基于生成对抗网络的电子鼻数据校正方法与流程
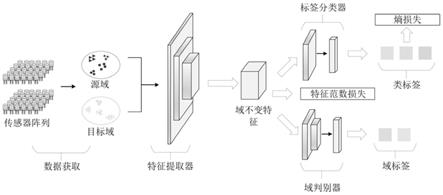
1.本发明涉及传感器数据识别技术领域,特别涉及一种电子鼻数据的校正方法。
背景技术:
2.传感器漂移是指在输入量不变的情况下,传感器输出量随着时间变化的现象。引起传感器漂移的一个原因是传感器老化、中毒或者环境波动等非主观因素,由此产生的传感器漂移数据集包括长期漂移集和短期漂移数据集。引起传感器漂移的一个原因是板间差异,即传感器及相应的硬件在制造时产生的偏差,由此产生的传感器漂移数据为板间差异数据集。除了时间漂移和板间漂移,更复杂的情况是传感器既存在时间漂移也存在板间漂移,由此产生的传感器漂移数据集为混合漂移数据集。
3.机器学习的默认假设是训练集和测试数据是独立同分布的。上述两个现象导致了现有的模型无法对产生漂移(传感器漂移和板间差异统称漂移)的数据进行准确分类。具体到电子鼻系统领域,传感器漂移是电子鼻系统不可规避的一个问题,电子鼻数据因时间漂移或板间差异导致了数据分布不一致,进而导致了数据集之间的类内非同质性,影响机器学习模型的分类准确率,进而限制了电子鼻系统的推广和应用。
技术实现要素:
4.有鉴于此,本发明的目的是提供一种基于生成对抗网络的电子鼻数据校正方法,以解决传感器漂移问题导致电子数据分布不一致,进而导致了数据集之间的类内非同质性的技术问题。
5.本发明基于生成对抗网络的电子鼻数据校正方法包括以下步骤:
6.1)搭建命名为feda的神经网络,所述feda包括用于提取源域和目标域的域不变特征的特征提取器gf、用来区分数据来自源域和目标域的域判别器gd、用于计算域不变特征的l2范数损失的l2范数模块g
l
、用于数据类别的分类的标签分类器gy、用于计算类熵损失的类条件概率熵ge和用于进行梯度反转的梯度反转层,所述梯度反转层连接在特征提取器gf和域判别器gd之间,
7.所述特征提取器gf的输出作为类条件概率熵ge,域判别器gd,l2范数模块g
l
,以及标签分类器gy的输入;把数据分为标签丰富的源域和无标签的目标域,定义源域其中ns表示源域样本数量,表示源域的第i个样本,表示源域第i个样本的标签;其中n
t
表示源域样本数量,表示目标域第j个样本;源域数据的分布为p(xs,ys),目标域数据分布为q(x
t
,y
t
),p≠q;
8.2)进行领域对抗训练:分别在特征提取器gf和域判别器gd上添加一个梯度反转层,首先在数据正向传播过程中训练特征提取器gf学习到域不变特征,从而让域判别器gd无法区分特征是来自源域和还是目标域,再通过最小化域分类损失ld来训练域判别器gd,使得域判别器gd可以区分源域和目标域特征;然后在数据反向传播经过梯度反转层的时候反转梯度,让特征提取器gf无法正确判断领域不变特征,以此完成对抗训练;
9.在领域对抗训练过程中,计算特征提取器gf所提取特征的l2范数,并通过自适应的特征范数损失lf使得源域和目标域的l2范数在大范围上取得平衡;且类条件概率熵ge采用最小化目标域条件熵lh以减少目标域的类间重叠,增加类内同质性。
10.进一步,在步骤2)中通过对抗损失ld来训练特征提取器gf学习域不变特征,对抗损失ld表述如下:
[0011][0012]
其中xs,x
t
表示源域和目标域,表示源域的第i个样本,表示目标域第j个样本。
[0013]
进一步,在步骤2)中梯度反转层反转ld的梯度是把梯度替换为其中σ表示权重参数;把梯度反转层的伪函数定义为r
σ
(x),则梯度反转表示为如下两个函数:
[0014][0015]
其中i表示单位矩阵。
[0016]
进一步,步骤2)中所述自适应的特征范数损失是通过最大均特征分布差异的方式构造得到,构造步骤包括:
[0017]
定义源域和目标域的最大平均特征分布差异如下:
[0018][0019]
其中mmfdd[gf,xs,x
t
]为最大平均特征分布差;xi,xj分别表示源域和目标域的数据。
[0020]
构造一个距离z来拟合源域和目标域之间的特征范数差距lz,使源域和目标域的l2范数分别收敛到z,从而使得mmfdd[gf,ds,d
t
]最小,
[0021][0022]
再构造自适应的特征范数损失lf,公式如下,
[0023][0024]
其中δz表示残差特征范数,wg表示权重参数。
[0025]
进一步,在步骤2)中最小化目标域条件熵lh的公式如下,
[0026][0027]
其中c表示类别数量,表示目标域第k类的预测概率,we表示权重参数。
[0028]
进一步,所述的基于生成对抗网络的电子鼻数据校正方法还包括优化反向传播,
优化目标为:
[0029][0030]
其中θf,θy,θd分别表示gf,gy,gd的参数,α,β,γ分别表示权重参数;的参数,α,β,γ分别表示权重参数;分别表示θf,θy,θd的最优参数;ly为用于引导特征提取器gf和标签分类器gy做出正确的类别预测的交叉熵损失,在源域上ly表示为:
[0031][0032]
本发明的有益效果:
[0033]
本发明基于生成对抗网络的电子鼻数据校正方法,降低了源域和目标域的分布差异,增加了类内同质性,解决电子鼻数据的域适应问题,能提高对传感器漂移数据集的分类正确率。
附图说明
[0034]
图1是feda神经网络的整体框架图。
具体实施方式
[0035]
下面结合附图和实施例对本发明作进一步描述。
[0036]
本实施例中基于生成对抗网络的电子鼻数据校正方法包括以下步骤:
[0037]
1)搭建命名为feda的神经网络,所述feda包括用于提取源域和目标域的域不变特征的特征提取器gf、用来区分数据来自源域和目标域的域判别器gd、用于计算域不变特征的l2范数损失的l2范数模块g
l
、用于数据类别的分类的标签分类器gy、用于计算类熵损失的类条件概率熵ge和用于进行梯度反转的梯度反转层,所述梯度反转层连接在特征提取器gf和域判别器gd之间。
[0038]
所述特征提取器gf的输出作为类条件概率熵ge,域判别器gd,l2范数模块g
l
,以及标签分类器gy的输入;把数据分为标签丰富的源域和无标签的目标域,定义源域其中ns表示源域样本数量,表示源域的第i个样本,表示源域第i个样本的标签;其中n
t
表示源域样本数量,表示目标域第j个样本;源域数据的分布为p(xs,ys),目标域数据分布为q(x
t
,y
t
),p≠q。
[0039]
2)进行领域对抗训练:分别在特征提取器gf和域判别器gd上添加一个梯度反转层,首先在数据正向传播过程中训练特征提取器gf学习到域不变特征,从而让域判别器gd无法区分特征是来自源域和还是目标域,再通过最小化域分类损失ld来训练域判别器gd,使得域判别器gd可以区分源域和目标域特征;然后在数据反向传播经过梯度反转层的时候反转梯度,让特征提取器gf无法正确判断领域不变特征,以此完成对抗训练。
[0040]
在领域对抗训练过程中,计算特征提取器gf所提取特征的l2范数,并通过自适应的特征范数损失lf使得源域和目标域的l2范数在大范围上取得平衡;且类条件概率熵ge采用最小化目标域条件熵lh以减少目标域的类间重叠,增加类内同质性。
[0041]
在步骤2)中通过对抗损失ld来训练特征提取器gf学习域不变特征,以领域对抗的方式来解决电子鼻存在漂移问题,对抗损失ld表述如下:
[0042][0043]
其中xs,x
t
表示源域和目标域,表示源域的第i个样本,表示目标域第j个样本。
[0044]
在步骤2)中梯度反转层反转ld的梯度是把梯度替换为其中σ表示权重参数;把梯度反转层的伪函数定义为r
σ
(x),则梯度反转表示为如下两个函数:
[0045][0046]
其中i表示单位矩阵。
[0047]
较小范数的参数或特征在推断时发挥的信息作用较小,为了减弱噪声样本的影响,使得源域和目标域的特征范数在大范围值上实现平衡,增加域转移效果,本实施例在步骤2)还计算了特征提取器gf提取的域不变特征的l2范数,l2范数是一个非负评价指标函数。步骤2)中所述自适应的特征范数损失是通过最大均特征分布差异的方式构造得到,构造步骤包括:
[0048]
定义源域和目标域的最大平均特征分布差异如下:
[0049][0050]
其中mmfdd[gf,xs,x
t
]为最大平均特征分布差;xi,xj分别表示源域和目标域的数据。
[0051]
从数学上可以把l2范数理解为球心(或者超球原点)到向量点的距离,为此构造一个距离z来拟合源域和目标域之间的特征范数差距lz,使源域和目标域的l2范数分别收敛到z,从而使得mmfdd[gf,ds,d
t
]最小,
[0052][0053]
在构造公式(4)的时候是从数据整体去估计的,因为z的取值是事先定好的,z的取值将决定源域和目标域之间的距离差距是否优化得当,并没有考虑到局部的实例变化。为了能让z可以实例自适应,再构造自适应的特征范数损失lf,公式如下,
[0054][0055]
其中δz表示残差特征范数,wg表示权重参数。公式(5)在使得mmfdd[gf,ds,d
t
]最小的同时也可以避免小批量分布的大小限制和统计估计量的变化。因为z是随着数据的变化而变化的,这样可以更好地让源域和目标域的特征范数在大范围上实现平衡。
[0056]
在步骤2)中最小化目标域条件熵lh的公式如下,
[0057][0058]
其中c表示类别数量,和均表示目标域第k类的预测概率,we表示权重参数。熵越小模型的混乱程度越低,信息准确性就越大,低熵的类别预测可以有效地促进类间的低密度分离,对于无标签的目标域来讲,降低其混乱度可以有效的进行分类。条件熵是类重叠的度量,因此最小化目标域条件熵lh可以减少类之间的重叠,提高类内的高紧实性,从而减轻类内的非同质性。
[0059]
作为对上述实施例的改进,所述的基于生成对抗网络的电子鼻数据校正方法还包括优化反向传播以得到最优的函数解,优化目标为:
[0060][0061]
其中θf,θy,θd分别表示gf,gy,gd的参数,α,β,γ分别表示权重参数;的参数,α,β,γ分别表示权重参数;分别表示θf,θy,θd的最优参数;ly为用于引导特征提取器gf和标签分类器gy做出正确的类别预测的交叉熵损失,在源域上ly表示为:
[0062][0063]
定义伪目标函数如下:
[0064][0065]
其中r是梯度反转层的简写,α,β,γ是权重系数。基于上述的描述我们可以寻找公式(9)的鞍点:
[0066][0067]
在鞍点,域判别器gd的参数θd使域分类损失最小化,标签分类器gy的参数θy使标签预测损失最小化,特征提取器gf的参数θf最小化标签预测损失(使特征具有判别性),同时最大化域分类损失(使特征具有域不变性)。本实施例中采用随机梯度下降法来更新这些参数。
[0068]
可以找到鞍点作为以下随机更新的驻点,
[0069][0070]
其中η表示学习率,一般动态设置。表示在第i个训练示例处计算的相应损失函数。
[0071]
下面在采用电子鼻长期漂移,短期漂移,板间差异,混合漂移四个数据集进行实验验证实施例中所提出方法的有效性。
[0072]
针对长期漂移数据集的实验
[0073]
对于长期漂移实验,采用公开的电子鼻传感器长期漂移数据集并按照实验设置1进行实验,分类精度作为评价指标。
[0074]
表1长期漂移传感器数据集
[0075][0076]
实验设置1:batch1作为训练集(源域)用于训练,batch k(k=2,3,4,
…
,10)作为测试集(目标域)用于测试。
[0077]
表2展示了在实验设置1下不同算法的分类精度,从表中可以清楚的看到实施例中公开的方法feda的分类精度为82.67%,比新近提出的子空间投影方法mscp-sss高出4.57个百分点。这说明了本实施例中所提出的方法可以对传感器数据的分布漂移起到不错的校正。
[0078]
表2设置1下的长期漂移传感器数据集上不同方法的类精度比较
[0079]
[0080]
针对短期漂移数据集的实验
[0081]
对于电子鼻短期漂移问题,采用电子鼻短期漂移数据集并按照实验设置2进行实验,采用分类精度作为评价指标。
[0082]
表3短期漂移传感器数据集
[0083][0084]
实验设置2:batch 1作为源域用于模型训练,batch 2作为目标域用于模型测试。
[0085]
表4设置2下的短期漂移传感器数据集上不同方法的类精度比较
[0086][0087]
从表4可以清楚的知道实施例所提出的方法取得了最高的分类精度,比mcsp-sss方法提高了4.44个百分点,比近年提出的wdgrl方法提高了3.12个百分点,说明本实施例所提出的方法可以有效的解决电子鼻短期时间漂移问题。
[0088]
针对板间差异数据集的实验
[0089]
对于电子鼻板间差异问题,采用公开的板间差异数据集(https://jordifonollosa.wordpress.com/downloads/public-datasets/)以及生物感知与智能信息处理重庆市重点实验室的肺癌电子鼻数据集(参见论文《mcsp-sss:a domain adaptive framework for high-accuracy sensor data classification》)按照实验设置3和实验设置4进行实验验证,分类精度作为评价指标。
[0090]
表5公开板间漂移电子鼻数据集
[0091][0092]
实验设置3:batch 1作为源域用于模型训练,batch k(k=2,3,4,5)作为目标域用于模型测试。
[0093]
实验设置4:prototype 1作为源域用于模型训练,prototype 2作为目标域用于模型测试。
[0094]
公开板间差异电子鼻数据集按照实验设置3进行实验,实验结果罗列在表6中,从表中可以清楚地看出feda在公开的板间取得了很好的分类结果,说明了本实施例所提出的方法可以解决电子鼻板间差异问题,并提高模型的分类精度。
[0095]
表6设置3下公开板间差异传感器数据集上不同方法的类精度比较
[0096][0097][0098]
针对混合漂移数据集的实验
[0099]
对于电子鼻传感器混合漂移问题,即电子鼻既存在板间差异又存在时间漂移,我们采用公开的混合漂移数据集(参见论文《anti-drift in e-nose:a subspace projection approach with driftreduction》)并按照实验设置5进行实验验证,分类精度作为评价指标。
[0100]
表7混合漂移电子鼻数据集
[0101][0102]
实验设置5:master作为源域进行模型训练,salve作为目标域用于模型测试。
[0103]
表8设置5下混合漂移传感器数据集上不同方法的类精度比较
[0104][0105]
从表8可以看到本实施例提出的方法在混合实验数据集上有很好的分类效果,这表明本实施例提出的方法可以处理电子鼻混合漂移问题。
[0106]
最后说明的是,以上实施例仅用以说明本发明的技术方案,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1