷积神经网络作为深度学习方法中众多模型中的一种,得到了广泛使用。为实现轻量级计算,保证处理的实时性。本发明采用的网络为具有24层网络的yolov3-tiny,该网络架构采用全卷积的方式(无全连接层),最后输出的特征图送入yolo层,该层采用了基于anchor的预测方法来取代全连接层。本发明所设计的卷积神经网络架构如表1所示。在第一层卷积层进行处理前,送入网络的输入特征图大小为416*416*3。其中出现的网络层功能介绍如下。
[0095]
表1卷积神经网络架构
[0096][0097]
注:route层(
·
)内表示进行特征图拼接的网络层数。
[0098]
(1)卷积层
[0099]
卷积层主要分成三个部分,输入图像先进行卷积计算,之后对卷积计算输出结果进行批归一化,最后通过激活函数得到该卷积层的最终输出特征图像。下面将分开介绍上述三个部分。
[0100]
a.卷积计算
[0101]
在图像处理中,卷积通常作为特征提取的有效方法。卷积的主要功能是指卷积核(即滤波器)通过在输入图片上滑动,通过卷积操作从而得到一组新的图像特征。在实际计算中,通常会以互相关计算替代卷积,即卷积核与对应图像点进行点积运算并取平均值。
[0102]
卷积的输出和卷积核的大小是有关的,卷积核尺度增大,对应的输出图像特征尺度会相应减小。除了卷积核大小,输出尺度的大小还和卷积核的步长(stride)以及输入图像是否进行了零填充(zero padding)有关。其中,步长指的是卷积核的滑动间隔,默认为1;零填充指在输入图像矩阵的四周填充零的操作,经过零填充后进行卷积运算特征图尺寸不变(步长为1)。
[0103]
此外,输出特征的通道数和卷积核的个数相关,即输出特征通道数总是等于卷积核个数。例如,输入有3个通道,设置2个卷积核。则对于每个卷积核,先在输入3个通道上分别作卷积,再将三个通道结果相加起来得到单个卷积核的卷积输出,由于卷积核有2个,从而输出通道数为2。
[0104]
b.批归一化
[0105]
对输入图像进行卷积计算后,得到初步结果后,需要对其进行批归一化。这可以使地貌更加平滑,使梯度更加具有预测性和稳定性,一定程度上解决梯度消失的问题,可以更快的进行训练。其原理如下,输入为一个小批量样本:i={λ1,...,λn};输出:{yi=bn
λ,β
(λi)},其具体展开如(1)所示.
[0106][0107]
其中,ε为大于0的较小的常数,作用为防止分母等于0,γ,β为需要学习的模型参数。而在预测过程中,单个样本的输出不应取决于批归一化所需要的随机小批量样本,但又由于无法采样到所有样本,故采用滚动平均值式(2)的方法来替代式(1)中平均值μi的计算。
[0108][0109]
c.激活函数
[0110]
激活函数(activation functions)可以看做一个非线性处理单元,引入的作用是在使神经网络具有非线性,使神经网络能够具有学习复杂函数的能力。常用的激活函数有sigmoid、relu(rectified linear unit)、tanh等。其中sigmoid函数表达形式为relu函数表达形式为max(0,x),以及tanh函数为tanh(x)。
[0111]
其中relu函数在实际应用中比sigmoid/tanh函数收敛速度快很多,且在x》0时能够保证梯度不衰减,但在x《0的时候是无梯度的,会导致权重无法更新。故研究人员提出了leaky relu激活函数,其表达形式为式(3),函数在x负半轴的斜率为α(模型训练中取α=0.01),来保证x《0时的梯度存在。
[0112]
f(x)=max(αx,x).
ꢀꢀꢀ
(3)
[0113]
本发明采用的卷积神经网络,除yolo层前的卷积层输出经过的激活函数为线性激活函数linear(f(x)=x)外,其余卷积层都经过非线性激活函数leakyrelu处理后输出。
[0114]
(2)最大值池化层(maxpool)
[0115]
池化层(pooling layer)通常在卷积层之后使用,一般用于简化卷积层输出的特征,即进行降采样。池化操作通常有最大值池化和平均值池化两种方式,本发明网络池化层均采用最大值池化方式。
[0116]
(3)上采样层(upsample)与特征融合层(route)
[0117]
由于卷积神经网络层数越深,输出的特征图大小越小,深层特征图若和浅层特征图进行特征融合(在深度方向上进行拼接),需要对深层卷积网的输出特征图进行上采样操作,来保持和浅层特征的维度匹配。上采样层使用了最近邻差值方法,该差值方法无需计算,通过将与待求像素距离最近的邻像素的像素值赋值给待求像素值来实现。
[0118]
特征融合层的作用是将浅层卷积网络与深层卷积网的输出特征图在深度方向上进行拼接(需要上采样),特征融合的作用是保留浅层特征图的信息,在一定程度上防止由于网络过深带来的特征信息的丢失,为之后yolo层的预测保留更多的特征。
[0119]
(4)yolo层
[0120]
yolo层对全连接层进行了取代,作用是在全卷积神经网络输出的特征图上进行分类和定位回归。本发明所用网络共有两个yolo层,分别负责不同尺度特征图(13*13和26*26)的预测,分别对应13*13网格和26*26网格的划分,来实现多尺度预测。即大网格预测大物体,小网格预测小物体。每个网格会由三个先验框即anchor进行预测,先验框大小确定,其中13*13网格anchor大小对应[[81,82],[135,169],[344,319]],26*26网格anchor大小对应[[10,14],[23,27],[37,58]]。由于本发明预测类别仅有1个,送入yolo层的特征图大小应为3*(5+1)=18,即yolo层前卷积层的输出通道数(卷积核个数)应设置为18。
[0121]
步骤2)预测流程设计;
[0122]
输入图片通过卷积神经网络提取特征,得到一定大小的特征图,如13*13,然后再将输入图像平均分成13*13个网格(grid cells)。根据训练集中提供的bbox真值(ground truth,gt),目标的中心坐标落在哪个网格中,就由该网格来预测该目标。每个网格会有固定数量(3个)的边界框参与预测,预测使用的三个先验边界框是预先通过k-means聚类得到的固定大小的锚框(anchor),此外,预测得到的特征图除上述13*13的两个特征维度外,还有纵向的深度维度,大小为b*(5+c),其中b表示每个网格所需要预测的边界框数量(3个anchor),c表示边界框的类别,5表示bbox的四个坐标信息和目标置信度。
[0123]
卷积神经网络需要为每个bbox预测四个坐标值,网络输出t
x
,ty,tw,th为相对目标中心网格左上角坐标的偏移值,其中t
x
表示目标中心网格左上角坐标x方向的偏移值,ty表示目标中心网格左上角坐标y方向的偏移值,tw为矩形框宽度方向上的偏移量,th为矩形框高度方向上的偏移量。进而通过式(4)计算得出预测的bbox坐标值,其中c
x
,cy为目标中心网格距图像坐标系原点的偏移量,lw,lh表示为锚框的宽和高,σ(
·
)为sigmoid函数,其值域为(0,1)起归一化作用,计算结果b
x
,by,bw,bh表示预测得到的bbox坐标(以网格为单位)。
[0124][0125]
卷积神经网络除了需要预测bbox坐标外,还需要预测出类别置信度得分其计算公式如式(5)。其中pr(classi)表示目标属于类别i的概率,指预测框和真值框之间的交叠比(intersection over union,iou),pr(classi|object)指条件类别概率,表示在目标已经存在的前提下目标属于类别i的概率,pr
(objecti)表示bbox框是否包含目标的概率。从而得到上述预测值即实现了对领航无人机的识别。
[0126][0127]
步骤3)损失函数设计;
[0128]
为使模型预测值接近训练样本真值,需要首先明确模型的损失函数(lossfunction)。损失函数用来表示模型预测值与训练样本之间的差异。为使模型预测准确,需要通过训练并不断迭代来降低损失函数,不断更新模型权重。即当模型权重取得目标值时使损失函数达到最小。本发明网络所使用的的损失函数loss分为三个部分,定位损失、目标置信度损失和分类损失。
[0129]
(1)定位损失
[0130]
常用的定位损失函数有:最小平方误差(mean square error,mse)损失函数,交并比(intersection over union,iou)损失函数等。yolov3使用的的定位损失函数为mse损失函数,其表达式为式(6)。其中,s表示网格共有s*s个,每个网格有b个候选锚框。t
xi
,t
yi
,t
wi
,t
hi
表示网络输出值即预测值,表示真值,以上数据表示预测/真值坐标相对网格左上角坐标的偏移量。系数目的是提升对小物体的检测效果。以及表示第i个网格的第j个锚框(anchor)是否负责预测该目标,若负责预测为1,否则为0。可以看出,该定位损失函数是通过计算定位框的坐标预测值与真值之间的差值平方的和得到。
[0131][0132]
由于mse方法直接对坐标进行误差计算,针对不同大小的检测框并不具备尺度不变性,即物体在图像中的大小会对定位精度产生影响。并且经过实际实验测试结果表明(见第三章模型检测效果验证),该损失函数训练出的模型虽然能够准确识别目标,但对预测目标的精准定位较差。基于广义交并比的损失函数(generalized intersection over union,giou)是hamid rezatofighi于2019年提出的一种对iou进行改进的定位损失函数。因此,本发明使用基于giou的定位损失函数替代mse来作为网络的定位损失函数项。下面对giou进行介绍。iou即交并比,计算的是预测边框面积和真实边框面积的交集和并集的比值,计算公式为式(7)。可以看出,由于iou是比值计算得到,是具备尺度不变性的。但又由于iou无法区分两物体之间不同的对齐方式,即不同方向上有交叉级别的两个重叠对象的iou也可能会相等,故直接使用iou作损失函数结果仍会较差。故giou在iou的计算基础上进行了优化,计算公式为式(8)。从giou定义可以得出,可以看出当两个目标框a和b无重叠区域时,iou=0将会失去优化目标,而giou通过引入最小包围区域c解决了以上问题。进而定位损失函数表示为式(9)。
[0133][0134][0135][0136]
(2)目标置信度损失
[0137]
目标置信度损失函数如式(10)所示,其中co表示物体的置信度,为真值,与含义相反。
[0138][0139]
(3)分类损失
[0140]
对于检测物体的分类问题使用二元交叉熵(binary cross entropy,bce)函数,如式(11)所示。其中ρ(c)表示类别c的分类概率,以及表示真值。
[0141][0142]
最终的损失函数即为上述三部分相加,loss=l
giou
+lco
nf
+l
cla
。
[0143]
步骤4)相对定位解算;
[0144]
相机通过将三维坐标系中的坐标点映射到二维的图像平面,这一过程可用几何模型来描述。单目相机的成像过程可用针孔相机模型来描述,相机坐标系原点设置于摄像机的光心o(针孔模型中的针孔)处,习惯上z轴指向相机正前方,根据右手坐标系,x轴和y轴分别指向相机右侧和下侧。从而构成相机坐标系o-x-y-z。设p点为现实世界的空间点,经过光心o投影后,落在物理成像平面坐标系o
′‑
x
′‑y′‑z′
上,成像点为p
′
。设p的坐标为[x y z]
t
,p
′
的坐标为[x
′ꢀy′ꢀz′
]
t
,焦距f大小为像素平面到小孔的距离。从而,根据相似三角形关系,得式(12)。
[0145][0146]
相机的最终输出为由像素点组成的图片,需要建立像素坐标系o-μ-ν,通常定义方式为:图片左上角第一个像素点位置为原点o,μ轴向右和x正半轴平行,ν轴向下和y轴负半轴平行。从物理成像平面坐标系转换至像素坐标系,经过了缩放与平移。设在μ轴和ν轴分别缩放了p和q倍,原点平移坐标为则物理成像平面p
′
到像素平面的转换关系如式(13)所示。
[0147]
[0148]
代入式(12),得到
[0149][0150]
其中f
x
=pf,fy=qf。像素f单位为米,p、q单位为像素/米,故f
x
、fy的单位为
[0151]
像素。进一步将式(14)写为矩阵形式得
[0152][0153]
式(15)中,由元素f
x
,fy,组成的r
3*3
矩阵即为相机的内参数矩阵k,该矩阵系数在相机出厂之后固定常数,不会随使用发生变化。但实际使用中需要预先标定,从而得出参数值。为得到所使用相机的内参数矩阵,采用张氏标定法进行相机标定。最终得到参数为f
x
=924.873180像素、fy=923.504522像素、像素和像素。
[0154]
[x y z]
t
为图片中像素坐标系[μ ν]
t
所对应的相机坐标系下的三维坐标,也是相对定位算法最终要求得的坐标。但由于单目相机的尺度不确定性,图像中目标像素点的深度信息无法直接获得。即z的信息无法通过上述计算得出。但由于已知无人机的轴距和相机焦距,根据相似三角形原理,可以计算得出深度信息z如式(16)所示,其中w
uav
为由无人机轴距计算出的无人机水平宽度,μ
uav
为无人机在图片中的像素宽度。
[0155][0156]
步骤5)无人机控制算法设计;
[0157]
根据计算出的无人机相对位置关系,以无人机的速度为控制输入,对跟随无人机位置进行控制。其中采用pid控制器,控制输入u如式(17)所示。
[0158][0159]
其中pd∈r3为期望相对位置输入,pb=[x y z]
t
∈r3为机体坐标系下的无人机位置。k
p
,ki,kd分别为控制器的p、i、d项控制参数。
[0160]
本发明旨在针对gps拒止环境下无人机编队的定位问题,设计一种新型多无人机基于单目视觉的智能识别及相对定位算法,进行了微型无人机编队实时飞行实验。下面结合实施例和附图对本发明做出详细说明,步骤如下:。
[0161]
一、实验软硬件平台架构
[0162]
(1)无人机硬件平台
[0163]
视觉相对定位实验平台使用的无人机为两架大疆dji tello无人机,单架无人机重量仅80g,尺寸大小为98*92.5*41mm。无人机及其主要搭载传感器如图1所示,包括无人机
底部的光流传感器和红外激光传感器,分别于用于无人机自身的水平和高度定位。该无人机搭载一个前视摄像头,输出图片为500万像素,分辨率大小为960*720。无人机内置高清720p图传和wifi模块,将图片通过wifi传至地面站进行计算。搭载1.1ah/3.8v可拆卸电池,最大飞行时间约为13分钟。本发明中,除机载传感器用于定位外,还使用optitrack运动捕捉系统进行定位,但该定位系统不参与无人机的控制,仅用于数据记录,并和视觉相对定位算法获得的定位数据进行比较。
[0164]
(2)软件平台架构
[0165]
基于视觉相对定位的无人机编队系统软件的运行及数据流动关系如图2所示。本发明所使用的的软件系统主要包括运行于地面站的基于深度学习的无人机实时识别算法、基于udp的无线通信系统、视觉信息解算及无人机控制程序。在上述框图执行前,需要首先使用地面站进行模型离线训练,该部分具体介绍见实验验证部分。下面按功能将上述软件单独介绍。
[0166]
首先是基于深度学习的无人机实时识别算法,该部分在模型训练完成的基础上,将无人机实时识别算法进一步封装为api函数供无人机控制系统调用,得到图像中无人机的位置。
[0167]
基于udp(user datagram protocol)的无线通信系统通过在无人机和地面站之间构建局域网,来将相机实时图片通过wifi传送至地面站计算,以及地面站发送实时控制指令至跟随无人机。其中无人机的ip地址设置为192.168.10.1,地面站的ip地址设置为192.168.10.2。除ip地址外,udp进程间通信还需要对应端口号。其中用于无人机控制的端口号为8889,地面站通过将计算出的无人机控制量发送至该端口号实现无人机实时控制;用于查询无人机状态如电池电量、imu等信息的端口号设置为8890;用于视频流传输的端口号设置为11111。为防止数据丢失,无人机成功接收消息后会返回“ok”。
[0168]
视觉信息解算及无人机控制部分在上一部分进行了详细叙述,本部分不再赘述。此外,无人机地面站除运行上述算法外,还用于实施监控跟随无人机状态如电池电量、无人机识别算法输出的相机实时图像信息等。对无人机的正常飞行起关键作用。
[0169]
一、基于背景减法的数据集自动标注与模型训练
[0170]
数据集的预先标注结果在训练过程中充当着真值的作用,因此如何标注数据集以及准确标注数据集是要解决的首要问题。若采用人工的方法,手动以矩形框圈出图像中的无人机的位置,由于人眼视觉分辨率的有限以及人工操作的不确定性,这必然会导致标注出的矩形框坐标和真实坐标存在一定的误差。这最终会对后期的无人机相对定位的准确性产生影响。为此,本发明基于背景减法原理对原始数据集进行处理与标注,其简要流程如图3所示。下面对数据集获取及其标注方法进行展开介绍。
[0171]
(1)数据集采集
[0172]
为保证背景减法算法的前提条件,需要保持同组数据背景相同。实验设备选取为一台摄像机,型号为索尼dv hdr-cx700。之后选择一处场景,以三脚架固定相机来保证录制视频背景相同。视频第一帧为背景图(不存在无人机),之后实验人员操纵无人机在相机视野下飞行,录制一段时间,从而得到一组数据集视频,如图4所示。之后更换场景,重复上述操作。
[0173]
(2)基于背景减法的数据集标注
[0174]
首先,提取上述视频第一帧作为背景图,之后数据集视频中每帧图片与背景图片做“减法”操作,即进行背景分割。对背景分割结果进行二值化阈值处理,此时图片存在较多噪点,进一步对图片进行形态学膨胀去除噪点。得出无人机在图片中的轮廓,如图3中间图片所示。最终计算出无人机在图片中的最小外界矩形坐标,并将其按固定格式写入文件。流程图如图5所示。
[0175]
(3)模型训练
[0176]
本发明基于darknet构造卷积神经网络,使用上文所述的损失函数进行离线训练,获得模型。训练服务器及无人机地面站采用图6所示的移动工作站,该移动工作站配置主要为(nvidia)quadro p3200 gpu、intel酷睿i7 cpu,和16g内存,运行系统为ubuntu 18.04。训练数据集样本大小为5000张图片左右,模型训练时间约为1小时左右。
[0177]
二、模型检测效果验证
[0178]
为保证无人机视觉相对定位的准确性与安全性,训练出一个效果优秀的模型是确保实验顺利进行的关键环节。本发明对模型进行逐步优化的步骤主要为:(1)首先采用人工标注的数据集及mse损失函数进行模型训练。经过实际实验测试,效果较差,识别出的无人机矩形框包含较大冗余背景。如图7所示。(2)进而,基于背景减法算法重新进行数据集标注,损失函数同样采用基于mse方法,模型效果有所改良,冗余背景面积减少,但仍有提升空间。如图8所示。(3)数据集不变,将基于mse的损失函数更改为基于giou算法的损失函数进行训练,识别效果得到进一步提高,即识别出的无人机矩形框能够基本贴合无人机最小外接矩形框,如图9所示。进而得到最终实验所用模型。
[0179]
为能更直观说明模型改良效果,在542张测试图片上进行了不同模型之间的无人机识别结果误差分析,误差计算方法为上述不同模型预测出的面积减去数据集样本真值面积,结果除以数据集样本真值面积,再取绝对值。最后对所有样本误差求和取平均值。最终使用不同模型识别结果,计算得到的误差结果如下表所示。
[0180]
表2模型误差计算结果
[0181][0182]
三、室内实验验证
[0183]
为了证明上述算法应用于无人机编队的可行性,在由两架无人机组成的无人机编队平台上分别进行室内实验验证。实验场景及地面站实时显示的跟随无人机视角如图10所示,图中数字表示无人机识别结果的置信度。
[0184]
坐标系说明如下:相机固连在无人机上,可认为相机坐标系与无人机机体坐标系原点相重合,且均为右手坐标系。但方向定义不同,其中存在旋转关系,具体关系如图11所示。机体坐标系x轴指向无人机正前方,y轴指向机体右侧,z轴垂直于xoy平面指向地面方向。而相机坐标系z轴指向无人机正前方垂直于成像平面,x轴指向无人机右侧平行于成像平面坐标系横轴,y轴指向地面即平行于成像平面坐标系的纵轴。将运动捕捉系统的坐标系定义为惯性坐标系,并以其最终计算出的相对位置作为真值与视觉相对定位信息进行比较。
[0185]
(1)基于视觉的编队集结与定点悬停飞行实验
[0186]
为验证算法的有效性,首先进行编队集结与定点保持飞行实验,跟随无人机通过视觉捕捉领航无人机的位置形成编队,并实现编队的定点悬停。具体实验流程为,实验操作人员首先遥控领航无人机至指定位置悬停,之后跟随者无人机起飞,跟随者无人机相机视野中出现领航者无人机的位置,跟随者无人机根据计算出的相对位置进行控制,形成编队,并保持队形悬停一段时间。最终,操作人员控制无人机降落。实验中,以运动捕捉系统(optitrack)计算出的位置信息作为真值来记录编队飞行轨迹,并将其和视觉估计出的数据进行对比。
[0187]
通过在两架无人机上部署反光点,运动捕捉系统获得的全局坐标系下的无人机编队位置数据如图12所示,其中uav1为领航无人机,uav2为跟随无人机。可以看出,跟随无人机能够根据领航无人机的位置进行相对定位。自起飞点起飞后,经过收敛过程逐渐稳定悬停在领航无人机的正后方。
[0188]
为更直观地说明视觉相对定位效果,给出领航无人机与跟随无人机之间的x轴、y轴和z轴的相对位置坐标(以领航无人机为原点)。x轴相对坐标如图13所示,其中蓝色线段表示使用运动捕捉系统optitrack获取的x轴相对位置,即作为真值的实际位置。红色虚线表示通过视觉信息计算出的x轴相对位置。从图中可以看出,除起飞后的调整阶段(0-5秒)相机不能稳定捕捉到无人机,测量数据误差较大。无人机稳定后,真值与视觉计算位置之间误差均在
±
0.2m范围内。并且x方向期望相对跟踪距离为1.75m,控制误差大约保持在
±
0.25m内。
[0189]
y轴相对坐标如图14所示,可以看出无人机稳定后,真值与视觉计算出的相对位置在y方向上的误差在
±
0.15m范围内。而y方向期望相对跟踪坐标为0m,控制误差大约保持在
±
0.2m内。
[0190]
z轴相对坐标如图15所示,可以看出无人机稳定后,真值与视觉计算出的相对位置在z方向上的误差在
±
0.1m范围内。而z方向期望相对跟踪坐标为0m,即跟随无人机与领航无人机高度保持一致,控制误差大约保持在
±
0.1m内。
[0191]
最后给出两无人机之间的三维距离如图16所示,可以看出无人机稳定后,真值与视觉计算出的无人机之间的三维距离误差在
±
0.2m范围内。而实际期望跟踪距离由上述x-y-z轴的期望距离可计算出为1.75m,可以看出三维距离上的控制误差大约保持在
±
0.25m内。
[0192]
(2)编队矩形飞行实验
[0193]
在验证上述编队定点悬停的可行性后,进一步进行编队飞行实验,证明无人机视觉相对定位算法的可行性。在本节实验中,领航无人机由实验操作人员通过遥控器遥控飞行,飞行形状大致为矩形,领航无人机的水平速度控制采用光流传感器,高度控制采用激光测距传感器。跟随无人机采用自动飞行模式,会自主根据领航无人机的位置调节自身位置,飞行轨迹同样大致为矩形。运动捕捉系统获得的全局坐标系下的无人机编队位置数据如图17所示,其中uav1为领航无人机,uav2为跟随无人机。无人机的飞行方向、起飞和降落点均在图中标注。
[0194]
同样为了更直观的说明该过程的视觉相对定位效果,给出领航无人机与跟随无人机之间的x轴、y轴和z轴的相对位置坐标(以领航无人机为原点)。x轴相对坐标如图18所示,
其中蓝色线段表示使用运动捕捉系统optitrack获取的x轴相对位置,即作为真值的实际位置。红色虚线表示通过视觉信息计算出的x轴相对位置。从图中可以看出,除起飞后的调整阶段(0-5秒)相机不能稳定捕捉到无人机,测量数据误差较大。无人机稳定后,真值与视觉计算位置之间误差均在
±
0.2m范围内。并且x方向期望相对跟踪距离为1.75m,控制误差大约保持在
±
0.4m内。由于领航无人机的大幅度运动以及图片传回地面站存在一定的延时效果,以及图片处理延时,该部分控制误差较上节较大。
[0195]
y轴相对坐标如图19所示,可以看出无人机稳定后,真值与视觉计算出的相对位置在y方向上的误差在
±
0.05m范围内。而y方向期望相对跟踪坐标为0m,控制误差大约保持在
±
0.4m内。
[0196]
z轴相对坐标如图20所示,可以看出无人机稳定后,真值与视觉计算出的相对位置在z方向上的误差在
±
0.2m范围内。而z方向期望相对跟踪坐标为0m,即跟随无人机与领航无人机高度保持一致,控制误差大约保持在
±
0.2m内。最后曲线下降过程为领航无人机降落过程。
[0197]
最后给出两无人机之间的三维距离如图21所示,可以看出无人机稳定后,真值与视觉计算出的无人机之间的三维距离误差在
±
0.2m范围内。而实际期望跟踪距离由上述x-y-z轴的期望距离可计算出为1.75m,可以看出三维距离上的控制误差大约保持在
±
0.4m内。实验结果也最终验证了本发明设计的应用于多无人机编队的基于深度学习的视觉相对定位方法的可行性和跟踪控制算法的有效性。
[0198]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1